 不同树种叶片养分含量提取的高光谱方法及精度评价-莱森光学
不同树种叶片养分含量提取的高光谱方法及精度评价-莱森光学
引言
氮(N)、磷(P)、钾(K)是作物生长发育必需的大量元素,任何一种元素的缺乏不仅会影响作物生长速度和产量,还会引起植株体内相关生化成分的变化。了解作物的营养水平,及时进行追肥决策,可为珍稀濒危植物实行精准栽培管理和保护提供理论依据。实时、快速、无损和准确的植被营养水平快速检测方法在管理中很有必要。光谱技术具有分析速度快、效率高、成本低、重现性好和测试方便等特点,是探测和获取作物营养状态和长势信息的有效手段。植物营养状况与其叶片光谱特征密切相关,故探究植被N、P、K元素含量与光谱数据的关系,建立光谱估算模型,可为各种植被营养元素含量实时快速检测提供技术手段,对珍稀植被的科学管理具有重要的现实意义。国内外学者对水稻、油菜、小麦、番茄、果树、蔬菜等作物的N、P、K含量光谱估算模型进行了大量研究。如Li等通过发现油菜叶片的光谱数据可用于估算磷、铁含量的变化。Wright等利用遥感数据建立光谱与小麦N含量的二次多项式模型,模型决定系数(R2)为0.52~0.80;Fitzgerald等利用光谱预测了小麦氮素水平,所建立的小麦氮素模型预测的相对系数达到0.97,均方差为0.65。黄双萍等对反射光谱进行各种预处理后,对柑橘叶片磷含量进行了建模,最佳模型决定系数分别为0.905、0.881;邢东兴等对红富士苹果树氮、磷、钾含量与光谱反射率及其多种变换形式进行相关性分析,并建立了偏最小二乘回归模型。张瑶等利用光谱分析技术建立苹果叶片氮素预测模型,最终得到采用支持向量机建立的氮素回归模型,其测定和验证绝对系数均达到0.74以上,上述研究多基于农田施肥试验下的农作物和果树开展,较少涉及自然生长下林木。另外,可见光近红外光谱进行叶片养分监测时,模型精度与叶片结构、测量环境等密切相关,但当前植被养分监测中,关于不同处理方法对模型精度影响的研究相对较少。
对数据进行可靠的预处理可以提高模型的精度,有研究表明,基线校正(BC)能够有效抑制由于光谱测量的背景因素及叶片表面杂质造成的基线漂移;标准正态变换(NV)通过对每个单独的光谱(即一个面向采样的标准化)的中心和缩放来消除散射效应;多元散射校正(MSC)能有效校正由光程变化对光谱造成的影响,改善信噪比,消除漫反射光谱的基线以及光谱的不重复性;Savitzky-Gola(SG)平滑滤波可以提高光谱的平滑性并降低噪音的干扰,其中一阶微分可以去除同波长无关的漂移,二阶微分可以去除同波长线性相关的漂移。
同时高光谱具有波段多、光谱范围窄、数据量大等缺点,需要对其进行降维,以提高模型的运算速率,防止模型过拟合。其中,线性降维方法主成分分析(PCA)是目前应用最为广泛的降维方法之一,PCA降维依据方差最大化原理,将数据从高维空间向低维空间映射。非线性降维方法核主成分分析(KPCA)和多维尺度分析(MDS)保留了全局特征,其中,KPCA基于核函数原理,可以有效提取非线性特征,通过非线性映射将输入空间投影到高纬度空间,在高纬度特征空间对映射数据作主成分分析,MDS则是利用成对样本间的相似性构建合适的低维空间。上述高维数据降维方法已在多个领域被广泛应用,但关于叶片高光谱数据降维对林木叶片养分预测性能的研究相对较少,结果也不一致。
因此,本研究基于深圳市大鹏半岛自然保护区和坝光古银叶树湿地园的19种树种叶片反射光谱,拟分析原始光谱、基线矫正、多元散射校正、正交信号校正、标准正态变换、SG一阶导数、SG二阶导数等预处理方式对养分建模精度的影响,并对比3种数据降维方式对模型精度的影响,探讨叶片养分快速诊断的最佳数据预处理方式、数据降维方式以及反演算法对模型精度的影响,以期为林木叶片养分快速检测和基于遥感的林业管理提供依据。
材料与方法
2.1 研究区概况
深圳市大鹏半岛自然保护区于2010年获批准成立,总面积144.05km2,包括笔架山、排牙山、鹅公村周边山地森林、坝光红树林、西冲香蒲桃林和东涌红树林等区域。保护区有1000多种野生植物、200多种陆生脊椎动物和几十种珍稀濒危物种,是全国首个建立在城市内的以森林生态类型为主的自然保护区。坝光银叶树湿地园位于大鹏半岛最北端,海拔0~20m,处于亚热带季风气候区。坝光银叶树群落是全世界发现的树龄最长的天然古银叶树群落。银叶树属于梧桐科银叶树属,为热带、亚热带海岸红树林植物,多分布于高潮线附近的海滩内缘,以及潮水淹及滩地,属于典型的水陆两栖的红树植物。该银叶树群落主要分布在滨海沼泽湿地生境,远离海岸的陆地生境以及邻海陆地生境内海湾滩地的海生环境。群落内除了银叶树外,其他建群种还包括阴香、假苹婆、多毛茜草树、海杧果、银柴、鸭脚木、细叶榕等阔叶树种。
2.2 样本采集
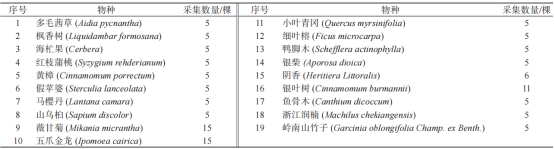
共采集19种典型树种共122棵数据,具体采集树种和棵数见表1所示。每棵树沿树冠一周,用采样剪均匀选择冠层3个方向的枝条,每棵枝条上选择9片健康叶片用清水洗净,用干净棉布擦干,入保鲜袋装好并编号。
表1 本研究使用的树种类别
2.3 研究方法
2.3.1植物叶片光谱的采集
叶片野外光谱数据采用便携式地物光谱仪进行采集,并加装10°视场镜头。波长范围在350~2500nm,输出间隔为1nm。每次测定光谱前进行暗电流去除和白板校正,分别在叶尖、叶中、叶根采集3次,取其平均值作为该叶片的光谱反射值,同一棵树的叶片光谱反射值均值作为一个样本的光谱,利用软件求算数平均得到122个样本的反射光谱数据。
2.3.2养分值测定
同步采集叶片并送检,将同一棵树的叶片捣碎混合测定全氮、全磷、全钾的均值,其中薇甘菊和五爪金龙采取单枝条测定养分值含量。植物全氮磷钾的测定按农业标准(NY/T2017-2011)测定,植物样品用硫酸-过氧化氢消煮,采用全自动定氮仪测定植物全氮(N),以钼锑抗吸光光度法测定全磷(P),以火焰光度法测定全钾(TK)。
2.4 高光谱数据预处理和降维方法
使用Unscrambler10.4软件对植物的光谱数据进行11种预处理(包含4种组合方法):基线较正(Baseline)、多元散射较正(MSC)、标准正态变换处理(SNV)、一阶导数处理、二阶导数处理、基线较正结合一阶导数处理(baseline+1st)、基线较正结合二阶导数处理(baseline+2nd)、标准正态变换结合一阶导数处理(SNV+1st)、标准正态变换结合二阶导数处理(SNV+2nd)、多元散射较正结合一阶导数处理(MSC+1st)、多元散射较正结合二阶导数处理(MSC+2nd)。对原始光谱进行去噪,将噪声较大的波段350~379、1351~1429、1801~1949和2401~2500nm的光谱数据予以剔除。基于Matlab2017b数据降维工具箱,采用PCA、KPCA和MDS对叶片光谱数据进行降维处理。
2.5 建模集和预测集的划分
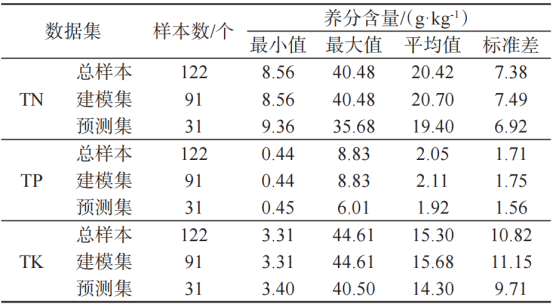
将122个样本按物种首字母大小顺序排序,每隔4个样本取出1个做预测集,保证每种植物都有一组或者一组以上的数据作为预测集,共取得预测集31个,其余91个作为建模集样本,最终建模集和预测集样本比例约为3∶1,建模样本和预测样本的各养分元素样本范围基本一致且分布均匀(表2)。由表2可知,各样本间具有一定的差异性,建模集和预测集平均值相近,标准差均较小。
表2 各养分含量描述性统计分析
2.6 模型构建
采用偏最小二乘回归(PLSR)和支持向量机回归(SVR)建立高光谱数据和营养含量的回归模型。选取建模集决定系数(R2C)、均方根误差(RMSEc),交叉验证集决定系数(R2cv)、均方根误差(RMSEcv)、和相对分析误差(RPD)综合评价模型的效果。其中,R2越大、RMSE越小,表明模型预测效果越好,R2C和R2cv的差值越小说明模型稳定,其中相对分析误差的计算公式为:
RPD=SD/RMSEp(1)
式中:SD为验证集样本标准差;RMSEp验证集均方根误差。当RPD≥2.0,说明模型具有极好的定量预测能力;当1.4<2.0时,说明模型预测能力较好,可对样品进行估测;当rpd≤1.4时,则认为模型不可靠。<>
结果与分析
3.1 不同光谱预处理方法下模型精度对比
计算不同光谱数据预处理方式下TN、TP和TK监测模型的平均精度,结果表明,采用不同的数据预处理可以提高模型的建模和预测精度,其中SNV与一阶导数结合的预处理方式,3种养分指标建模的平均精度最高(图1)。
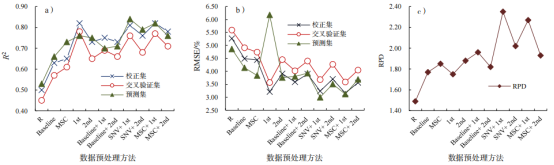
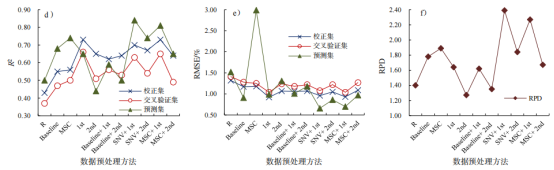
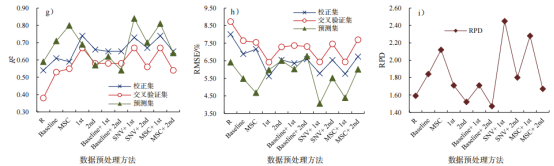
图1不同光谱预处理方式下TN(a、b、c)、TP(d、e、f)和TK(g、h、i)模型精度对比
TN的模型中(图1-a、b、c),不同预处理下,预测模型确定系数从0.53提高到0.84,预测均方根误差从4.86%下降到3.00%。一阶导数和二阶导数处理后,模型性能比Baseline或MSC处理下的模型性能高。Baseline、SNV、MSC与导数处理结合可以进一步提高模型性能,其中SNV+1st处理后模型精度最高,建模模型确定系数为0.81,均方根误差为3.24%;预测集确定系数为0.84,均方根误差为3.00%,RPD为2.35。从图1-d、e、f可以看出,经过光谱数据预处理后,TP预测模型确定系数从0.50提升到0.84,预测均方根误差从1.52%下降到0.66%,RPD为2.39。与TN有相似之处,两种预处理方式结合相比单一预处理,模型精度有所提升。其中SNV+1st的预处理方式,模型精度最高,建模模型确定系数为0.81,均方根误差为0.96%;预测模型确定系数为0.84,均方根误差为0.66%,模型RPD值为2.39。由图1-g、h、i可以看出,经预处理,TK预测模型确定系数从0.59提升至0.84,均方根误差从6.41%下降到4.06%。其中,SNV+1st预处理下,模型的平均精度最高,建模模型确定系数为0.73,均方根误差为5.78;预测模型确定系数为0.84,均方根误差为4.06%,RPD值为2.45。
3.2 不同降维处理和建模方法下模型精度的比较
图2显示了不同数据降维方法下模型精度的差异,3种数据降维处理中,PCA降维处理后的模型精度最高,KernelPCA算法次之,MDS算法最低,但降维处理后模型精度低于未降维处理的模型精度。PCA降维处理后TN模型的平均R2C、R2cv、RMSEc、RMSEcv、R2p、RMSEp和RPD分别为0.78、0.73、3.48%、3.89%、0.77、3.50%和2.04。TP模型的R2C、R2cv、RMSEc、RMSEcv、R2p、RMSEp和RPD分别为0.69、0.61、1.00%、1.12%、0.70、1.01%和1.83。TK模型的R2C、R2cv、RMSEc、RMSEcv、R2p、RMSEp和RPD分别为0.71、0.64、6.09%、6.78%、0.72、5.34%和1.91。
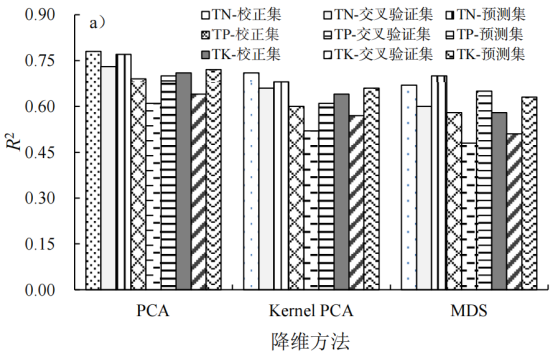
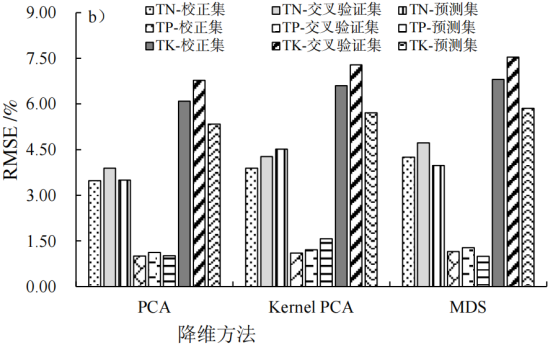
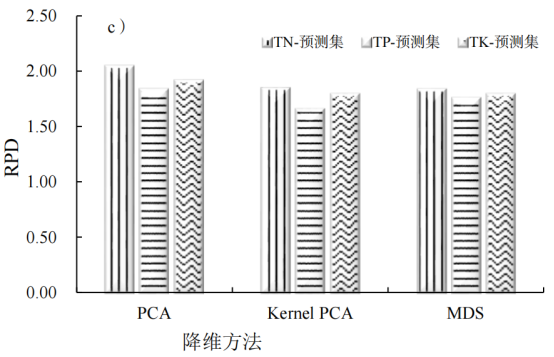
图2不同降维方法下TN、TP和TK模型精度
讨论
综上所述,MSC、Baseline、SNV、一阶导数和二阶导数处理具有提升模型预测精度能力,一阶导数、二阶导数与MSC、Baseline、SNV结合能进一步提高模型对参数的预测性能,这与已有研究关于不同光谱预处理方式对土壤等地物的光谱分类和预测模型精度影响的结论一致。本研究涉及19种不同的树种,不同树种的叶片结构差异较大。SNV+1st处理可以有效消除基线和其他背景的干扰,消除表面散射和光程对光谱的影响,最大程度提高模型预测参数的性能。采用PCA算法、非线性的基于核的PCA降维和MDS进行降维处理,所建立的模型精度存在差异,其中,PCA降维算法所得的模型精度最高。从模型确定系数和RPD值发现,PLSR和SVR都可以用于叶片养分建模,不同建模方法模型精度存在差异,交叉验证和独立验证结果均表明SVR模型比PLSR模型在TN、TP、TK快速检测中精度更高,因此认为SVR模型更适合可见光近红外光谱叶片养分建模,这与Xu等的研究结论基本一致。SVR模型性能较PLSR模型性能好,可能与叶片TN、TP、TK与光谱数据间的非线性程度相关。可见光近红外光谱数据和叶片养分之间由于测量环境或者化学分析等外部因素可能增强这种非线性关系。
表3 不同建模方法下TN、TP和TK模型的精度
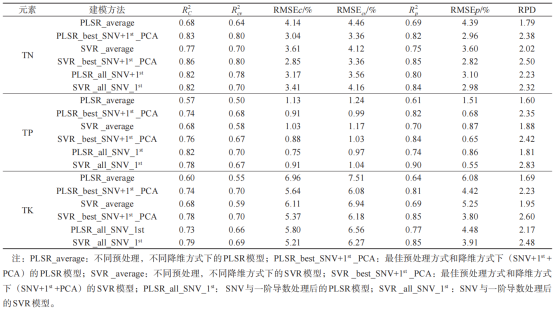
结论
以深圳市坝光银叶园和大鹏半岛自然保护区主要半红树树种叶片的可见光近红外光谱与TN、TP、TK含量关系为基础,探讨了不同光谱数据预处理方法、不同数据降维方法、不同建模方法对模型精度的影响。结果表明,适当的预处理可以提高养分指标建模的精度,其中,SNV结合一阶导数的处理方式,在3种养分指标建模中,性能均最好。3种数据降维方式的对比结果显示,PCA降维处理的模型精度最高,PLSR和SVR模型交叉验证和外部验证的结果均表明,SVR模型的性能最好。SNV一阶导数处理后数据进行PCA降维建立的SVR模型在各个模型中性能最好。
本研究发现模型监测叶片生化组分的能力与光谱数据预处理方法、建模方法等具有密切的关系,但未进行养分建模的光谱特征分析。后续研究将进一步探讨叶片养分建模的机理,并结合机器学习等方法,探索光谱特征选择和机器学习算法对叶片生化组分建模和预测精度的影响。
推荐:
便携式地物光谱仪iSpecField-NIR/WNIR
专门用于野外遥感测量、土壤环境、矿物地质勘探等领域的最新明星产品,由于其操作灵活、便携方便、光谱测试速度快、光谱数据准确是一款真正意义上便携式地物光谱仪。

无人机机载高光谱成像系统iSpecHyper-VM100
一款基于小型多旋翼无人机机载高光谱成像系统,该系统由高光谱成像相机、稳定云台、机载控制与数据采集模块、机载供电模块等部分组成。无人机机载高光谱成像系统通过独特的内置式或外部扫描和稳定控制,有效地解决了在微型无人机搭载推扫式高光谱照相机时,由于振动引起的图像质量较差的问题,并具备较高的光谱分辨率和良好的成像性能。

便携式高光谱成像系统iSpecHyper-VS1000
专门用于公安刑侦、物证鉴定、医学医疗、精准农业、矿物地质勘探等领域的最新产品,主要优势具有体积小、帧率高、高光谱分辨率高、高像质等性价比特点采用了透射光栅内推扫原理高光谱成像,系统集成高性能数据采集与分析处理系统,高速USB3.0接口传输,全靶面高成像质量光学设计,物镜接口为标准C-Mount,可根据用户需求更换物镜。

审核编辑黄宇
-
成像系统
+关注
关注
2文章
201浏览量
14025 -
无人机
+关注
关注
230文章
10582浏览量
183531 -
高光谱
+关注
关注
0文章
365浏览量
10060
发布评论请先 登录
相关推荐
基于近红外高光谱图像的花生内部霉变快速判别方法研究-莱森光学

莱森光学:光致发光量子效率光谱系统的测量精度是多少?


基于高光谱遥感数据的辣椒叶片叶绿素含量反演
地物光谱仪:水稻高光谱与叶绿素含量研究

从哪些角度选择高光谱遥感成像光谱仪?这些厂家比较有实力!
iSpecField-NIR便携式地物光谱仪:多领域应用的高效工具
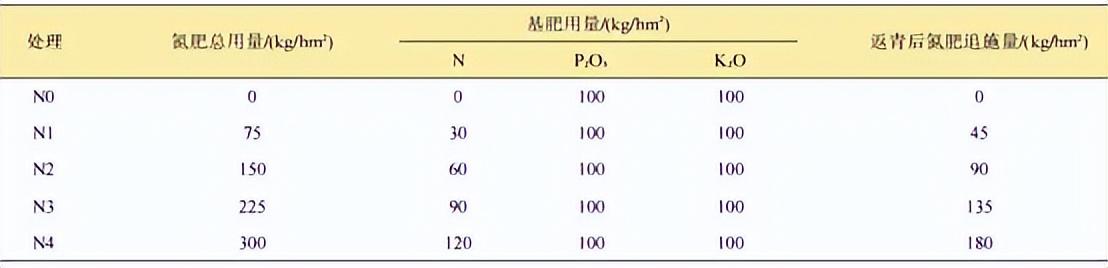
利用高光谱技术估测小麦叶片氮量和土壤供氮水平
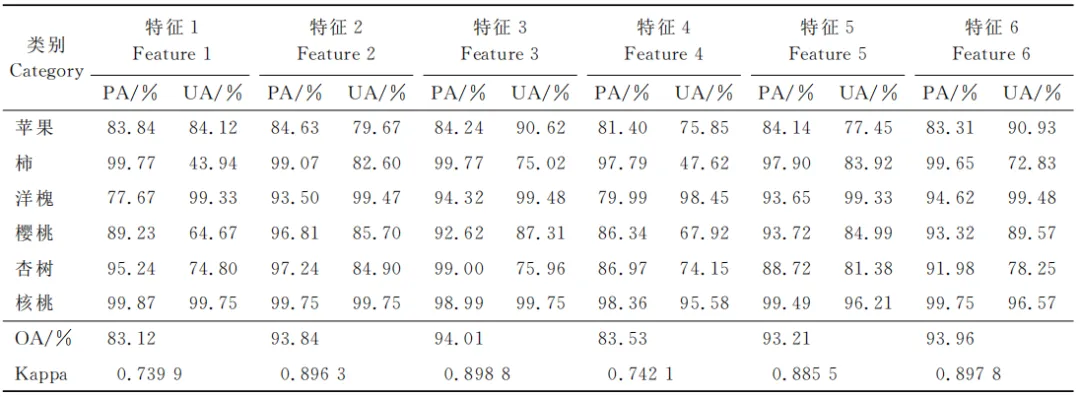
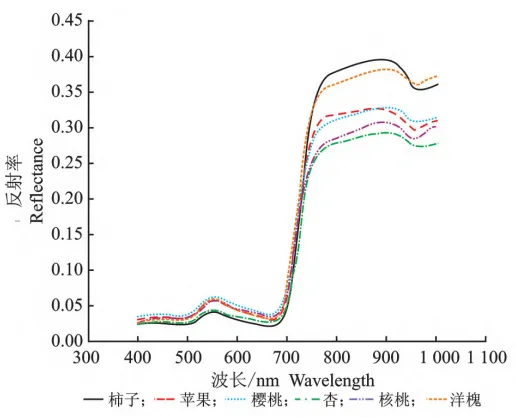
高光谱成像系统:深度学习机载高光谱影像树种分类研究
基于高光谱成像的蔬菜新鲜度检测






 工商网监
工商网监
评论