 CUDA编程分布式共享内存
CUDA编程分布式共享内存
Distributed Shared Memory
计算能力9.0中引入的线程块集群为线程块集群中的线程提供了访问集群中所有参与线程块的共享内存的能力。这种分区共享内存称为 Distributed Shared Memory,对应的地址空间称为分布式共享内存地址空间。属于线程块集群的线程可以在分布式地址空间中读、写或执行原子操作,而不管该地址属于本地线程块还是远程线程块。无论内核是否使用分布式共享内存,共享内存大小规格(静态的或动态的)仍然是每个线程块。分布式共享内存的大小就是每个集群的线程块数量乘以每个线程块的共享内存大小。
访问分布式共享内存中的数据需要所有线程块存在 。用户可以使用cluster .sync()从Cluster Group API中保证所有线程块已经开始执行。用户还需要确保在线程块退出之前完成所有分布式共享内存操作。
CUDA提供了一种访问分布式共享内存的机制,应用程序可以从利用它的功能中获益。让我们看看一个简单的直方图计算,以及如何使用线程块集群在GPU上优化它。 计算直方图的标准方法是在每个线程块的共享内存中进行计算,然后执行全局内存原子 。
这种方法的一个限制是共享内存容量。一旦直方图容器不再适合共享内存,用户就需要直接计算直方图,从而计算全局内存中的原子。对于分布式共享内存,CUDA提供了一个中间步骤,根据直方图桶的大小,直方图可以直接在共享内存、分布式共享内存或全局内存中计算。
下面的CUDA内核示例展示了如何在共享内存或分布式共享内存中计算直方图,具体取决于直方图箱的数量。
#include
// Distributed Shared memory histogram kernel
__global__ void clusterHist_kernel(int *bins, const int nbins, const int bins_per_block, const int *__restrict__ input,
size_t array_size)
{
extern __shared__ int smem[];
namespace cg = cooperative_groups;
int tid = cg::this_grid().thread_rank();
// Cluster initialization, size and calculating local bin offsets.
cg::cluster_group cluster = cg::this_cluster();
unsigned int clusterBlockRank = cluster.block_rank();
int cluster_size = cluster.dim_blocks().x;
for (int i = threadIdx.x; i < bins_per_block; i += blockDim.x)
{
smem[i] = 0; //Initialize shared memory histogram to zeros
}
// cluster synchronization ensures that shared memory is initialized to zero in
// all thread blocks in the cluster. It also ensures that all thread blocks
// have started executing and they exist concurrently.
cluster.sync();
for (int i = tid; i < array_size; i += blockDim.x * gridDim.x)
{
int ldata = input[i];
//Find the right histogram bin.
int binid = ldata;
if (ldata < 0)
binid = 0;
else if (ldata >= nbins)
binid = nbins - 1;
//Find destination block rank and offset for computing
//distributed shared memory histogram
int dst_block_rank = (int)(binid / bins_per_block);
int dst_offset = binid % bins_per_block;
//Pointer to target block shared memory
int *dst_smem = cluster.map_shared_rank(smem, dst_block_rank);
//Perform atomic update of the histogram bin
atomicAdd(dst_smem + dst_offset, 1);
}
// cluster synchronization is required to ensure all distributed shared
// memory operations are completed and no thread block exits while
// other thread blocks are still accessing distributed shared memory
cluster.sync();
// Perform global memory histogram, using the local distributed memory histogram
int *lbins = bins + cluster.block_rank() * bins_per_block;
for (int i = threadIdx.x; i < bins_per_block; i += blockDim.x)
{
atomicAdd(&lbins[i], smem[i]);
}
}
上面的内核可以在运行时启动,集群大小取决于所需的分布式共享内存的数量。如果直方图足够小,可以容纳一个块的共享内存,用户可以启动集群大小为1的内核。下面的代码片段展示了如何根据共享内存需求动态启动集群内核。
// Launch via extensible launch
{
cudaLaunchConfig_t config = {0};
config.gridDim = array_size / threads_per_block;
config.blockDim = threads_per_block;
// cluster_size depends on the histogram size.
// ( cluster_size == 1 ) implies no distributed shared memory, just thread block local shared memory
int cluster_size = 2; // size 2 is an example here
int nbins_per_block = nbins / cluster_size;
//dynamic shared memory size is per block.
//Distributed shared memory size = cluster_size * nbins_per_block * sizeof(int)
config.dynamicSmemBytes = nbins_per_block * sizeof(int);
CUDA_CHECK(::cudaFuncSetAttribute((void *)clusterHist_kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, config.dynamicSmemBytes));
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeClusterDimension;
attribute[0].val.clusterDim.x = cluster_size;
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
config.numAttrs = 1;
config.attrs = attribute;
cudaLaunchKernelEx(&config, clusterHist_kernel, bins, nbins, nbins_per_block, input, array_size);
}
-
gpu
+关注
关注
28文章
4754浏览量
129073 -
CUDA
+关注
关注
0文章
121浏览量
13643 -
API接口
+关注
关注
1文章
84浏览量
10467
发布评论请先 登录
相关推荐
分布式软件系统
使用分布式I/O进行实时部署系统的设计
在NI分布式管理器创建共享变量失败,想请教各位原因
利用NI VeriStand 2010特性创建分布式系统
分布式系统的优势是什么?
HarmonyOS应用开发-分布式设计
分布式软总线实现近场设备间统一的分布式通信管理能力如何?
vxworks驱动及分布式编程

CUDA 6中的统一内存模型
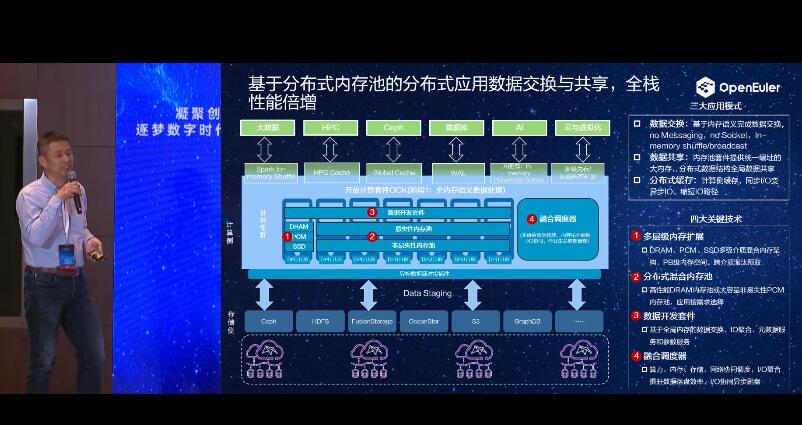
欧拉(openEuler)Summit2021:基于分布式内存池的分布式应用数据交换与共享
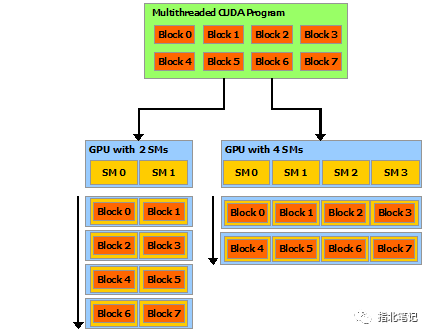
CUDA简介: CUDA编程模型概述
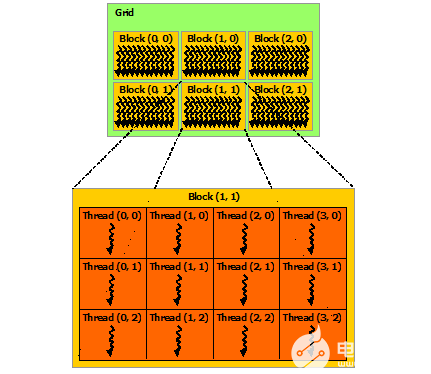
介绍CUDA编程模型及CUDA线程体系





 工商网监
工商网监
评论