 深度学习基础知识(4)
深度学习基础知识(4)
神经网络的学习:从训练数据中自动获取最优权重的过程,是使损失函数的值最小的权重参数。
机器学习做手写数据识别:从图像中提取特征量,再用机器学习技术学习这些特征量的模式。 图像的特征量通常表示为向量的形式,机器视觉领域常用的特征量包括SIFT、SURF和HOG等。 对转换后的向量使用机器学习中的SVM、KNN等分类器进行学习。
深度学习直接学习图像本身,特征量也是由机器来学习的。 它的优点是对所有问题都可以用同样的流程来解决。
1、训练数据和测试数据
机器学习中,一般将数据分为训练数据和测试数据。 首先使用训练数据进行学习,寻找最优的参数,然后使用测试数据评价模型。 为了正确评价模型的泛化能力,必须划分训练数据和测试数据。 泛化能力是指处理未被观察过的数据的能力。 获得泛化能力是机器学习的最终目标。 仅仅使用一个数据集去学习和评价参数,是无法正确评价的。 可能顺利处理某个数据集,但无法处理其他数据集的情况。 只对某个数据集过度拟合的状态称为过拟合,避免过拟合也是机器学习的一个重要课题。
2、损失函数
神经网络通过损失函数寻找最优权重参数。 损失函数是表示神经网络性能的恶劣程度的指标。
1)均方误差
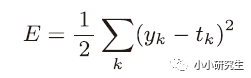
表示输出与训练数据的不匹配程度,希望得到最小的均方误差。
2)交叉熵误差

实际上只计算对应正确解标签的输出的自然对数。 交叉熵误差的值是由正确解标签所对应的输出结果决定的。 根据自然对数的图像,正确解标签对应的输出越大,交叉熵误差越接近0,当输出为1时,交叉熵误差为0。 使用代码实现时为了避免负无穷大需要添加一个微小值。
以上都是针对单个数据的损失函数,如果要求所有训练数据的损失函数的总和,需要写成下式

MNIST数据集的训练数据有60000个,如果求全部数据的损失函数和不太现实。 因此,需要从全部数据中选出一部分,神经网络的学习也是从训练数据中选出一部分(mini-batch)然后对每批数据进行学习。
从训练数据中随机抽取10笔数据的代码:
train_size=x_train.shape[0]
batch_size=10
batch_mask=np.random.choice(train_size,batch_size)
x_batch=x_train[batch_mask]
t_batch=t_train[batch_mask]
x_train形状为60000*784,所以train_size=60000。 使用np.random.choice()可以从指定的数字中随机选择想要的数字,在60000个数据中随机取10个数字。 后续只需要使用这个mini_batch计算损失函数。
3、mini_batch交叉熵误差的实现
def cross_entropy_error(y,t):
if y.dim==1:
t=t.reshape(1,t.size)
y=y.reshape(1,y.size)
batch_size=y.shape[0]
return -np.sum(t*np.log(y+1e-7))/batch_size
当y的维度为1,即求单个数据的交叉熵误差时,需要改变数据的形状变为1*60000,当输入为mini-batch时,需要用batch的个数进行归一化,计算单个数据的平均交叉熵误差。
return -np.sum(np.log(y[np.arange(batch_size),t]+1e-7))/batch_size
如果训练数据是标签形式,改为上述代码。 np.arange(batch_size)会生成一个0到batch_size-1的数组,因为t中的标签是以0-9数字的方式进行存储的,所以y[np.arange(batch_size),t]生成了一个二维数组。
4、为什么要设定损失函数
在神经网络的学习中,寻找最优权重和偏置时,要寻找使损失函数的值尽可能小的参数,需要计算梯度并更新参数。 如果用识别精度作为指标,绝大多数地方的导数都会变为0导致参数无法更新。 因为识别精度的概念是在训练数据中正确识别的数量,稍微改变权重的值识别精度可能无法变化,即使变化也是离散的值。 阶跃函数不能作为激活函数的原因也是这样,对微小变化不敏感,且变化是不连续的。
-
神经网络
+关注
关注
42文章
4771浏览量
100753 -
函数
+关注
关注
3文章
4331浏览量
62593 -
SVM
+关注
关注
0文章
154浏览量
32457 -
机器学习
+关注
关注
66文章
8416浏览量
132619 -
深度学习
+关注
关注
73文章
5503浏览量
121152
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论