 ChatGPT与深度学习的完美融合:打造智能化推荐系统新时代
ChatGPT与深度学习的完美融合:打造智能化推荐系统新时代


PNN |AutoRec | 推荐算法
NFM | ChatGPT | 深度学习
新技术如ChatGPT、LLM、AIGC等的兴起,使推荐系统拥有更强的学习和预测能力。然而,推荐算法仍然是深度学习推荐系统中不可或缺的关键技术。推荐算法和这些技术应相辅相成,相互补充。推荐算法中的冷启动问题、Explore & Exploit、流行度纠偏、打散重排等问题,都是ChatGPT等技术未考虑的。AutoRec、Deep Crossing、NeuralCF、PNN、Wide&Deep、NFM、AFM、DIEN等模型的引入,丰富了推荐算法的解决方案,使得推荐系统更具智能和个性化。未来,推荐算法和ChatGPT等技术的结合将成为推荐系统发展的重要方向。
深度学习推荐系统已经被广泛应用于互联网大厂的推荐服务中,如阿里巴巴的淘宝推荐、腾讯的微信推荐、美团的点评推荐等。这些大厂不断探索和优化深度学习推荐系统,不断提高推荐的精度和效率。同时,深度学习推荐系统也面临着一些挑战,如数据隐私保护、模型可解释性、用户反馈等问题。在未来,深度学习推荐系统将继续在互联网行业中发挥重要作用,为用户提供更加个性化、精准的推荐服务。
当然,深度学习推荐系统与GPU服务器之间有着密不可分的关系。GPU服务器是一种高性能计算服务器,其主要特点是拥有多个GPU加速卡,可以大幅提高计算速度和效率。而深度学习推荐系统需要大量的计算资源,尤其是在训练模型和处理大规模数据时,需要使用GPU加速计算。因此,GPU服务器成为了深度学习推荐系统的重要基础设施。
在深度学习推荐系统中,GPU服务器主要用于训练深度神经网络模型。深度神经网络模型通常包含多个隐层,需要大量的计算资源来进行反向传播算法的优化和参数更新。使用GPU服务器可以大幅提高训练速度和效率,同时还可以处理大规模的数据集,提高模型的准确性和泛化能力。
此外,GPU服务器还可以用于推荐系统的实时推荐。在实时推荐中,需要根据用户的实时行为和环境信息,快速生成推荐结果。使用GPU服务器可以大幅提高推荐系统的响应速度和实时性,满足用户的需求。
蓝海大脑GPU服务器拥有高效、稳定、安全的性能,为深度学习推荐系统提供强大的计算支持。采用高性能NVIDIA GPU,支持多种深度学习框架,如TensorFlow、PyTorch、Caffe等,满足不同深度学习任务的需求。
什么是深度学习推荐系统?
深度学习推荐系统是一种利用深度学习技术来实现个性化推荐的系统。在深度学习推荐系统中,推荐算法通过学习用户的历史行为和兴趣偏好,为用户提供更加个性化的推荐服务。下面将介绍深度学习推荐系统的基本原理和深度学习在推荐系统中的应用原理。
一、推荐系统的基本概念
推荐系统是一种信息过滤系统,它可以为用户推荐他们可能感兴趣的信息或商品。推荐系统通常包括两个主要组成部分:用户模型和物品模型。用户模型是对用户兴趣的建模,物品模型是对物品属性的建模。推荐系统通过分析用户的历史行为和兴趣偏好,以及物品的属性和特征,来为用户推荐最符合他们兴趣的物品。
二、为什么在推荐系统是互联网的增长引擎
推荐系统在互联网行业中扮演着重要的角色,它不仅能够解决用户在信息过载的情况下如何高效获得感兴趣信息的问题,还能够帮助公司达成商业目标、增加公司收益。推荐系统的优化目标因公司业务模式而异,例如,视频类公司更注重用户观看时长,电商类公司更注重用户的购买转化率,新型公司更注重用户的点击等。
三、深度学习对推荐系统的革命性构建
深度学习对推荐系统的革命性贡献在于对推荐模型部分的改进。与传统的推荐模型相比,深度学习模型对数据模式的拟合能力和对特征组合的挖掘能力更强。深度学习模型结构的灵活性,使其能够根据不同推荐场景调整模型,使之与特定业务数据契合。
然而,深度学习对海量训练数据及数据实时性的要求也对推荐系统的数据流部分提出了新的挑战。如何尽可能做到海量数据的实时处理、特征的实时提取以及线上模型服务过程的数据实时获取,是深度学习推荐系统数据部分需要攻克的难题。因此,推荐系统的设计需要考虑到数据流的实时性和处理能力,以及推荐模型的精度和效率。只有在这两个方面都达到了最优化,才能实现推荐系统的最大化商业价值。
深度学习在推荐系统中的应用?
深度学习推荐模型已经成为推荐和广告领域的主流。与传统的机器学习模型相比,深度学习模型的表达能力更强,能够挖掘出更多数据中潜藏的模式。深度学习的模型结构非常灵活,能够根据业务场景和数据特点,灵活调整模型结构,使模型与应用场景完美契合。从技术角度讲,深度学习推荐模型大量借鉴并融合了深度学习在图像、语音及自然语言处理方向的成果,在模型结构上进行了快速的演化。选择模型的标准应遵循模型在工业界和学术界影响力较大,已经被知名互联网公司成功应用,以及在深度学习推荐系统发展过程中起到重要的节点作用这三个原则。
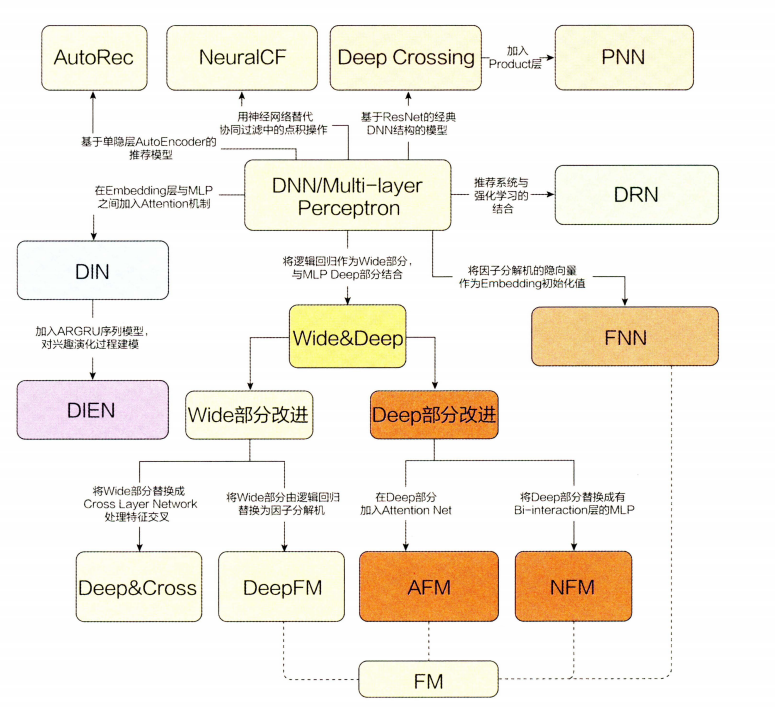
一、深度学习推荐模型的演化关系图
下图展示了主流深度学习推荐模型的演化图谱。通过改变神经网络的结构,构建特点各异的深度学习推荐模型,其主要演变方向包括:
1、改变神经网络的复杂程度
从最简单的单层神经网络模型AutoRec,到经典的深度神经网络结构Deep Crossing,这类模型主要通过一层层增加深度神经网络的层数和结构复杂度来提升模型表达能力。
2、改变特征交叉方式
主要通过丰富深度学习网络中特征交叉的方式来提升模型表达能力,例如改变用户向量和物品向量互操作方式的NeuralCF和定义多种特征向量交叉操作的PNN模型。
3、组合模型
主要是通过组合两种不同特点优势互补的深度学习网络,提升模型的综合能力,例如Wide&Deep模型及其后续变种Deep&Cross、DeepFM等。
4、FM模型的深度学习演化版本
FM模型在深度学习时代的后续版本,例如NFM、FNN、AFM等,它们对FM模型进行了不同的改进方向。
5、注意力机制与推荐模型的结合
将“注意力机制”应用于深度学习推荐模型中,例如结合FM和注意力机制的AFM和引入了注意力机制的CTR预估模型DIN。
6、序列模型与推荐模型的结合
使用序列模型模拟用户行为或用户兴趣的演化趋势,代表模型是DIEN。
7、强化学习与推荐模型的结合
将强化学习应用于推荐领域,强调模型的在线学习和实时更新,代表模型是DRN。
二、AutoRec一一单隐层神经网络推荐模型
AutoRec是一种基于自编码器的推荐模型,它可以自动地学习用户的兴趣特征,并根据这些特征为用户推荐个性化的商品或服务。AutoRec的模型结构相对简单,主要由两个部分组成:编码器和解码器。
编码器部分将用户的历史行为数据,如点击、购买、评分等,作为输入,经过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了用户的兴趣特征,可以用来表示用户的兴趣偏好。
解码器部分将编码器输出的隐向量表示作为输入,经过一定的神经网络层次结构,将其重构成原始的用户历史行为数据。在这个过程中,AutoRec模型会尽可能地还原原始数据,从而最大限度地保留用户的兴趣特征。
在训练过程中,AutoRec模型会通过最小化重构误差来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征。训练完成后,模型可以根据用户的历史行为数据,预测用户可能感兴趣的商品或服务。
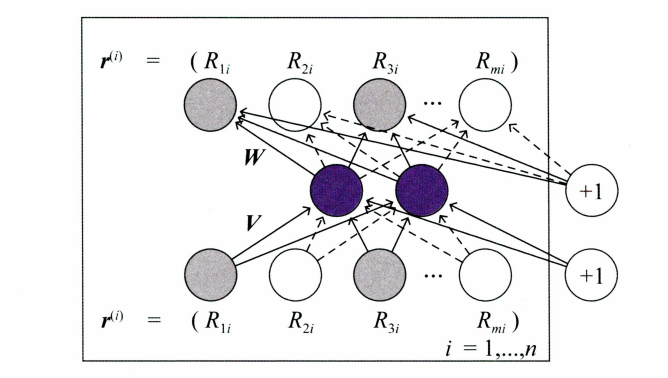
AutoRec模型结构图
三、Deep Crossing 模型一一经典的深度学习架构
Deep Crossing是一种基于神经网络的推荐模型,它可以自动地学习用户的兴趣特征,并根据这些特征为用户推荐个性化的商品或服务。Deep Crossing的模型结构相对复杂,主要由两个部分组成:特征交叉层和多层感知机。
特征交叉层将用户的历史行为数据,如点击、购买、评分等,作为输入,经过一定的神经网络层次结构,将其进行特征交叉,从而得到更加丰富的特征表示。这个特征交叉层可以帮助模型学习到更加复杂和抽象的用户兴趣特征。
多层感知机部分将特征交叉层的输出作为输入,经过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了用户的兴趣特征,可以用来表示用户的兴趣偏好。
在训练过程中,Deep Crossing模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征。训练完成后,模型可以根据用户的历史行为数据,预测用户可能感兴趣的商品或服务。
Deep Crossing是一种基于神经网络的推荐模型,它可以自动地学习用户的兴趣特征,并根据这些特征为用户推荐个性化的商品或服务。它的模型结构相对复杂,由特征交叉层和多层感知机两个部分组成。
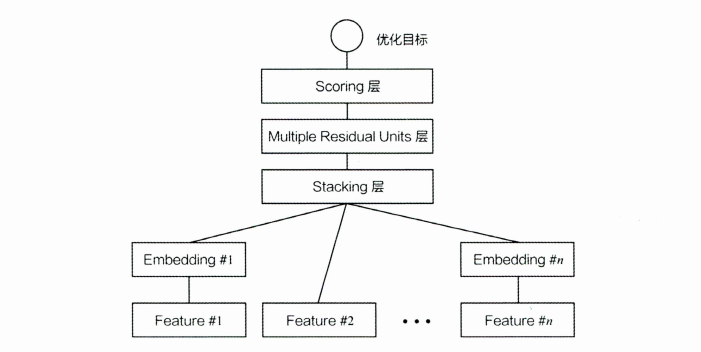
Deep Crossing 模型结构图
四、NeuralCF 模型——CF 与深度学习的结合
NeuralCF是一种基于神经网络的推荐模型,它可以自动地学习用户的兴趣特征,并根据这些特征为用户推荐个性化的商品或服务。NeuralCF的模型结构相对简单,主要由两个部分组成:用户嵌入层和物品嵌入层。
用户嵌入层将用户的历史行为数据,如点击、购买、评分等,作为输入,经过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了用户的兴趣特征,可以用来表示用户的兴趣偏好。
物品嵌入层将商品的特征数据,如商品的类别、价格、评分等,作为输入,经过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了商品的特征信息,可以用来表示商品的属性和特点。
在训练过程中,NeuralCF模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征和商品的特征信息。训练完成后,模型可以根据用户的历史行为数据和商品的特征信息,预测用户可能感兴趣的商品或服务。
NeuralCF是一种基于神经网络的推荐模型,它可以自动地学习用户的兴趣特征和商品的特征信息,并根据这些特征为用户推荐个性化的商品或服务。它的模型结构相对简单,由用户嵌入层和物品嵌入层两个部分组成。
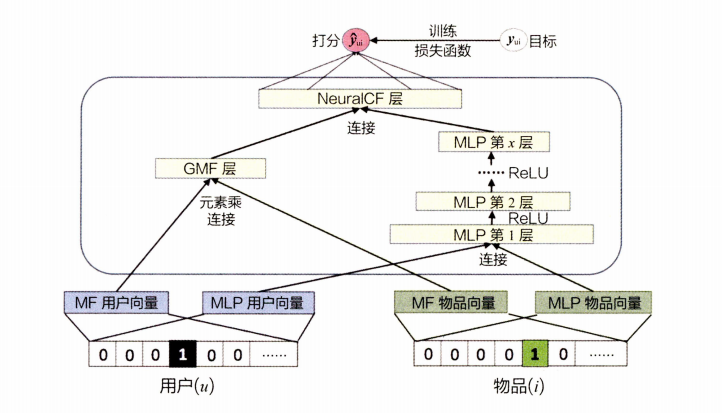
NeuralCF 模型
NeuralCF模型框架基于用户向量和物品向量这两个Embedding层,利用不同的互操作层进行特征的交叉组合,并且可以灵活地进行不同互操作层的拼接。这体现了深度学习构建推荐模型的优势,即利用神经网络理论上能够拟合任意函数的能力,灵活地组合不同的特征,按需增加或减少模型的复杂度。
在实践中,需要注意的是,并不是模型结构越复杂、特征越多越好。要防止过拟合的风险,往往需要更多的数据和更长的训练时间才能使复杂的模型收敛。这需要算法工程师在模型的实用性、实时性和效果之间进行权衡。
然而,NeuralCF模型也存在局限性。由于是基于协同过滤的思想进行构造的,所以NeuralCF模型并没有引入更多其他类型的特征,这在实际应用中无疑浪费了其他有价值的信息。此外,对于模型中互操作的种类并没有做进步的探究和说明。这都需要后来者进行更深入的探索。
五、PNN 模型一一加强特征交叉能力
PNN(Product-based Neural Networks)是一种基于神经网络的推荐模型,它结合了FM(Factorization Machines)和深度神经网络的优点,可以更好地处理高维稀疏特征数据。
PNN的模型结构包括两个部分:特征交叉层和多层感知机。
特征交叉层将用户的历史行为数据和商品的特征数据,如点击、购买、评分等,作为输入,通过FM模型进行特征交叉,从而得到更加丰富的特征表示。这个特征交叉层可以帮助模型学习到更加复杂和抽象的用户兴趣特征和商品特征。
多层感知机部分将特征交叉层的输出作为输入,经过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了用户的兴趣特征和商品的特征信息,可以用来表示用户对商品的兴趣程度。
在训练过程中,PNN模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征和商品的特征信息。训练完成后,模型可以根据用户的历史行为数据和商品的特征信息,预测用户可能感兴趣的商品或服务。
PNN是一种基于神经网络的推荐模型,它结合了FM和深度神经网络的优点,可以更好地处理高维稀疏特征数据。它的模型结构相对复杂,由特征交叉层和多层感知机两个部分组成。
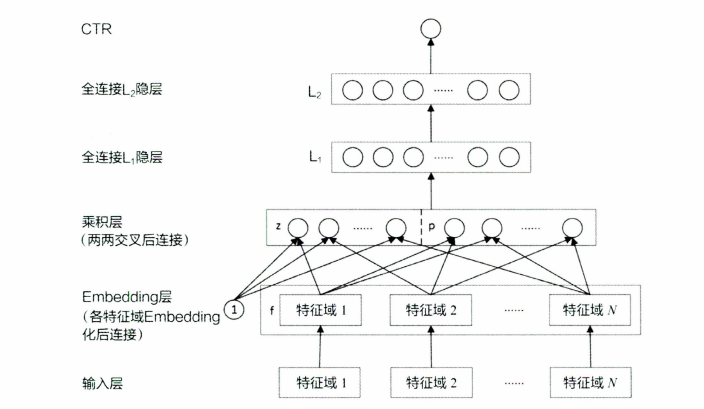
PNN 模型模型结构图
PNN模型强调了特征Embedding之间的交叉方式是多样化的。相比于简单的交由全连接层进行无差别化的处理,PNN模型定义的内积和外积操作显然更有针对性地强调了不同特征之间的交互,从而让模型更容易捕获特征的交叉信息。
然而,PNN模型同样存在着一些局限性。例如,在外积操作的实际应用中,为了优化训练效率进行了大量的简化操作。此外,对所有特征进行无差别的交叉,在一定程度上忽略了原始特征向量中包含的有价值信息。如何综合原始特征及交叉特征,让特征交叉的方式更加高效,后续的Wide&Deep模型和基于FM的各类深度学习模型将给出它们的解决方案。
六、Wide&Deep 模型一一记忆能力和泛化能力的综合
Wide&Deep是一种基于神经网络的推荐模型,它结合了线性模型和深度神经网络的优点,可以更好地处理稀疏特征数据和非线性关系。
Wide&Deep的模型结构包括两个部分:线性模型和深度神经网络。
线性模型部分将用户的历史行为数据和商品的特征数据,如点击、购买、评分等,作为输入,通过一定的线性变换,得到一个线性组合的特征表示。这个线性组合的特征表示可以用来表示用户和商品之间的简单关系,如用户购买某个商品的概率与用户点击该商品的次数成正比。
深度神经网络部分将用户的历史行为数据和商品的特征数据作为输入,通过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了用户的兴趣特征和商品的特征信息,可以用来表示用户对商品的兴趣程度。
在训练过程中,Wide&Deep模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征和商品的特征信息。训练完成后,模型可以根据用户的历史行为数据和商品的特征信息,预测用户可能感兴趣的商品或服务。
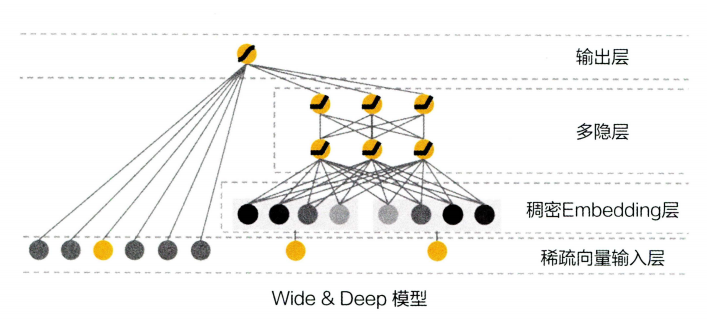
Wide&Deep 模型结构图
七、NFM——FM 的神经网络化尝试
NFM(Neural Factorization Machines)是一种基于神经网络的推荐模型,它结合了FM和深度神经网络的优点,可以更好地处理高维稀疏特征数据。
NFM的模型结构包括两个部分:特征交叉层和多层感知机。
特征交叉层将用户的历史行为数据和商品的特征数据,如点击、购买、评分等,作为输入,通过FM模型进行特征交叉,从而得到更加丰富的特征表示。这个特征交叉层可以帮助模型学习到更加复杂和抽象的用户兴趣特征和商品特征。
多层感知机部分将特征交叉层的输出作为输入,经过一定的神经网络层次结构,将其映射成一个低维度的隐向量表示。这个隐向量表示包含了用户的兴趣特征和商品的特征信息,可以用来表示用户对商品的兴趣程度。
在训练过程中,NFM模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征和商品的特征信息。训练完成后,模型可以根据用户的历史行为数据和商品的特征信息,预测用户可能感兴趣的商品或服务。
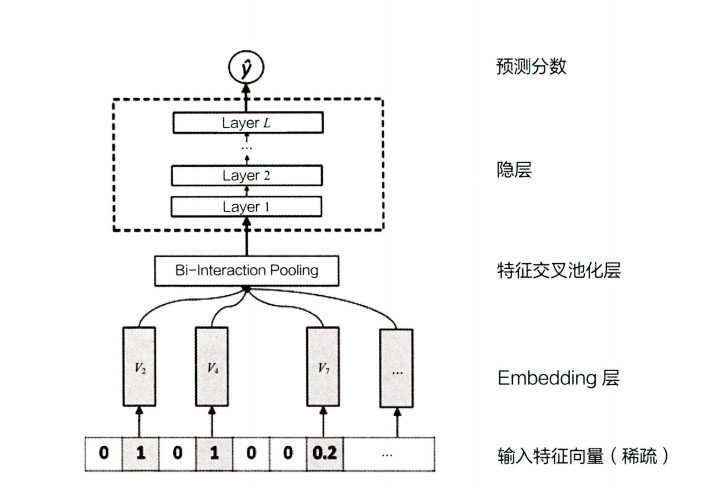
NFM 的深度网络部分模型结构图
八、AFM——引入注意力机制的FM
AFM(Attentional Factorization Machines)是一种基于注意力机制的推荐模型,它结合了FM和注意力机制的优点,可以更好地处理高维稀疏特征数据和非线性关系。
AFM的模型结构包括两个部分:特征交叉层和注意力机制。
特征交叉层将用户的历史行为数据和商品的特征数据,如点击、购买、评分等,作为输入,通过FM模型进行特征交叉,从而得到更加丰富的特征表示。这个特征交叉层可以帮助模型学习到更加复杂和抽象的用户兴趣特征和商品特征。
注意力机制部分将特征交叉层的输出作为输入,通过一定的神经网络层次结构,学习出每个特征的重要性权重。这个权重可以用来表示不同特征对于用户兴趣的重要程度,从而进一步提高模型的预测准确度。
在训练过程中,AFM模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣特征和商品的特征信息。训练完成后,模型可以根据用户的历史行为数据和商品的特征信息,预测用户可能感兴趣的商品或服务。
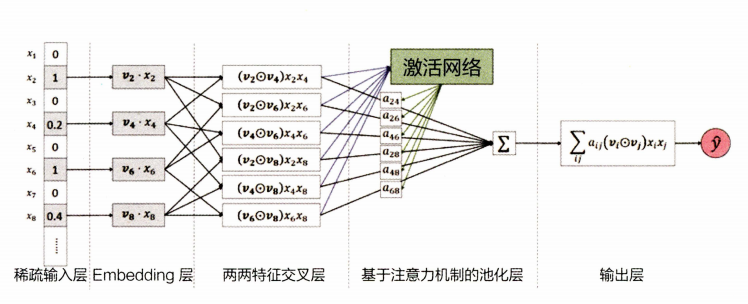
AFM模型结构图
九、DIEN——序列模型与推荐系统的结合
DIEN(Deep Interest Evolution Network)是一种基于深度学习的推荐模型,它结合了序列模型和兴趣演化模型的优点,可以更好地处理用户兴趣的演化过程。
DIEN的模型结构包括三个部分:兴趣抽取层、兴趣进化层和预测层。
兴趣抽取层将用户的历史行为数据,如点击、购买、评分等,作为输入,通过一定的神经网络层次结构,学习出每个行为的向量表示。这个向量表示包含了用户的兴趣信息,可以用来表示用户当前的兴趣状态。
兴趣进化层将兴趣抽取层的输出作为输入,通过一定的神经网络层次结构,学习出每个行为对于用户兴趣演化的影响。这个影响可以用来表示用户兴趣的演化过程,从而更好地预测用户未来的兴趣。
预测层将兴趣进化层的输出和商品的特征数据,如价格、类别、品牌等,作为输入,通过一定的神经网络层次结构,预测用户对于每个商品的兴趣程度。这个预测结果可以用来推荐给用户最可能感兴趣的商品或服务。
在训练过程中,DIEN模型会通过最小化交叉熵损失函数来优化模型参数,从而使得模型可以更加准确地学习用户的兴趣演化过程和商品的特征信息。训练完成后,模型可以根据用户的历史行为数据和商品的特征信息,预测用户可能感兴趣的商品或服务。
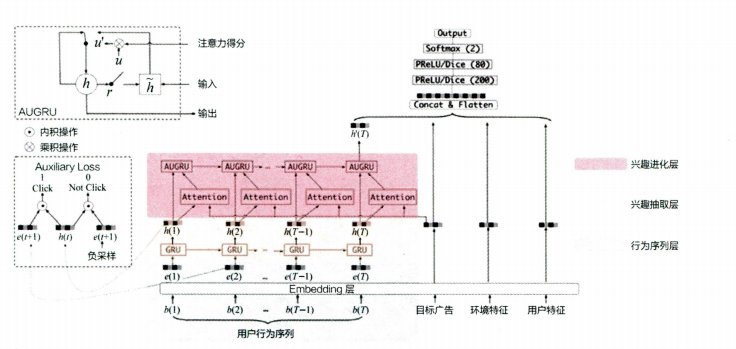
DIEN 模型的结构图
深度学习推荐系统的应用领域
深度学习推荐系统是一种基于深度学习算法的推荐系统,它可以通过学习用户的历史行为和商品的特征信息,预测用户对于每个商品的兴趣程度,从而推荐给用户最可能感兴趣的商品或服务。深度学习推荐系统在电商、社交、视频、音乐等领域都有广泛的应用场景。
一、电商领域
在电商领域,深度学习推荐系统可以帮助电商平台更好地推荐商品给用户。电商平台通常有庞大的商品库存,而用户的购买行为也随着时间和场景的变化而变化,因此需要一个智能的推荐系统来帮助用户快速找到感兴趣的商品。深度学习推荐系统可以通过对用户的历史购买行为和商品的特征信息进行分析和学习,预测用户对于每个商品的兴趣程度,从而推荐给用户最可能感兴趣的商品。此外,深度学习推荐系统还可以根据用户的行为数据和商品的特征信息,实现商品的个性化推荐和定制化服务。
二、社交领域
在社交领域,深度学习推荐系统可以帮助社交平台更好地推荐用户感兴趣的内容和好友。社交平台通常有大量的用户和内容,而用户的兴趣和需求也随着时间和场景的变化而变化,因此需要一个智能的推荐系统来帮助用户快速找到感兴趣的内容和好友。深度学习推荐系统可以通过对用户的历史行为数据和内容的特征信息进行分析和学习,预测用户对于每个内容的兴趣程度,从而推荐给用户最可能感兴趣的内容和好友。此外,深度学习推荐系统还可以根据用户的行为数据和内容的特征信息,实现内容的个性化推荐和定制化服务。
三、视频领域
在视频领域,深度学习推荐系统可以帮助视频平台更好地推荐用户感兴趣的视频内容。视频平台通常有大量的视频内容,而用户的兴趣和需求也随着时间和场景的变化而变化,因此需要一个智能的推荐系统来帮助用户快速找到感兴趣的视频内容。深度学习推荐系统可以通过对用户的历史行为数据和视频的特征信息进行分析和学习,预测用户对于每个视频的兴趣程度,从而推荐给用户最可能感兴趣的视频内容。此外,深度学习推荐系统还可以根据用户的行为数据和视频的特征信息,实现视频的个性化推荐和定制化服务。
四、音乐领域
在音乐领域,深度学习推荐系统可以帮助音乐平台更好地推荐用户感兴趣的音乐内容。音乐平台通常有大量的音乐内容,而用户的兴趣和需求也随着时间和场景的变化而变化,因此需要一个智能的推荐系统来帮助用户快速找到感兴趣的音乐内容。深度学习推荐系统可以通过对用户的历史行为数据和音乐的特征信息进行分析和学习,预测用户对于每个音乐的兴趣程度,从而推荐给用户最可能感兴趣的音乐内容。此外,深度学习推荐系统还可以根据用户的行为数据和音乐的特征信息,实现音乐的个性化推荐和定制化服务。
深度学习推荐系统的优缺点
深度学习推荐系统是一种利用深度学习算法来实现个性化推荐的技术。它能够从用户的历史行为数据和商品/内容的特征信息中学习用户的兴趣和需求,从而预测用户对于每个商品/内容的兴趣程度,实现更准确的个性化推荐。
一、优点
深度学习推荐系统的优点主要包括:更准确的推荐结果、更好的用户体验、更高的商业价值。
首先,深度学习推荐系统能够从大量的用户行为数据和商品/内容的特征信息中学习用户的兴趣和需求,从而预测用户对于每个商品/内容的兴趣程度,实现更准确的个性化推荐。相比于传统的推荐算法,深度学习推荐系统能够更好地捕捉用户的兴趣和需求,从而提高推荐结果的准确性。
其次,深度学习推荐系统能够根据用户的历史行为数据和商品/内容的特征信息,实现个性化推荐和定制化服务,从而提高用户的满意度和体验。用户可以更快速地找到自己感兴趣的商品/内容,从而提高使用体验和满意度。
最后,深度学习推荐系统能够帮助企业更好地推荐商品/内容和服务,提高销量和用户留存率,从而带来更高的商业价值。企业可以通过深度学习推荐系统来提高用户的忠诚度,增加用户的购买频率和购买金额,从而提高企业的盈利能力。
二、缺点
深度学习推荐系统需要大量的用户行为数据来进行学习和预测,但是这些数据涉及到用户的隐私,如果不加以保护可能会引发数据泄露和滥用的问题。企业需要采取一系列措施来保护用户的隐私,例如数据脱敏、数据加密等。
其次,深度学习推荐系统需要进行大量的计算和训练,需要消耗大量的计算资源和时间,对于一些资源有限的企业来说可能会带来较高的成本和风险。企业需要根据自身的情况来选择适合的深度学习模型和计算平台,以实现最优的推荐效果和成本效益。
最后,深度学习模型的结构和参数较为复杂,对于一些不懂技术的用户来说可能难以理解和接受,这也会降低用户的信任和使用体验。企业需要加强对于用户的解释和说明,提高用户的理解和信任程度。
大厂在深度学习推荐系统的实践
推荐系统领域是深度学习落地最充分,产生商业价值最大的应用领域之 些最前沿的研究成果大多来自业界巨头的实践 Facebook 2014 年提出的 GBDT+LR 组合模 型引领特征工程模型 化的方向,到 2016 年微软提 Deep Crossing 模型,谷歌发布 Wide&Deep 模型架构,以及 YouTube 公开其深度学习 推荐系统,业界迎来了深度学习推荐系统应用的浪潮 至今日 ,无论 里巴 巴团队在商品推荐系统领域的持 新,还是 Airbnb 在搜索推荐过程中对深度 学习的前沿应用 ,深度学习 经成了推荐系统领域当之无愧 主流
对从业者或有志成为推荐工程师的读者来说,处在这个代码开源和知识共享 的时代无疑是幸运的 我们几乎可以零距离地通过业界先锋的论文、博客及技术 演讲接触到最前沿的推荐系统应用 本章的内容将由简入深,由框架到细节,依 讲解 Facebook Airbnb YouTube 及阿里巴巴的深度学习推荐系统 希望读者 能够在之前章节的知识基础上,关注业界最前沿的推荐系统应用的技术细节和工 程实现,将推荐系统的知识融会贯通,学以致用
一、Facebook 的深度学习推荐系统
Facebook 的深度学习推荐系统是一种利用深度学习算法来实现个性化推荐的技术。它能够从用户的历史行为数据和内容的特征信息中学习用户的兴趣和需求,从而预测用户对于每个内容的兴趣程度,实现更准确的个性化推荐。Facebook 的深度学习推荐系统主要包括以下几个方面的内容:
1、深度学习模型
Facebook的深度学习推荐系统主要采用了卷积神经网络(CNN)和循环神经网络(RNN)等深度学习模型。这些模型能够从用户的历史行为数据和内容的特征信息中学习用户的兴趣和需求,从而预测用户对于每个内容的兴趣程度。其中,CNN主要用于对于图像和视频等内容的处理,而RNN主要用于对于文本和序列数据的处理。
具体来说,Facebook的深度学习推荐系统使用了一种称为DNN(Deep Neural Network)的模型,该模型由多个深度神经网络组成。这些网络可以处理不同类型的输入数据,例如文本、图像、视频和用户行为数据等。在模型训练的过程中,DNN会自动学习用户的兴趣和行为模式,从而为每个用户生成一个独特的兴趣向量。这个向量可以用来预测用户对于不同内容的兴趣程度。
2、数据处理
Facebook的深度学习推荐系统需要处理大量的用户行为数据和内容特征信息。为了保护用户的隐私,Facebook采用了一系列的数据脱敏和加密技术,以确保用户的数据安全和隐私。同时,Facebook还采用了分布式存储和计算技术,以提高数据处理的效率和速度。
具体来说,Facebook的深度学习推荐系统使用了一种称为Hadoop的分布式计算框架,该框架可以将大规模数据分布式存储和处理。此外,Facebook还使用了一种称为Presto的分布式SQL查询引擎,该引擎可以快速查询海量数据。
3、特征工程
Facebook的深度学习推荐系统还需要进行特征工程,以提取用户和内容的特征信息。Facebook采用了一系列的特征提取和转换技术,例如词袋模型、TF-IDF等,以提取文本和序列数据的特征信息。同时,Facebook还采用了图像和视频处理技术,以提取图像和视频内容的特征信息。
具体来说,Facebook的深度学习推荐系统使用了一种称为Word2Vec的技术,该技术可以将文本数据转换为向量表示,以便于深度学习模型的处理。此外,Facebook还使用了一种称为ResNet的卷积神经网络,该网络可以提取图像和视频内容的特征信息。
4、实时推荐
Facebook的深度学习推荐系统需要实时地对于用户的行为进行分析和推荐。为了实现实时推荐,Facebook采用了分布式计算和流处理技术,以实现对于用户行为的实时分析和推荐。
具体来说,Facebook的深度学习推荐系统使用了一种称为Kafka的流处理平台,该平台可以处理大规模实时数据流。此外,Facebook还使用了一种称为Flink的流处理引擎,该引擎可以实现对于数据流的实时处理和分析。
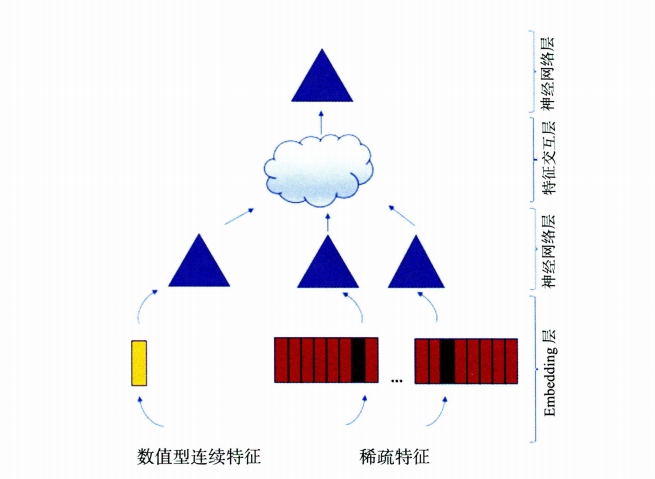
Facebook的深度学习模型DLRM
二、Airbnb 基于 Embedding 的实时搜索推荐系统
Airbnb是全球知名的住宿分享平台,用户可以在Airbnb上租借房屋、公寓、别墅等各类住宿场所。为了提高用户的搜索和预订体验,Airbnb开发了基于Embedding的实时搜索推荐系统,该系统可以为用户提供更加准确和个性化的搜索结果和推荐服务。
1、Embedding技术
Embedding技术是一种将离散型数据转换为连续型向量的技术,例如将用户ID、房源ID、城市名称等转换为向量表示。Embedding技术可以将复杂的离散型数据转换为连续型向量,从而方便深度学习模型的处理。在Airbnb的实时搜索推荐系统中,Embedding技术被广泛应用于用户、房源和城市等数据的表示。
2、实时搜索推荐
Airbnb的实时搜索推荐系统需要实时地对于用户的搜索行为进行分析和推荐。为了实现实时推荐,Airbnb采用了分布式计算和流处理技术,以实现对于用户行为的实时分析和推荐。
具体来说,Airbnb的实时搜索推荐系统使用了一种称为Kafka的流处理平台,该平台可以处理大规模实时数据流。此外,Airbnb还使用了一种称为Flink的流处理引擎,该引擎可以实现对于数据流的实时处理和分析。
3、搜索排序
Airbnb的实时搜索推荐系统需要对于搜索结果进行排序,以提供更加准确和个性化的搜索服务。为了实现搜索排序,Airbnb采用了一种称为LambdaMART的机器学习模型,该模型可以对于搜索结果进行排序和评分。
具体来说,LambdaMART是一种基于树的排序模型,它可以将搜索结果转换为向量表示,并使用梯度提升树(Gradient Boosting Tree)进行排序和评分。LambdaMART可以考虑多个因素,例如用户的偏好、房源的质量和地理位置等,从而为用户提供更加准确和个性化的搜索结果。
4、推荐服务
Airbnb的实时搜索推荐系统还需要提供推荐服务,以帮助用户发现更多的房源和住宿场所。为了实现推荐服务,Airbnb采用了一种称为DeepWalk的图嵌入技术,该技术可以将房源和城市等数据表示为图,并将其转换为向量表示。
具体来说,DeepWalk是一种基于随机游走的图嵌入技术,它可以将图中的节点转换为向量表示,从而方便深度学习模型的处理。在Airbnb的实时搜索推荐系统中,DeepWalk被广泛应用于房源和城市等数据的表示和推荐。通过DeepWalk,Airbnb可以为用户提供更加准确和个性化的推荐服务。
Airbnb 的搜索业务场景
三、YouTube 深度学习视频推荐系统
YouTube是全球最大的视频分享网站之一,每天有数以亿计的用户在其中观看和分享视频。为了提高用户的视频观看体验,YouTube开发了基于深度学习的视频推荐系统,该系统可以为用户提供更加准确和个性化的视频推荐服务。
1、数据收集和处理
YouTube的深度学习视频推荐系统需要收集和处理大量的视频数据,包括视频的标题、标签、描述、观看历史、用户评分等信息。为了处理这些数据,YouTube采用了一种称为Bigtable的分布式数据库,该数据库可以支持海量数据的存储和处理。
2、特征提取
为了实现视频的推荐,YouTube需要将视频转换为向量表示,以方便深度学习模型的处理。为了实现特征提取,YouTube采用了一种称为视频编码器的技术,该技术可以将视频转换为向量表示。
具体来说,视频编码器是一种基于卷积神经网络的技术,它可以将视频的每一帧转换为向量表示,并将这些向量组合成视频的表示。在YouTube的深度学习视频推荐系统中,视频编码器被广泛应用于视频的特征提取和表示。
3、深度学习模型
YouTube的深度学习视频推荐系统需要使用深度学习模型进行视频的推荐。为了实现视频的推荐,YouTube采用了一种称为DNN(Deep Neural Network)的深度学习模型,该模型可以实现对于用户兴趣和视频特征的建模。
具体来说,DNN模型是一种多层神经网络模型,它可以将用户的观看历史、搜索行为、评分等信息转换为向量表示,并将视频的特征表示与用户的兴趣表示进行匹配和推荐。在YouTube的深度学习视频推荐系统中,DNN模型被广泛应用于视频推荐和个性化服务。
4、推荐服务
YouTube的深度学习视频推荐系统需要提供推荐服务,以帮助用户发现更多的视频和频道。为了实现推荐服务,YouTube采用了一种称为协同过滤的技术,该技术可以基于用户的历史行为和兴趣推荐相关的视频和频道。
具体来说,协同过滤是一种基于用户行为的推荐技术,它可以分析用户的历史观看行为和评分,从而推荐与用户兴趣相关的视频和频道。在YouTube的深度学习视频推荐系统中,协同过滤被广泛应用于视频推荐和个性化服务。
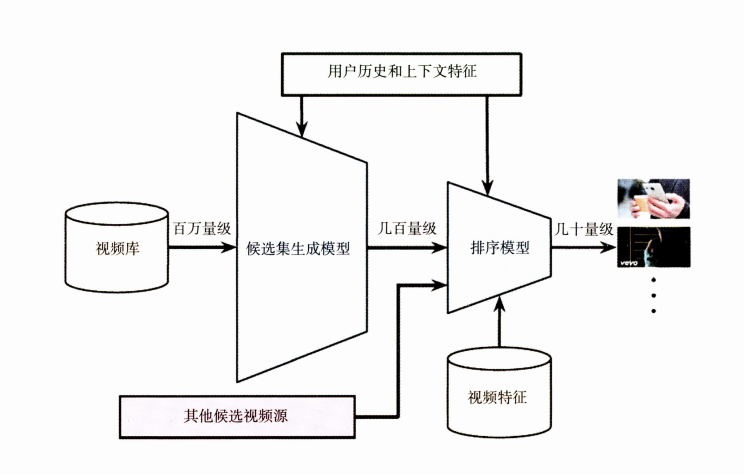
YouTube 系统整体架构
四、阿里巴巴深度学习推荐系统
阿里巴巴是全球领先的电商平台之一,每天有数以亿计的用户在其中进行购物和交易。为了提高用户的购物体验,阿里巴巴开发了基于深度学习的推荐系统,该系统可以为用户提供更加准确和个性化的商品推荐服务。
1、数据收集和处理
阿里巴巴的深度学习推荐系统需要收集和处理大量的用户数据,包括用户的购买历史、浏览历史、搜索行为、评价等信息。为了处理这些数据,阿里巴巴采用了一种称为MaxCompute的分布式数据处理平台,该平台可以支持海量数据的存储和处理。
2、特征提取
为了实现商品的推荐,阿里巴巴需要将商品转换为向量表示,以方便深度学习模型的处理。为了实现特征提取,阿里巴巴采用了一种称为商品编码器的技术,该技术可以将商品转换为向量表示。
具体来说,商品编码器是一种基于卷积神经网络的技术,它可以将商品的图片、标题、描述等信息转换为向量表示,并将这些向量组合成商品的表示。在阿里巴巴的深度学习推荐系统中,商品编码器被广泛应用于商品的特征提取和表示。
3、深度学习模型
阿里巴巴的深度学习推荐系统需要使用深度学习模型进行商品的推荐。为了实现商品的推荐,阿里巴巴采用了一种称为DIN(Deep Interest Network)的深度学习模型,该模型可以实现对于用户兴趣和商品特征的建模。
具体来说,DIN模型是一种基于神经网络的模型,它可以将用户的购买历史、浏览历史、搜索行为等信息转换为向量表示,并将商品的特征表示与用户的兴趣表示进行匹配和推荐。在阿里巴巴的深度学习推荐系统中,DIN模型被广泛应用于商品推荐和个性化服务。
4、推荐服务
阿里巴巴的深度学习推荐系统需要提供推荐服务,以帮助用户发现更多的商品和优惠。为了实现推荐服务,阿里巴巴采用了一种称为GBDT(Gradient Boosting Decision Tree)的技术,该技术可以基于用户的历史行为和兴趣推荐相关的商品和优惠。
具体来说,GBDT是一种基于决策树的推荐技术,它可以分析用户的历史购买行为和评价,从而推荐与用户兴趣相关的商品和优惠。在阿里巴巴的深度学习推荐系统中,GBDT被广泛应用于商品推荐和个性化服务。
深度学习推荐系统的未来发展与展望
随着互联网和大数据技术的不断发展,推荐系统已经成为了各大电商、社交媒体、视频网站等互联网企业的重要组成部分。而深度学习技术的应用,则为推荐系统的性能提升带来了巨大的机会。那么,深度学习推荐系统的未来发展方向和可能面临的挑战是什么呢?
首先,深度学习推荐系统将更加注重个性化推荐。传统的推荐系统主要基于用户历史行为和商品属性等信息进行推荐,而深度学习技术可以从用户的社交网络、搜索记录、浏览行为等更多维度的数据中提取特征,进一步挖掘用户的兴趣和需求,实现更加精准的个性化推荐。
其次,深度学习推荐系统将更加注重多样性推荐。在传统的推荐系统中,往往会出现“过度推荐”或“过度相似”的问题,即推荐的商品或内容过于单一或相似,难以满足用户多样化的需求。而深度学习技术可以通过引入多个隐层,增加推荐系统的复杂度,从而实现更加多样化的推荐。
第三,深度学习推荐系统将更加注重实时性和可解释性。在互联网时代,用户的需求和兴趣变化非常快,因此推荐系统需要具备实时性,能够快速响应用户的需求。同时,推荐系统的可解释性也非常重要,用户需要了解推荐系统是如何推荐的,以便更好地理解和接受推荐结果。
然而,深度学习推荐系统在未来的发展中也将面临一些挑战。首先,深度学习推荐系统需要大量的数据支持,而这些数据往往需要用户的授权和许可,因此如何保护用户隐私将成为一个重要问题。其次,深度学习推荐系统需要高度的计算资源和算法优化,这将对互联网企业的技术实力和投入提出更高要求。最后,深度学习推荐系统的可解释性和透明度也需要进一步提高,以便用户更好地理解和接受推荐结果。
审核编辑黄宇
-
智能化
+关注
关注
15文章
5276浏览量
60379 -
深度学习
+关注
关注
73文章
5614浏览量
124748 -
ChatGPT
+关注
关注
31文章
1608浏览量
10427
发布评论请先 登录
【智能检测】基于AI深度学习与飞拍技术的影像测量系统:实现高效精准的全自动光学检测与智能制造数据闭环
机载系统智能化的基石:分布式网络控制系统与容器虚拟化技术的深度融合实践

福州移动与华为联合推出国内首个端到端智能化体验经营系统
无人机巡检系统开启智能检测新时代
AI赋能6G与卫星通信:开启智能天网新时代
突破传统桎梏,PPEC Workbench 开启电源智能化设计新路径
图为科技锚定具身智能新时代:NVIDIA Jetson引领边缘计算融合创新

AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联
LCR测试仪如何实现智能化与AI融合

深度智能 基座跃迁 鸿道Intewell,面向“AI+智造”的新型工业操作系统

MS3142马达驱动开启消费类产品的智能化时代



评论