 【AI简报20230522期】ChatGPT App 来了!谷歌大模型PaLM 2细节遭曝光
【AI简报20230522期】ChatGPT App 来了!谷歌大模型PaLM 2细节遭曝光
aAI 简报 20230522期
1. ChatGPT App 来了!
原文:https://mp.weixin.qq.com/s/aWBhq8Ff3XoOK4Yre8Qhxg
两个月前,在 ChatGPT 相继公开 API、带来「插件功能」之际,我们明显感知到了 GPT 正在以前所未有的速度成为人工智能时代的 Windows,AI 发展也正处于 iPhone 4 时刻。
当下,ChatGPT 的进度再下一城,其自身真正迎来了 iPhone 时刻。
今天凌晨,OpenAI 在美国发布了一款适用于 iOS 客户端的免费 ChatGPT App,这意味着很多用户随时随地都能访问这款 AI 聊天机器人。
该 App 不仅基于 Whisper AI 语音识别模型提供语音输入支持,还可以与网页版 AI 助手 ChatGPT 同步聊天记录。这也是 OpenAI 首次将 ChatGPT 引入官方移动客户端。
不过,有些遗憾的是,该 App 目前仅限于美国地区用户使用。OpenAI 称未来几周内会逐步扩展到其他国家/地区,也会“很快”推出适用于 Android 设备的 ChatGPT 应用程序。
从功能上来看,ChatGPT App 和网页版应用程序一样,作为一款 AI 聊天机器人,可以直接对它提问,由此,不同行业的不同用户能够通过它得到自己想要代码、邮件模版、文本建议等答案,
从使用流程上来看,用户首先也要有 OpenAI 账号登录 ChatGPT App 后,才能正常使用。与此同时,由于 ChatGPT 的互动回应等 AI 处理操作是在 OpenAI 服务器上进行,因此需要联网才能用。

OpenAI 在官方公告中还指出,ChatGPT Plus 订阅者可以拥有和网页版类似的功能,如独家访问 GPT-4 的功能、“提前访问”新功能以及有更快的响应时间。
值得一提的是,ChatGPT Plus 服务最早是在今年 2 月推出,每月费用是 20 美元,包括即使在高峰期也能访问 ChatGPT。
在 iOS 端 ChatGPT App 上线的第一时间,在不少人持以好奇的时候,国外工具分析平台 Emerge Tools 率先对这款 App 进行了拆解分析,在 Twitter 上为我们揭晓了 ChatGPT iOS 应用程序是如何制作的。
Emerge Tools 表示,ChatGPT iOS App 的整体安装大小为 41.9 MB,结构相当简单。以下是 X-Ray 树状图,看不太清楚的小伙伴,也可以通过 Emerge Tools 官网(https://www.emergetools.com/app/example/ios/chatgpt)查看 ChatGPT App 的模块组成。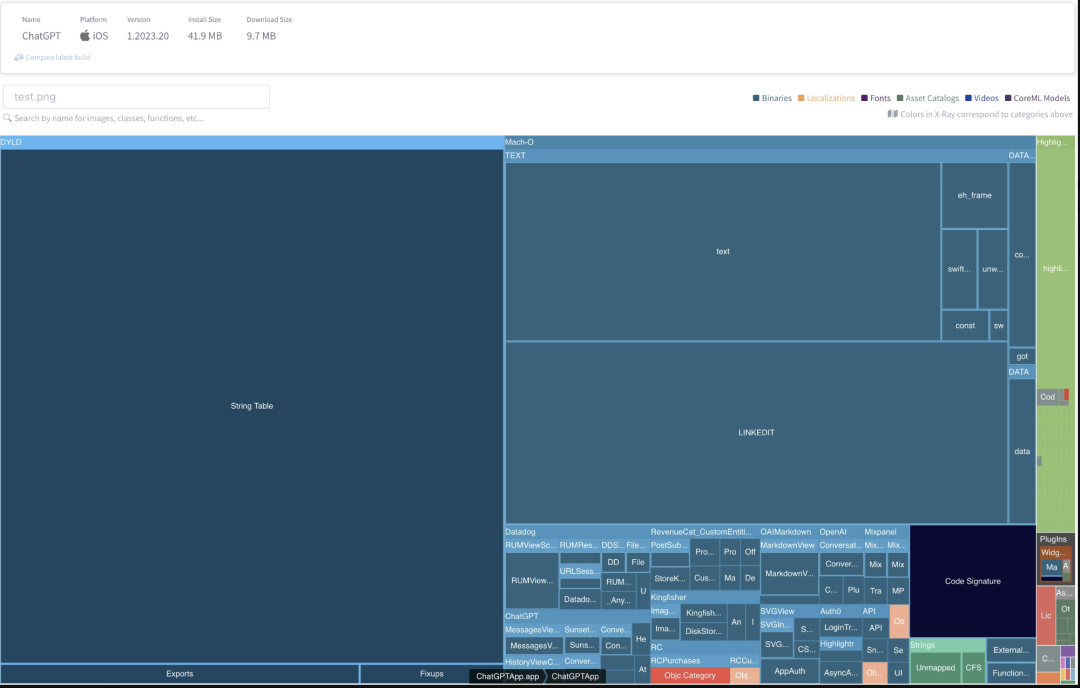
Emerge Tools 称:ChatGPT 没有链接任何动态框架,这样有助于保持 App 的体积小。通过解析,我们可以看到一些静态链接的模块,譬如:
@mixpanel——用于分析
@datadoghq——用于记录
@getsentry——用于性能监控
@RevenueCat——用于付款
@auth0——用于身份验证
+ 其他
另外,Emerge Tools 还使用了其自己的开源分析工具 ETTrace(https://github.com/emergeTools/ettrace)分析了该 App 的启动过程。其认为,「该 App 整体启动时间非常快,实际上只初始化了几个包含的框架,没有明显的瓶颈」。同时,Emerge Tools 称,看起来该应用程序只是转发了与 OpenAI 的服务器之间的查询/响应。
2. 几行代码安装,免费做图无上限:Stability AI公布DreamStudio开源版本
原文:https://mp.weixin.qq.com/s/WiuD9XcN4TCDhpBh7fXLjw
自从文本到图像开源模型 Stable Diffusion 最初版本发布以来,DreamStudio 一直是 Stability AI 新模型和功能的主要界面。迄今,用户已经借助 DreamStudio 创建了数百万张图像。
最近,DreamStudio 还升级到了 SDXL,实现了比其前身 Stable Diffusion 2.1 更详细的图像和构图,并能用较短的 prompt 来创建描述性图像。
就目前来说,DreamStudio 已经可以生成这样的图像,效果不输 Midjourney 5.1:
尽管 DreamStudio 提供了几乎没有门槛的图像生成方法,但它也有一个条件:付费。SDXL 版本的定价甚至还要更高一些。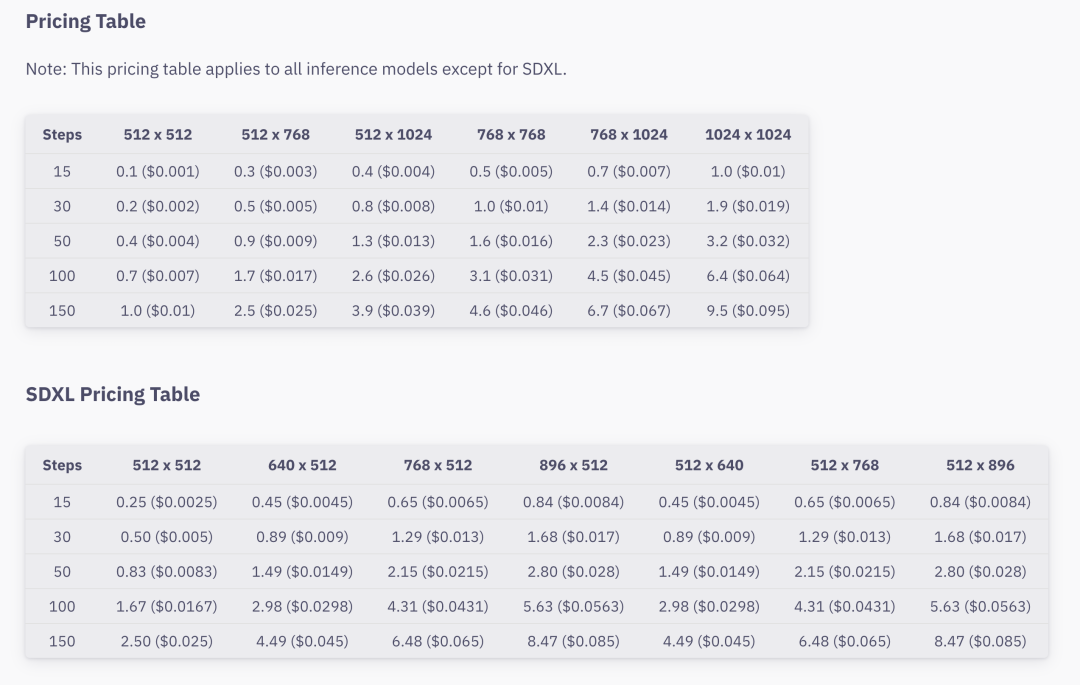
而且,对一部分技术过关的开发者来说,他们也希望能够在 DreamStudio 的基础上进行一些应用扩展。或许是听到了网友们的心声?刚刚,Stability AI 发布了 DreamStudio 的开源版本 ——StableStudio。
开源地址:https://github.com/Stability-AI/StableStudio
「我们相信,扩大技术落地的最佳方式是通过开放、社区驱动的开发,而不是闭源产品的私有化迭代。」Stability AI 表示。
在该公司的规划中,StableStudio 的目标是进行更广泛的社区合作,为生成式 AI 打造一个世界级的用户界面,让用户能够充分控制。尽管 DreamStudio 仍将是 Stability 公司托管的 StableStudio 的实现,但最终目标是培养一个能够超越任何由单一公司开发的项目。
具体来说,StableStudio 和 DreamStudio 有什么区别?
Stability AI 做了一些调整,使得该项目对社区更加友好。包括:
-
删除了 DreamStudio 专属品牌;
-
所有在线 API 调用都已被插件系统取代,用户可以轻松更换后端;
-
删除了专属于 Stability 的帐户功能,例如计费、API 密钥管理等。
扩展功能
DreamStudio 最初被设想为 Disco Diffusion 的动画 studio,2022 年 Stable Diffusion 发布之后,DreamStudio 的重点就转向了图像生成。
受今年爆火的对话模型启发,4 月 Stability AI 发布了开源 LLM StableVicuna。DreamStudio 的开源版本 StableStudio 将和 StableVicuna 结合,推出聊天界面。
Stability AI 表示,StableStudio 未来可能会更新以下功能:
-
通过 WebGPU 进行局部推理
-
通过 stable-diffusion-webui 进行局部推理
-
桌面安装
-
ControlNet 工具
3. 3.6万亿token、3400亿参数,谷歌大模型PaLM 2细节遭曝光
原文:https://mp.weixin.qq.com/s/KisM8tU8sHZLhUjxcCG-NA
上周四,在 2023 谷歌 I/O 大会上,谷歌 CEO 皮查伊宣布推出对标 GPT-4 的大模型 PaLM 2,并正式发布预览版本,改进了数学、代码、推理、多语言翻译和自然语言生成能力。

PaLM 2 模型提供了不同尺寸规模的四个版本,从小到大依次为 Gecko、Otter、Bison 和 Unicorn,更易于针对各种用例进行部署。其中轻量级的 Gecko 模型可以在移动设备上运行,速度非常快,不联网也能在设备上运行出色的交互式应用程序。不过会上,谷歌并没有给出有关 PaLM 2 的具体技术细节,只说明了它是构建在谷歌最新 JAX 和 TPU v4 之上。

昨日,据外媒 CNBC 看到的内部文件称,PaLM 2 是在 3.6 万亿个 token 上训练。作为对比,上代 PaLM 接受了 7800 亿 token 的训练。
此外,谷歌之前表示 PaLM 2 比以前的 LLM 规模更小,这意味着在完成更复杂任务的同时变得更加高效。这一点也在内部文件中得到了验证,PaLM 2 的训练参数量为 3400 亿,远小于 PaLM 的 5400 亿。
PaLM 2 的训练 token 和参数量与其他家的 LLM 相比如何呢?作为对比,Meta 在 2 月发布的 LLaMA 接受了 1.4 万亿 token 的训练。OpenAI 1750 亿参数的 GPT-3 是在 3000 亿 token 上训练的。
虽然谷歌一直渴望展示其 AI 技术的强大能力以及如何嵌入到搜索、电子邮件、文件处理和电子表格中,但也不愿公布其训练数据的大小或其他细节。其实这样做的不只谷歌一家,OpenAI 也缄口不言其最新多模态大模型 GPT-4 的细节。他们都表示不披露细节是源于业务的竞争属性。
不过,随着 AI 军备竞赛的持续升温,研究界越来越要求提高透明度。并且在前段时间泄露的一份谷歌内部文件中,谷歌内部研究人员表达了这样一种观点:虽然表面看起来 OpenAI 和谷歌在 AI 大模型上你追我赶,但真正的赢家未必会从这两家中产生,因为第三方力量「开源」正在悄然崛起。
目前,这份内部文件的真实性尚未得到验证,谷歌也并未对相关内容置评。
4. 前哈工大教授开发的ChatALL火了!可同时提问17个聊天模型,ChatGPT/Bing/Bard/文心/讯飞都OK
原文:https://www.thepaper.cn/newsDetail_forward_23143443?commTag=true
今天的你,是否还在几个聊天大模型之间“反复横跳”?
毕竟各家训练数据和方法不尽相同,擅长和不擅长的东西也都不一样。
现在,不用这么麻烦了。
有人开发了一个名叫“ChatALL”的应用,可以将你的提问同时发送给10多个市面上常见的聊天机器人,比如ChatGPT、GPT4、Bing、Bard、Claude、文心一言、讯飞星火等等,并一一展现出来。
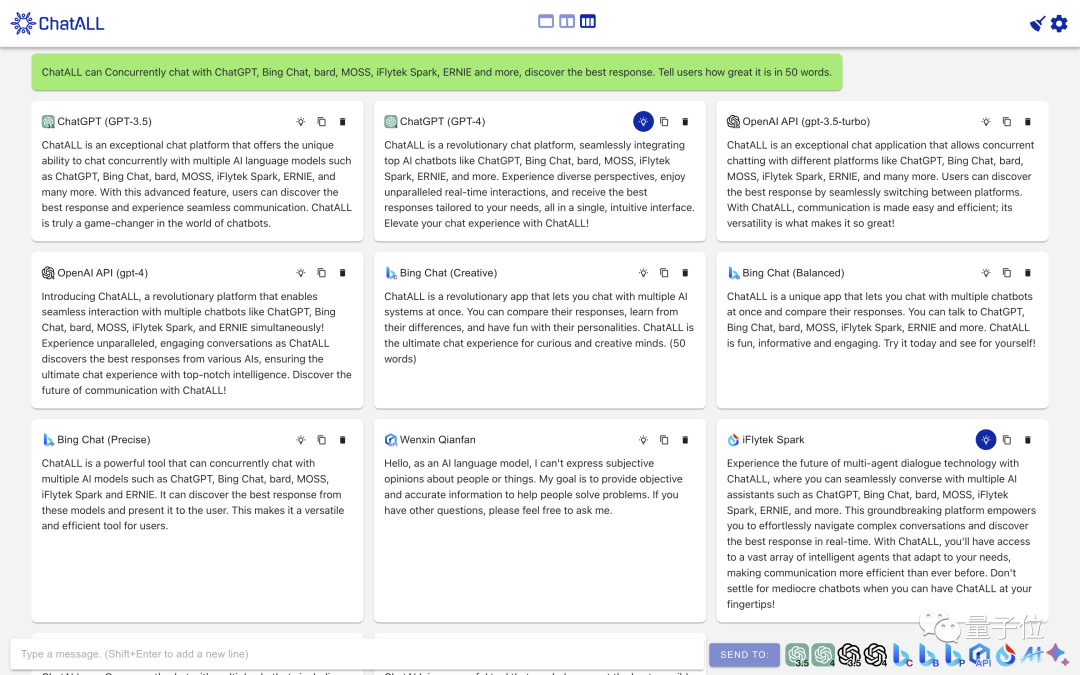
由此一来,你就可以轻松比对出答得最好的那一个,然后采用。
简直太方便了有没有?
这不,项目非常受欢迎,已登上GitHub今日热榜第一名,揽获1.6k+标星。

它是一个应用程序,支持中英德三种语言。
只需下载安装包即可使用,Mac、Windows和Linux都支持。
其功能包括:
-
快问模式:不需要等待前面的请求完成,就可以发下一条指令
-
对话历史保存在本地,保护你的隐私
-
高亮喜欢的答案,删除不需要的答案
-
自动保持ChatGPT不掉线
-
随时启用/禁用任何机器人
-
在一列、两列或三列视图之间切换
-
……
未来还能够推荐最佳答案。
目前支持的AI聊天机器人列表如下: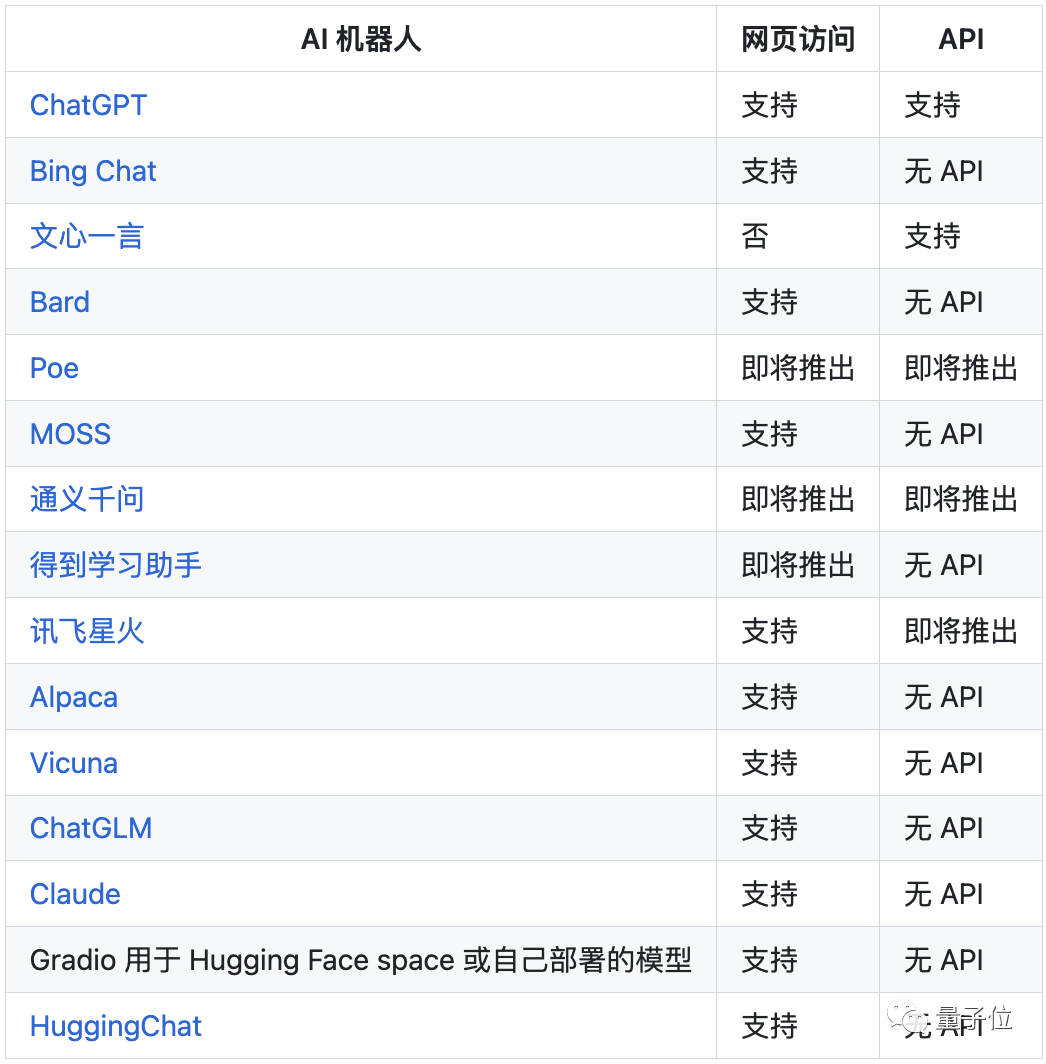
其中,特别包括一个本地Gradio,它可以对接你自己部署的模型。
而在应用程序界面中,一共显示了17个图标,证明目前最多已可支持17种聊天机器人。
需要注意的是,这只是一个集中了所有聊天AI的程序,不是代理,所以每个都需要你登录自己的账号,当然,API token也可以。
登录之后,想一次询问哪些机器人就点亮对应的图标,就可以开始玩耍了。大家快去试试吧。
5. AI孙燕姿成今年爆火歌手,这一时代眼见不实,耳听为虚
原文:https://mp.weixin.qq.com/s/1XP5VAJe7Extk6TEkU9rzQ
就在近期,华语乐坛的不少歌迷喜气洋洋,认为目前的歌坛回到了20年前,歌迷们又享受到了许多动听的歌声。不过与以往不同的是,这些演唱者并非真人,而是一个个训练出来的AI。
这些AI足以以假乱真,通过技术将一首音乐以更换演唱者的方式来进行不同的演绎,不仅为歌坛带来了不一样的视听体验,同时也引发了行业对AI技术应用的思考。在AI时代,我们的所见所闻,或许都是由AI创造的。
光怪陆离的AI时代
如今的网络上有一个梗,要问今年哪个歌手最火,答案可能会出乎许多人意料,并不是某位歌手,而是一些由AI所制作出来的语音,如AI孙燕姿、AI周杰伦等。通过将原来歌手的声音进行采集训练,从而替换另一首歌的原唱。
通过这种方式,实现了让自己喜欢的歌手唱另一首自己喜欢但非歌手的歌,比如用孙燕姿的声音演唱周杰伦的《晴天》。关键在于,不论是演唱语调、技巧乃至音色,几乎都与孙燕姿相差无几。
实现这一技术目前已经有一套标准流程,先通过收集大量的音乐和歌词,并对这些数据进行清洗和标注,以便训练算法和模型。再选择合适的算法和模型,并进行优化和调整,以提高虚拟人物的歌唱和表演能力。
通过语音合成技术将文字转换为声音,并对声音进行处理和优化,以达到更加自然和流畅的效果。最后将原来歌曲的声音替换成语音合成的声音,再进行调试,就能得到一首全新演唱的歌曲。
既然都已经可以替换声音演唱歌曲了,那么更进一步替换视频画面进行演绎也就不太难了。近期谷歌的I/O大会上,便公布了一项Universal Translator技术,该工具旨在将视频从一种语言翻译成另一种语言,同时保留整体基调和氛围。
这意味着该技术不仅可以将音频从一种语言翻译成另一种语言,还可以模仿说话者的声音、语气和面部表情,人物说话视频会根据目标语言的发音同步改变口型。
当然,为了避免这项技术被用来制作虚假视频,谷歌将这项技术只授权给少部分的合作厂商使用,普通人是无法接触到的。但市场上如今已经有许多类似的AI出现,谷歌的此举不过是略作限制,但无法阻止这股趋势。
更有甚者,如一位美国网红发布了AI版本的自己“Caryn AI”,这个应用是一款聊天机器人,可以作为用户的虚拟伴侣,目前正在内部测试阶段,每分钟收费一美元。
据美国杂志《财富》披露,就在过去一周的时间内,这款软件已经为其创造了7.16万美元(约合人民币50万元)的收入,已经吸引了超过1000名付费粉丝。
这种模式或许也将冲击未来的娱乐行业,想象每一位追星的粉丝,只要付费,都将拥有与自己偶像一对一聊天的机会,其所创造的价值潜力将是巨大的。
但这种由AI所创造出来的音乐、视频、伴侣或者偶像,真的可以提供人们所需要的情绪价值吗?这是个值得思考的问题。
AI之后的隐忧
尽管这些AI应用的落地前景非常诱人,比如采用AI替换歌曲中的声音,就能够实现歌手只需要提供声音的模板,便可以进行批量的音乐制作。甚至不用自己演唱,也能够推行相关专辑。
技术上主要通过机器学习技术,训练机器模仿一个特定的歌手的音乐风格、声音和唱腔,然后将这些技能应用于其他歌曲的录制中。这种技术在一定程度上提高了录制歌曲的效率和质量,并且可以节省制作成本。
但如果使用他人的声音进行创作,就可能有侵权的风险。尤其在数据采集阶段,以语音替换为例,首先需要收集大量的语音数据,并对这些数据进行标注和处理。标注可以包括音素、语调、语速等信息,以便训练模型能够准确地识别和替换语音。
这一过程便可能涉及到对用户隐私数据的采用,甚至对用户的隐私和数据安全造成威胁,还有可能进一步造成财产安全。因为语音合成就可能被犯罪分子用于诈骗,通过合成亲属或者熟人的声音来谋取资金。
如果用AI更改视频画面甚至进一步篡改其中的对话,则可能造成更多的风险。比如将会遇到即便是用视频聊天,也无法确定对面的是不是真的想要联系的那个人。这项技术目前甚至已经应用在许多的直播平台中,比如一些虚拟主播、虚拟偶像等,如果一旦滥用,可能会造成更多的危害。
为了避免这一情况的发生,除了加强对AI技术的监管,建立相应的法律制度和规范,还可以通过一些技术手段来避免自身的数据被采集,从而造成侵权以及侵犯隐私的风险。比如采用区块链技术来保护数据的安全性和隐私性,采用人工智能算法来检测和识别恶意行为等手段。
以区块链技术为例,其去中心化和不可变性特点能够确保数据的安全和完整性,因此可以用于AI技术的安全验证和认证。基于区块链技术,数据交互和交流的过程被保护,因此可以授权AI对数据的操作并确保AI数据访问权限受到限制。
同时,区块链技术还可以帮助人们更好地控制AI技术的使用,并提高AI的公正和透明性。例如,以基于区块链技术的智能合约的方式来控制AI的使用,可以加强对AI系统的监督,并确保其行为符合人类的期望和价值。
当然,区块链技术还面临着可扩展性、隐私保护等问题,同时在操作成本和技术难度方面也存在一定的限制,还无法完全避免AI滥用的问题。
我们还可以运用数字签名技术检测音频和视频是否被AI修改,数字签名是指在文件中包含数字代码的技术,在将文件传输或转发给其他人时,可以验证文件的完整性和真实性。或者使用机器学习算法来检测这些变化,例如,可以使用深度神经网络来对音频或视频进行分析,以检测其中的模式和结构是否与人类创作者的作品相似。如果发现有明显的差异,则可能表明该作品是由AI生成的。
但随着未来AI技术的发展,这些差异化和容易被检测出来的问题都有可能被AI克服,使得我们最终很难分辨哪些产品是由AI制作,哪些才是由人所原创的。
写在最后
随着生成式AI技术的大爆发,如ChatGPT、文心一言、讯飞星火等聊天机器人的出现,让人们工作效率得以极大地提高,Stable Diffusion、Midjourney等AI的出现,让图片制作成本大幅降低,Universal Translator、Video Dubbing AI等,让视频也开始变得容易制作。
这些AI技术的出现显然极大的解放了人们的生产力,让人类发展走上快车道。当然有人会说以上这些AI都是通过收集大量数据之后,输出缝合之后的产品,根本不能称得上是原创。
但就像我们的学习过程一样,最开始都是模仿,后来才开始拥有自己的独立风格,但这些风格或多或少都会有之前学习过的影子,而这就是创造的过程,AI也是如此。
更值得关注的是,随着AI技术的快速发展,其所带来的风险也在与日俱增。如何更好的处理AI所引发的风险,将是我们未来所面对的主要问题。
6. 星一文看尽深度学习各种注意力机制,学习推荐!
https://mp.weixin.qq.com/s/PkzzElN1uk2Yzu1DsYnOdQ
注意力机制在计算机视觉领域的应用主要使用于捕捉图像上的respective field,而在自然语言处理领域中的应用主要使用于定位关键的token。下面简单介绍下注意力机制在早期的几个经典应用。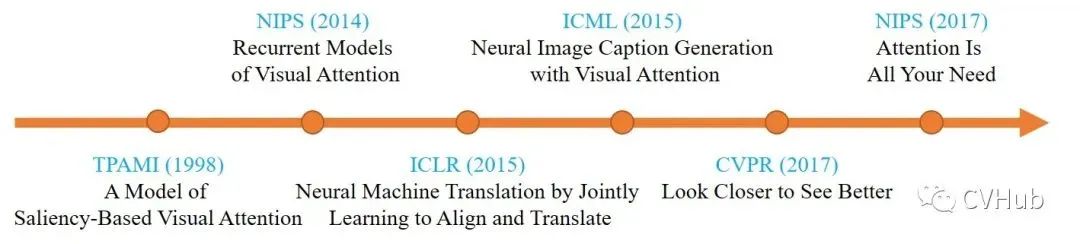
《A Model of Saliency-Based Visual Attention for Rapid Scene Analysis》[2]
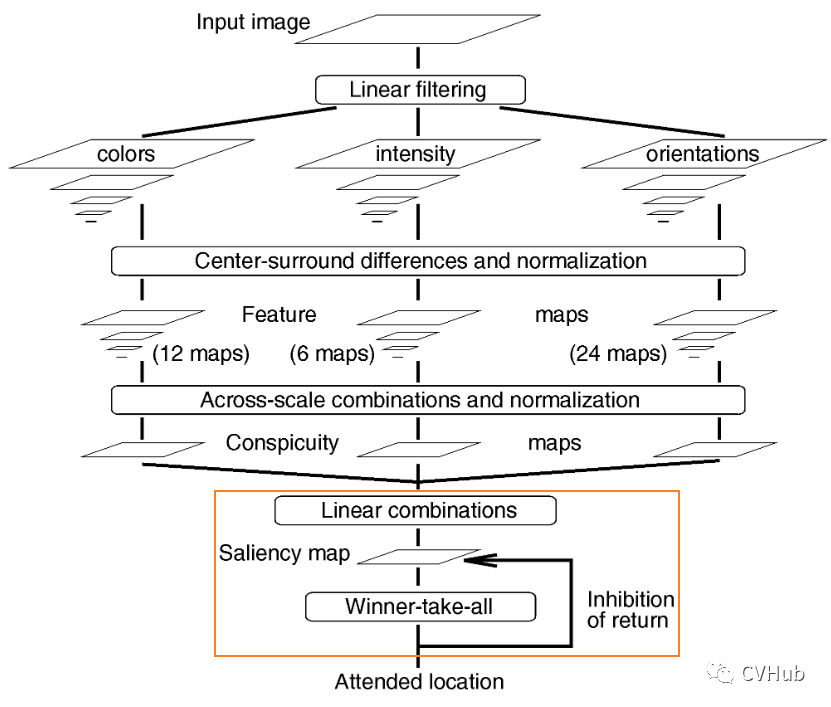
这是早期将注意力机制应用于计算机视觉领域的一篇代表作,文章于1998年发表于TAPMI。作者受早期灵长目视觉系统的神经元结构启发,提出了一种视觉注意力系统,可以将多尺度的图像特征组合成单一的显著性图。最后,利用一个动态神经网络,并按照显著性的顺序来高效的选择重点区域。
《Recurrent Models of Visual Attention》[3]
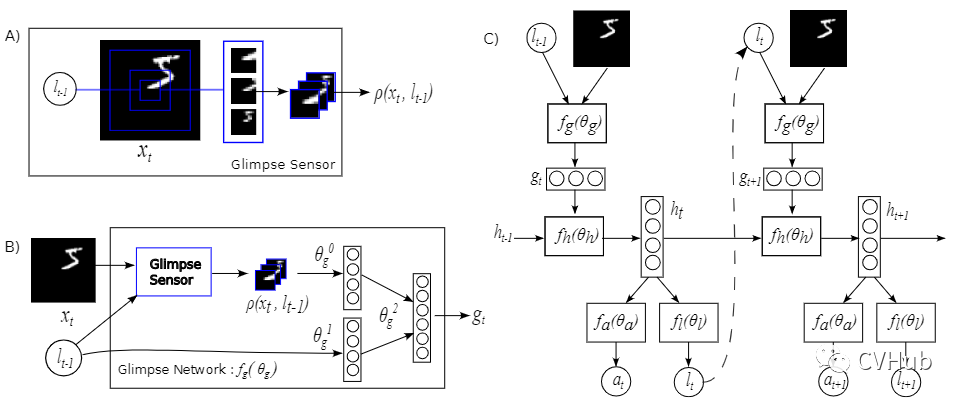
使注意力机制真正火起来的当属于谷歌DeepMind于2014年所提出的这篇文章,该论文首次在RNN模型上应用了注意力机制的方法进行图像分类。
《Neural Machine Translation by Jointly Learning to Align and Translate》[4]
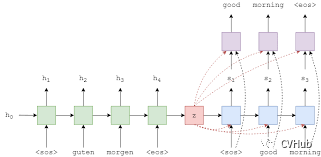
这是由深度学习三巨头之一Yoshua Bengio等人于2015年发表于ICLR上的一篇论文,该论文的最大贡献是将注意力机制首次应用到NLP领域,实现了同步的对齐和翻译,解决以往神经机器翻译(NMT)领域使用Encoder-Decoder架构的一个潜在问题,即将信息都压缩在固定长度的向量,无法对应长句子。
《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》[5]
这篇文章由Yoshua Bengio等人于2015年在ICML上所发表的,该论文将注意力机制引入到图像领域,作者提出了两种基于注意力机制的图像描述生成模型: 使用基本反向传播训练的Soft Attetnion方法和使用强化学习训练的Hard Attention方法。
《Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition》[6]
这是发表于CVPR 2017年的一篇文章,作者提出了一种基于CNN的注意力机制,叫做循环注意力卷积神经网络(Recurrent Attention Convolutional Neural Network, RA-CANN),该网络可以递归地分析局部信息,并从所获取的局部区域中提取细粒度信息。此外,作者还引入了一个注意力生成子网络(Attenion Proposal Sub-Network, APN),迭代的对整图操作以生成对应的子区域,最后再将各个子区域的预测记过整合起来,从而后的整张图片最终的分类预测结果。
《Attention is All Your Need》[7]
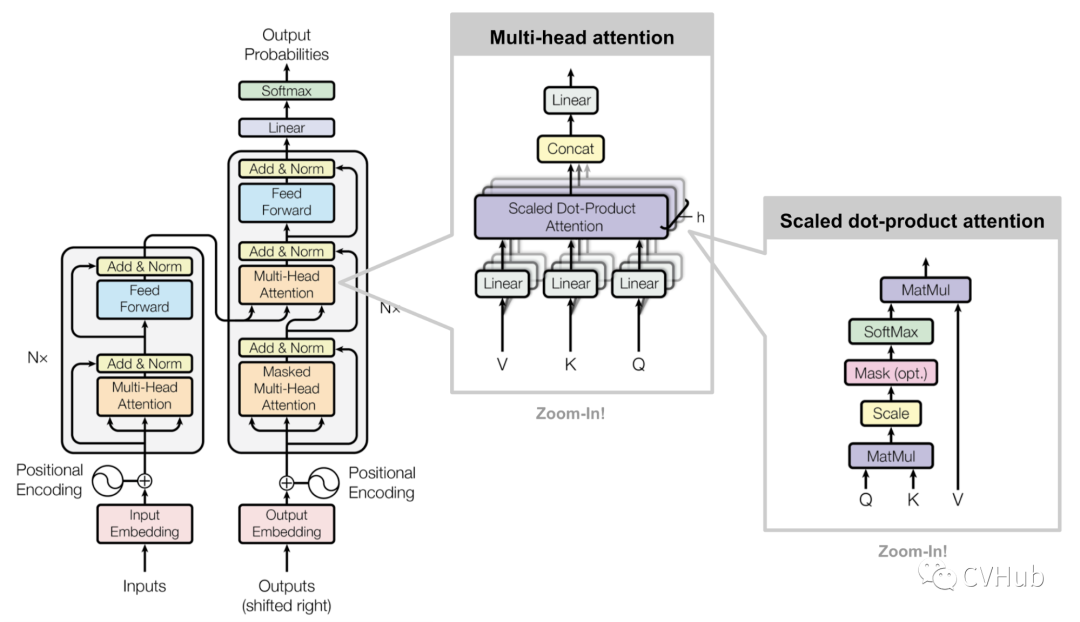
这是由谷歌机器翻译团队于2017年发表于NIPS上的一篇文章,该论文最大的贡献便是抛弃了以往机器翻译基本都会应用的RNN或CNN等传统架构,以编码器-解码器为基础,创新性的提出了一种Transformer架构。该架构可以有效的解决RNN无法并行处理以及CNN无法高效的捕捉长距离依赖的问题,近期更是被进一步地应用到了计算机视觉领域,同时在多个CV任务上取得了SOTA性能,挑战CNN在CV领域多年的霸主地位。
本文将重点围绕通道、空间、自注意力、类别等多个维度[8]介绍计算机视觉领域中较为出名的注意力机制方法,力争用最简短的语言解释得更加通俗易懂。
通道&空间注意力
通道注意力旨在显示的建模出不同通道之间的相关性,通过网络学习的方式来自动获取到每个特征通道的重要程度,最后再为每个通道赋予不同的权重系数,从而来强化重要的特征抑制非重要的特征。
空间注意力旨在提升关键区域的特征表达,本质上是将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域。
SE-Net[9]
《Squeeze-and-Excitation Networks》发表于CVPR 2018,是CV领域将注意力机制应用到通道维度的代表作,后续大量基于通道域的工作均是基于此进行润(魔)色(改)。SE-Net是ImageNet 2017大规模图像分类任务的冠军,结构简单且效果显著,可以通过特征重标定的方式来自适应地调整通道之间的特征响应。
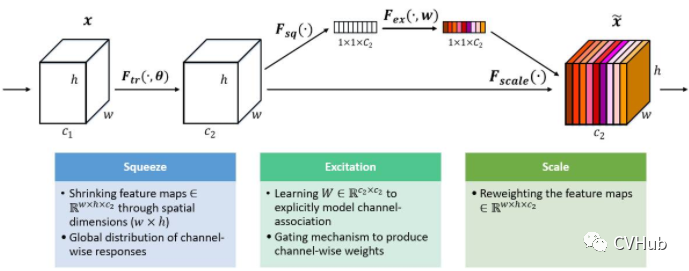
-
Squeeze利用全局平均池化(Global Average Pooling, GAP) 操作来提取全局感受野,将所有特征通道都抽象为一个点;
-
Excitation利用两层的多层感知机(Multi-Layer Perceptron, MLP) 网络来进行非线性的特征变换,显示地构建特征图之间的相关性;
-
Transform利用Sigmoid激活函数实现特征重标定,强化重要特征图,弱化非重要特征图。
1classSELayer(nn.Module):
2def__init__(self,channel,reduction=16):
3super(SELayer,self).__init__()
4self.avg_pool=nn.AdaptiveAvgPool2d(1)
5self.fc=nn.Sequential(
6nn.Linear(channel,channel//reduction,bias=False),
7nn.ReLU(inplace=True),
8nn.Linear(channel//reduction,channel,bias=False),
9nn.Sigmoid()
10)
11
12defforward(self,x):
13b,c,_,_=x.size()
14y=self.avg_pool(x).view(b,c)
15y=self.fc(y).view(b,c,1,1)
16returnx*y.expand_as(x)
此外,本文还总结了一下网络,感兴趣的同学可以查看原文。
GE-Net[10]
RA-Net[12]
SK-Net[13]
SPA-Net[14]
ECA-Net[15]
CBAM[16]
BAM[17]
scSE[18]
A2-Nets[19]
Non-Local[20]
DA-Net[22]
ANLNet[24]
CC-Net[26]
GC-Net[28]
…
———————End———————
RT-Thread线下入门培训
6月 - 郑州、杭州、深圳
1.免费2.动手实验+理论3.主办方免费提供开发板4.自行携带电脑,及插线板用于笔记本电脑充电5.参与者需要有C语言、单片机(ARM Cortex-M核)基础,请提前安装好RT-Thread Studio 开发环境

立即扫码报名
报名链接
https://jinshuju.net/f/UYxS2k
巡回城市:青岛、北京、西安、成都、武汉、郑州、杭州、深圳、上海、南京
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!
点击阅读原文,进入RT-Thread 官网
-
RT-Thread
+关注
关注
31文章
1289浏览量
40127
原文标题:【AI简报20230522期】ChatGPT App 来了!谷歌大模型PaLM 2细节遭曝光
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
名单公布!【书籍评测活动NO.34】大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
谷歌发布AI文生图大模型Imagen
截杀ChatGPT-4o,谷歌系AI产品迎来全面升级
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢
谷歌发布全新AI模型Genie
谷歌AI大模型Gemma全球开放使用
谷歌发布开源AI大模型Gemma
谷歌发布新型AI模型Genie
是德科技如何赋能医疗AI大模型应用呢?






 工商网监
工商网监
评论