 深度剖析FPGA架构
深度剖析FPGA架构
FPGA 即 Field Programmable Gate Arrays,现场可编程门阵列。如果逻辑代数为数字世界的理论指导,那么逻辑门电路就是盖起座座数字大厦的基本块块砖瓦,无论基本的数字电路还是现代的集成电路,无不构建在逻辑门之上,把逻辑门和时钟组合起来,人们搭建起了加法器、选择器、锁存器、触发器,进而的运算单元、可控制单元、RAM。按照聪明的工程师设计好的电路图纸再将这些基本的数字电路原件组合起来,再设计成可以印刷的集成电路形式,就可以构成各种专用的集成电路(ASIC)或者通用计算机处理器(CPU)等。FPGA相对ASIC来说更灵活。ASIC相对来说量产后会更廉价、节能,性能也更好。
专用集成电路只在意输入和输出,中间的一切算法会被固化到硬件设计中;而通用CPU则同时接收数据流和指令流,按照软件工程师的程序指令序列执行一些列计算任务(虽有人将CPU也归为ASIC,但是我觉得这是在硬件角度上来说的,从计算任务的可编程性角度CPU实际上是最灵活通用的)。FPGA则介于ASIC和CPU之间,它并非将逻辑门组成的原件之间的连接形式固化,也非做成最有利通用计算的形式动态地接收软件指令来调动片上已有的计算单元,而是可以通过重复硬件编程来改变它逻辑门所组成的基本功能单元和调整这些单元之间的连接关系。
1. 硬件架构介绍
1.1 Overview
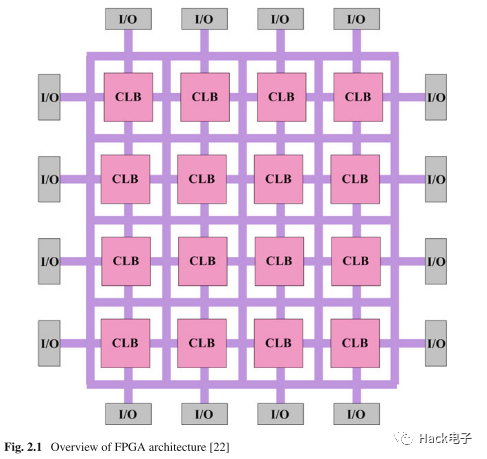
如下图所示,逻辑上,FPGA主要由可编程的逻辑块(programmable logic block, 主要是图中CLB) 和 可编程互联网络 (programmable interconnect network / routing interconnect, 主要是图中SB, CB和一些路由通道组成)。
+-----------+
| |
| LUT +-+
| | | +--------+ +-----------+
+-----------+ | | | | |
+----> BLE +----> CLB +----+
+-----------+ | | | | | |
| | | +--------+ +-----------+ |
| Flip-Flop +-+ |
| | +---------------------+ |
+-----------+ | | |
| Switch Box (SB) +----+
| | |
+---------------------+ |
+---> FPGA
+---------------------+ |
| | |
| Connection Box +----+
| (CB) | |
+---------------------+ |
|
+---------------------+ |
| | |
| I/O Block | |
| +----+
+---------------------+
空间布局上,可以简单理解为下图[1]:
- 按编程技术分类FPGA
FPGA的基础,即可配置性依赖于存储这些硬件门配置的介质,这种区别也成为FPGA的编程技术,按照这种硬件编程技术分类,FPGA分为三类: 基于SRAM的FPGA 、基于flash的FPGA和 基于反熔丝(antifuse)的FPGA [1]。
基于SRAM的FPGA是断电易失的,所以需要在开机(startup)时通过JTAG编程,或者通过内置/外置的非易失存储进行编程。
基于flash的FPGA的逻辑门本身就是非易失的。antifuse FPGA只能编程一次,不可逆。
1.2 组成单元
- Look-Up Table (SRAM based)
k-bound LUT或称为LUT-k指的是有k个输入、2^k个配置bits的布尔函数逻辑。如下图[1]所示的basic logic element(BLE)由1个LUT-4和一个D型触发器(Flip-Flop)构成,其中多个LUT-4有16个SRAM构成的配置位,通过这些配置为配置这些选择器可以构成任意一个4输入逻辑单元。

这个例子中,配置数据存在SRAM中,基于这种BLE的FPGA可以称为基于SRAM(或说static memory)的FPGA。
- Switch Box (SRAM based)
如下图[1]Switch Box中,分为双向(a)和单向(b),一般后者更常用。这些switch都是基于pass transistor[3]的,每个pass transistor可以独立地进行开关配置。

- 基于NAND Flash 的 FPGA 组件
同样也有人提出基于NAND flash的FPGA,基于NAND flash相对基于SRAM,除了LUT、SB的配置形式需要重新设计外,NAND flash还具有NVM都有的非易失特点,可以减少外置flash存储的使用,在上电后不用重新配置。
但是当今的主流FPGA技术还是SRAM,因为它和一般的CMOS集成电路技术分享技术,可以得到集成度、速度和功耗上的不断提升。
一般的,要用Flash替代SRAM作为配置位,需要将SRAM cell替换为FMC(flash memory cell),如下图以2-LUT为例[2],每个FMC都由2个flash晶体管Fp和Fq组成。当然论文[2]的作者也提出了针对NAND Flash的更高效替代方法。

1.3 IP核
FPGA的IP核(core)可以看做是软件中的各种库,避免了编程或设计人员重复造轮子。现代FPGA的可编程门阵列只占50%,其他大部分被硬IP核占据。
硬IP核是系统设计中一些常用的模块,直接以模块形式集成到FPGA的,比如memory block、calculating circuits,transceiver和protocol controller等,有些甚至加入了CPU、DSP等[6]。
2. 软件流程
软件流程也叫CAD(计算机辅助)流程,负责将人实现的上层应用逻辑映射到FPGA可编程硬件逻辑上,这个映射对最终的性能影响很大,所以这也是人们研究的一个重点。
这个过程将人写的硬件描述语言HDL转成可以最终编程到FPGA的比特流。这个过程大概分为5步: synthesis(综合)、technology mapping, mapping, placement, routing。CAD 工具最后生成的就是bit流。软件流程的框图[1]如下:

-
Logic Synthesis 逻辑综合 将VHDL/verilog这类硬件描述编程语言转成布尔门、flip-flops。
-
Technology Mapping 将上一步的逻辑门转成k-bound的LUT (lookup-table)。
-
Clustering/Packing 将多个LB(即k-bound LUT + flip-flop对,或称BLE) 组成logic block clusters。主要有三种方法,各有利弊:
top-down:k路分割问题的基本的cost function 是 net cut,即partition间的边数。
depth-optimal:用逻辑的重复换取更快的运行
bottom-up: FPGA CAD中用的比较多,因为运行快
-
Placement 主要决定logic block 的放到FPGA哪个logic block 位置,以最小的wiring 为主(wire length-driven placement)。或者平衡wiring 的密度(routability-driven placement);或者找到最快的电路速度(timing-driven placement)。常用partitioning或者模拟退火的方法
-
Routing 阶段将网络关联到物理的routing网络,当前state-of-the-art 算法是pathfinder。
在这些阶段之后,还有时序分析阶段和bitstream生成阶段,最后的bitstream会真正的用于编程到SRAM存储位来配置逻辑门。
3. Host FPGA管理系统的发展
[4] 提出了一种"FPGA操作系统", [5] 是对FPGA虚拟化的综述。
[5]中的虚拟化其实是广义的虚拟化,包括FPGA的 时分复用 、虚拟执行和 虚拟机 。
- 时分复用:任务大,单FPGA资源少(而非FPGA资源少、任务小而要一直进行切换FPGA配置)。
- 虚拟执行:将任务切分为多个需要通信的子任务(Petri-Net model),用一种运行时系统去管理它们。
- 虚拟机:有vFPGA支持的hypervisor,或者称为shell。
FPGA虚拟化的目标和其他资源的虚拟化类似:单设备多租户、资源管理、灵活性、隔离性、扩展性、虚拟化性能损失最小化、安全性、可靠性和易用性。
FPGA和CPU、GPU的根本区别是应用是硬件电路而非 汇编指令 。这带来了大得多的切换开销,不仅时间复用,空间也要复用。
...
对于FPGA相关工作的分类可以分为3种:resource level 、Node level 和 multi-node level。
3.1 Resource Level
分为可配置的(比如可以重新编程的逻辑阵列)和不可配置的(比如IP核)。
可配置overlays架构部分 :
Overlays架构的思路是将FPGA编译(配置)阶段分成两部分,将CAD部分提前,只有硬件部分inline执行,来减少整体的重新配置时间。overlays的管理粒度可大可小,从软核的虚拟化,到向量处理器,再到自定义处理单元(PE)再到细粒度的LUT单元。比较高层次的软核、向量处理器对一般的软件工程师更友好,不需要很多的硬件优化。而PE粒度(或称coarse-grained reconfigurable arrays, CGRAs)以一个代数运算作为单元。又例如DRAGEN芯片专门针对DNA处理,overlay层允许生物领域专家能够用FPGA加速运算。
overlay的二级制应用之于configuration bit 类似于 Java JVM的字节码之于机器码。所以像字节码到原生机器码的转换一样,overlay应用可以直接转为overlay的FPGA配置。
不可配置的IO虚拟化部分 :
通常用来管理多个应用共享的IO资源,和其他虚拟化技术类似,虚拟化层可以用来提升安全/隔离性、隐藏IO操作的复杂性、监视资源占用和保证QoS,有时也可以提升性能(比如加buffer)等。从根本上,IO虚拟化的概念支持和CPU、软件系统类似,只是具体实现不同。对于FOGA而言,控制逻辑可以在软件层,也可以是硬件模块,软件层次用来实现更灵活的配置、硬件部分加速IO访问和管理。
这里的总结主要指的是一些host的工作可以卸载到FPGA,比如FPGA辅助NIC[7]、辅助SSD[8],甚至用于加速memcached这种通用KV cache的网络[9, 10]。
3.2 Node Level
一般类似于虚拟机/多进程中的设备虚拟化,分为多/单应用组合上单/多FPGA四种[5]:

涉及到VMM、shell、调度等问题。
VMM型 将FPGA当成一种IO资源,像其他虚拟机一样以CPU为主体,这种情况下FPGA就像GPU一样用,对软件开发者更友好。
Shell型 以FPGA自身,给出与host通信、与其他IO设备通信、应用管理等的设计。比如一种典型的设计是在FPGA的可配置部分,将管理部分和应用部分分开,利用FPGA的partial reconfiguration特性主要重新配置FPGA的应用部分,但这也会带来很多开销,包括让长连线增加等。而且为实现多租户增加的partial resion的数量也会导致更慢的运算速度,所以找到一个合适的partial regions 大小和数量很重要!
调度问题 在FPGA上和CPU不太一样,因为上下文切换和partial重配置需要占的时间很长,所以抢占式调度当前不太现实。现在大多数方案基于非抢占调度,并且主要着眼时间的优化,最近也开始有工作研究空间的优化。
3.3 Multi-node Level
提供抽象,让多个FPGA组合起来工作。大概架构分为3种[5]:

-
FPGA
+关注
关注
1625文章
21665浏览量
601747 -
RAM
+关注
关注
8文章
1367浏览量
114518 -
可编程
+关注
关注
2文章
844浏览量
39781 -
数字电路
+关注
关注
193文章
1600浏览量
80490
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论