 一定要「分词」吗?Andrej Karpathy:是时候抛弃这个历史包袱了
一定要「分词」吗?Andrej Karpathy:是时候抛弃这个历史包袱了
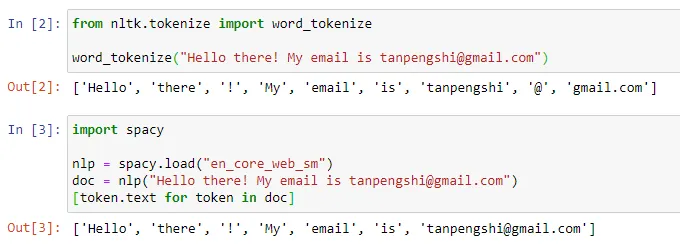
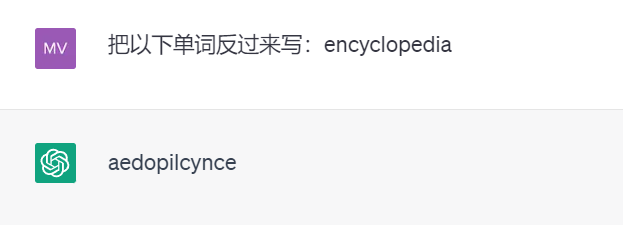
是时候抛弃 tokenization 了?ChatGPT 等对话 AI 的出现让人们习惯了这样一件事情:输入一段文本、代码或一张图片,对话机器人就能给出你想要的答案。但在这种简单的交互方式背后,AI 模型要进行非常复杂的数据处理和运算,tokenization 就是比较常见的一种。 在自然语言处理领域,tokenization 指的是将文本输入分割成更小的单元,称为「token」。这些 token 可以是词、子词或字符,取决于具体的分词策略和任务需求。例如,如果对句子「我喜欢吃苹果」执行 tokenization 操作,我们将得到一串 token 序列:["我", "喜欢", "吃", "苹果"]。有人将 tokenization 翻译成「分词」,但也有人认为这种翻译会引起误导,毕竟分割后的 token 未必是我们日常所理解的「词」。


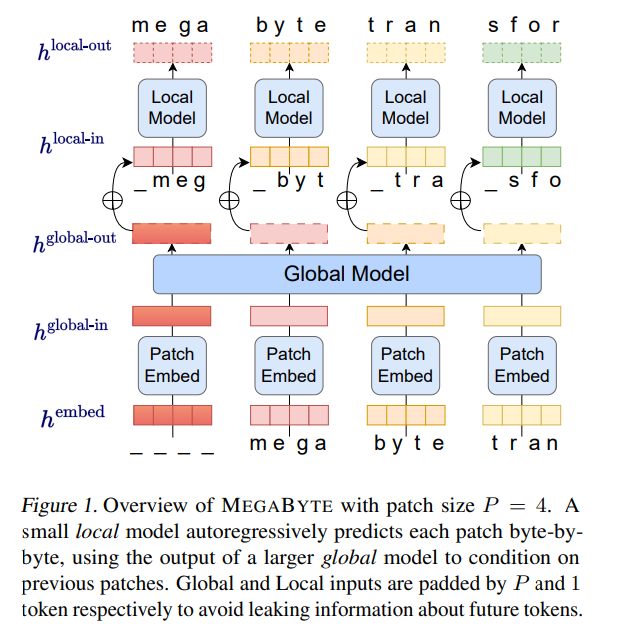
- patch 嵌入器,它通过无损地连接每个字节的嵌入来简单地编码 patch;
- 全局模块 —— 带有输入和输出 patch 表征的大型自回归 transformer;
- 局部模块 —— 一个小型自回归模型,可预测 patch 中的字节。
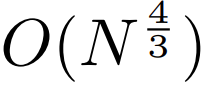 ,即使是长序列也能易于处理。
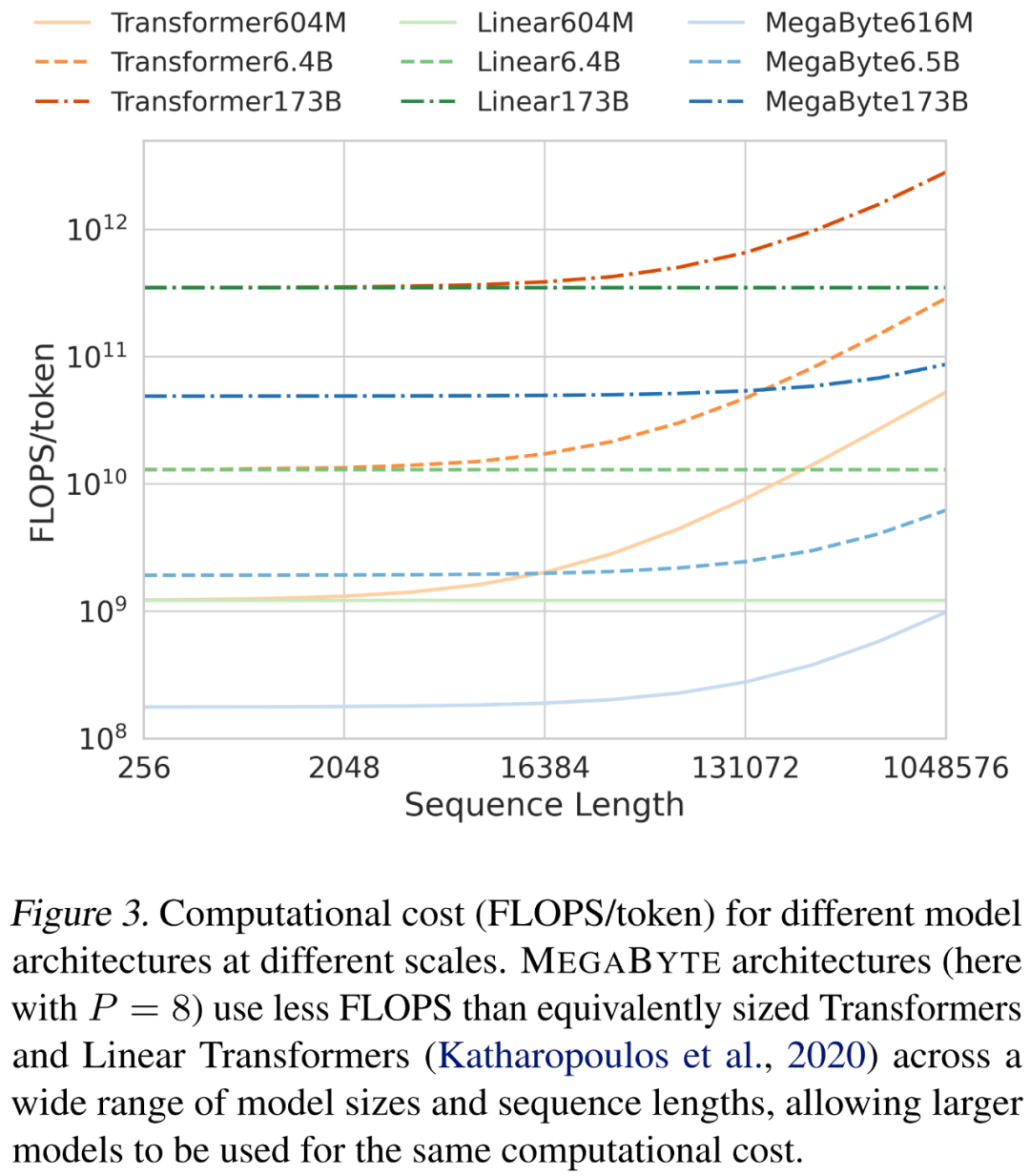
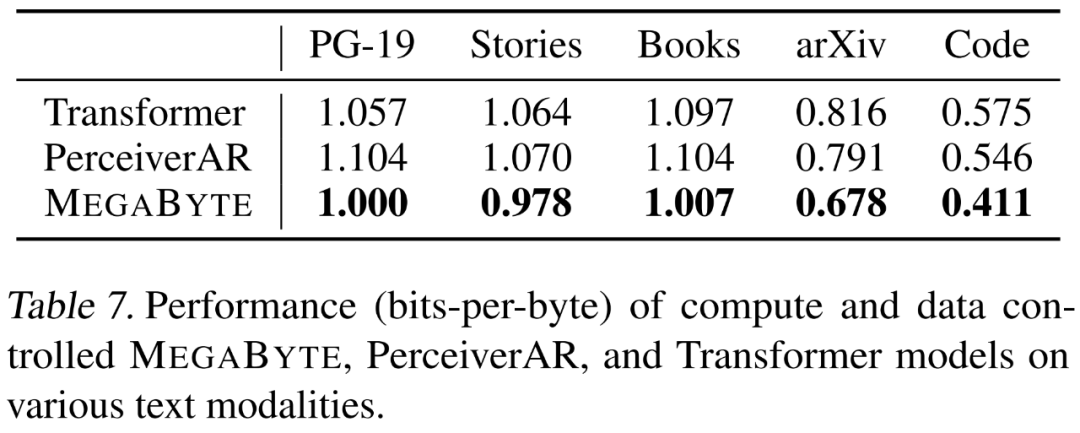
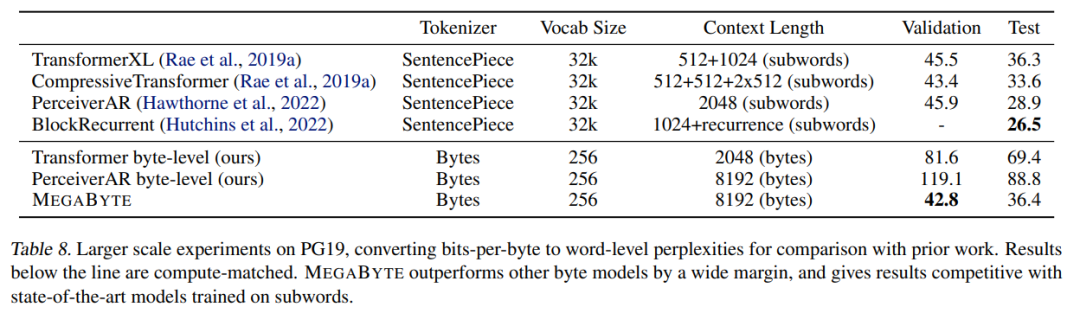
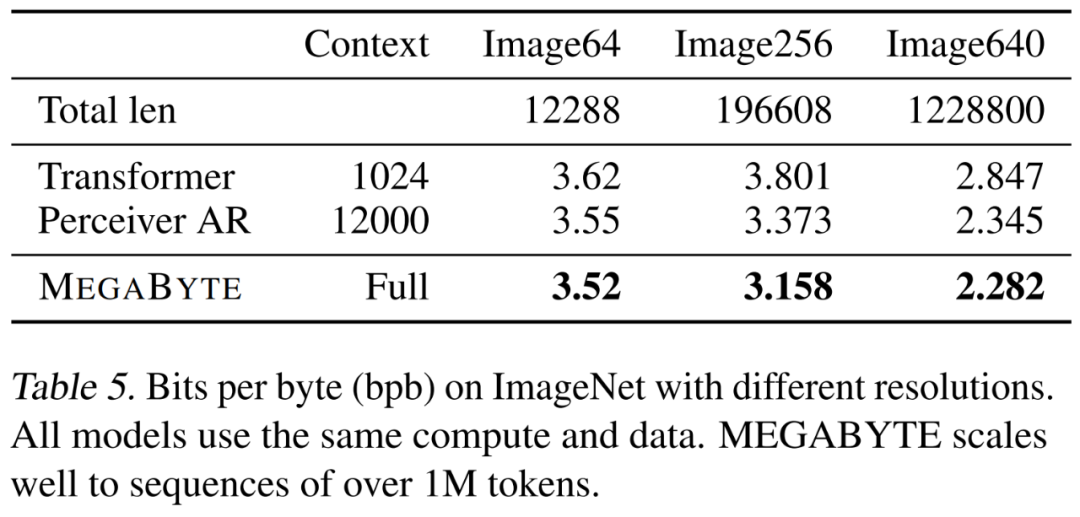
,即使是长序列也能易于处理。2. per-patch 前馈层。在 GPT-3 等超大模型中,超过 98% 的 FLOPS 用于计算 position-wise 前馈层。MEGABYTE 通过给 per-patch(而不是 per-position)使用大型前馈层,在相同的成本下实现了更大、更具表现力的模型。在 patch 大小为 P 的情况下,基线 transformer 将使用具有 m 个参数的相同前馈层 P 次,而 MEGABYTE 仅需以相同的成本使用具有 mP 个参数的层一次。 3. 并行解码。transformer 必须在生成期间串行执行所有计算,因为每个时间步的输入是前一个时间步的输出。通过并行生成 patch 的表征,MEGABYTE 在生成过程中实现了更大的并行性。例如,具有 1.5B 参数的 MEGABYTE 模型生成序列的速度比标准的 350M 参数 transformer 快 40%,同时在使用相同的计算进行训练时还改善了困惑度(perplexity)。 总的来说,MEGABYTE 让我们能够以相同的计算预算训练更大、性能更好的模型,将能够处理非常长的序列,并提高部署期间的生成速度。 MEGABYTE 还与现有的自回归模型形成鲜明对比,后者通常使用某种形式的 tokenization,其中字节序列被映射成更大的离散 token(Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2021) 。tokenization 使预处理、多模态建模和迁移到新领域变得复杂,同时隐藏了模型中有用的结构。这意味着大多数 SOTA 模型并不是真正的端到端模型。最广泛使用的 tokenization 方法需要使用特定于语言的启发式方法(Radford et al., 2019)或丢失信息(Ramesh et al., 2021)。因此,用高效和高性能的字节模型代替 tokenization 将具有许多优势。 该研究对 MEGABYTE 和一些强大的基线模型进行了实验。实验结果表明,MEGABYTE 在长上下文语言建模上的性能可与子词模型媲美,并在 ImageNet 上实现了 SOTA 的密度估计困惑度,并允许从原始音频文件进行音频建模。这些实验结果证明了大规模无 tokenization 自回归序列建模的可行性。 MEGABYTE 主要组成部分

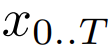 映射成一个长度为
映射成一个长度为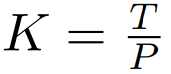 、维度为
、维度为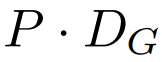 的 patch 嵌入序列。
的 patch 嵌入序列。
首先,每个字节都嵌入了一个查找表
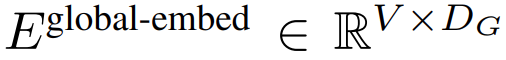 ,形成一个大小为 D_G 的嵌入,并添加了位置嵌入。
,形成一个大小为 D_G 的嵌入,并添加了位置嵌入。
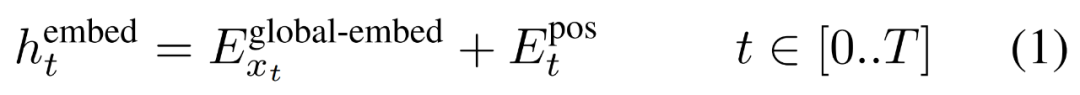
然后,字节嵌入被重塑成维度为
的 K 个 patch 嵌入的序列。为了允许自回归建模,该 patch 序列被填充以从可训练的 patch 大小的填充嵌入(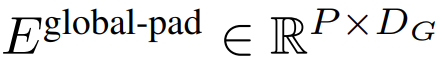 ),然后从输入中移除最后一个 patch。该序列是全局模型的输入,表示为
),然后从输入中移除最后一个 patch。该序列是全局模型的输入,表示为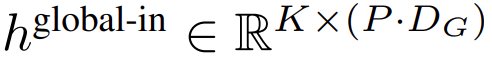 。
。
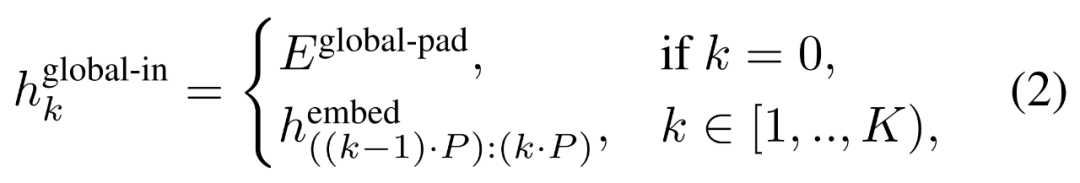
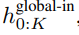 ,并通过对先前 patch 执行自注意力来输出更新的表示
,并通过对先前 patch 执行自注意力来输出更新的表示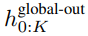 。
。
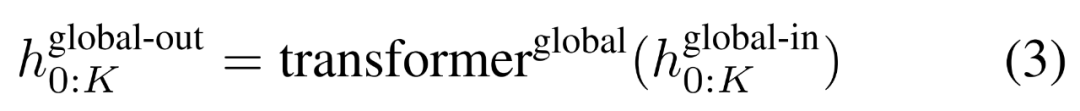
最终全局模块的输出
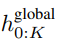 包含 P・D_G 维的 K 个 patch 表示。对于其中的每一个,研究者将它们重塑维长度为 P、维度为 D_G 的序列,其中位置 p 使用维度 p・D_G to (p + 1)・D_G。然后将每个位置映射到具有矩阵
包含 P・D_G 维的 K 个 patch 表示。对于其中的每一个,研究者将它们重塑维长度为 P、维度为 D_G 的序列,其中位置 p 使用维度 p・D_G to (p + 1)・D_G。然后将每个位置映射到具有矩阵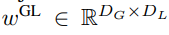 的局部模块维度,其中 D_L 为局部模块维度。接着将这些与大小为 D_L 的字节嵌入相结合,用于下一个
的局部模块维度,其中 D_L 为局部模块维度。接着将这些与大小为 D_L 的字节嵌入相结合,用于下一个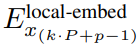 的 token。
的 token。局部字节嵌入通过可训练的局部填充嵌入(E^local-pad ∈ R^DL)偏移 1,从而允许在 path 中进行自回归建模。最终得到张量
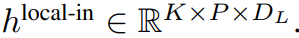
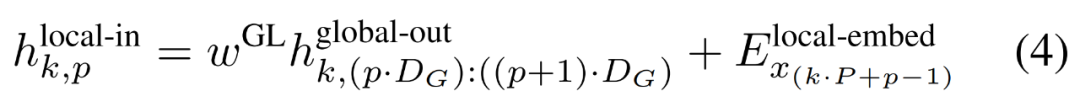
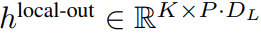 。
。

最后,研究者可以计算每个位置的词汇概率分布。第 k 个 patch 的第 p 个元素对应于完整序列的元素 t,其中 t = k・P + p。
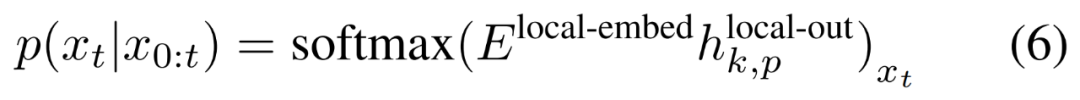
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
87文章
31054浏览量
269401 -
数据转换
+关注
关注
0文章
87浏览量
18013 -
模型
+关注
关注
1文章
3255浏览量
48906
原文标题:一定要「分词」吗?Andrej Karpathy:是时候抛弃这个历史包袱了
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
为什么第一盏灯一定要用0xfe,其他的灯也一定要用该数值才有效?
为什么第一盏灯一定要用0xfe,其他的灯也一定要用该数值才有效?因为接触这个时间不多,请你们尽量教会我啊 ,谢谢虽然你们都会说这很简单,但我还是不懂,请你们耐心指导
发表于 10-18 22:46
自然语言处理中的分词问题总结
的分词系统了,2-3 行代码就可以实现分词调用和词性标注,速度还不错。基于 HMM 模型实现,可以实现一定程度的未登录词识别。Jieba 有精确模式、全模式、搜索模式三种。全模式是找到
发表于 10-26 13:48
基于hanlp的es分词插件
摘要:elasticsearch是使用比较广泛的分布式搜索引擎,es提供了一个的单字分词工具,还有一个分词插件ik使用比较广泛,hanlp是
发表于 07-01 11:34
hanlp分词工具应用案例:商品图自动推荐功能的应用
怎么实现了。分析了一下解决方案步骤: 1、图库建设:至少要有图片吧,图片肯定要有关联的商品名称、商品类别、商品规格、关键字等信息。 2、商品分词
发表于 08-07 11:47
DSP和SDRAM之间的数据总线一定要加电阻吗
俺也是个初学者,对信号完整性了解不多。只是看到参考电路上,DSP和SDRAM之间的数据总线,地址总线中间都加了小电阻。感觉是信号完整性用的 。但是现在布线的时候,感觉比较麻烦,不如不加这个呢。所以,我想问一下。DSP(单片机)和
发表于 07-20 14:23
北大开源了一个中文分词工具包,名为——PKUSeg
多领域分词:不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。 我们目前支持了新闻领域,网
手机充电一定要充满吗
充电一定要在手机没电之前充电,也不能充满电,要充到一定电量就拔掉充电器,这样才能更好的保护手机的电池,不要等手机电量全部用没之后在充电,这个叫做深度放电,这样对手机的损害是非常大的,所以说小编请大家千万不要这么做。
在购买洗衣机的时候 一定要结合自身的实际需求
洗衣机的种类非常多,很多人在挑选的时候都会感到非常头疼,不知道要买哪种洗衣机更好,所以,我们在挑选之前一定要有自己的想法,多点学习相关的知识,这样才不会买到一些不实用的洗衣机,而且也不会白白浪费钱。
发表于 04-09 14:50
•431次阅读
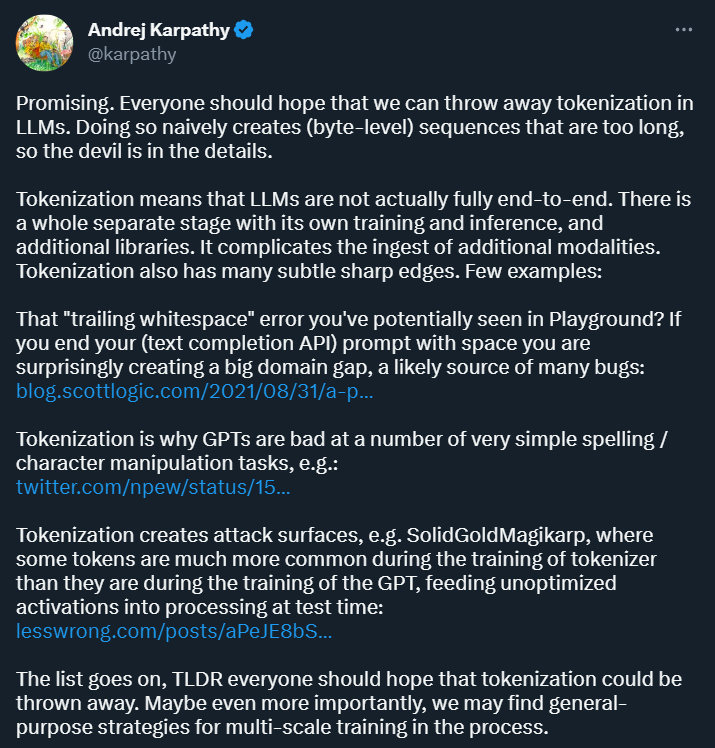
特斯拉前AI总监Andrej Karpathy:大模型有内存限制,这个妙招挺好用!
为了让大家更好的理解 Karpathy 的内容。我们先介绍一下「Speculative decoding」方法,对后续理解更加有益,其主要用于加速大模型的推理。据了解,GPT-4 泄密报告也提到了 OpenAI 线上模型推理使用了它(不确定是否 100%)。





 工商网监
工商网监
评论