 如何评估CPU硬件效率?CPU硬件运行效率介绍
如何评估CPU硬件效率?CPU硬件运行效率介绍
提到CPU性能,大部分同学想到的都是CPU利用率,这个指标确实应该首先被关注。但是除了利用率之外,还有很容易被人忽视的指标,就是指令的运行效率。如果运行效率不高,那CPU利用率再忙也都是瞎忙,产出并不高。
这就好比人,每天都是很忙,但其实每天的效率并不一样。有的时候一天干了很多事情,但有的时候只是瞎忙了一天,回头一看,啥也没干!
一、CPU 硬件运行效率
那啥是CPU的运行效率呢?介绍这个之前我们得先来简单回顾下CPU的构成和工作原理。CPU在生产过程结束后,在硬件上就被***刻成了各种各样的模块。
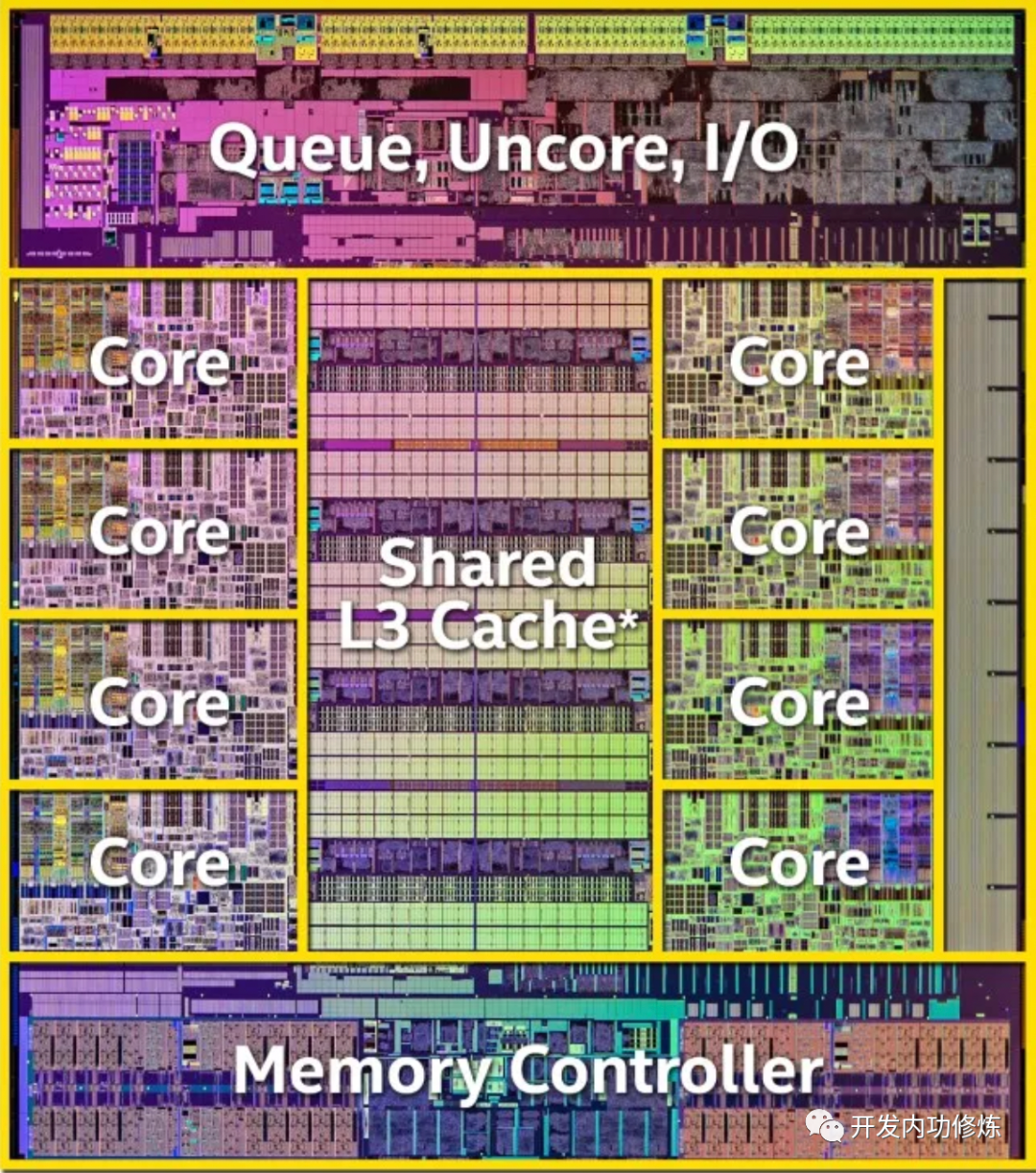
在上面的物理结构图中,可以看到每个物理核和L3 Cache的分布情况。另外就是在每个物理核中,还包括了更多组件。每个核都会集成自己独占使用的寄存器和缓存,其中缓存包括L1 data、L1 code 和L2。
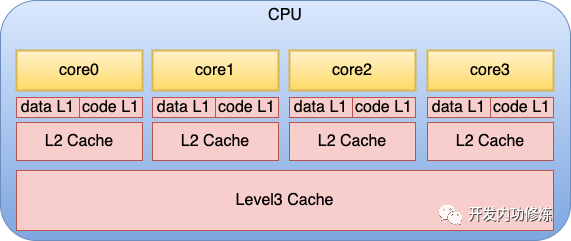
服务程序在运行的过程中,就是CPU核不断地从存储中获取要执行的指令,以及需要运算的数据。这里所谓的存储包括寄存器、L1 data缓存、L1 code缓存、L2 缓存、L3缓存,以及内存。 当一个服务程序被启动的时候,它会通过缺页中断的方式被加载到内存中。当 CPU 运行服务时,它不断从内存读取指令和数据,进行计算处理,然后将结果再写回内存。
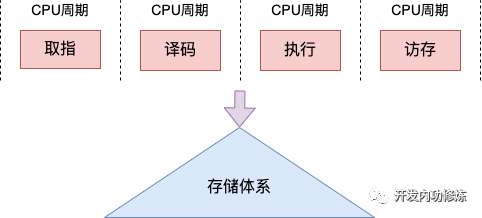
不同的 CPU 流水线不同。在经典的 CPU 的流水线中,每个指令周期通常包括取指、译码、执行和访存几个阶段。
在取指阶段,CPU 从内存中取出指令,将其加载到指令寄存器中。
在译码阶段,CPU 解码指令,确定要执行的操作类型,并将操作数加载到寄存器中。
在执行阶段,CPU 执行指令,并将结果存储在寄存器中。
在访存阶段,CPU 根据需要将数据从内存写入寄存器中,或将寄存器中的数据写回内存。
但,内存的访问速度是非常慢的。CPU一个指令周期一般只是零点几个纳秒,但是对于内存来说,即使是最快的顺序 IO,那也得 10 纳秒左右,如果碰上随机IO,那就是 30-40 纳秒左右的开销。
所以CPU为了加速运算,自建了临时数据存储仓库。就是我们上面提到的各种缓存,包括每个核都有的寄存器、L1 data、L1 code 和L2缓存,也包括整个CPU共享的L3,还包括专门用于虚拟内存到物理内存地址转换的TLB缓存。
拿最快的寄存器来说,耗时大约是零点几纳秒,和CPU就工作在一个节奏下了。再往下的L1大约延迟在 2 ns 左右,L2大约 4 ns 左右,依次上涨。
但速度比较慢的存储也有个好处,离CPU核更远,可以把容量做到更大。所以CPU访问的存储在逻辑上是一个金字塔的结构。越靠近金字塔尖的存储,其访问速度越快,但容量比较小。越往下虽然速度略慢,但是存储体积更大。
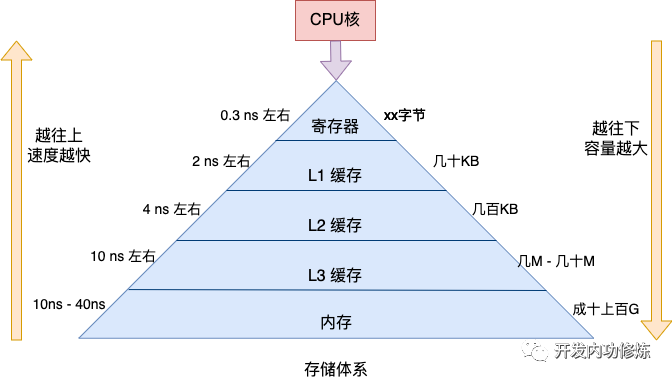
基本原理就介绍这么多。现在我们开始思考指令运行效率。根据上述金字塔图我们可以很清楚地看到,如果服务程序运行时所需要的指令存储都位于金字塔上方的话,那服务运行的效率就高。如果程序写的不好,或者内核频繁地把进程在不同的物理核之间迁移(不同核的L1和L2等缓存不是共享的),那上方的缓存就会命中率变低,更多的请求穿透到L3,甚至是更下方的内存中访问,程序的运行效率就会变差。
那如何衡量指令运行效率呢?指标主要有以下两类
第一类是CPI和IPC。
CPI全称是cycle per instruction,指的是平均每条指令的时钟周期个数。IPC的全称是instruction per cycle,表示每时钟周期运行多少个指令。这两个指标可以帮助我们分析我们的可执行程序运行的快还是慢。由于这二位互为倒数,所以实践中只关注一个CPI就够了。
CPI 指标可以让我们从整体上对程序的运行速度有一个把握。假如我们的程序运行缓存命中率高,大部分数据都在缓存中能访问到,那 CPI 就会比较的低。假如说我们的程序的局部性原理把握的不好,或者是说内核的调度算法有问题,那很有可能执行同样的指令就需要更多的CPU周期,程序的性能也会表现的比较的差,CPI 指标也会偏高。
第二类是缓存命中率。
缓存命中率指标分析的是程序运行时读取数据时有多少没有被缓存兜住,而穿透访问到内存中了。穿透到内存中访问速度会慢很多。所以程序运行时的 Cachemiss 指标就是越低越好了。
二、如何评估CPU硬件效率
上一小节我们说到CPU硬件工作效率的指标主要有 CPI 和缓存命中率。那么我们该如何获取这些指标呢?
2.1 使用 perf 工具
第一个办法是采用 Linux 默认自带的 perf 工具。使用 perf list 可以查看当前系统上支持的硬件事件指标。
#perflisthwcache Listofpre-definedevents(tobeusedin-e): branch-instructionsORbranches[Hardwareevent] branch-misses[Hardwareevent] bus-cycles[Hardwareevent] cache-misses[Hardwareevent] cache-references[Hardwareevent] cpu-cyclesORcycles[Hardwareevent] instructions[Hardwareevent] ref-cycles[Hardwareevent] L1-dcache-load-misses[Hardwarecacheevent] L1-dcache-loads[Hardwarecacheevent] L1-dcache-stores[Hardwarecacheevent] L1-icache-load-misses[Hardwarecacheevent] branch-load-misses[Hardwarecacheevent] branch-loads[Hardwarecacheevent] dTLB-load-misses[Hardwarecacheevent] dTLB-loads[Hardwarecacheevent] dTLB-store-misses[Hardwarecacheevent] dTLB-stores[Hardwarecacheevent] iTLB-load-misses[Hardwarecacheevent] iTLB-loads[Hardwarecacheevent]
上述输出中我们挑几个重要的来解释一下
cpu-cycles: 消耗的CPU周期
instructions: 执行的指令计数,结合cpu-cycles可以计算出CPI(每条指令需要消耗的平均周期数)
L1-dcache-loads: 一级数据缓存读取次数
L1-dcache-load-missed: 一级数据缓存读取失败次数,结合L1-dcache-loads可以计算出L1级数据缓存命中率
dTLB-loads:dTLB缓存读取次数
dTLB-load-misses:dTLB缓存读取失败次数,结合dTLB-loads同样可以算出缓存命中率
使用 perf stat 命令可以统计当前系统或者指定进程的上面这些指标。直接使用 perf stat 可以统计到CPI。(如果要统计指定进程的话只需要多个 -p 参数,写名 pid 就可以了)
#perfstatsleep5 Performancecounterstatsfor'sleep5': ...... 1,758,466cycles#2.575GHz 871,474instructions#0.50insnpercycle
从上述结果 instructions 后面的注释可以看出,当前系统的 IPC 指标是 0.50,也就是说平均一个 CPU 周期可以执行 0.5 个指令。前面我们说过 CPI 和 IPC 互为倒数,所以 1/0.5 我们可以计算出 CPI 指标为 2。也就是说平均一个指令需要消耗 2 个CPU周期。
我们再来看看 L1 和 dTLB 的缓存命中率情况,这次需要在 perf stat 后面跟上 -e 选项来指定要观测的指标了,因为这几个指标默认都不输出。
#perfstat-eL1-dcache-load-misses,L1-dcache-loads,dTLB-load-misses,dTLB-loadssleep5 Performancecounterstatsfor'sleep5': 22,578L1-dcache-load-misses#10.22%ofallL1-dcacheaccesses 220,911L1-dcache-loads 2,101dTLB-load-misses#0.95%ofalldTLBcacheaccesses 220,911dTLB-loads
上述结果中 L1-dcache-load-misses 次数为22,578,总的 L1-dcache-loads 为 220,911。可以算出 L1-dcache 的缓存访问失败率大约是 10.22%。同理我们可以算出 dTLB cache 的访问失败率是 0.95。这两个指标虽然已经不高了,但是实践中仍然是越低越好。
2.2 直接使用内核提供的系统调用
虽然 perf 给我们提供了非常方便的用法。但是在某些业务场景中,你可能仍然需要自己编程实现数据的获取。这时候就只能绕开 perf 直接使用内核提供的系统调用来获取这些硬件指标了。
开发步骤大概包含这么两个步骤
第一步:调用 perf_event_open 创建 perf 文件描述符
第二步:定时 read 读取 perf 文件描述符获取数据
其核心代码大概如下。为了避免干扰,我只保留了主干。
intmain()
{
//第一步:创建perf文件描述符
structperf_event_attrattr;
attr.type=PERF_TYPE_HARDWARE;//表示监测硬件
attr.config=PERF_COUNT_HW_INSTRUCTIONS;//标志监测指令数
//第一个参数pid=0表示只检测当前进程
//第二个参数cpu=-1表示检测所有cpu核
intfd=perf_event_open(&attr,0,-1,-1,0);
//第二步:定时获取指标计数
while(1)
{
read(fd,&instructions,sizeof(instructions));
...
}
}
在源码中首先声明了一个创建 perf 文件所需要的 perf_event_attr 参数对象。这个对象中 type 设置为 PERF_TYPE_HARDWARE 表示监测硬件事件。config 设置为 PERF_COUNT_HW_INSTRUCTIONS 表示要监测指令数。
然后调用 perf_event_open系统调用。在该系统调用中,除了 perf_event_attr 对象外,pid 和 cpu 这两个参数也是非常的关键。其中 pid 为 -1 表示要监测所有进程,为 0 表示监测当前进程,> 0 表示要监测指定 pid 的进程。对于 cpu 来说。-1 表示要监测所有的核,其它值表示只监测指定的核。
内核在分配到 perf_event 以后,会返回一个文件句柄fd。后面这个perf_event结构可以通过read/write/ioctl/mmap通用文件接口来操作。
perf_event 编程有两种使用方法,分别是计数和采样。本文中的例子是最简单的技术。对于采样场景,支持的功能更丰富,可以获取调用栈,进而渲染出火焰图等更高级的功能。这种情况下就不能使用简单的 read ,需要给 perf_event 分配 ringbuffer 空间,然后通过mmap系统调用来读取了。在 perf 中对应的功能是 perf record/report 功能。
将完整的源码编译运行后。
#gccmain.c-omain #./main instructions=1799 instructions=112654 instructions=123078 instructions=133505 ...
三、perf内部工作原理
你以为看到这里本文就结束了?大错特错!只讲用法不讲原理从来不是咱们开发内功修炼公众号的风格。
所以介绍完如何获取硬件指标后,咱们接下来也会展开聊聊上层的软件是如何和CPU硬件协同来获取到底层的指令数、缓存命中率等指标的。展开聊聊底层原理。
CPU的硬件开发者们也想到了软件同学们会有统计观察硬件指标的需求。所以在硬件设计的时候,加了一类专用的寄存器,专门用于系统性能监视。关于这部分的描述参见Intel官方手册的第18节。这个手册你在网上可以搜到,我也会把它丢到我的读者群里,还没进群的同学加我微信 zhangyanfei748527。
这类寄存器的名字叫硬件性能计数器(PMC: Performance Monitoring Counter)。每个PMC寄存器都包含一个计数器和一个事件选择器,计数器用于存储事件发生的次数,事件选择器用于确定所要计数的事件类型。例如,可以使用PMC寄存器来统计 L1 缓存命中率或指令执行周期数等。当CPU执行到 PMC 寄存器所指定的事件时,硬件会自动对计数器加1,而不会对程序的正常执行造成任何干扰。
有了底层的支持,上层的 Linux 内核就可以通过读取这些 PMC 寄存器的值来获取想要观察的指标了。整体的工作流程图如下
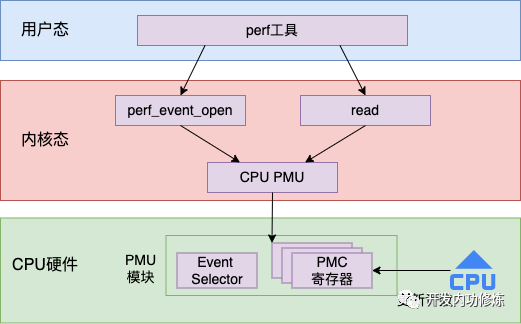
接下来我们再从源码的视角展开看一下这个过程。
3.1 CPU PMU 的初始化
Linux 的 PMU (Performance Monitoring Unit)子系统是一种用于监视和分析系统性能的机制。它将每一种要观察的指标都定义为了一个 PMU,通过 perf_pmu_register 函数来注册到系统中。
其中对于 CPU 来说,定义了一个针对 x86 架构 CPU 的 PMU,并在开机启动的时候就会注册到系统中。
//file:arch/x86/events/core.c
staticstructpmupmu={
.pmu_enable=x86_pmu_enable,
.read=x86_pmu_read,
...
}
staticint__initinit_hw_perf_events(void)
{
...
err=perf_pmu_register(&pmu,"cpu",PERF_TYPE_RAW);
}
3.2 perf_event_open 系统调用
在前面的实例代码中,我们看到是通过 perf_event_open 系统调用来创建了一个 perf 文件。我们来看下这个创建过程都做了啥?
//file:kernel/events/core.c
SYSCALL_DEFINE5(perf_event_open,
structperf_event_attr__user*,attr_uptr,
pid_t,pid,int,cpu,int,group_fd,unsignedlong,flags)
{
...
//1.为调用者申请新文件句柄
event_fd=get_unused_fd_flags(f_flags);
...
//2.根据用户参数attr,定位pmu对象,通过pmu初始化event
event=perf_event_alloc(&attr,cpu,task,group_leader,NULL,
NULL,NULL,cgroup_fd);
pmu=event->pmu;
//3.创建perf_event_contextctx对象,ctx保存了事件上下文的各种信息
ctx=find_get_context(pmu,task,event);
//4.创建一个文件,指定perf类型文件的操作函数为perf_fops
event_file=anon_inode_getfile("[perf_event]",&perf_fops,event,
f_flags);
//5.把event安装到ctx中
perf_install_in_context(ctx,event,event->cpu);
fd_install(event_fd,event_file);
returnevent_fd;
}
上面的代码是 perf_event_open 的核心源码。其中最关键的是 perf_event_alloc 的调用。在这个函数中,根据用户传入的 attr 来查找 pmu 对象。回忆本文的实例代码,我们指定的是要监测CPU硬件中的指令数。
structperf_event_attrattr; attr.type=PERF_TYPE_HARDWARE;//表示监测硬件 attr.config=PERF_COUNT_HW_INSTRUCTIONS;//标志监测指令数
所以这里就会定位到我们3.1节提到的 CPU PMU 对象,并用这个 pmu 初始化 新event。接着再调用 anon_inode_getfile 创建一个真正的文件对象,并指定该文件的操作方法是 perf_fops。perf_fops 定义的操作函数如下:
//file:kernel/events/core.c staticconststructfile_operationsperf_fops={ ... .read=perf_read, .unlocked_ioctl=perf_ioctl, .mmap=perf_mmap, };
在创建完 perf 内核对象后。还会触发在perf_pmu_enable,经过一系列的调用,最终会指定要监测的寄存器。
perf_pmu_enable ->pmu_enable ->x86_pmu_enable ->x86_assign_hw_event
//file:arch/x86/events/core.c
staticinlinevoidx86_assign_hw_event(structperf_event*event,
structcpu_hw_events*cpuc,inti)
{
structhw_perf_event*hwc=&event->hw;
...
if(hwc->idx==INTEL_PMC_IDX_FIXED_BTS){
hwc->config_base=0;
hwc->event_base=0;
}elseif(hwc->idx>=INTEL_PMC_IDX_FIXED){
hwc->config_base=MSR_ARCH_PERFMON_FIXED_CTR_CTRL;
hwc->event_base=MSR_ARCH_PERFMON_FIXED_CTR0+(hwc->idx-INTEL_PMC_IDX_FIXED);
hwc->event_base_rdpmc=(hwc->idx-INTEL_PMC_IDX_FIXED)|1<<30;
} else {
hwc->config_base=x86_pmu_config_addr(hwc->idx);
hwc->event_base=x86_pmu_event_addr(hwc->idx);
hwc->event_base_rdpmc=x86_pmu_rdpmc_index(hwc->idx);
}
}
3.3 read 读取计数
在实例代码的第二步中,就是定时调用 read 系统调用来读取指标计数。在 3.2 节中我们看到了新创建出来的 perf 文件对象在内核中的操作方法是 perf_read。
//file:kernel/events/core.c
staticconststructfile_operationsperf_fops={
...
.read=perf_read,
.unlocked_ioctl=perf_ioctl,
.mmap=perf_mmap,
};
perf_read 函数实际上支持可以同时读取多个指标出来。但为了描述起来简单,我只描述其读取一个指标时的工作流程。其调用链如下:
perf_read __perf_read perf_read_one __perf_event_read_value perf_event_read __perf_event_read_cpu perf_event_count
其中在 perf_event_read 中是要读取硬件寄存器中的值。
staticintperf_event_read(structperf_event*event,boolgroup)
{
enumperf_event_statestate=READ_ONCE(event->state);
intevent_cpu,ret=0;
...
again:
//如果event正在运行尝试更新最新的数据
if(state==PERF_EVENT_STATE_ACTIVE){
...
data=(structperf_read_data){
.event=event,
.group=group,
.ret=0,
};
(void)smp_call_function_single(event_cpu,__perf_event_read,&data,1);
preempt_enable();
ret=data.ret;
}elseif(state==PERF_EVENT_STATE_INACTIVE){
...
}
returnret;
}
smp_call_function_single 这个函数是要在指定的 CPU 上运行某个函数。因为寄存器都是 CPU 专属的,所以读取寄存器应该要指定 CPU 核。要运行的函数就是其参数中指定的 __perf_event_read。在这个函数中,真正读取了 x86 CPU 硬件寄存器。
__perf_event_read ->x86_pmu_read ->intel_pmu_read_event ->x86_perf_event_update
其中 __perf_event_read 调用到 x86 架构这块是通过函数指针指过来的。
//file:kernel/events/core.c
staticvoid__perf_event_read(void*info)
{
...
pmu->read(event);
}
在3.1中我们介绍过CPU 的这个pmu,它的read函数指针是指向 x86_pmu_read的。
//file:arch/x86/events/core.c
staticstructpmupmu={
...
.read=x86_pmu_read,
}
这样就会执行到 x86_pmu_read,最后就会调用到 x86_perf_event_update。在 x86_perf_event_update 中调用 rdpmcl 汇编指令来获取寄存器中的值。
//file:arch/x86/events/core.c
u64x86_perf_event_update(structperf_event*event)
{
...
rdpmcl(hwc->event_base_rdpmc,new_raw_count);
returnnew_raw_count
}
最后返回到 perf_read_one 中会调用 copy_to_user 将值真正拷贝到用户空间中,这样我们的进程就读取到了寄存器中的硬件执行计数了。
//file:kernel/events/core.c
staticintperf_read_one(structperf_event*event,
u64read_format,char__user*buf)
{
values[n++]=__perf_event_read_value(event,&enabled,&running);
...
copy_to_user(buf,values,n*sizeof(u64))
returnn*sizeof(u64);
}
总结
虽然内存很快,但它的速度在 CPU 面前也只是个弟弟。所以 CPU 并不直接从内存中获取要运行的指令和数据,而是优先使用自己的缓存。只有缓存不命中的时候才会请求内存,性能也会变低。
那观察 CPU 使用缓存效率高不高的指标主要有 CPI 和缓存命中率几个指标。CPU 硬件在实现上,定义了专门 PMU 模块,其中包含专门用户计数的寄存器。当CPU执行到 PMC 寄存器所指定的事件时,硬件会自动对计数器加1,而不会对程序的正常执行造成任何干扰。有了底层的支持,上层的 Linux 内核就可以通过读取这些 PMC 寄存器的值来获取想要观察的指标了。
我们可以使用 perf 来观察,也可以直接使用内核提供的 perf_event_open 系统调用获取 perf 文件对象,然后自己来读取。
审核编辑:刘清
-
寄存器
+关注
关注
31文章
5390浏览量
121855 -
PMC
+关注
关注
0文章
89浏览量
15021 -
光刻机
+关注
关注
31文章
1159浏览量
47737 -
LINUX内核
+关注
关注
1文章
316浏览量
21850
发布评论请先 登录
相关推荐
硬件高手实战分享——提高系统效率的几个误解
龙芯1号CPU的网络计算机硬件系统设计
使用智能外设提高CPU效率

Intel Graphics上提高CPU效率的DX12
苹果A13 Bionic芯片的CPU和GPU评述,达到最高性能状态时的效率
cpu的程序是如何运行起来的
CPU工作过程——MCU

CPU利用率过高的原因是什么
信创基础硬件:CPU、GPU、存储和整机
CPU中的特殊指令可以加速编码效率
CPU的硬件运行效率






 工商网监
工商网监
评论