 GPT-4 的模型结构和训练方法
GPT-4 的模型结构和训练方法
在 GPT-4 的发布报道上,GPT-4 的多模态能力让人印象深刻,它可以理解图片内容给出图片描述,甚至能在图片内容的基础上理解其中的隐喻或推断下一时刻的发展。无疑,面向所谓的 AGI(通用人工智能),多模态显然是必经之路。但是遗憾 GPT-4 的图片输入能力尚且没有完全放开,而即使放开我们对 GPT-4 的模型结构和训练方法也知之甚少。
而最近,中科院自动化所带来了一项有趣的工作,推出了多模态的大规模语言模型 X-LLM,同时支持图片、语音以及视频等多种模态信息作为大模型的输入,并且展现了类似于 GPT-4 的表现。比如当输入图像时,X-LLM 可以识别图像位置、理解图像中的食物。当输入视频时,X-LLM 也可以总结视频内容,检索电影片段的电影名称,基于视频内容结合图像回答问题等等。以论文中的一张图片为例,当用户希望 X-LLM 介绍输入的图片时,X-LLM 准确的理解了图片相关于游戏王者荣耀,并且给出了一定的介绍。
从性能来看,作者团队使用了 30 张模型未见过的图像,每张图像都与相关于对话、详细描述以及推理三类的问题,从而形成了 90 个指令-图像对以测试 X-LLM 与 GPT-4 的表现。可以看到,通过使用 ChatGPT 从 1 到 10 为模型回复进行评分,与 GPT-4 相比 X-LLM 取得了 84.5% 的相对分数,表明了模型在多模态的环境中是有效的。

除此之外,这篇工作也开源了相关的代码和一个简洁高质量的中文多模态指令数据集,帮助后续工作使用 X-LLM 的框架进行研究,
在进入论文之前,首先来想想一个问题,GPT-4 是如何获得其强大的多模态能力的呢?论文作者给出了一个假设:“GPT-4 的多模态能力来源于其更先进,更大的语音模型,即 GPT-4 是用语言的形式表达出了其他模态的内容”。
这个假设也就是讲,需要将多模态的数据“对齐”到语言数据之中,然后再投入大模型以获得多模态能力,在这个假设的基础上,作者提出了 X2L 接口,其中 X 意味着多模态数据,而 L 则表示语言,X2L 接口即将多个单模态编码器与一个大规模语言模型(LLM)进行对齐。其中,图像接口 I2L 采用 BLIP-2 中的 Q-Former,视频接口 V2L 复用图像接口的参数,但是考虑了编码后的视频特征,语言接口 S2L 采用 CIF 与 Transformer 结构将语音转换为语言。整个 X-LLM 的训练包含三个阶段,分别是(1)转换多模态信息;(2)将 X2L 对齐到 LLM;(3)将多模态数据整合到 LLM 中。
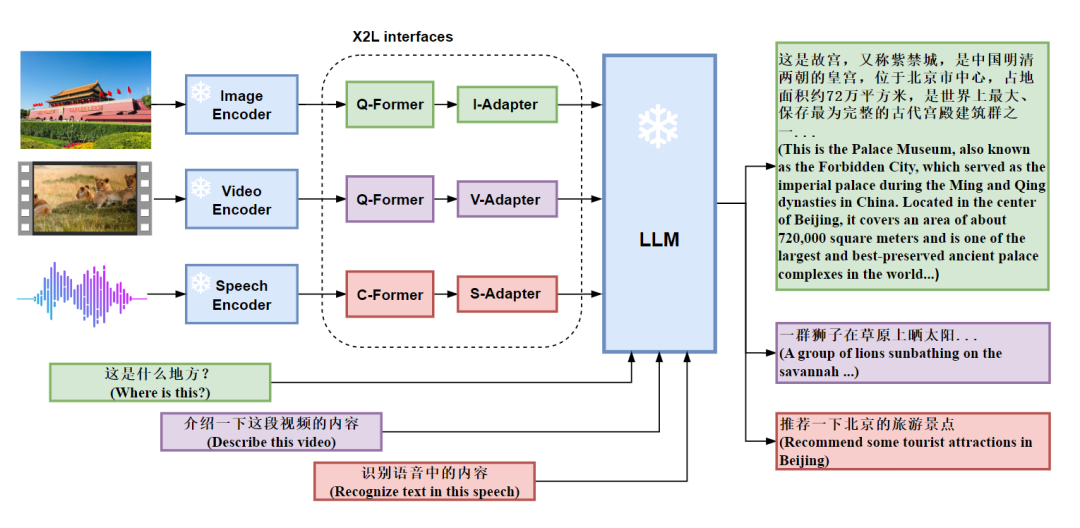
具体而言,多模态信息转换的三个接口设计如下:
图像接口:图像接口由 Q-Formers 和 I-Adapter 模块组成。Q-Formers的目标是将图像转换为语言,将从图像编码器获得的图像特征转换为长度为 L 的准语言嵌入的序列。I-Adapter 模块旨在对齐准语言嵌入的维数和 LLM 的嵌入维数;
视频接口:视频接口与图像接口采用相同的结构,并且均匀采样使用 T 帧表示每个视频,再将每帧视频视为图像,构建长度为 T x L 的准语言嵌入序列;
语言接口:语音接口由两部分组成,即 C-Former 和 S-Adaptor。C-Former 是 CIF 模块和 12 层 Transformer 模块的组合。CIF 模块通过变长下采样将语音编码器的语音特征序列压缩为相同长度的令牌级语音嵌入序列,而 Transformer 结构为令牌级语音嵌入提供了更强的上下文建模。S-Adaptor 用于将 Transformer 结构的输出投影到 LLM 的输入向量空间,从而进一步缩小了语音与语言之间的差距。
而在第二阶段,Q-Former 的参数来源于 BLIP2 中的 Q-Former 的参数。为了使得 Q-Former 适应中文 LLM,作者们使用了一个总共包括约 1400 万个中文图片-文本对的数据集进行训练,并使用图片中训练好的接口初始化视频中的 Q-Former 和 V-Adapter,最后,使用 ASR 数据训练语音接口,使语音界面的输出与 LLM 对齐。在整个过程中,Encoder 部分与 LLM 部分都不参与训练,只有接口部分进行训练。
而最后第三阶段,论文使用多模态联合训练增强 X-LLM 的多模态能力,但是可以看到,在没有进行联合训练时,X-LLM 已经具有了识别多模态的能力,这种能力很有可能是来自于 LLM。而为了进行联合训练,作者构建了一个多模态指令数据集对接口进行微调,包含(1) 图像-文本指令数据,(2)语音-文本指令数据,(3) 视频-文本指令数据以及 (4) 图像-文本-语音指令数据。整个数据集主要来源于 MiniGPT-4(图像,3.5k)、AISHELL-2(语音,2k)以及 ActivityNet(视频,1k)。
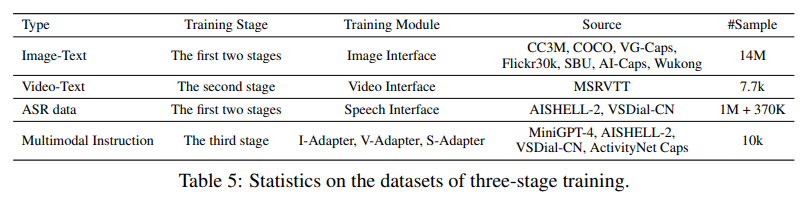
而在实验方面,论文作者开发了一个聊天界面,用以与其他开源的多模态大规模语言模型( LLaVA 与 MiniGPT-4)做对比,整体而言,X-LLM 具备了相当不错的阅读和理解图片的能力,并且可以更好的捕捉其中具有“中国特色”的预料,如下图问答所示,当输入天安门的图片时,X-LLM 准确的识别出了它是北京的故宫,并且给出了一些历史的介绍,而相应 LLaVA 与 MiniGPT-4 仅仅识别出来了中国的宫殿和旗帜,但是并没有提到 Forbidden City。
同时,X-LLM 也能准确的识别和理解语音信息,这里的“详细描述一下这个“照片”是以语音形式进行的输入,可以看到 X-LLM 也能给出相当不错的回答,并且可以进行延申交流。
此外,在视频问答方面,X-LLM 也表现得相当不错,对于输入的水母游动的视频,X-LLM 可以颇为准确的为视频做出标题,并配以文字。
对于敏感信息,X-LLM 也能做到识别
除了 X-LLM 这样一个将大规模语音模型向多模态方向扎实推进了一步的框架外,作者也意外的发现,在英文数据集上训练的 Q-former 的参数可以转移到其他语言(汉语),并仍然保持有效性。这种语言的可传递性极大地增加了使用英语图像文本数据和其训练的模型参数平移到其他语言中的可能性,并提高了在其他语言中训练多模态 LLM 的效率。
透过这篇工作,或许我们可以一窥多模态大模型光明的未来,回到开头,多模型必然是 AGI 的必经之路,那么以语言为基准统一多模态可不可以实现呢?那就要看跟随这篇工作出现的未来了吧!
-
数据
+关注
关注
8文章
7047浏览量
89068 -
模型
+关注
关注
1文章
3247浏览量
48856 -
语言模型
+关注
关注
0文章
526浏览量
10277
原文标题:中科院发布多模态 ChatGPT,图片、语言、视频都可以 Chat ?中文多模态大模型力作
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ChatGPT升级 OpenAI史上最强大模型GPT-4发布
GPT-4多模态模型发布,对ChatGPT的升级和断崖式领先
最新、最强大的模型GPT-4将向美国政府机构开放
人工通用智能的火花:GPT-4的早期实验
GPT-4已经会自己设计芯片了吗?
GPT-4催生的接口IP市场空间
爆了!GPT-4模型架构、训练成本、数据集信息都被扒出来了

OpenAI宣布GPT-4 API全面开放使用!
GPT-3.5 vs GPT-4:ChatGPT Plus 值得订阅费吗 国内怎么付费?
GPT-4没有推理能力吗?
OpenAI最新大模型曝光!剑指多模态,GPT-4之后最大升级!

ChatGPT plus有什么功能?OpenAI 发布 GPT-4 Turbo 目前我们所知道的功能






 工商网监
工商网监
评论