 算力呈指数级增长,服务器有哪些进展?
算力呈指数级增长,服务器有哪些进展?
电子发烧友网报道(文/黄晶晶)人工智能的基座包括数据、算力和算法。其中算力更是数据和算法的支撑。各类模型基于数据量、算法的训练和推理推动了算力需求。
根据OpenAI的测算数据,AI训练运行所使用的算力每3-4个月增长一倍。AI训练运行所使用的算力已增长超30万倍。IDC数据显示,2022年我国智能算力规模达到268百亿亿次/秒(EFLOPS),超过通用算力规模;预计未来5年我国智能算力规模的年复合增长率将达52.3%。
构筑算力必然离不开服务器的建设。作为全球顶级的人工智能/高性能计算服务器制造商和解决方案提供商,Supermicro公司日前向电子发烧友网表示,新业务合约有很大一部分来自人工智能/高性能计算领域,而且许多与ChatGPT有关。
Supermicro高管表示,人工智能界并不知道未来还会遇到多少计算密集型问题。以GPT-3为例,它需要323 Zetta FLOPS的算力和1750亿个参数来训练模型,更需要庞大的算力来执行推理工作。更加智能的GPT-4将会有更多的参数,有可能达到一万亿甚至更多。
为了运转这样的大模型和大规模参数,如何有效运用服务器显得十分重要,这关乎服务器的性价比选择。Supermicro公司高管说到,当大量的GPU服务器集群起来时,人工智能/高性能计算应用的每一微秒都很重要。Supermicro设计开发了各种不同架构的GPU服务器,提升了CPU和GPU之间或从GPU到GPU的数据传输速度。通过合理选择系统SKU,解决方案的设计可以将每个CPU/GPU核心利用到极致。从边缘到云,从训练到推理,当前市面上所需的人工智能/高性能计算应用,Supermicro都可以提供全方位的GPU服务器,能让客户充分利用计算资源上花费的每一分钱。
更大的服务器存储空间
随着CPU、GPU和内存技术的发展,现代计算集群处理数据的速度和数量不断增加,因此有必要增强存储性能,以便将数据馈送给应用时不会形成减缓整个系统的速度的瓶颈。
最近,Supermicro推出了超高性能、高密度PB级All-Flash NVMe服务器新机型。更新产品系列中初步推出的产品将在1U 16槽机架式安装系统中支持高达1/2 PB的储存空间,随后的产品则将在2U 32槽机架式安装系统中为Intel和AMD PCIe Gen5平台提供1 PB储存空间。
Supermicro高管表示,Supermicro的Petascale All-Flash服务器提供业界领先的存储性能和容量,可以减少满足热存储和温存储要求所需的机架式系统数量,并通过诸多功能特点降低总体拥有成本。
具体来说,容量扩展,更广泛的PCB有助于实现更灵活的NAND芯片布局;性能扩展,可扩展连接器设计,多链路宽度(x4、x8、x16),支持不同电源配置;热效率,散热和制冷管理改进;面向未来,通用连接器适用于各种尺寸规格,可以为未来几代PCIe提供更加强大的信号完整性;解决方案范围,各种功率配置(20W-70W),适用于更高容量/性能的固态硬盘。
“安装了速度更快的固态硬盘之后,系统的平衡就变得更加重要。Supermicro拥有全新的NUMA平衡对称架构,可以提供到驱动器的最短信号路径、到存储器的带宽平衡和灵活的网络选项,从而降低时延。最重要的是,对称设计还有助于确保整个系统的气流畅通无阻,因此可以使用更加强大的处理器。”Supermicro高管说道。
桌面型GPU兼顾AI与液冷散热
CPU/GUP/xPU也构成了系统设计的热量挑战,各种处理器消耗的功率不断攀升,另一方面,科研/医疗设施/金融/石油和天然气企业需要人工智能/高性能计算来提高其专业竞争力。在这些企业中,有很多需要在员工工作的地点设置工作站或本地服务器。
基于这样的需求,Supermicro推出功能强大、安静且节能的NVIDIA加速人工智能(AI)开发平台系列当中的首款装置。全新的AI开发平台SYS-751GE-TNRT-NV1是一款应用优化的系统,在开发及运行AI软件时表现尤其出色。此外,这个性能强大的系统可以支持小团队里的用户同步运行训练、推理和分析等工作负载。
独立的液冷功能可满足四个NVIDIA® A100 Tensor Core GPU和两个第4代Intel Xeon可扩展处理器的散热需求,在发挥完整性能的同时提高整体系统效率,并实现了在办公环境下的安静(约30dB)运行。
对于散热的考量,Supermicro高管认为搭载NVIDIA A800等强大的协加速器、且声压级介于30~45分贝的工作站,必须采用液冷解决方案才能满足这一需求。冷板式液冷在市场上经过了十多年的考验,目前其成熟度和可靠性已经达到了数据中心大规模部署的水平。
创新技术驱动成长
早前,Supermicro就提出了观察到的七大创新技术,他们包括高性能350W CPU和700W GPU、处理速度更快的DDR5内存、第五代PCI-E 5.0技术、Compute Express Link(CXL,开放式互联标准)、400G高速网络、新型固态硬盘和液冷技术。
简言之就是更高的功耗和更快的数据传输速度。这就需要优化功率效率、解决热量挑战、加强第五代PCIe、DDR5、高速网络、无阻塞系统架构设计和部署等。
Supermicro高管指出,这些创新技术背后的一个共同点是热量调度。更快的处理器频率、更多的计算核心、更高速的网络都会产生更多的热量,这些热量必须输送到数据中心之外。他表示,正如我们预计的技术趋势和产品路线图所示,当前和新一代人工智能/高性能计算服务器采用的热量解决方案必须比目前的空气冷却更加高效。
展望已经到来的AI爆发的时代,ChatGPT的需求日益增长,不仅推高了服务器的销量,而且还推动新技术通过大规模部署而被普遍接纳的机会。GPT提供的服务包括语言翻译、聊天机器人、内容生成、语言分析、语音辅助等等。
要实现人工智能系统的所有关键技术,就需要足够快速的服务器,并通过复杂的架构、用于维护工作的液冷管布置等将其联网。这些专业技术知识意味着解决方案将不再作为一个个的服务器提供。完整的解决方案部署更像是一个具有机架级就绪水平的即插即用解决方案。
Supermicro将ChatGPT视为服务器市场增长的关键驱动力,未来我们会看到GPT服务的更多创新型用例。Supermicro已准备好面对这个趋势,始终保持在AI服务器技术前沿,并提供创新的解决方案,使得客户能够加速他们的AI应用规划,同时优化总体拥有成本并通过绿色计算最大限度地减少对环境的影响。
-
服务器
+关注
关注
12文章
9237浏览量
85666 -
AI
+关注
关注
87文章
31155浏览量
269488 -
Supermicro
+关注
关注
0文章
29浏览量
9329
发布评论请先 登录
相关推荐
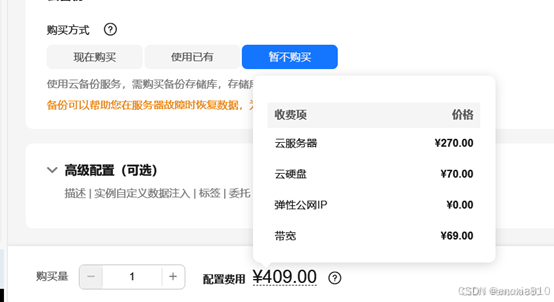
华为云征文 云计算新纪元:Flexus 云服务器 X 实例引领柔性算力时代,部署 Zabbix 运维监控
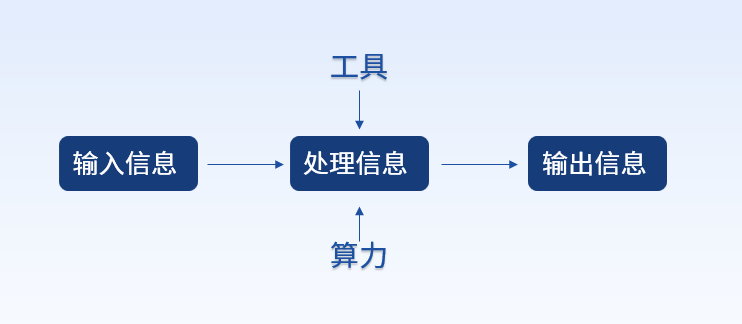
算力基础篇:从零开始了解算力
中科曙光入选2024算力服务产业图谱及算力服务产品名录
算力服务器为什么选择GPU

AI高算力服务器散热,需要用到哪些导热界面材料?

引领柔性算力新风潮,加速企业数智转型首选服务器就是它
智能算力存在缺口,AI服务器市场规模持续提升
算力十问:超算智算,通算及算存比
解锁未来,华为云耀云服务器 X 实例引领柔性算力新时代

华为中国合作伙伴大会2024 | 软通动力全面布局算力服务







 工商网监
工商网监
评论