 如何在OpenCV中使用基于深度学习的边缘检测?
如何在OpenCV中使用基于深度学习的边缘检测?
什么是边缘检测?
边缘检测是计算机视觉中一个非常古老的问题,它涉及到检测图像中的边缘来确定目标的边界,从而分离感兴趣的目标。最流行的边缘检测技术之一是Canny边缘检测,它已经成为大多数计算机视觉研究人员和实践者的首选方法。让我们快速看一下Canny边缘检测。
Canny边缘检测算法
1983年,John Canny在麻省理工学院发明了Canny边缘检测。它将边缘检测视为一个信号处理问题。其核心思想是,如果你观察图像中每个像素的强度变化,它在边缘的时候非常高。
在下面这张简单的图片中,强度变化只发生在边界上。所以,你可以很容易地通过观察像素强度的变化来识别边缘。

现在,看下这张图片。强度不是恒定的,但强度的变化率在边缘处最高。(微积分复习:变化率可以用一阶导数(梯度)来计算。)

Canny边缘检测器通过4步来识别边缘:
去噪:因为这种方法依赖于强度的突然变化,如果图像有很多随机噪声,那么会将噪声作为边缘。所以,使用5×5的高斯滤波器平滑你的图像是一个非常好的主意。
梯度计算:下一步,我们计算图像中每个像素的强度的梯度(强度变化率)。我们也计算梯度的方向。
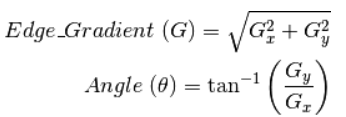
梯度方向垂直于边缘,它被映射到四个方向中的一个(水平、垂直和两个对角线方向)。
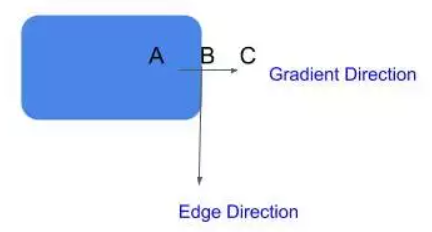
非极大值抑制:现在,我们想删除不是边缘的像素(设置它们的值为0)。你可能会说,我们可以简单地选取梯度值最高的像素,这些就是我们的边。然而,在真实的图像中,梯度不是简单地在只一个像素处达到峰值,而是在临近边缘的像素处都非常高。因此我们在梯度方向上取3×3附近的局部最大值。
迟滞阈值化:在下一步中,我们需要决定一个梯度的阈值,低于这个阈值所有的像素都将被抑制(设置为0)。而Canny边缘检测器则采用迟滞阈值法。迟滞阈值法是一种非常简单而有效的方法。我们使用两个阈值来代替只用一个阈值:
高阈值 = 选择一个非常高的值,这样任何梯度值高于这个值的像素都肯定是一个边缘。
低阈值 = 选择一个非常低的值,任何梯度值低于该值的像素绝对不是边缘。
在这两个阈值之间有梯度的像素会被检查,如果它们和边缘相连,就会留下,否则就会去掉。
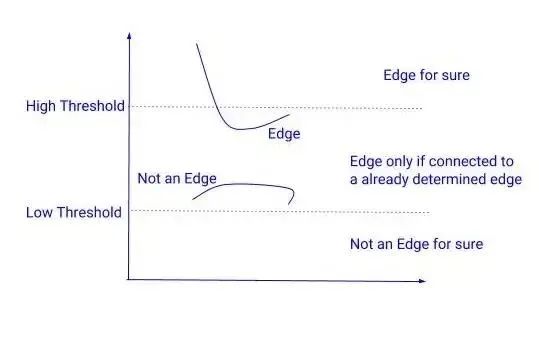
迟滞阈值化
Canny 边缘检测的问题:
由于Canny边缘检测器只关注局部变化,没有语义(理解图像的内容)理解,精度有限(很多时候是这样)。
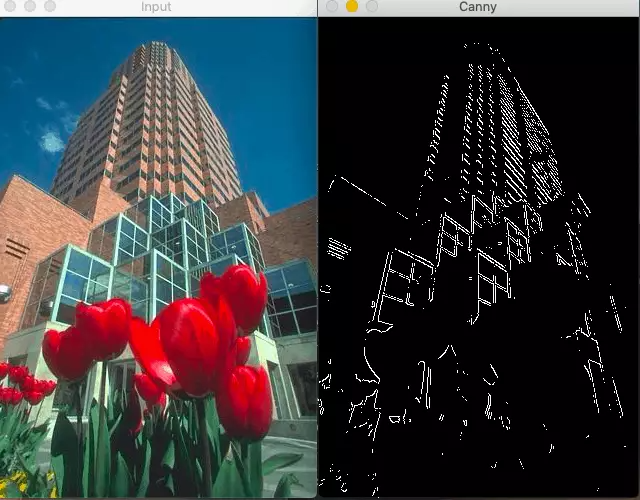
Canny边缘检测器在这种情况下会失败,因为没有理解图像的上下文
语义理解对于边缘检测是至关重要的,这就是为什么使用机器学习或深度学习的基于学习的检测器比canny边缘检测器产生更好的结果。
OpenCV中基于深度学习的边缘检测
OpenCV在其全新的DNN模块中集成了基于深度学习的边缘检测技术。你需要OpenCV 3.4.3或更高版本。这种技术被称为整体嵌套边缘检测或HED,是一种基于学习的端到端边缘检测系统,使用修剪过的类似vgg的卷积神经网络进行图像到图像的预测任务。
HED利用了中间层的输出。之前的层的输出称为side output,将所有5个卷积层的输出进行融合,生成最终的预测。由于在每一层生成的特征图大小不同,它可以有效地以不同的尺度查看图像。
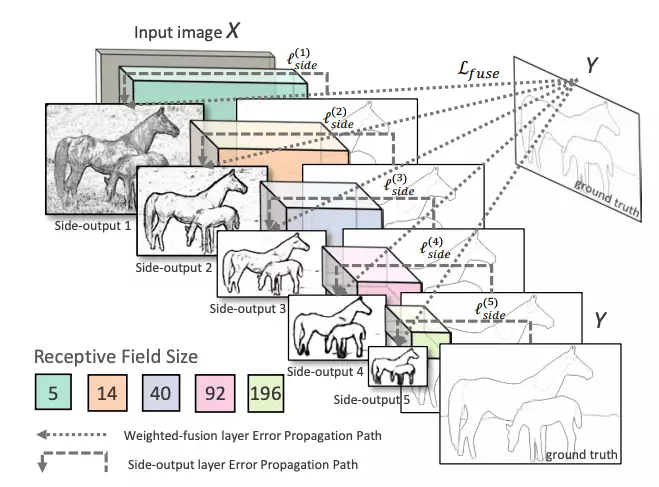
网络结构:整体嵌套边缘检测
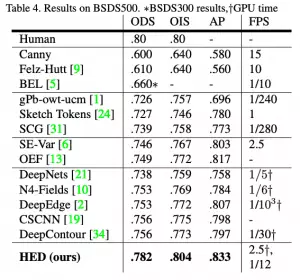
HED方法不仅比其他基于深度学习的方法更准确,而且速度也比其他方法快得多。这就是为什么OpenCV决定将其集成到新的DNN模块中。以下是这篇论文的结果:
在OpenCV中训练深度学习边缘检测的代码
OpenCV使用的预训练模型已经在Caffe框架中训练过了,可以这样加载:
shdownload_pretrained.sh
网络中有一个crop层,默认是没有实现的,所以我们需要自己实现一下。
classCropLayer(object): def__init__(self,params,blobs): self.xstart=0 self.xend=0 self.ystart=0 self.yend=0 #Ourlayerreceivestwoinputs.Weneedtocropthefirstinputblob #tomatchashapeofthesecondone(keepingbatchsizeandnumberofchannels) defgetMemoryShapes(self,inputs): inputShape,targetShape=inputs[0],inputs[1] batchSize,numChannels=inputShape[0],inputShape[1] height,width=targetShape[2],targetShape[3] self.ystart=(inputShape[2]-targetShape[2])//2 self.xstart=(inputShape[3]-targetShape[3])//2 self.yend=self.ystart+height self.xend=self.xstart+width return[[batchSize,numChannels,height,width]] defforward(self,inputs): return[inputs[0][:,:,self.ystart:self.yend,self.xstart:self.xend]]
现在,我们可以重载这个类,只需用一行代码注册该层。
cv.dnn_registerLayer('Crop',CropLayer)
现在,我们准备构建网络图并加载权重,这可以通过OpenCV的dnn.readNe函数。
net=cv.dnn.readNet(args.prototxt,args.caffemodel)
现在,下一步是批量加载图像,并通过网络运行它们。为此,我们使用cv2.dnn.blobFromImage方法。该方法从输入图像中创建四维blob。
blob=cv.dnn.blobFromImage(image,scalefactor,size,mean,swapRB,crop)
其中:
image:是我们想要发送给神经网络进行推理的输入图像。
scalefactor:图像缩放常数,很多时候我们需要把uint8的图像除以255,这样所有的像素都在0到1之间。默认值是1.0,不缩放。
size:输出图像的空间大小。它将等于后续神经网络作为blobFromImage输出所需的输入大小。
swapRB:布尔值,表示我们是否想在3通道图像中交换第一个和最后一个通道。OpenCV默认图像为BGR格式,但如果我们想将此顺序转换为RGB,我们可以将此标志设置为True,这也是默认值。
mean:为了进行归一化,有时我们计算训练数据集上的平均像素值,并在训练过程中从每幅图像中减去它。如果我们在训练中做均值减法,那么我们必须在推理中应用它。这个平均值是一个对应于R, G, B通道的元组。例如Imagenet数据集的均值是R=103.93, G=116.77, B=123.68。如果我们使用swapRB=False,那么这个顺序将是(B, G, R)。
crop:布尔标志,表示我们是否想居中裁剪图像。如果设置为True,则从中心裁剪输入图像时,较小的尺寸等于相应的尺寸,而其他尺寸等于或大于该尺寸。然而,如果我们将其设置为False,它将保留长宽比,只是将其调整为固定尺寸大小。
在我们这个场景下:
inp=cv.dnn.blobFromImage(frame,scalefactor=1.0,size=(args.width,args.height), mean=(104.00698793,116.66876762,122.67891434),swapRB=False, crop=False)
现在,我们只需要调用一下前向方法。
net.setInput(inp) out=net.forward() out=out[0,0] out=cv.resize(out,(frame.shape[1],frame.shape[0])) out=255*out out=out.astype(np.uint8) out=cv.cvtColor(out,cv.COLOR_GRAY2BGR) con=np.concatenate((frame,out),axis=1) cv.imshow(kWinName,con)
结果:
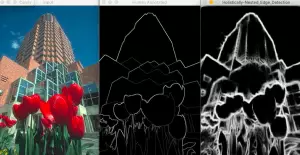
中间的图像是人工标注的图像,右边是HED的结果

中间的图像是人工标注的图像,右边是HED的结果。
审核编辑:刘清
-
信号处理器
+关注
关注
1文章
254浏览量
25278 -
OpenCV
+关注
关注
31文章
635浏览量
41361 -
图像边缘检测
+关注
关注
0文章
7浏览量
6543 -
高斯滤波器
+关注
关注
0文章
9浏览量
1735
原文标题:在OpenCV中基于深度学习的边缘检测
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在深度学习中使用纹理分析

AI模型部署边缘设备的奇妙之旅:如何在边缘端部署OpenCV
Rayeager PX2开发板测试opencv边缘检测效果
【DragonBoard 410c试用体验】之OpenCV中canny算子边缘检测
如何在您选择的边缘计算框架中使用EdgeScale
如何在OpenCV中使用基于深度学习的边缘检测


如何在OpenCV中实现CUDA加速
如何在深度学习结构中使用纹理特征







 工商网监
工商网监
评论