 一文告诉你AI模型QAT量化遇到震荡问题应该如何解决呢?
一文告诉你AI模型QAT量化遇到震荡问题应该如何解决呢?
1、简介
量化是优化神经网络以实现高效推理和设备执行同时保持高精度的最成功方法之一。通过将常规32位浮点格式的权重和激活压缩为更高效的低位定点表示,如INT8,这样可以在边缘设备上部署神经网络时降低功耗并加速推理。
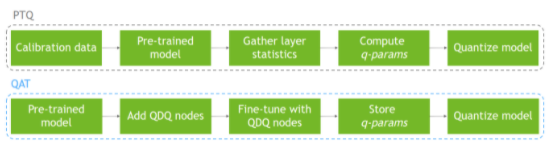
尽管量化具有明显的功率和延迟优势,但由于精度降低,量化是以增加噪声为代价的。然而,近年来的研究人员已经表明,神经网络对这种噪声是鲁棒的,并且可以使用训练后量化技术(PTQ)以最小的精度下降量化到8比特。
PTQ可能非常有效,通常只需要访问一个小的校准数据集,但当应用于神经网络的低位量化(≤4位)时会受到影响。同时,量化感知训练(QAT)已成为事实上的标准方法,用于实现低比特量化,同时保持接近全精度的精度。通过模拟训练或微调期间的量化操作,网络可以适应量化噪声,并达到比PTQ更好的解决方案。
本文重点关注量化权重在量化感知训练过程中发生的振荡。在量化神经网络的优化中,这是一个鲜为人知且研究不足的现象,在训练期间和训练后对网络产生了重大影响。当使用流行的直通估计器(STE)进行QAT时,权重似乎在相邻量化级别之间随机振荡,从而在优化过程中导致有害噪声。有了这一见解,作者调研了QAT的最新进展,这些进展声称性能得到了改善,并评估了它们在解决这种振荡行为方面的有效性。
权重振荡的一个不利症状是,它们会破坏在训练期间收集的批量归一化层的估计推断统计数据,导致验证准确性差。作者发现这种效应在具有深度可分离层的高效网络(如MobileNets或EfficientNets)的低位量化中尤为明显,但可以通过在训练后重新估计批量归一化统计数据来有效解决。
虽然批量归一化重新估计克服了振荡的一个显著症状,但它并没有解决其根本原因。为此,我们提出了两种有效减少振荡的新算法:振荡抑制和迭代权重冻结。通过在振荡源处处理振荡,本文的方法提高了精度,超出了批量归一化重新估计的水平。本文表明,这两种方法在高效网络的4-bit和3-bit量化方面都取得了最先进的结果,如MobileNetV2、MobileNetV3和ImageNet上的EfficientNet lite。
2、QAT中的振荡
首先研究了为什么权值在量化感知训练中会振荡,以及这种现象如何在实践中影响神经网络训练。
2.1、量化感知训练

2.2、振荡问题

在附录A.3中表明降低学习率会降低振荡的振幅,但不会影响其频率。

值得注意的是,这种行为与随机舍入有相似之处,其中潜在权重与量化水平的接近程度与舍入到该水平的概率有关。然而,在STE中,随机性的来源于梯度的离散性质,而不是采样。可以注意到,振荡并不是标准STE独有的,而是存在于文献中提出的STE的几种变体中,在图1中给出了其中的一小部分。
2.3、实践中的振荡
这些振荡不仅仅是这个toy例子的副作用。它们确实存在于更大的神经网络中,对它们的优化具有重要意义。图2显示了使用ImageNet上的LSQ训练的MobileNetV2的深度可分离层中接近收敛的3位量化权重的进展。可以观察到,许多权重似乎在2个相邻的量化级别之间随机振荡。

在图3中还可以看到,在假定的网络收敛之后,很大一部分潜在权重正好位于网格点之间的决策边界。这进一步强化了一个观察结果,即很大一部分权重会振荡而不收敛。
作者确定了与神经网络训练中的振荡相关的2个主要问题:
批量归一化推理统计的错误估计
对网络优化的不利影响
1、批量标准化的影响
在训练批量归一化过程中,层跟踪每层输出的平均值和方差的指数移动平均值(EMA),以便在推理过程中用作真实样本统计的近似值。当训练全精度神经网络时,可以预期权重在接近收敛时会非常缓慢地变化。因此,预计每一层的输出统计数据在迭代过程中都相当稳定,因此EMA是统计数据的一个很好的估计。

然而,QAT中的振荡会导致整数权重的快速变化(见图2),从而导致迭代之间的显著分布偏移,甚至接近收敛。振荡引起的输出分布的突然而大的变化可能会破坏EMA统计数据,导致准确性的显著下降。
事实上,有两个因素放大了这种影响:
权重位宽
每个输出通道的权重数量

比特宽度越低,量化级别之间的距离就越大,因为它与成比例。当振荡权重从一个量化级别移动到另一个量化级时,它们在输出分布中造成成比例的较大偏移。第二个重要因素是每个输出通道的权重数量。权重的数量越小,单个权重对最终累积的贡献就越大。当累积数量增加时,由于大数定律,振荡的影响趋于平均。
在表1中,使用KL散度来量化population和 estimated statistics之间的差异,确实观察到,与MobileNetV2中的逐点卷积和ResNet18中的全卷积相比,深度可分离层的KL发散要大得多。
这个问题的一个简单直接的解决方案是在训练后用一小部分数据重新估计批量归一化统计。这种方法作者称之为批处理归一化(BN)重新估计,有时用于随机量化公式。然而,作者认为由于振荡权重,它在确定性QAT公式中也是必不可少的。

在表2中可以看到BN重新估计不仅提高了MobileNetV2的最终量化精度,而且降低了不同种子之间的方差。作者进一步观察到,对于MobileNetV2,随着比特宽度的减小,精度上的差距变大,而对于ResNet18,情况并非如此。
2、对训练的影响
除了损害BN统计之外,振荡还可能对训练过程本身产生负面影响。为了说明这一点,首先表明,如果在两种振荡状态之间随机采样振荡权重,则具有3位权重的收敛MobileNetV2可以实现较低的训练损失(和较高的验证精度)。

在表3中给出了这个实验的结果。可以观察到,采样网络上的平均训练损失与最终收敛模型的平均训练损失相似。然而,许多样本实现了较低的训练损失,并且最佳随机采样网络显示出显著较低的训练损失。
作者还使用AdaRound的自适应来执行振荡权重的二进制优化。在最终任务丢失时同时优化所有层的舍入,类似于文献中使用模拟退火来解决二进制优化问题。可以看到,这种二进制优化在最佳随机样本和原始收敛网络的基础上显著改进。这表明,权重振荡会阻止网络在训练过程中收敛到最佳局部最小值,并可能对优化过程不利。
最后,在训练的早期使用振荡冻结技术防止振荡会导致比振荡权重的二元优化更高的验证精度。这表明,振荡不仅会阻止QAT在训练结束时收敛到最佳局部最小值,而且还会导致优化器在训练早期朝着次优方向发展。
3、克服QAT的振荡问题
既然已经确定了振荡在优化过程中可能会产生负面影响,特别是对于低位量化,所以就把重点放在如何克服它们上。首先,引入了一种用于量化振荡的度量,然后提出了两种新的技术,旨在防止在量化感知训练过程中出现振荡。
3.1、量化振荡
在解决振荡之前,需要一种在训练中检测和测量振荡的方法。建议使用指数移动平均(EMA)来计算随时间变化的振荡频率。然后,可以将最小频率定义为振荡权重的阈值。对于在迭代t中发生的振荡,需要满足两个条件:

然后,使用指数移动平均(EMA)来跟踪随时间变化的振荡频率:

3.2、振荡阻尼
当权重振荡时,它们总是在两个量化区间之间的决策阈值附近移动。这意味着振荡权重总是接近量化bin的边缘。为了抑制振荡行为,使用了一个正则化项,该项鼓励潜在权重靠近bin的中心而不是边缘。将类似于权重衰减的阻尼损失定义为:

独立于标度s,因此间接独立于位宽。进一步将潜在权重剪裁到量化网格的范围,使得只有在量化期间没有被剪裁的权重才会获得正则化效果。这对于避免在基于LSQ的范围学习中与量化尺度梯度的任何有害相互作用很重要。这种正则化的缺点是,它不仅影响振荡的权重,而且还会阻碍不处于振荡状态的权重的移动。
3.3、振荡权值的迭代冻结
作者提出了另一种更有针对性的方法,通过在训练中冻结权重来防止权重振荡。在这种方法中,跟踪训练期间每个权重的振荡频率,如方程(4)所述。如果任何权重的振荡频率超过阈值,该权重将被冻结,直到训练结束。在整数域中应用冻结,以便在优化过程中scale 的潜在变化不会导致不同的舍入。
当一个权重振荡时,它不一定在两种振荡状态下花费相等的时间。正如在第2.2节的示例中所示,权重处于每个状态的可能性线性地取决于该量化状态与最优值的距离。结果,随着时间的推移,所有量化值的期望将对应于最优值。一旦权重的频率超过阈值,它就可能处于两种量化状态中的任何一种。为了将权重冻结到更频繁的状态,使用指数移动平均值(EMA)记录以前的整数值。然后,通过四舍五入EMA将最频繁的整数状态分配给冻结权重。

在算法1中总结了提出的迭代权重冻结。注意,该算法可以与任何基于梯度的优化器组合使用,并且不限于特定的量化公式或梯度估计器。在迭代级别上冻结权重的想法与迭代修剪密切相关,在迭代修剪中,小权重被迭代修剪(冻结为零)。
4、实验
4.1、消融实验
1、振荡阻尼



在表4中,作者研究了阻尼损失的强度如何影响网络的最终精度以及训练结束时振荡权重的比例。在前3行中可以观察到,随着系数λ的增加,振荡权重的比例降低,BN重新估计前后的精度差距缩小。然而,过多的阻尼会损害最终的精度,这表明过度的正则化会抑制权重在量化级别之间的有益移动。
解决这个问题的方法是在训练过程中逐渐增加正规化权重。这允许潜在权重在训练的第一阶段更自由地移动,同时通过应用更强的正则化来减少接近收敛的有害振荡。
作者发现λ的余弦退火计划在实践中效果良好。Han等人也注意到,这种规则化在训练的早期阶段是有害的,但实际上采用了两阶段优化过程。这样的策略可以显著抑制振荡,同时不会损害准确性。最佳阻尼配置比BN后重新估计基线提高了近1%,比BN前重新估计基线改善了5%以上。
在图4(左)中还看到了阻尼对图3中相同深度可分离层的潜在重量分布的影响。正如预期的那样,潜在权重现在聚集在量化bin中心周围,在决策边界几乎没有任何权重。
2、迭代权重冻结

在表5中展示了迭代权重冻结算法对各种冻结阈值的有效性。在整个训练过程中使用恒定的阈值,可以看到残差振荡的数量随着阈值的降低而显著减少,并且网络中只保留一些低频振荡。还可以看到,前BN重新估计精度更接近后BN重新估计准确性,正如人们在训练结束时振荡较少时所预期的那样。
然而,如果振荡阈值变得太低,那么在训练的早期阶段,太多的权重会被冻结,从而降低最终的准确性。为了解决这个问题,对冻结阈值应用了一个类似于阻尼中使用的退火计划。这能够使用更强的冻结阈值,并在训练结束时冻结几乎所有的振荡,此时它们最具破坏性。
最佳冻结阈值比BN后重新估计基线提高了近1%,比BN前重新估计基线改善了5%以上。它的精度与振荡阻尼相当,同时残差振荡显著减少(0.04%对1.11%)。
在图4(右)中可以看到迭代权值冻结如何改变MobileNetV2的层conv.3.1的潜在权值分布。大部分潜在权值现在被冻结在bin中心,去除在图3中决策边界观察到的峰值。
4.2、与其他QAT方法的比较

将克服振荡的方法与其他QAT替代方案进行了比较,并证明了它们在流行的高效神经网络的低比特量化中的有效性。为了与文献中现有的方法进行比较,作者对权重和激活进行了量化。在表6中展示了MobileNetV2的结果,并证明两种算法在3-bits和4-bits量化方面都优于文献中所有竞争的QAT技术。


还在表7和表8中分别获得了MobileNetV3 Small和EfficientNet lite的最新结果。在所有情况下,本文的振荡预防方法都比常用的LSQ基线显著提高(>1%),表明本文的方法对其他高效网络的普遍适用性。
可以注意到,与LSQ基线相比,振荡抑制导致训练时间增加了约33%。另一方面,迭代权重冻结在实现类似性能的同时,计算开销可以忽略不计。
-
振荡器
+关注
关注
28文章
3832浏览量
139050 -
神经网络
+关注
关注
42文章
4771浏览量
100722
发布评论请先 登录
相关推荐
在LTspice中导入模型时遇到相关问题
多层板的焊盘到底应该怎么设计?华秋一文告诉你
X-CUBE-AI 7.1.0生成代码初始化错误如何解决呢?
【KV260视觉入门套件试用体验】Vitis AI 进行模型校准和来量化
一文告诉你如何用好AD797
Google发布新API,支持训练更小更快的AI模型
利用NVIDIA TensorRT实现推理的QAT伪量化
使用NVIDIA QAT工具包实现TensorRT量化网络的设计





 工商网监
工商网监
评论