 时钟树综合CTS阶段如何去降低Latency和Skew
时钟树综合CTS阶段如何去降低Latency和Skew
对于时钟树综合,各位后端工程师应该都很熟悉,做好一个模块/一个chip的时钟树,对整个项目的功耗和Timing影响都是巨大的。一个优秀的后端工程师,也不会只是单纯的放置几个TAP点,来工具根据source group来自己分点做Tree,这样只会跑flow 做树的工程师在面对工具搞不定的复杂时钟结构的时候,只能束手无策,导致绕线完返修,花费很多时间在signoff阶段,对时序和功耗硬修,甚至导致流片delay,今天我们就来根据项目经验来帮助大家做出更好,更完美的时钟树!
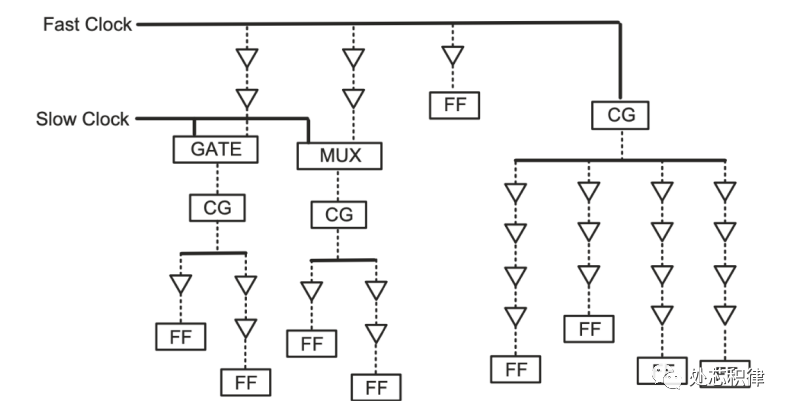
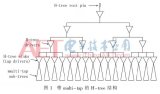
图一 一个最常见的muti Clock的时钟树结构
首先我们要明白做树的最终目的—当然是为了PPA的提升,其实不做树可不可以?当然可以!当你当前的模块规模比较小,且没啥时序风险和PV,PI风险的时候,甚至可以不做树。但是时钟结构复杂/时序功耗本身就有风险的模块就不行了,树做的不好将会导致ecoRoute完signoff阶段的时序收不下来,功耗很差,甚至根本没法收敛,导致最后回退版本,老老实实回去做树!那小编觉得就完全没有必要了,我们以innovus为例,来帮助大家快速做到对树的收敛,从而对CTS有更深的理解,而非只会跑flow看结果。
其实对于CTS这个步骤,我们可以把从初始时钟结构到最终的时钟树结构分为三个阶段,并且在这三个阶段分别去存对应的Database,以方便分析究竟是哪一步出问题了?
第一部分—分点,这一部分主要靠工具去完成,工具会识别后端工程师提供的source group(这个根据工程师设置的tap点来定组),并将同一skew group下source group下面的对应tap点(可以是MUX,BUFF,INV,ICG等等)的OutPutPin的generate clk视为一样的时钟结构,进而工具会clone主Gating下除Sink点以外的原本时钟路径上的逻辑单元和时序单元,并将整条Path包含Sink点挂到离其最近,时序更优的Tap点下,这一分点形成初始树的过程,在Innovus下通过以下命令实现:

对于复杂的时钟结构,即多个分频时钟,倍频CRG子时钟,工具没办法很好的去分点或者说没有过多的考虑时序,而是单纯考虑距离,对Sink点进行暴力切分,导致Common Path的长度非常的短,共同路径由source port到clone gating变成只有source port到主 ICG,这有可能会使得不同分点下的两个Sink的local skew偏大,进而影响postCTS后的timing。这种情况我们可以通过分点完后自己手动ec挂点/分点前在Spec约束文件添加preserve port来控制工具的分点结果。
第二部分—Cluster解DRV,这一部分也主要靠工具去完成,在开始这步骤之前,工程师需要检测对于部分Net有么有设置dont touch,有没有设置ideal net,以免CTS综合后发现部分CK Cell的transition过大,一追溯发现是DRV没有解决,这一部分引起latency增大的原因其实主要是因为Placement摆放CK cell位置的不合理,使得时钟路径发生了detour,增加了Net delay和部分本可以不存在的解transiton的INV。这一部分遇到问题的主要解决办法为:1.检查place阶段是不是有些Sink的局部density过大/过小,导致工具在修DRV的时候拉扯较远/没有位置摆放INV;2.手动ec,将最后一级INV的Fanout Sink直接挂到最近一级Clone的gating上,再解DRV(记得带个强驱动的BUFF一起挂,否则可能会因为clone gating的outputload突然增大而导致transition解的不好,传递到下几级,导致latency增大)
第三部分—Full阶段长树,这一部分工具会根据你的Spec约束来对Sink之间的Skew进行平衡,在innovus中我们一般通过ccopt_design来进行长tree和OPT同步的操作,实际上innovus在ccopt阶段初期,首先会确定placement的信息,其中包括density和DRC的相关信息的check,然后在准备阶段,innovus会刷新一遍IO的skew,并判断各个skewgroup之间的关系,哪个是主clk,哪个是generateclk,是否存在复制关系?在判断完skewgroup的复制关系后,innovus会进行early global route,进行快速绕线,以判断有没有绕线风险,并且检查检查NDR以及track的完整性等等。
所以基于以上工具的三个阶段操作,后端APR工程师们需要明确分点做树的阶段目标是什么?1.降低latency,以与其他模块的时钟树串起来对齐;2.降低local skew,以减少后期fix timing工作量,降低timing风险;3.增加common path的delay,目的也是为了降低latency和local skew;4.减少CK cell的数量,有利于降低面积和功耗。在这里,小编基于日常项目给出几种做短树的latency和做小skew的方法:
增加TAP点的数量,这个方法虽然可以有效的降低skew和latency,但是会带来功耗负担以及面积浪费,并且随着TAP点增加到一定数量,收益其实会逐渐收敛。所以这个方法后端工程师最好建立在规定数量TAP点实在修不下来delay和skew的时候再使用。
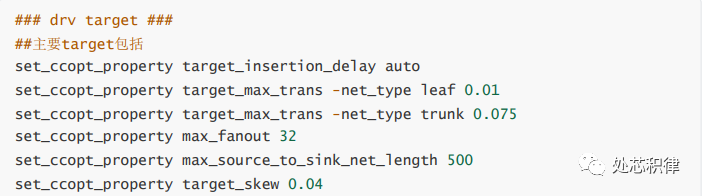
修改target来优化工具的分点和balance长树,内容主要包括(注: 修改要在clk spec生产后,即generate spec后分点前)
增加new skrewgroup以及generated clk来指导工具解drv和长tree(这个主要优化latency,skew变化并不大),以图一的CLK结构为例子,Fast Clk下MUX的ZN端可以设置generate CLK,并以这个为source,设置一个新的skew group.

Size up时钟路径上的icg以及buffer/inv,logic等instance,这样可以增加驱动,降低transition,进而降低latency(这种方式不仅会优化latency,skew也会由一定的优化),比如D4的DCCKBUF换成D8的BUFF,H12的BUFF换成H9的BUFF等等。
可以通过提树/推树的xxx ps的方法,来做长做短树,Place阶段推树/cts阶段设置insertation delay都有利于树的做短(这个方法主要影响的是balance长tree阶段),这个通常可以针对cluster阶段latency不大,但是balance长tree阶段突然树长变长的path,例如

修改Space中的CK Pin的类型,有些不影响Timing的前提下把Pin设置成为stop ignore throughpin(这个方法主要影响的是balance长tree阶段)
一些ec操作,一般是工具分点/解DRV有问题的时候,才需要工程师去手动,比如重新挂点,presever pin,手动clone icg挂点等等
掌握了以上这些内容,想必各位ICer将会对CTS有更深的理解,CTS的实现其实随着模块时钟复杂的变化会有更多其他方法去降低Latency以及Skew,例如调整flowPlan,与前端商量修改RTL代码的时钟结构,修改综合时候map的lib cell,引入Mesh Cell等等。但是所有的一切,都是为了芯片有个更好的PPA,这样才能让你和大家的加班没有白费!
审核编辑:刘清
-
DRV
+关注
关注
0文章
18浏览量
20638 -
时钟树
+关注
关注
0文章
53浏览量
10732 -
Mux
+关注
关注
0文章
38浏览量
23350 -
CTS
+关注
关注
0文章
34浏览量
14054
原文标题:细聊时钟树综合CTS阶段如何去降低Latency和Skew
文章出处:【微信号:处芯积律,微信公众号:处芯积律】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
射频识别芯片设计中时钟树功耗的优化与实现
数字IC设计中的分段时钟树综合
哪些因此会导致时钟skew过大呢?FPGA中降低时钟skew的几种方法





 工商网监
工商网监
评论