 中通快递采用英特尔数据中心GPU实现更高效的分拨视频流分析
中通快递采用英特尔数据中心GPU实现更高效的分拨视频流分析
随着电商行业的快速发展,快递业务总量增长迅猛。据统计,2022年上半年,全国快递服务企业的业务量累计完成512.2亿票,同比增长3.7%1。
一年一度的618即将来临,想必大家已经加好购物车了。这次可以放心在家等快递,因为快递巨头中通、韵达在提高效率和智慧化上,也已经做好了十足的准备。
优化视觉AI方案
为应对激增的业务量并提升快件揽收量与派送效率,上海韵达货运有限公司实施了网格仓2策略,借助由视觉人工智能 (AI) 驱动的智能共配3分拣系统对快件进行自动分拣。同时,由于快递行业重时效的特性,推进全链路时效优化也十分必要,为此,韵达正大力推广分拨视频分析平台以分析包括格口在内的分拨视频,进而优化激励机制和业务管理能力。然而,在项目推进过程中,韵达遇到了以下挑战:格仓承载快件数量庞大,例如上海某网点的网格仓试点每日需要处理的快件数量高达3万票4;智能分拣线须兼顾高准确度和低时延,系统识别的准确度须达到95%以上,智能分拣线系统的时延必须要小于130ms;视频流分析体量庞大,对算力要求高。
针对以上挑战,韵达基于英特尔 数据中心GPU Flex系列170和英特尔 分发版OpenVINO 工具套件来优化其三段码OCR检测系统和分拨视频分析平台性能。英特尔 数据中心GPU Flex 系列170是英特尔面向视觉AI和智能云计算等场景而打造的、基于英特尔 Xe 架构的GPU,拥有高达512个执行单元,能够保证多线程处理的吞吐量,同时支持H.264、H.265 (HEVC)硬件编码/解码和AV1编码/解码5,高度契合韵达视觉AI方案对图片与视频处理的需求。
英特尔 OpenVINO 具套件包含模型优化器和推理引擎两大组件。韵达利用 OpenVINO 模型优化器MO (Model Optimizer) 可将Caffe、TensorFlow、Pytorch和PaddlePaddle等多种常见框架的模型转换为OpenVINO 中间数据格式(IR, Intermediate Representation)的离线模型,并且对这些模型的性能进行优化;推理引擎则可以为跨英特尔多种芯片(包括 CPU、GPU和FPGA等)的计算机视觉异构计算提供加速支持。
为验证方案性能,韵达进行了三段码OCR测试和TSM (Temporal Shift Module)测试。在三段码OCR测试中,共对2450张图片进行了识别,测试结果显示平均运行时间为114 ms8,优于韵达130 ms的期望标准,可很好地满足韵达对低时延的需求。此外,根据实验室测试结果,经优化后,三段码OCR识别的准确度能够达到97 %-98%6,也优于韵达95%的预期基准。在TSM测试中,选用了1200个视频并分不同实例和批量大小做了测试,测试结果如下图所示。
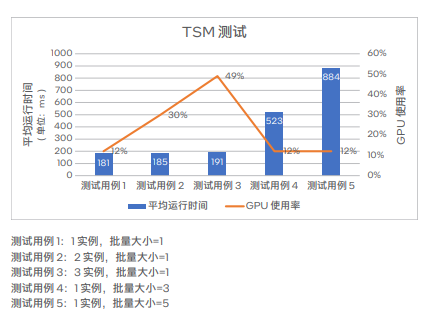
基于英特尔 数据中心 GPU Flex 170 的 TSM 测试 结果6
综合测试和网点试点结果,基于英特尔 数据中心GPU Flex系列170和英特尔 分发版OpenVINO 工具套件的视觉AI方案,从算力、时延、准确度、并发能力、稳定性和散热能力等多个方面都能很好地满足韵达的需求,并为韵达带来了以下业务优势:
提升业务效率并降低成本:智能分拣系统的部署显著提升了分拣线效率,进而提升了派送效率和派送时效;此外,高效的智能分拣系统还帮助韵达实现了人力和成本节约。
优化业务管理和决策:英特尔 数据中心GPU Flex系列170带来的高算力让韵达实现了更高效的分拨视频流分析,可帮助韵达在跨年度/跨季度预测、合理定价、网点时效提升和奖惩制定等方面做出优化。
中通快递采用英特尔 数据中心GPU和OpenVINO
以更高性价比扩展边缘视觉AI应用
一直以来,中通快递都在追求更先进、易用的技术方案来优化物流园区作业、运输和管理,在早期部署的边缘视觉AI方案,就能有效监测园区内是否存在攀爬传送带等危险作业,踩踏、暴力分拣等违规作业,以及未戴安全帽等着装安全问题。但随着业务的快速发展以及技术应用的不断深入,中通对边缘视觉AI方案提出了更高的要求,既要满足业务端的更多需求,比如在场区的分拣方面,可能存在的小件堵包、流水线拥堵和挂包等情况,以做到“实时发现、实时告警”等;又要让模型开发与维护更简洁、更高效,并降低成本,在实际场景中实现更高性价比。
为应对以上挑战,中通众多中心或网点都部署了新的英特尔 数据中心GPU Flex系列。在英特尔工程师的协助下,中通只需在相同模型上进行开发,即可基于XPU实现AI推理加速,从而实现对各种资源的充分利用。例如,同一模型,在对轻量级AI业务场景时,可以直接使用CPU,而在对实时性要求较高或者多并发的场景时,则使用英特尔 数据中心GPU Flex系列,从而减少针对不同硬件开发不同模型的负担,降低全网部署的难度。
英特尔 分发版 OpenVINO 工具套件是一个旨在优化和部署AI推理的开源工具套件。首先,中通利用其中的模型优化器可将基于其他深度学习框架的模型转换为统一且性能经过优化的OpenVINO IR模型,有效降低了模型优化与运维的复杂程度。其次,此工具套件中的Open Model Zoo提供了大量的免费且预训练好的深度学习模型及演示应用。中通在此次项目中也选用了其中的一些模型,有效地降低了模型开发难度并缩短了应用开发时间。同时,中通还利用了工具套件中的英特尔 Deep Learning Streamer (DL Streamer)7 并结合自身应用场景的特点创建了用于视频解码、编码和媒体智能分析的业务流,实现了在边缘对音视频进行智能分析和对英特尔 硬件平台的充分利用。
为满足像视频流计算这样对算力和实时性要求较高的应用需求,中通按需导入了英特尔 GPU Flex系列170,对部分服务器进行了升级改造并针对其ZTO Yolo v4 推理业务流进行了测试。测试结果显示,这一产品性能出色,可很好地满足中通相关应用场景的需求。
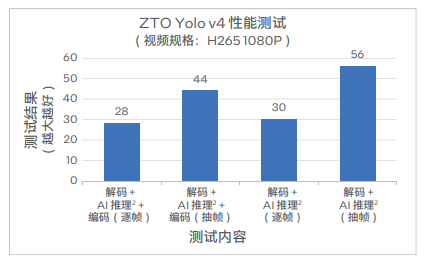
英特尔软硬件全面创新
助力千行百业数智化转
英特尔除了在软硬件全面创新,满足各类需求,还拥有强大的生态系统和可靠的专业支持,来助力快递行业以及各行各业的数智化转型。
从算力提升到框架指令的适配,英特尔着眼AI应用开发与部署的各个环节,全面创新,旨在满足用户的不同需求。硬件层面,英特尔持续增强其CPU英特尔 至强 可扩展处理器的内置AI加速能力,第四代英特尔至强可扩展处理器内置了全新的英特尔高级矩阵扩展(英特尔 AMX),可大幅提高深度学习训练和推理性能。同时,英特尔还推出包括GPU、FPGA和VPU在内的各类专用加速器以满足不同场景对算力的特定需求。软件层面,从模型、框架到底层库,英特尔也在不断创新以适配各类硬件,赋能用户更好地基于英特尔 架构实现AI加速。例如,在英特尔 oneAPI 和OpenVINO 工具套件的支持下,模型可实现跨英特尔 CPU和GPU的无缝切换,且几乎不会对应用层造成任何影响。
部署并加速AI应用开发并非易事,尤其是在异构计算兴起的今天,高要求、大规模AI应用更是变得越来越复杂。英特尔强大的生态系统和专业的技术支持团队可为用户在项目前、项目中和项目后提供参考方案和专业支持,显著降低企业IT团队AI应用开发的复杂度并提升效率。
-
英特尔
+关注
关注
61文章
10019浏览量
172451 -
gpu
+关注
关注
28文章
4791浏览量
129473 -
数据中心
+关注
关注
16文章
4873浏览量
72435 -
AI
+关注
关注
87文章
31785浏览量
270578
原文标题:迎战快递高峰期,韵达、中通做了哪些准备?
文章出处:【微信号:英特尔中国,微信公众号:英特尔中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英特尔数据中心CPU销量降至14年最低
英特尔推出全新英特尔锐炫B系列显卡

第17届英特尔互联网数据中心大会顺利举行
英特尔12月或发布Battlemage GPU芯片
AMD数据中心营收首超英特尔
AMD数据中心业务首超英特尔,Nvidia异军突起
英特尔发布至强6性能核处理器,携手生态加速数据中心算力升级

英特尔数据中心XPU产品最新进展:预计2027年发布
英特尔是如何实现玻璃基板的?
英特尔OCI芯粒在新兴AI基础设施中实现光学I/O(输入/输出)共封装
英特尔实现光学IO芯粒的完全集成

英特尔中国投资立讯精密子公司,携手推进数据中心业务
采用144核,能效提升66%!英特尔至强6处理器震撼上市,加速数据中心升级






 工商网监
工商网监
评论