 手写词法分析器
手写词法分析器
在开始手写词法分析器之前呢,我们得先准备好一些零件,规划好将要使用哪些函数,如果函数没有现成的,那还得自己写。
输入
由于我们需要从流中读出,有时还需要放回流,词法分析器显然每次读入都是按字符读入,所以使用getchar函数一般没有问题,然后对于放回流,C中提供了一个ungetc的后悔函数,首先先来尝试一下这个函数:
int main()
{
char t;
t = getchar();
cout << t;
ungetc(t, stdin);
t = 'a';
t = getchar();
cout << t;
// input : 12, output : 11
}
其实也就是把这个字符放回到标准输入流的最前面。
判断
我们需要判断一个字符它是字符还是数字,参考实验指导中的代码,有一个头文件ctype.h可以帮上忙 。
isalnum() 判断一个字符是否是字母或数字
isalpha() 判断一个字符是否是字母
isdigit() 判断一个字符是否是十进制数字
islower() 判断一个字符是否是小写字母
isspace() 判断一个字符是否是空白符(包含\\n等空白效果的控制字符)
返回值:如果满足,返回非0,不满足,返回0;
子问题1:识别关键字、标识符、数据类型
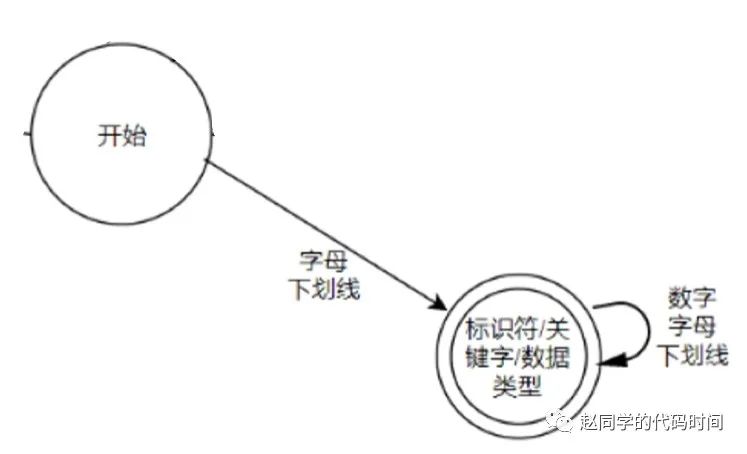
这一步要完成上面这一个分支,计划使用Trie树保存关键字,然后按照以下步骤进行,完成一个函数就可以:
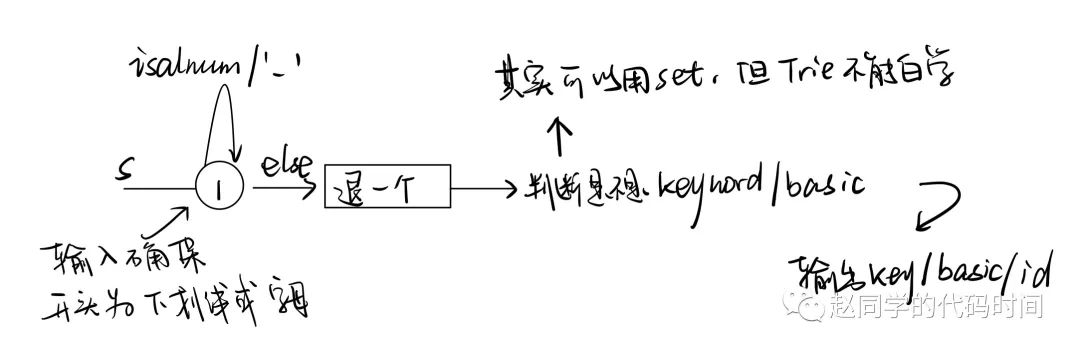
建树过程:
// 预设的keywords和basic
string keyword[] = {"if", "while", "do", "break", "float", "true", "false"};
string basic[] = {"int", "char", "bool", "float"};
// 宏定义,使代码更可读
#define KEYWORD 1
#define BASIC 2
#define IDENTITY 3
// 定义全局变量
const int N = 128;
int son[N][N], idx;
int token[N * N]; // 定义这个idx对应的token
// insert函数,详见Trie树
void insert(string s, int mode)
{
int p = 0; // 从根节点开始
for(int i = 0; i < s.size(); i ++)
{
if(!son[p][s[i]]) son[p][s[i]] = ++ idx;
p = son[p][s[i]];
}
token[idx] = mode;
}
// 查询函数,返回token类型
int query(string s)
{
int p = 0;
for(int i = 0; i < s.size(); i ++)
{
if(!son[p][s[i]]) return IDENTITY;
p = son[p][s[i]];
}
return token[p];
}
// 初始化函数
void initialize()
{
for(int i = 0; i < 7; i ++) insert(keyword[i], KEYWORD);
for(int i = 0; i < 4; i ++) insert(basic[i], BASIC);
}
查询测试:

已经成功的可以使用了。
我们可以发现,不光是keyword和basic和identity,其他的字符也可以存到Trie树里面去,比如以下专用符号:
= + - * / < <= > >= == != ; , ( ) [ ] { }
甚至是注释符号:
/* */
子问题2:识别数字
首先,为了识别数字,我们先给出数字的正则表达式:
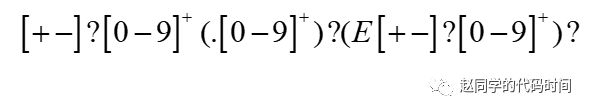
尝试给出NFA
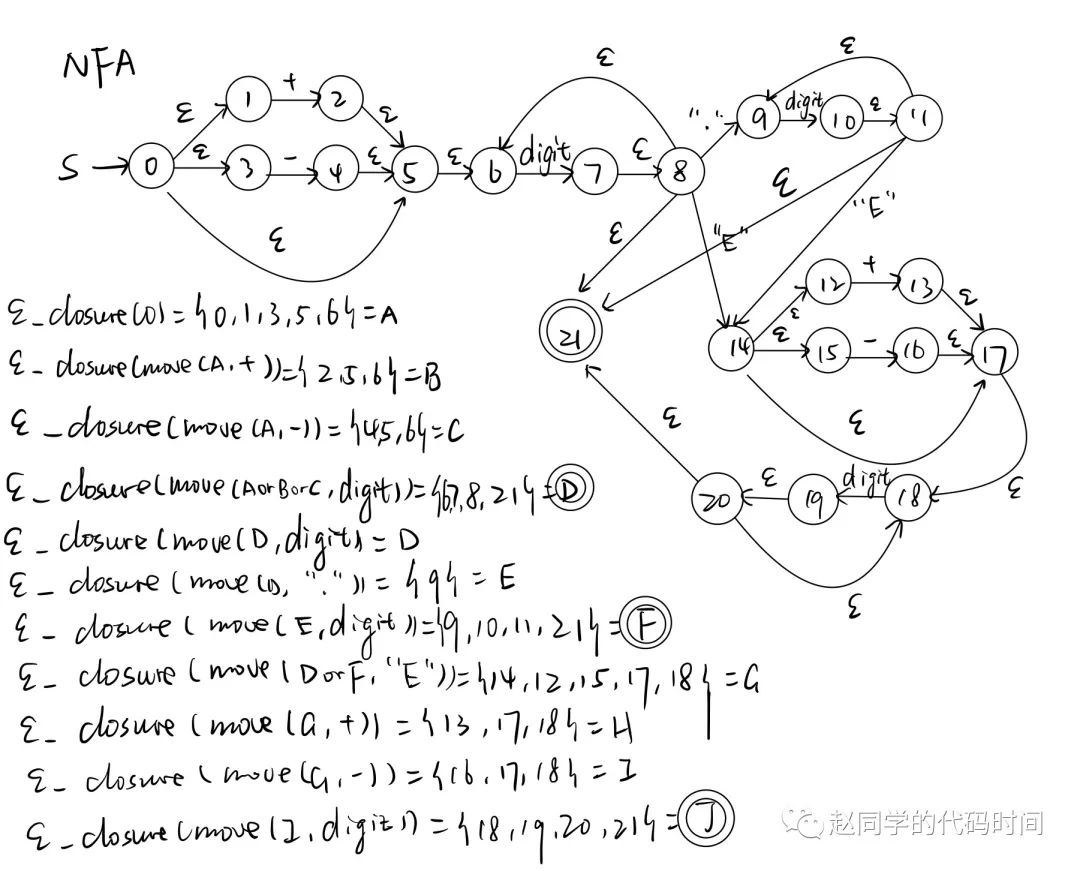
转化为DFA
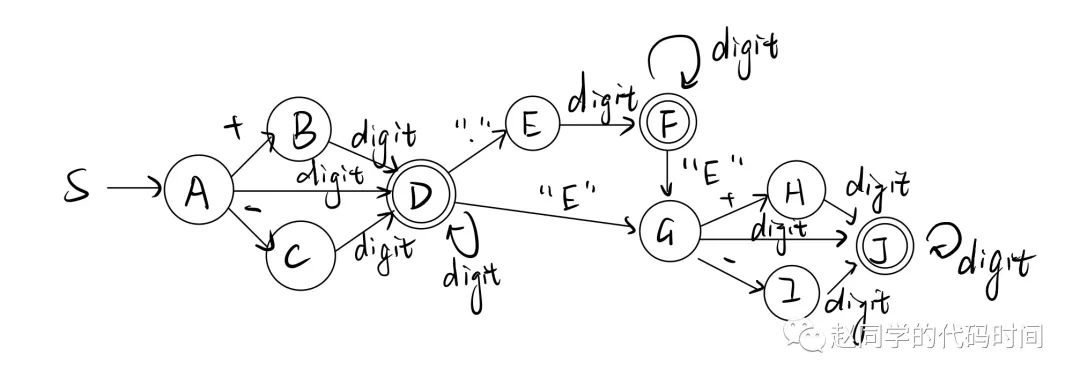
分析状态转移表:
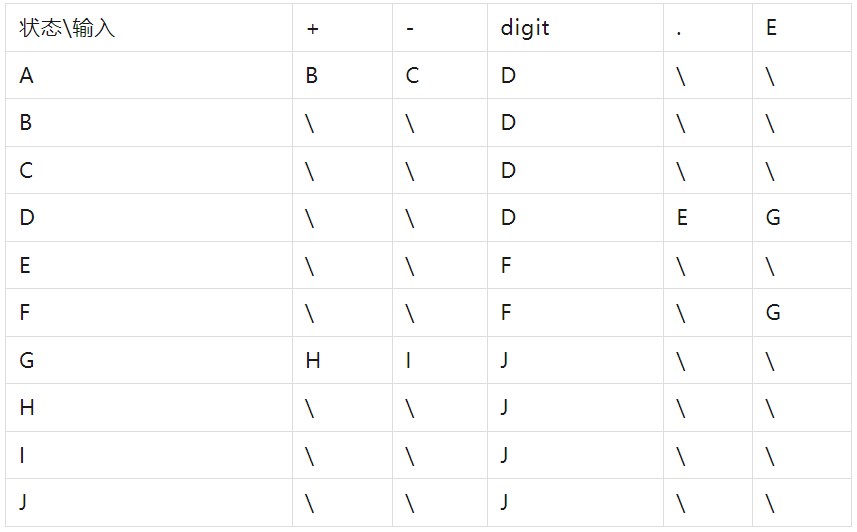
上标转化为代码表示:
int st[11][5] = {{0, 0, 0, 0, 0},
{2, 3, 4, 0, 0},
{0, 0, 4, 0, 0},
{0, 0, 4, 0, 0},
{0, 0, 4, 5, 7},
{0, 0, 6, 0, 0},
{0, 0, 6, 0, 7},
{8, 9, 10, 0, 0},
{0, 0, 10, 0, 0},
{0, 0, 10, 0, 0},
{0, 0, 10, 0, 0}};
根据状态转移表完成编程:
string num() // 输入一个数字字符串
{
string s;
char t;
int status = 1;
int last_status;
while(1){
t = getchar();
switch (t)
{
case '+':
last_status = status;
status = st[status][0];
break;
case '-':
last_status = status;
status = st[status][1];
break;
case '.':
last_status = status;
status = st[status][3];
break;
case 'E':
last_status = status;
status = st[status][4];
break;
case 'e':
last_status = status;
status = st[status][4];
break;
default:
if(isdigit(t))
{
last_status = status;
status = st[status][2];
}
else {
last_status = status;
status = 0;
}
break;
}
if(!status)
{
ungetc(t, stdin);
break;
}
s += t;
}
status = last_status;
if(status != 4 && status != 6 && status != 10) return "";
return s;
}
结果测试:
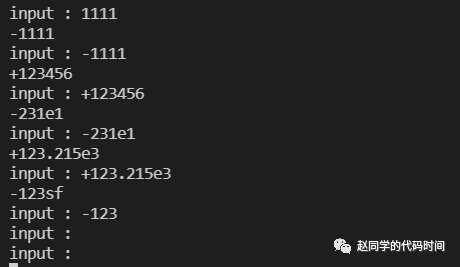
于是乎我们又实现了一个有限状态自动机,从而实现了数字字符串的输入。
子问题3:将输入分割为小字符串
要实现将输入分割为小字符串,且向前看的步长仅为1步。首先我们需要分析出究竟在什么时候,才应该将他们分开。
1) 以下划线、字母开头,使用Trie树搜索;
2) 以+ -开头,再看一步为数字,放回加减后使用DFA搜索;
3) 除+ -专用符号开头,使用Trie树搜索;
4) 注释符号开头,一直接收到遇到注释尾。
子问题4:处理注释
此处做一个简化,不考虑注释中的转义字符,匹配到 */ 则结束。
string comments()
{
string s;
char last_c, c;
while(last_c != '*' || c != '/')
{
last_c = c;
c = getchar();
s += c;
}
return s;
}
验证:
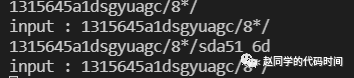
可以看到,它自动截取了注释的前面部分。
-
分析器
+关注
关注
0文章
92浏览量
12492 -
状态机
+关注
关注
2文章
492浏览量
27529 -
NFA
+关注
关注
0文章
4浏览量
7130
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论