 LLVM16的新增功能介绍
LLVM16的新增功能介绍
除了对今年架构的标准支持外,我们还完成了对可扩展矩阵扩展(SME和SME2)的汇编级支持。在CPU方面,此版本扩展了Armv9-A内核系列,支持我们的Cortex-A715和Cortex-X3 CPU。
A-profile 2022更新:Armv8.9-A和Armv9.4-A
现在,除了将在下一个LLVM版本中支持的保护调用堆栈(GCS)之外,所有扩展都可以进行汇编和反汇编。Arm C语言扩展(ACLE)也用两个新的内部函数__rsr128和__wsr128进行了扩展;这些使得新的128位系统寄存器更容易访问。LLVM现在支持这些内部函数。
转换加固扩展(THE)是Armv9.4-A的主要安全改进之一,也是虚拟内存系统体系结构(VMSA)的一部分。其目的是防止在攻击者获得内核权限的情况下对虚拟内存的转换表进行任意更改。新的读取-检查-写入(RCW)指令已添加到体系结构中,以允许在禁用普通写入的同时对此类表进行受控修改。
尽管这些指令是针对内核而非用户空间开发人员的,但RCW指令可以很好地映射到C++中128位数据类型上的各种原子操作。更具体地说,fetch_and、fetch_or和exchange可以直接用这些指令来实现。
这个功能对任何使用原子操作的人都很有用,所以我们在LLVM 16中添加了代码生成支持。在LRCPC3和LSE2扩展也可用的目标中,这些专用指令直接从C++代码生成,而不需要汇编或内部函数。
以下是std::atomic::fetch_and的示例:
#includestd::atomic<__uint128_t> global; void sink(__uint128_t); void ldclrpal_example(__uint128_t x) { __uint128_t res = global.fetch_and(x); sink(res); } void ldclrp_example(__uint128_t x) { __uint128_t res = global.fetch_and(x, std::memory_order_relaxed); sink(res); }
使用-march=armv9.4a+lse128+rcpc3-O3编译,生成的程序集显示正在生成的新指令:
ldclrpal_example(unsigned __int128):
mvn x1, x1
mvn x0, x0
adrp x8, global
add x8, x8, global
ldclrpal x0, x1, [x8]
b sink(unsigned __int128)
ldclrp_example(unsigned __int128):
mvn x1, x1
mvn x0, x0
adrp x8, global
add x8, x8, global
ldclrp x0, x1, [x8]
b sink(unsigned __int128)
多版本控制功能
如今,许多平台都有一个单一的二进制部署模型:每个应用程序都是通过一个二进制文件分发的。这使得开发人员很难针对多个体系结构功能。为了解决这个问题,LLVM 16提供了一种针对特定体系结构特征的方便方式,而不需要处理特征检测和其他细节。这个新功能被称为函数多版本控制。
提供了一个新的宏__HAVE_FUNCTION_MULTI_VERSIONING来检测功能的可用性。如果存在,我们可以要求编译器通过标记__attribute__((target_clones())来生成给定函数的多个版本。函数的最合适版本将在运行时调用。
在下面的示例中,一个函数被标记为要为Advanced SIMD(又名NEON)和SVE构建。如果SVE在目标上可用,则将使用SVE版本。
#ifdef __HAVE_FUNCTION_MULTI_VERSIONING
__attribute__((target_clones("sve", "simd")))
#endif
float foo(float *a, float *b) {
//
}
在某些情况下,开发人员希望为每个功能提供不同的代码。这也可以通过使用__attribute__((target_version()))来实现。在下面的例子中,我们为同一个函数提供了两个版本。同样,如果SVE可用,将调用SVE版本。宏__HAVE_FUNCTION_MULTI_VERSIONING允许编写与具有和不具有函数多版本控制的编译器兼容的代码。
#ifdef __HAVE_FUNCTION_MULTI_VERSIONING
__attribute__((target_version("sve")))
static void foo(void) {
printf("FMV uses SVE
");
}
#endif
// this attribute is optional
// __attribute__((target_version("default")))
static void foo(void) {
printf("FMV default
");
return;
}
此功能依赖于编译器rt(-rtlib=编译器rt),并且在默认情况下启用,但可以使用标志-mno fmv禁用它。请注意,函数多版本控制仍处于测试状态。ACLE规范非常欢迎通过打开新问题或创建pull请求来提供反馈。
性能改进
复数自动矢量化
LLVM 16包括对复数上的公共运算的自动矢量化的支持。这些分别利用了Armv8-A和Armv8-M体系结构的高级SIMD(Neon)和MVE指令集中可用的指令。例如,代码:
#include#define N 512 void fma (_Complex float a[restrict N], _Complex float b[restrict N], _Complex float c[restrict N]) { for (int i=0; i < N; i++) c[i] = a[i] * b[i]; }
输出以下汇编代码:
fma: // @fma mov x8, xzr .LBB0_1: // =>This Inner Loop Header: Depth=1 add x9, x0, x8 add x10, x1, x8 movi v2.2d, #0000000000000000 movi v3.2d, #0000000000000000 ldp q1, q0, [x9] add x9, x2, x8 add x8, x8, #32 cmp x8, #1, lsl #12 // =4096 ldp q5, q4, [x10] fcmla v3.4s, v1.4s, v5.4s, #0 fcmla v2.4s, v0.4s, v4.4s, #0 fcmla v3.4s, v1.4s, v5.4s, #90 fcmla v2.4s, v0.4s, v4.4s, #90 stp q3, q2, [x9] b.ne .LBB0_1 ret
请注意FCMLA指令的使用,该指令对复数向量执行融合乘加向量运算和可选的复数旋转。
默认启用功能专业化和SPEC2017内部改进
在为速度进行优化时,默认情况下在所有优化级别都启用了功能的专业化。通行证的优化启发式和编译时属性已经得到了改进,并且被认为通常足够有益,可以默认启用。
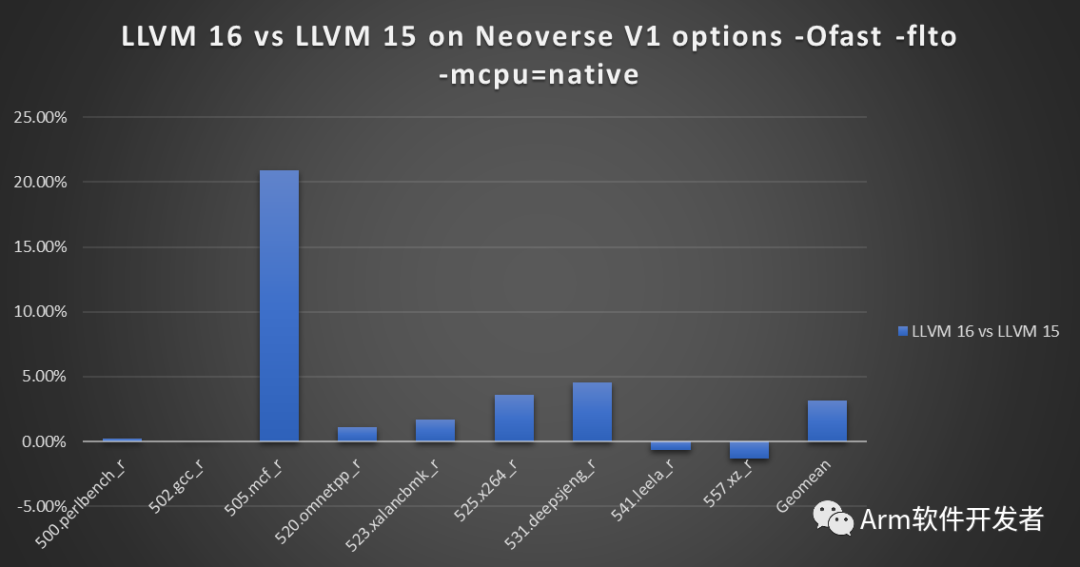
这种优化在各种AArch64平台上特别将SPEC2017 intrate中的505.mcf_r基准提高了约10%。这有助于将SPEC2017年intrate C/C++基准在AArch64提高3%。
请注意,SPEC2017性能提升还得益于SelectOpt通道和其他高级模式识别的默认调整和启用。
SVE和自动矢量化的改进
SVE的自动矢量化一直是一个非常活跃的发展领域。例如,到目前为止,在条件的不同分支中访问的指针的矢量化是非常基本的:大多数时候,它会被计算为成本太高。现在,指针上的基本运算包含在矢量器的成本模型中。这意味着现在可以在更好的情况下对以下代码进行矢量化:
void foo(float *dst, float *src, int *cond, long disp) {
for (long i=0; i<1024; i++) {
if (cond[i] != 0) {
dst[i] = src[i];
} else {
dst[i] = src[i+disp];
}
}
}
也就是说,在合成示例中,找到合适的环境以使矢量化有利可图是很棘手的,并且生成的代码非常长。如果你想看看矢量化的代码是什么样子的,你可以调整成本模型。使用-march=v9a-O3-Rpass=loop vectorize-mllvm-force target instruction cost=1编译前面的示例。
通过减少对显式合并操作的需求,尾部折叠循环的矢量化也得到了改进。例如,以下代码:
float foo(float *a, float *b) {
float sum = 0.0;
for (int i = 0; i < 1024; ++i)
sum += a[i] * b[i];
return sum;
}
用-march=armv9-a-Ofast-mllvm-sve tail folding=all编译,这表明现在发出了预测的FMLA:
.LLVM_15_LOOP:
ld1w { z2.s }, p1/z, [x0, x8, lsl #2]
ld1w { z3.s }, p1/z, [x1, x8, lsl #2]
add x8, x8, x10
fmul z2.s, z3.s, z2.s
sel z2.s, p1, z2.s, z0.s
whilelo p1.s, x8, x9
fadd z1.s, z1.s, z2.s
b.mi .LLVM_15_LOOP
.LLVM_16_LOOP:
ld1w { z1.s }, p1/z, [x0, x8, lsl #2]
ld1w { z2.s }, p1/z, [x1, x8, lsl #2]
add x8, x8, x10
fmla z0.s, p1/m, z2.s, z1.s
whilelo p1.s, x8, x9
b.mi .LLVM_16_LOOP
此外,通过减少对显式反向运算的需要,改进了具有反向迭代计数的循环的矢量化。以这个循环为例:
void foo(int *a, int *b, int* c) {
for (int i = 1024; i >= 0; --i) {
if (c[i] > 10)
a[i] = b[i] + 5;
}
}
使用-march=armv9-a-O3编译后,LLVM 16输出不再反转加载的数据,也不再反转用于条件的谓词:
.LLVM_15_LOOP:
ld1w { z0.s }, p0/z, [x16, x9, lsl #2]
ld1w { z1.s }, p0/z, [x17, x9, lsl #2]
rev z0.s, z0.s
rev z1.s, z1.s
cmpgt p1.s, p0/z, z0.s, #10
cmpgt p2.s, p0/z, z1.s, #10
rev p1.s, p1.s
rev p2.s, p2.s
ld1w { z0.s }, p1/z, [x14, x9, lsl #2]
ld1w { z1.s }, p2/z, [x15, x9, lsl #2]
add z0.s, z0.s, #5 // =0x5
add z1.s, z1.s, #5 // =0x5
st1w { z0.s }, p1, [x12, x9, lsl #2]
st1w { z1.s }, p2, [x13, x9, lsl #2]
sub x9, x9, x10
cmp x18, x9
b.ne .LLVM_15_LOOP
.LLVM_16_LOOP:
ld1w { z0.s }, p0/z, [x13, x9, lsl #2]
ld1w { z1.s }, p0/z, [x14, x9, lsl #2]
cmpgt p1.s, p0/z, z0.s, #10
cmpgt p2.s, p0/z, z1.s, #10
ld1w { z0.s }, p1/z, [x15, x9, lsl #2]
ld1w { z1.s }, p2/z, [x16, x9, lsl #2]
add z0.s, z0.s, #5 // =0x5
add z1.s, z1.s, #5 // =0x5
st1w { z0.s }, p1, [x17, x9, lsl #2]
st1w { z1.s }, p2, [x18, x9, lsl #2]
sub x9, x9, x10
cmp x12, x9
b.ne .LLVM_16_LOOP
LLVM 16上SVE的其他性能改进包括:
。DUP的使用在各种场景中都得到了极大的改进,尤其是对于128位LD1RQ变体。
。乘法-加法和乘法子指令可以更广泛地使用。
。对PTEST指令的需求已经大大减少。
。扩展循环负载消除现在是类型不可知的,因此可以检测更多的情况。
。SLP成本模型得到了改进。
Spec2017与Flang一起构建
去年12月,我们通过LLVM/Frang在O3上实现了所有Fortran速率基准测试的里程碑。主要关注点是启用四个失败的基准测试(521.wrf_r、527.cam4_r、549.fotonik3d_r、554.roms_r)。主要改进之一是通过使用复杂方言消除了对外部复杂数学库的依赖。
此外,通过改进前端和LLVM之间的信息共享,以及改进对快速数学的支持,还获得了一些性能。
您可以通过将-DLLVM_ENABLE_PROJECTS=“Flang;clang;mlir”传递给CMake来构建Flang。flang可执行文件称为flang-new;确保通过选项-flang实验exec来生成可执行文件。
Target-gated ACLE 内联
最初是由Highway库引发的,目标(“
现在支持的格式是:
。arch=
。cpu=
。tune=
。+<feature>,+no<feature>启用或禁用特定功能,以与GCC目标属性兼容。
。<feature>,no-<feature>启用或禁用特定功能,以便与以前的clang版本向后兼容。
随着上述变化,ACLE内部函数的实现也进行了修改,使其不再基于预处理器宏。相反,它们是基于当前目标启用的。这允许在单个函数中提供内部函数,而不需要为同一目标编译整个文件。以下示例说明了函数sve2_log上属性的使用:
#include#include void base_log(float *src, int *dst, int n) { for(int i = 0; i < n; i++) dst[i] = log2f(src[i]); } void __attribute__((target("sve2"))) sve2_log(float *src, int *dst, int n) { int i = 0; svbool_t p = svwhilelt_b32(i, n); while(svptest_any(svptrue_b32(), p)) { svfloat32_t d = svld1_f32(p, src+i); svint32_t l = svlogb_f32_z(p, d); svst1_s32(p, dst+i, l); i += svcntb(); p = svwhilelt_b32(i, n); } }
llvm objdump的改进
在LLVM 16中,Arm目标的LLVM objdump的输出在可读性和正确性方面得到了改进,使其成为基于LLVM的工具链上GNU objdump的更合适的替代品。
big-endian对象文件的反汇编现在可以正常工作。以前,每个指令字都被意外地进行了字节交换,并被分解为完全不同的东西。
此外,在反汇编中遇到的无法识别的指令会以更有用的方式进行处理。以前,反汇编程序只前进一个字节,然后从奇数地址重试。此策略在具有可变长度指令的体系结构上是有意义的,但在Arm上则不然。新的行为是推进整个指令,以便文件的其余部分可能会被正确地反汇编。
LLVM 16包括Arm架构的其他质量改进,包括Thumb与Arm反汇编的错误修复,以及现在包含正确字节的.byte指令。对指令编码进行了一些可读性改进,使Arm和32位Thumb更容易区分:现在您可以看到Arm指令有一个8位数字,Thumb有两个4位数字,中间有一个空格。
支持AArch64上的严格浮点
AArch64已经实现了严格的浮点语义。clang命令行选项-ffp model=strict现在在AArch64目标上被接受,而不是被忽略并发出警告。举个例子,只有在安全的情况下才执行FP除法:
float fn(int n, float x, float y) {
if (n == 0) {
x += 1;
} else {
x += y/n;
}
return x;
}
在LLVM 15上,使用-O2进行编译会生成以下代码:
fn(int, float, float): // @fn(int, float, float)
scvtf s3, w0
fmov s2, #1.00000000
cmp w0, #0
fdiv s1, s1, s3
fadd s1, s1, s0
fadd s0, s0, s2
fcsel s0, s1, s0, ne
ret
它将执行两个分支,包括除法,然后在fcsel中选择正确的结果。尽管保留了代码的功能,但当n=0时,它会导致伪FE_DIVBYZERO浮点异常。在LLVM 16上,使用-O2-ffp模型=严格编译会产生以下代码:
fn(int, float, float): // @fn(int, float, float)
cbz w0, .LBB0_2
scvtf s2, w0
fdiv s1, s1, s2
fadd s0, s0, s1
ret
.LBB0_2:
mov w8, #1
scvtf s1, w8
fadd s0, s0, s1
ret
其中两个不同的执行分支保持分离,从而防止FP异常的发生。
由于支持严格的FP,现在也接受了选项-frapping math和-frounding math。一方面,-ftrapping数学确保代码不会引入或删除任何类型的FP异常可能导致的副作用。其中包括软件可以通过检查FPSR异步检测到的异常。类似地,-founding数学避免应用假设特定FP舍入行为的优化。
在编译器rt和LLD中支持早期的Arm体系结构
LLD现在可以用作ARMv4和ARMv4T的链接器:它现在发出与ARMv4和ARMv4T兼容的thunk,而不是ARMv4的不兼容BX指令或ARMv4或ARMv4T的BLX指令。
与此相关的是,为ARMv4T、ARMv5TE和ARMv6添加了对编译器rt内置程序的支持,从而解锁了对这些体系结构的运行时支持。
由于这项启用工作,现在可以为这些32位Arm架构提供一个完整的基于LLVM的工具链。因此,Linux内核现在增加了对使用LLD构建Clang的支持,Rust程序不再需要依赖GNU链接器。
审核编辑:刘清
-
寄存器
+关注
关注
31文章
5337浏览量
120265 -
ARM处理器
+关注
关注
6文章
360浏览量
41726 -
编译器
+关注
关注
1文章
1624浏览量
49113 -
SIMD
+关注
关注
0文章
33浏览量
10289 -
GNU
+关注
关注
0文章
143浏览量
17492
原文标题:LLVM16的新增功能
文章出处:【微信号:Arm软件开发者,微信公众号:Arm软件开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenHarmony 3.0 LTS 新增特性功能
.NET Core 3.0(预览版 2)的新增功能是什么
在Swift中使用LLVM的四个要点

Vivado Design Suite 2015.3新增量编译功能介绍
Vivado Design Suite 2018.1设计套件中的新增功能介绍
iOS 16新增安全检查功能 保护用户的个人安全


OLLVM和LLVM功能介绍
LLVM源码浅析-1

LLVM国际开源软件社区发布正式支持LoongArch架构的版本
什么是LLVM?LLVM的优势和特点有哪些?
UCA认证和DGT 发布最新V16应急警示灯(Help Falsh)新增GPS通讯功能要求





 工商网监
工商网监
评论