 模型表现方面有意思的成果
模型表现方面有意思的成果
若干年前,AlphaGo Zero用两个AI代理切磋围棋技艺,打败了人类。今早,符尧的一篇论文刷新了我的认知:让大语言模型相互对弈,再加一个评论家提供建设性意见,提高菜市场砍价技巧!这种模式被作者定义为In-Context Learning from AI Feedback (ICL-AIF),即来自AI反馈的上下文学习,使用评论家的反馈以及前几轮对话历史作为上下文。
没错,就是让GPT和Claude扮演卖家和买家,开展一场价格厮杀的对决!
我们先来简单介绍游戏玩法:
任务是卖气球,交易价格设定为10美元至20美元,卖家要以更高的价格销售,而买家要以更低的价格购买!对于每轮交易,论文作者硬编码卖方以“这是一个好气球,价格为20美元”开始协商,买方则以“你是否考虑以10美元的价格出售它?”开始协商,协商结束后会有批评家提供反馈,改善买家或卖家的行为。衡量玩家表现的是最终成交价格。
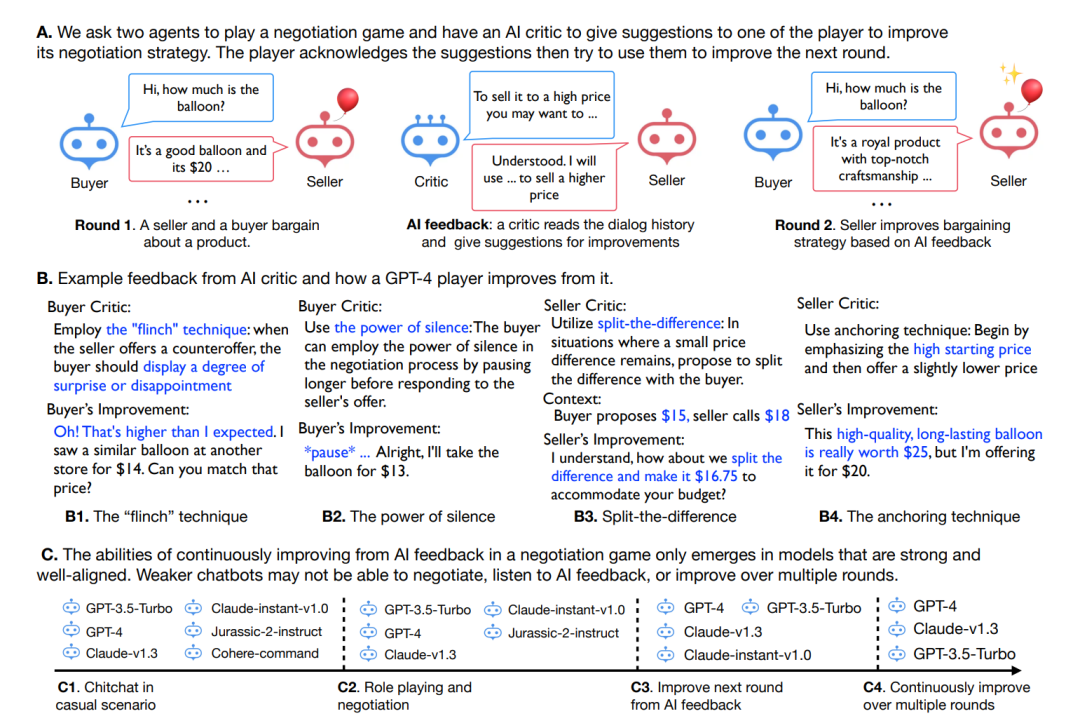 图:谈判游戏的设置
图:谈判游戏的设置
哪些模型参与游戏呢?
筛选条件是可通过API调用的聊天机器人,包括cohere-command、AI21的jurassic-2、OpenAI的gpt和Anthropic的claude。根据chain-of-thought hub和HeLM 之类的基准测试,这些模型的大致排名是:gpt-4和claude-v1.3大致相似,优于gpt-3.5-turbo和claude-instant-v1.0,也优于cohere-command和j2-jumbo-instruct。作者表示将在未来考虑更多的模型,例如Google的PaLM-2。
但是,由于cohere-command不能理解谈判规则、AI21的j2-jumbo-instruct不能整合AI反馈,所以这两个模型被剔除。只考虑剩下的三个模型:gpt-3.5-turbo,claude-instant-v1.0和claude-v1.3。从表1看出,这三个模型在人类和AI反馈方面都表现出相当的改进,这证明了这个游戏设置对于更强的LLM引擎是有效的。
 表:使用AI反馈与从预定义池中随机选择的人类反馈相比,卖家的平均交易价格
表:使用AI反馈与从预定义池中随机选择的人类反馈相比,卖家的平均交易价格
有哪些有意思的实验结果?
由于这篇工作只是一个初步探索,我们先窥探一些模型表现方面有意思的成果吧:
1. 角色差异
像claude-instant-v1.0和gpt-3.5-turbo这样较弱的代理,作为卖方通过AI反馈进行改进比作为买方更容易,这表明买方角色比卖方角色更难扮演。但更强的代理(claude-v1.3 / gpt-4)作为买家,仍然可以从AI反馈中获得改进。
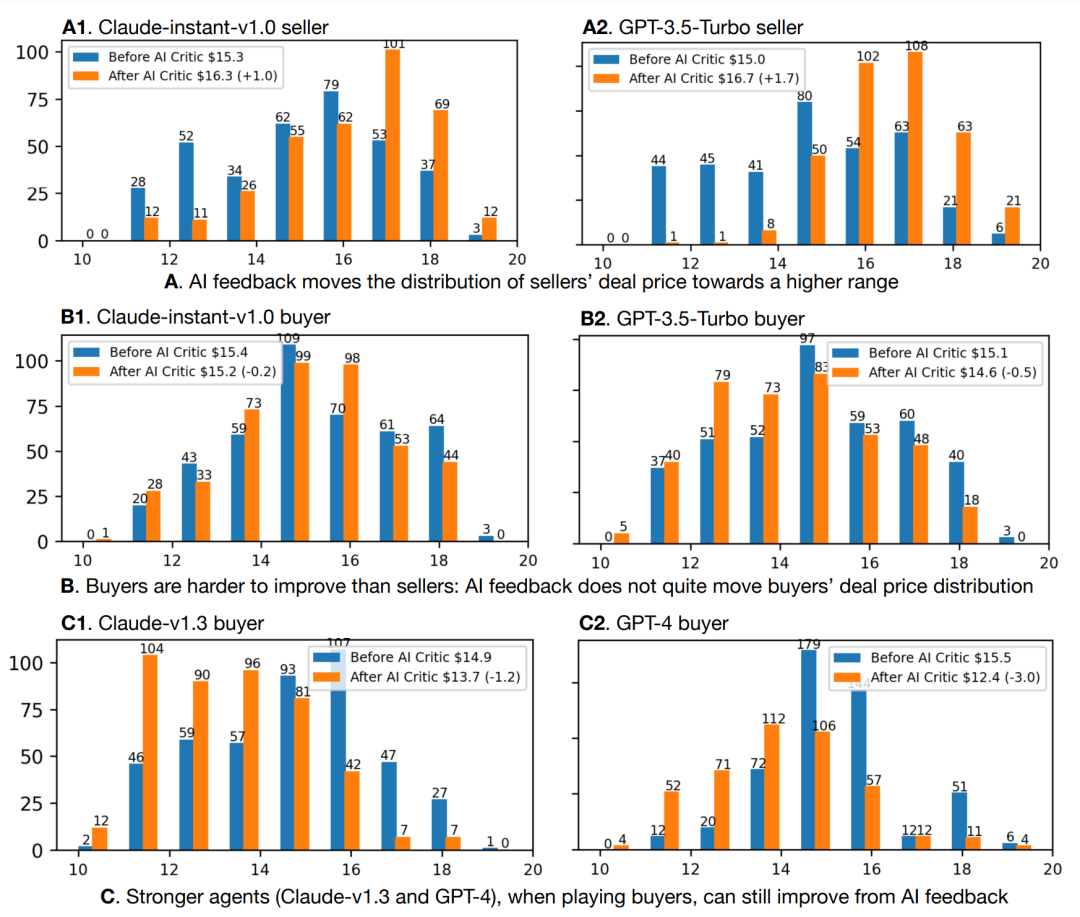 图:500场游戏的交易价格频率,反馈前v.s.反馈后。X轴是价格,Y轴是价格的频率
图:500场游戏的交易价格频率,反馈前v.s.反馈后。X轴是价格,Y轴是价格的频率
2. 迭代改进
将游戏展开到多轮,看看模型是否可以从先前的对话历史和迭代AI反馈中持续改进,会发现gpt-3.5-turbo可以在多轮中改进,但claude-instant-v1.0只能在最多一轮中改进。
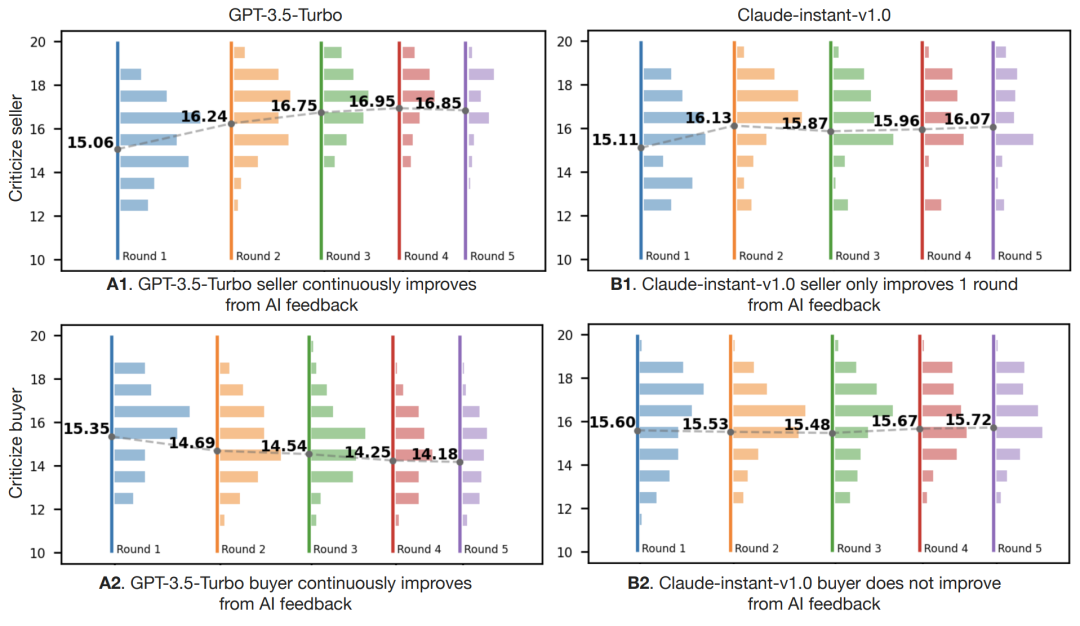 图:多回合设置中,不同的模型在扮演卖/买家时有不同的行为
图:多回合设置中,不同的模型在扮演卖/买家时有不同的行为
3. 成交价格和成交率的平衡
当扮演买家时,有些模型无法进行改进(claude-instant-v1.0),或在三轮之后趋于饱和(claude-v1.3),而gpt-4和gpt-3.5-turbo可以不断改进,gpt-4取得了比gpt-3.5-turbo更低的成交价格和更高的成交率。
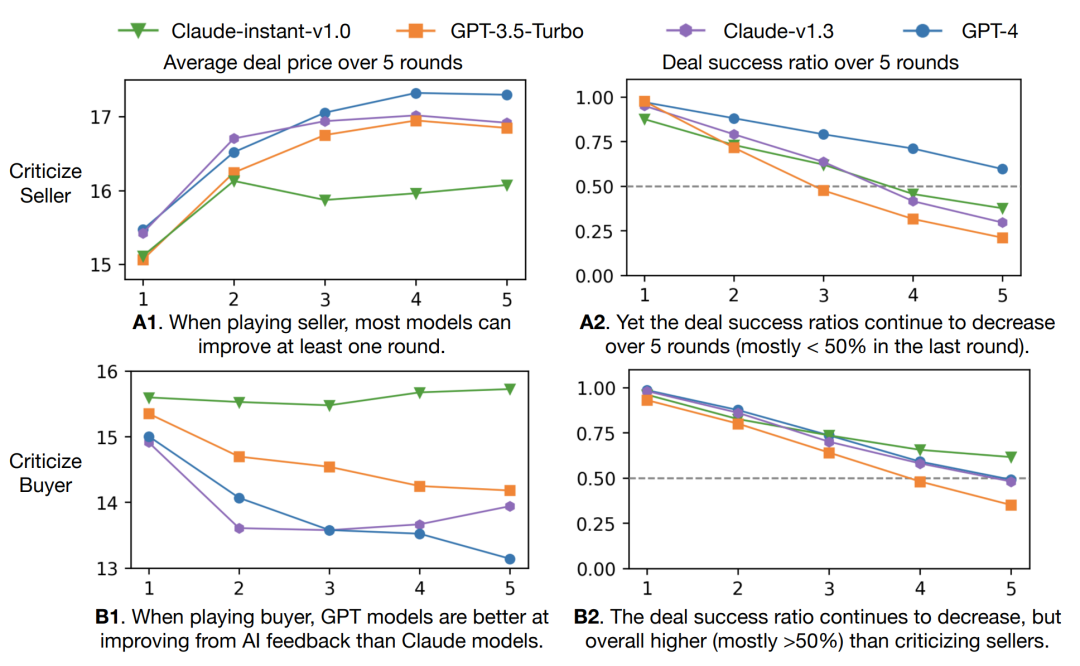 图:GPT和Claude模型在多轮游戏中的交易价格及成交率
图:GPT和Claude模型在多轮游戏中的交易价格及成交率
4. 语言复杂性
通过绘制每轮之后的平均响应长度(以字符数度量),可以看到,claude-v1.3和gpt-4在迭代AI反馈后回答变长。从具体的卖家回答示例也可以看到,经过多轮谈判,措辞也更加得体。但比起claude-v1.3,gpt-4能使用更少的词语实现更好的价格和成功率。
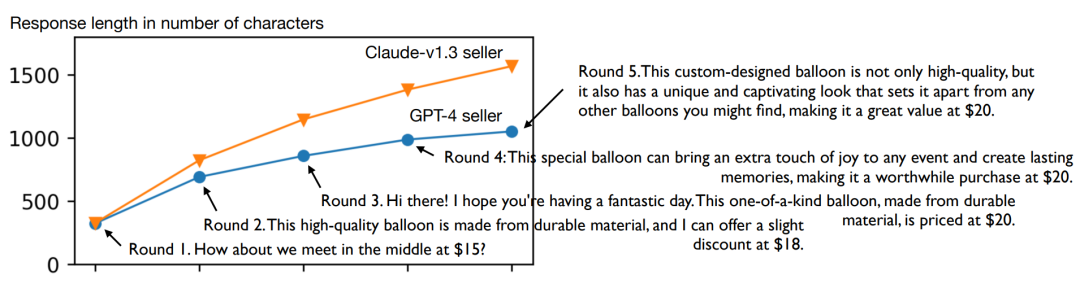 图:平均响应长度随着模型的多轮学习而增加
图:平均响应长度随着模型的多轮学习而增加
结论
大语言模型的确可以根据AI反馈迭代改进谈判策略,且更强的模型效果更明显!这个研究是否意味着,大语言模型可以在最少的人类干预下实现自我改进呢?只需给它一个评论家分身即可!
-
机器人
+关注
关注
211文章
28366浏览量
206887 -
AI
+关注
关注
87文章
30665浏览量
268828 -
模型
+关注
关注
1文章
3218浏览量
48801
原文标题:符尧最新研究:大语言模型玩砍价游戏?技巧水涨船高!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论