 在AI爱克斯开发板上用OpenVINO加速YOLOv8-seg实例分割模型
在AI爱克斯开发板上用OpenVINO加速YOLOv8-seg实例分割模型
 请先下载本文的范例代码仓,并搭建好YOLOv8的OpenVINO推理程序开发环境。
git clone https://gitee.com/ppov-nuc/yolov8_openvino.git
导出YOLOv8-seg实例分割OpenVINO IR模型
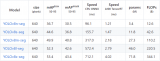
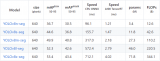
YOLOv8-seg的实例分割模型有5种,在COCO数据集完成训练,如下表所示。
请先下载本文的范例代码仓,并搭建好YOLOv8的OpenVINO推理程序开发环境。
git clone https://gitee.com/ppov-nuc/yolov8_openvino.git
导出YOLOv8-seg实例分割OpenVINO IR模型
YOLOv8-seg的实例分割模型有5种,在COCO数据集完成训练,如下表所示。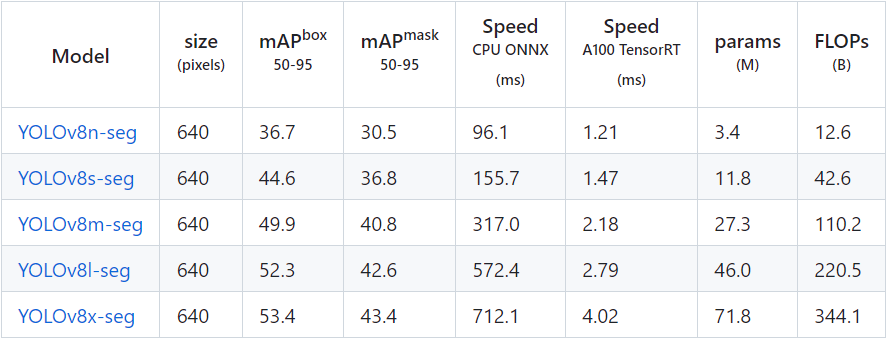 首先使用命令:yolo export model=yolov8n-seg.pt format=onnx,完成yolov8n-seg.onnx模型导出,如下图所示。
首先使用命令:yolo export model=yolov8n-seg.pt format=onnx,完成yolov8n-seg.onnx模型导出,如下图所示。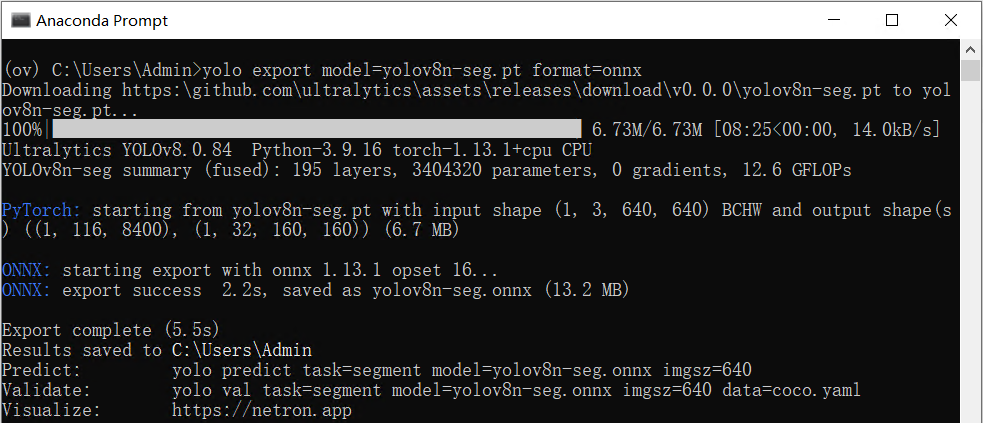 然后使用命令:mo -m yolov8n-seg.onnx --compress_to_fp16,优化并导出FP16精度的OpenVINO IR格式模型,如下图所示。
然后使用命令:mo -m yolov8n-seg.onnx --compress_to_fp16,优化并导出FP16精度的OpenVINO IR格式模型,如下图所示。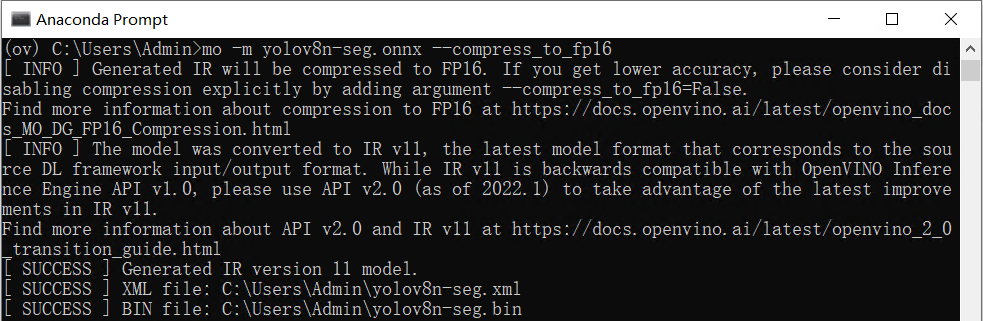 用benchmark_app测试YOLOv8-seg实例分割模型的推理计算性能
benchmark_app是OpenVINOTM工具套件自带的AI模型推理计算性能测试工具,可以指定在不同的计算设备上,在同步或异步模式下,测试出不带前后处理的纯AI模型推理计算性能。
使用命令:benchmark_app -m yolov8n-seg.xml -d GPU,获得yolov8n-seg.xml模型在AI爱克斯开发板的集成显卡上的异步推理计算性能,如下图所示。
用benchmark_app测试YOLOv8-seg实例分割模型的推理计算性能
benchmark_app是OpenVINOTM工具套件自带的AI模型推理计算性能测试工具,可以指定在不同的计算设备上,在同步或异步模式下,测试出不带前后处理的纯AI模型推理计算性能。
使用命令:benchmark_app -m yolov8n-seg.xml -d GPU,获得yolov8n-seg.xml模型在AI爱克斯开发板的集成显卡上的异步推理计算性能,如下图所示。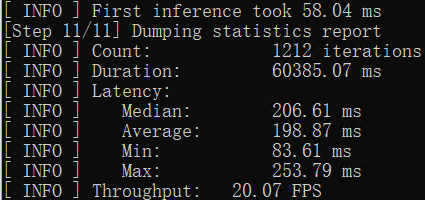 使用OpenVINO Python API编写YOLOv8-seg实例分割模型推理程序
用Netron打开yolov8n-seg.onnx可以看到模型的输入和输出,跟YOLOv5-seg模型的输入输出定义很类似:
使用OpenVINO Python API编写YOLOv8-seg实例分割模型推理程序
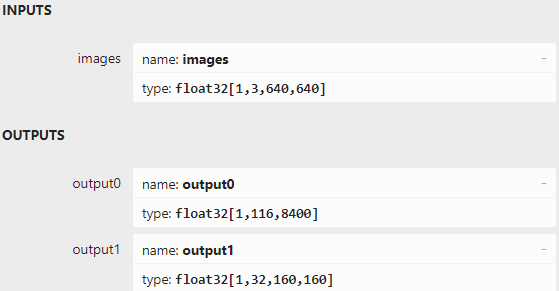
用Netron打开yolov8n-seg.onnx可以看到模型的输入和输出,跟YOLOv5-seg模型的输入输出定义很类似:-
输入节点名字:“images”;数据:float32[1,3,640,640]。
-
输出节点1的名字:“output0”;数据:float32[1,116,8400]。其中116的前84个字段跟 YOLOv8目标检测模型输出定义完全一致,即cx,cy,w,h和80类的分数;后32个字段用于计算掩膜数据。
-
输出节点2的名字:“output1”;数据:float32[1,32,160,160]。output0后32个字段与output1的数据做矩阵乘法后得到的结果,即为对应目标的掩膜数据。
 基于OpenVINO Python API的YOLOv8-seg实例分割模型范例程序yolov8_seg_ov_sync_infer_demo.py的核心源代码,如下所示:
基于OpenVINO Python API的YOLOv8-seg实例分割模型范例程序yolov8_seg_ov_sync_infer_demo.py的核心源代码,如下所示:# Initialize the VideoCapture
cap =cv2.VideoCapture("store-aisle-detection.mp4")
# Initialize YOLOv5 Instance Segmentator
model_path ="yolov8n-seg.xml"
device_name ="GPU"
yoloseg =YOLOSeg(model_path, device_name, conf_thres=0.3, iou_thres=0.3)
whilecap.isOpened():
# Read frame from the video
ret, frame =cap.read()
ifnotret:
break
# Update object localizer
start =time.time()
boxes, scores, class_ids, masks =yoloseg(frame)
# postprocess and draw masks
combined_img =yoloseg.draw_masks(frame)
end =time.time()
# show FPS
fps =(1/(end -start))
fps_label ="Throughput: %.2fFPS"%fps
cv2.putText(combined_img, fps_label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# show ALL
cv2.imshow("YOLOv8 Segmentation OpenVINO inference Demo", combined_img)
# Press Any key stop
ifcv2.waitKey(1) >-1:
print("finished by user")
break
运行结果,如下图所示: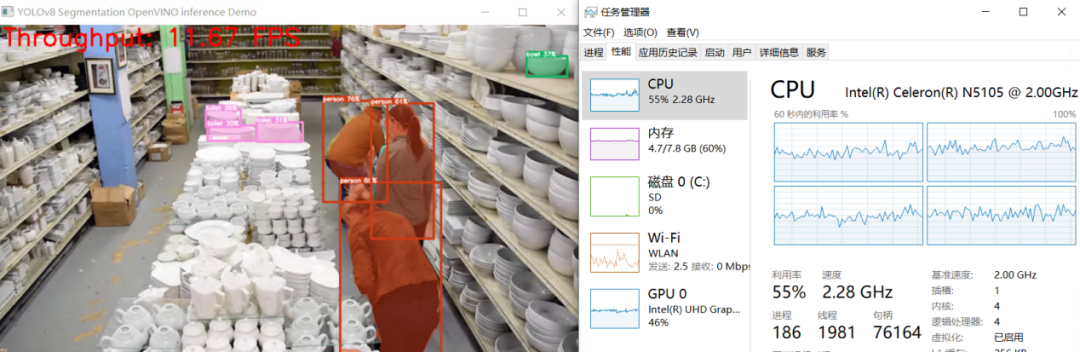 结 论
AI爱克斯开发板借助N5105处理器的集成显卡(24个执行单元)和OpenVINO,可以在YOLOv8-seg的实例分割模型上获得相当不错的性能。通过异步处理和AsyncInferQueue,还能进一步提升计算设备的利用率,提高AI推理程序的吞吐量。下一篇将继续介绍在《在AI爱克斯开发板上用OpenVINO加速YOLOv8-pose姿态检测模型》。
审核编辑 :李倩
结 论
AI爱克斯开发板借助N5105处理器的集成显卡(24个执行单元)和OpenVINO,可以在YOLOv8-seg的实例分割模型上获得相当不错的性能。通过异步处理和AsyncInferQueue,还能进一步提升计算设备的利用率,提高AI推理程序的吞吐量。下一篇将继续介绍在《在AI爱克斯开发板上用OpenVINO加速YOLOv8-pose姿态检测模型》。
审核编辑 :李倩-
开发板
+关注
关注
25文章
5161浏览量
98506 -
模型
+关注
关注
1文章
3387浏览量
49342 -
目标检测
+关注
关注
0文章
212浏览量
15686
原文标题:在AI爱克斯开发板上用OpenVINO加速YOLOv8-seg实例分割模型
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
在C++中使用OpenVINO工具包部署YOLOv5-Seg模型
【爱芯派 Pro 开发板试用体验】yolov8模型转换
在英特尔独立显卡上部署YOLOv5 v7.0版实时实例分割模型
在C++中使用OpenVINO工具包部署YOLOv5模型
TensorRT 8.6 C++开发环境配置与YOLOv8实例分割推理演示


自训练Pytorch模型使用OpenVINO™优化并部署在AI爱克斯开发板


在英特尔开发者套件上用OpenVINO™ 2023.0加速YOLOv8-Pose姿态估计模型

用OpenVINO™ C++ API编写YOLOv8-Seg实例分割模型推理程序
基于OpenVINO在英特尔开发套件上实现眼部追踪
基于哪吒开发板部署YOLOv8模型






 工商网监
工商网监
评论