 第一篇综述!分割一切模型(SAM)的全面调研
第一篇综述!分割一切模型(SAM)的全面调研
作为首个全面介绍基于 SAM 基础模型进展的研究,本文聚焦于 SAM 在各种任务和数据类型上的应用,并讨论了其历史发展、近期进展,以及对广泛应用的深远影响。
人工智能(AI)正在向 AGI 方向发展,这是指人工智能系统能够执行广泛的任务,并可以表现出类似于人类的智能水平,狭义上的 AI 就与之形成了对比,因为专业化的 AI 旨在高效执行特定任务。可见,设计通用的基础模型迫在眉睫。基础模型在广泛的数据上训练,因而能够适应各种下游任务。最近 Meta 提出的分割一切模型(Segment Anything Model,SAM)突破了分割界限,极大地促进了计算机视觉基础模型的发展。
SAM 是一个提示型模型,其在 1100 万张图像上训练了超过 10 亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。
为了充分了解 SAM,来自香港科技大学(广州)、上海交大等机构的研究者对其进行了深入研究并联合发表论文《 A Comprehensive Survey on Segment Anything Model for Vision and Beyond 》。

论文:https://arxiv.org/abs/2305.08196
作为首个全面介绍基于 SAM 基础模型进展的研究,该论文聚焦于 SAM 在各种任务和数据类型上的应用,并讨论了其历史发展、近期进展,以及对广泛应用的深远影响。
本文首先介绍了包括 SAM 在内的基础模型的背景和术语,以及对分割任务有重要意义的最新方法;
然后,该研究分析并总结了 SAM 在各种图像处理应用中的优势和限制,包括软件场景、真实世界场景和复杂场景,重要的是,该研究得出了一些洞察,以指导未来的研究发展更多用途广泛的基础模型并改进 SAM 的架构;
最后该研究还总结了 SAM 在视觉及其他领域的应用。
下面我们看看论文具体内容。
SAM 模型概览
SAM 源自于 2023 年 Meta 的 Segment Anything (SA) 项目。该项目发现在 NLP 和 CV 领域中出现的基础模型表现出较强的性能,研究人员试图建立一个类似的模型来统一整个图像分割任务。然而,在分割领域的可用数据较为缺乏,这与他们的设计目的不同。因此,如图 1 所示,研究者将路径分为任务、模型和数据三个步骤。
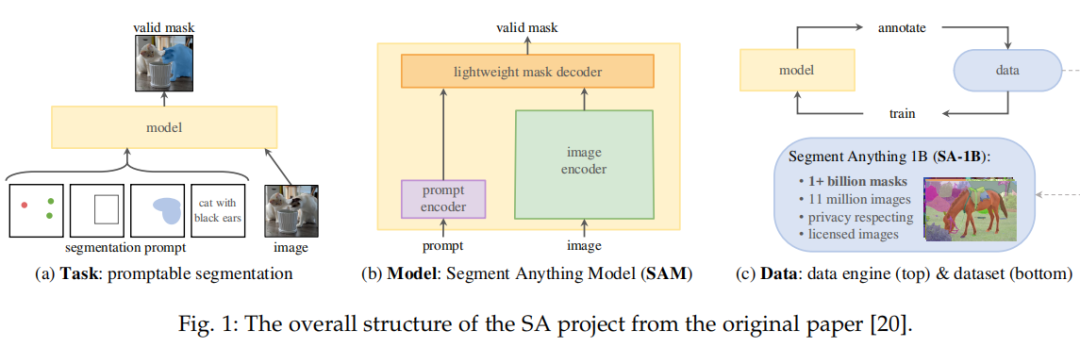
SAM 架构如下所示,主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。
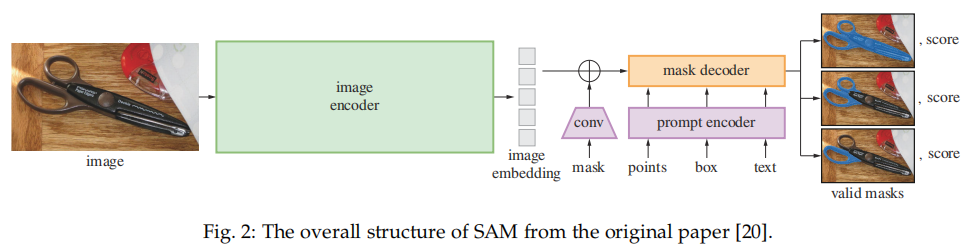
在对 SAM 有了初步认知后,接下来该研究介绍了 SAM 用于图像处理。
SAM 用于图像处理
这部分主要分场景进行介绍,包括:软件场景、真实场景以及复杂场景。
软件场景
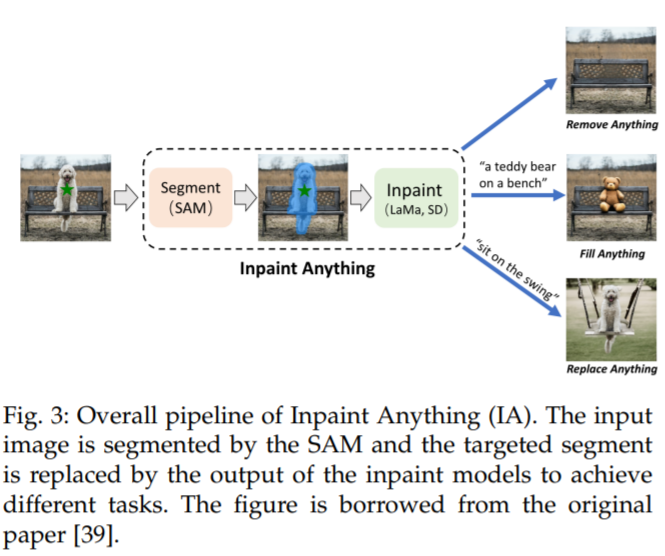
软件场景需要对图像编辑和修复进行操作,例如移除对象、填充对象和替换对象。然而,现有的修复工作,如 [99]、[100]、[101]、[102],需要对每个掩码进行精细的注释以达到良好的性能,这是一项劳动密集型的工作。SAM [20] 可以通过简单的提示如点或框来生成准确的掩码,可以帮助辅助图像编辑场景。
Inpaint Anything (IA) [39] 设计了一个流程,通过结合 SAM 的优势、最先进的图像修复器 [99],以及 AI 生成的内容模型 [103],来解决与修复相关的问题。这个流程如图 3 所示。对于对象移除,该流程由 SAM 和最先进的修复器组成,如 LaMa [99]。用户的点击操作被用作 SAM 的提示,以生成对象区域的掩码,然后 LaMa 使用 corrosion 和 dilation 操作进行填充。对于对象的填充和替换,第二步使用像 Stable Diffusion (SD) [103] 这样的 AI 生成的内容模型,通过文本提示用新生成的对象填充选定的对象。
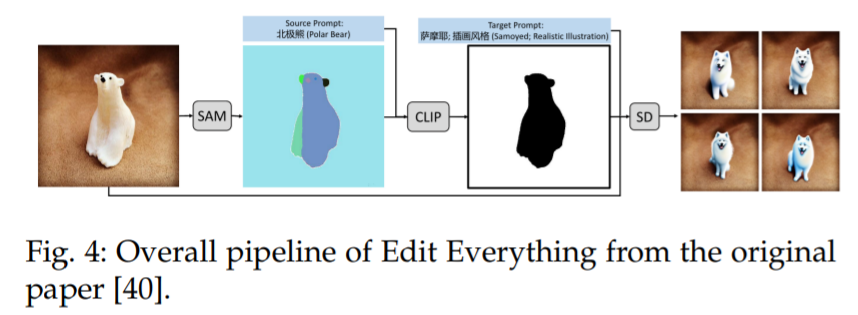
一个类似的想法也可以在 Edit Everything [40] 中看到,如图 4 所示,该方法允许用户使用简单的文本指令编辑图像。
真实场景
研究者表示 SAM 具有协助处理许多真实世界场景的能力,例如真实世界的物体检测、物体计数以及移动物体检测场景。最近,[108] 对 SAM 在多种真实世界分割场景(例如,自然图像、农业、制造业、遥感和医疗健康场景)中的性能进行了评估。该论文发现,在像自然图像这样的常见场景中,它具有优秀的泛化能力,而在低对比度的场景中,它的效果较差,而且在复杂场景中需要强大的先验知识。
例如,在民用基础设施缺陷评估的应用中,[42] 利用 SAM 来检测混凝土结构中的裂缝,并将其性能与基线 U-Net [109] 进行比较。裂缝检测过程如图 6 所示。结果显示,SAM 在检测纵向裂缝方面表现优于 UNet,这些裂缝更可能在正常场景中找到类似的训练图像,而在不常见的场景,即剥落裂缝方面,SAM 的表现不如 U-Net。
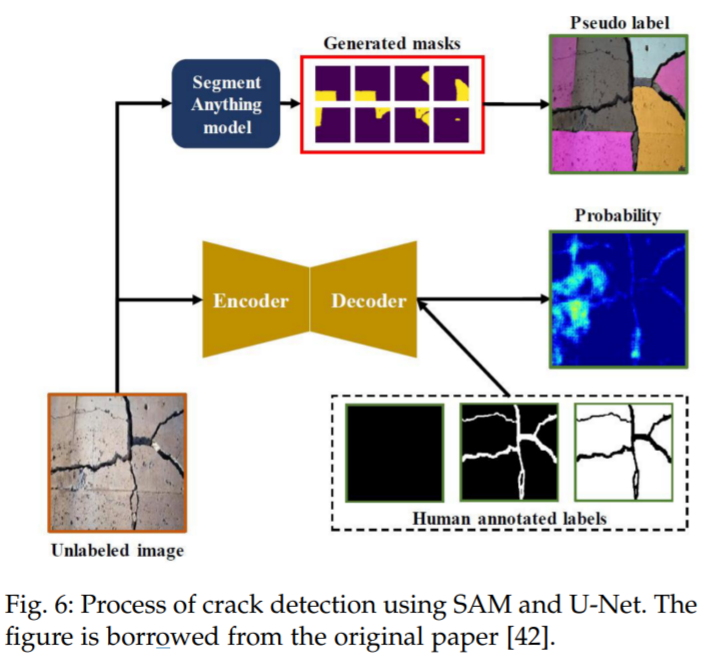
使用 SAM 和 U-Net 进行裂纹检测的过程。图摘自原论文 [42]。
与裂缝检测中的复杂图像案例不同,由于陨石坑的形状主要集中在圆形或椭圆形,所以使用 SAM 作为检测工具来进行陨石坑检测更为合适。陨石坑是行星探索中最重要的形态特征之一,检测和计数它们是行星科学中一个重要但耗时的任务。尽管现有的机器学习和计算机视觉工作成功地解决了陨石坑检测中的一些特定问题,但它们依赖于特定类型的数据,因此在不同的数据源中无法很好地工作。
在 [110] 中,研究者提出了一种使用 SAM 对不熟悉对象进行零样本泛化的通用陨石坑检测方案。这个流程使用 SAM 来分割输入图像,对数据类型和分辨率没有限制。然后,它使用圆形 - 椭圆形指数来过滤不是圆形 - 椭圆形的分割掩码。最后,使用一个后处理过滤器来去除重复的、人为的和假阳性的部分。这个流程在当前领域显示出其作为通用工具的巨大潜力,并且作者还讨论了只能识别特定形状的缺点。
复杂场景
除了上述的常规场景,SAM 是否能解决复杂场景(如低对比度场景)中的分割问题,也是一个有意义的问题,可以扩大其应用范围。为了探索 SAM 在更复杂场景中的泛化能力,Ji 等人 [22] 在三种场景,即伪装动物、工业缺陷和医学病变中,定量地将其与尖端模型进行比较。他们在三个伪装物体分割(COS)数据集上进行实验,即拥有 250 个样本的 CAMO [116],拥有 2026 个样本的 COD10K [117],以及拥有 4121 个样本的 NC4K [118]。并将其与基于 Transformer 的模型 CamoFormer-P/S [119] 和 HitNet [120] 进行比较。结果表明,SAM 在隐蔽场景中的技巧不足,并指出,潜在的解决方案可能依赖于在特定领域的先验知识的支持。在 [29] 中也可以得出同样的结论,作者在上述同样的三个数据集上,将 SAM 与 22 个最先进的方法在伪装物体检测上进行比较。
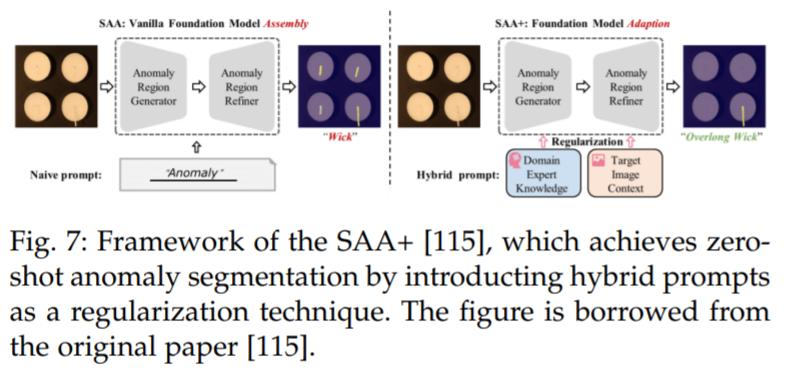
Cao 等人 [115] 提出了一个新的框架,名为 Segment Any Anomaly + (SAA+),用于零样本异常分割,如图 7 所示。该框架利用混合提示规范化来提高现代基础模型的适应性,从而无需领域特定的微调就能进行更精确的异常分割。作者在四个异常分割基准上进行了详细的实验,即 VisA [122],MVTecAD [123],MTD [124] 和 KSDD2 [125],并取得了最先进的性能。
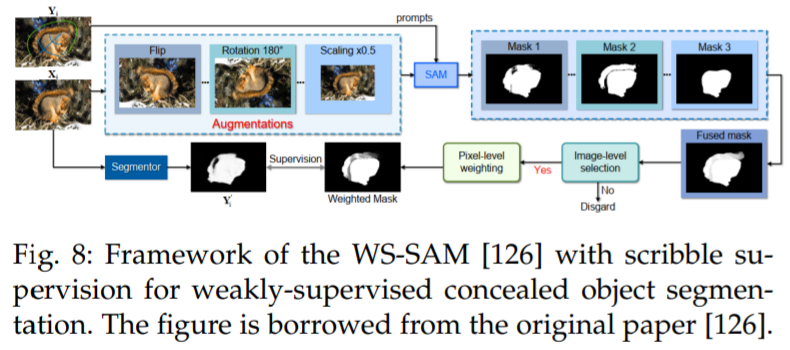
He 等人 [126] 提出了第一种方法(WSSAM),利用 SAM 进行弱监督隐蔽物体分割,解决了使用稀疏注释数据分割与周围环境融为一体的物体的挑战(参见图 8)。所提出的 WSSAM 包括基于 SAM 的伪标记和多尺度特征分组,以提高模型学习和区分隐蔽物体和背景。作者发现,仅使用 scribble 监督 [127],SAM 就可以生成足够好的分割掩码,以训练分割器。
更多模型和应用:视觉及其他
视觉相关
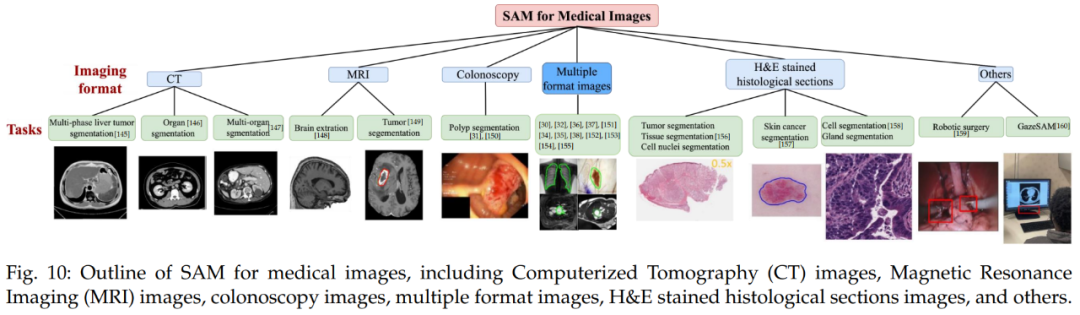
首先是医疗成像。医疗图像分割的目的是展示相应组织的解剖或病理结构,可以用于计算机辅助诊断和智能临床手术。
下图 10 为医疗图像 SAM 概览,包括了计算机断层扫描(CT)图像、磁共振成像(MRI)图像、结肠镜检查图像、多格式图像、H&E 染色组织切片图像等。
其次是视频。在计算机视觉领域,视频目标跟踪(VOT)和视频分割被认为是至关重要且不可或缺的任务。VOT 涉及在视频帧中定位特定目标,然后在整个视频的其余部分对其进行跟踪。因此,VOT 具有各种实际应用,例如监视和机器人技术。
SAM 在 VOT 领域做出了杰出贡献。参考文献 [46] 中引入了跟踪一切模型(Track Anything Model, TAM),高效地在视频中实现了出色的交互式跟踪和分割。下图 11 为 TAM pipeline。
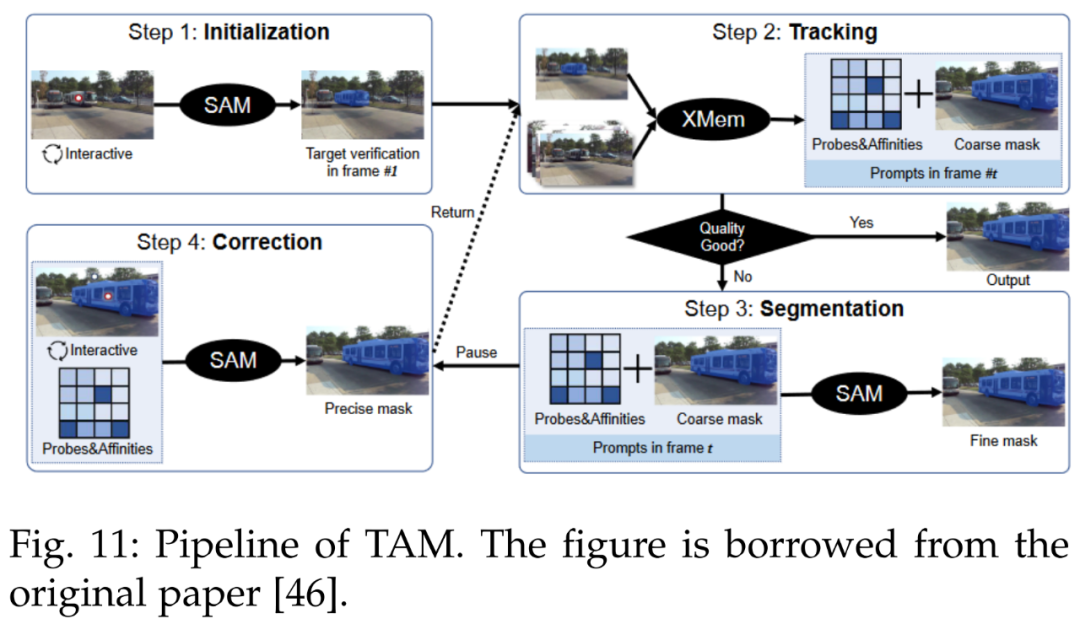
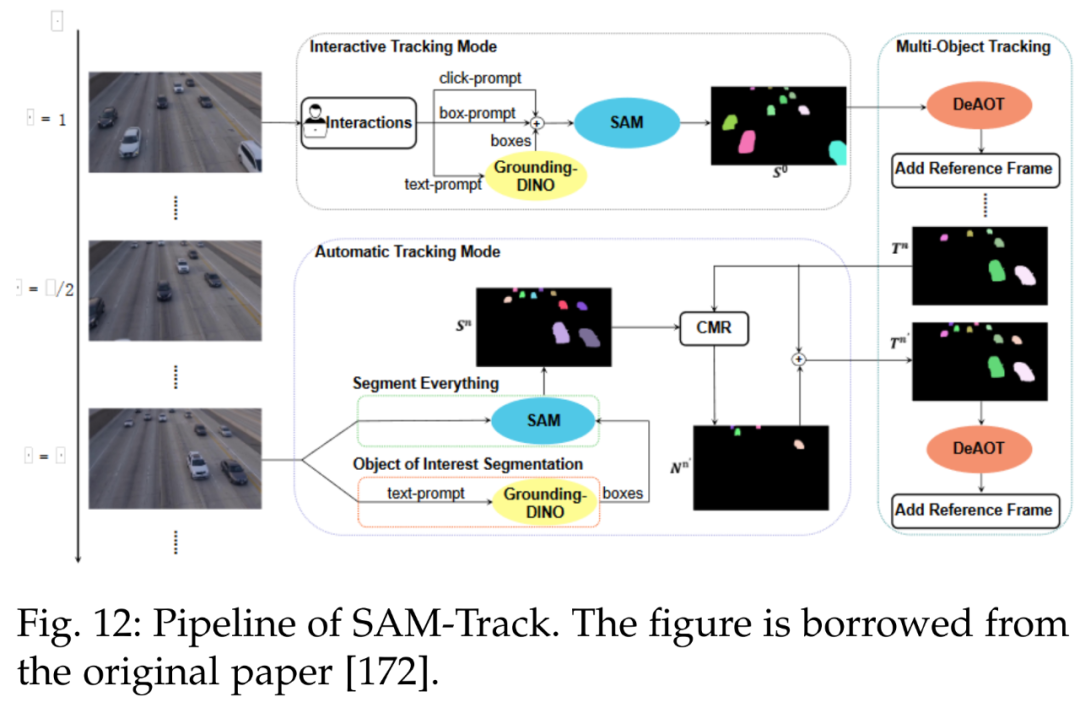
此外另一个跟踪模型为 SAMTrack,详见参考文献 [172]。SAMTrack 是一种视频分割框架,可通过交互和自动的方法实现目标跟踪和分割。下图 12 为 SAMTrack 的 pipeline。
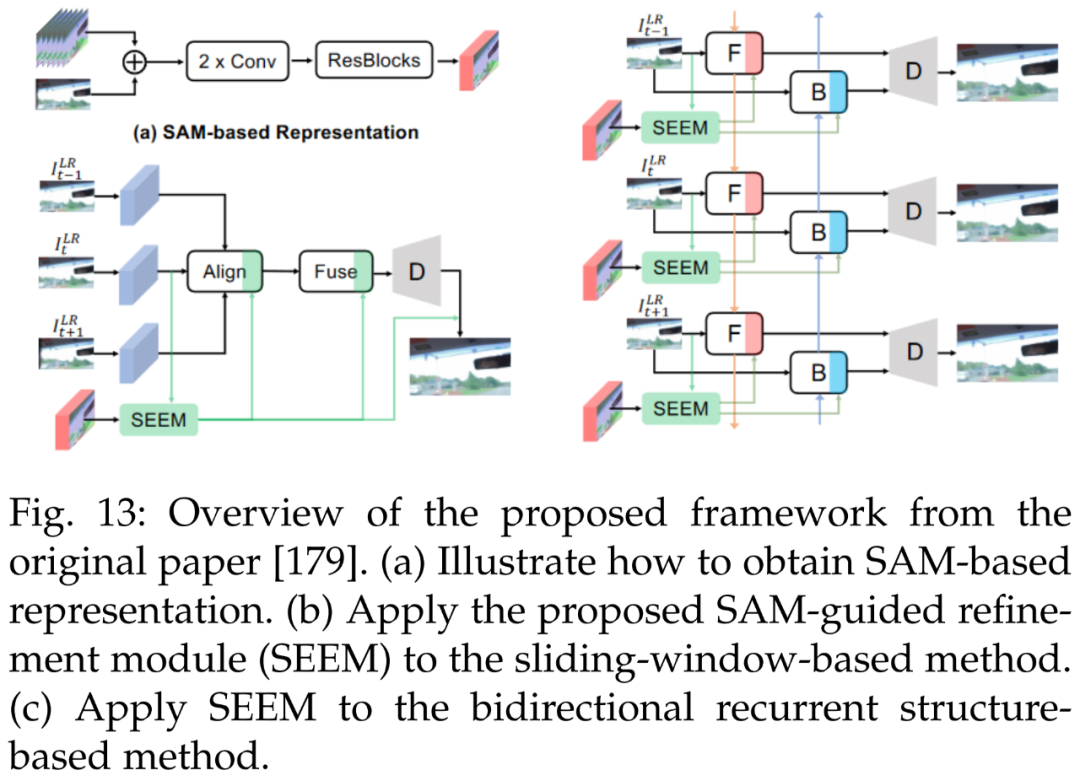
下图 13 为一个轻量级 SAM 指导的优化模块(SAM-guided refinement module, SEEM),用于提升现有方法的性能。
接着是数据注释。SAMText [180] 是一种用于视频中场景文本掩码注释的可扩展 pipeline。它利用 SAM 在大型数据集 SAMText-9M 上生成掩码注释,该数据集包含超过 2,400 个视频片段和超过 900 万个掩码注释。
此外参考文献 [143] 利用现有遥感目标检测数据集和以数据为中心的机器学习模型 SAM,构建了一个大规模遥感图像分割数据集 SAMRS,包含目标分类、位置和实例信息,可以用于语义分割、实例分割和目标检测研究。
视觉之外
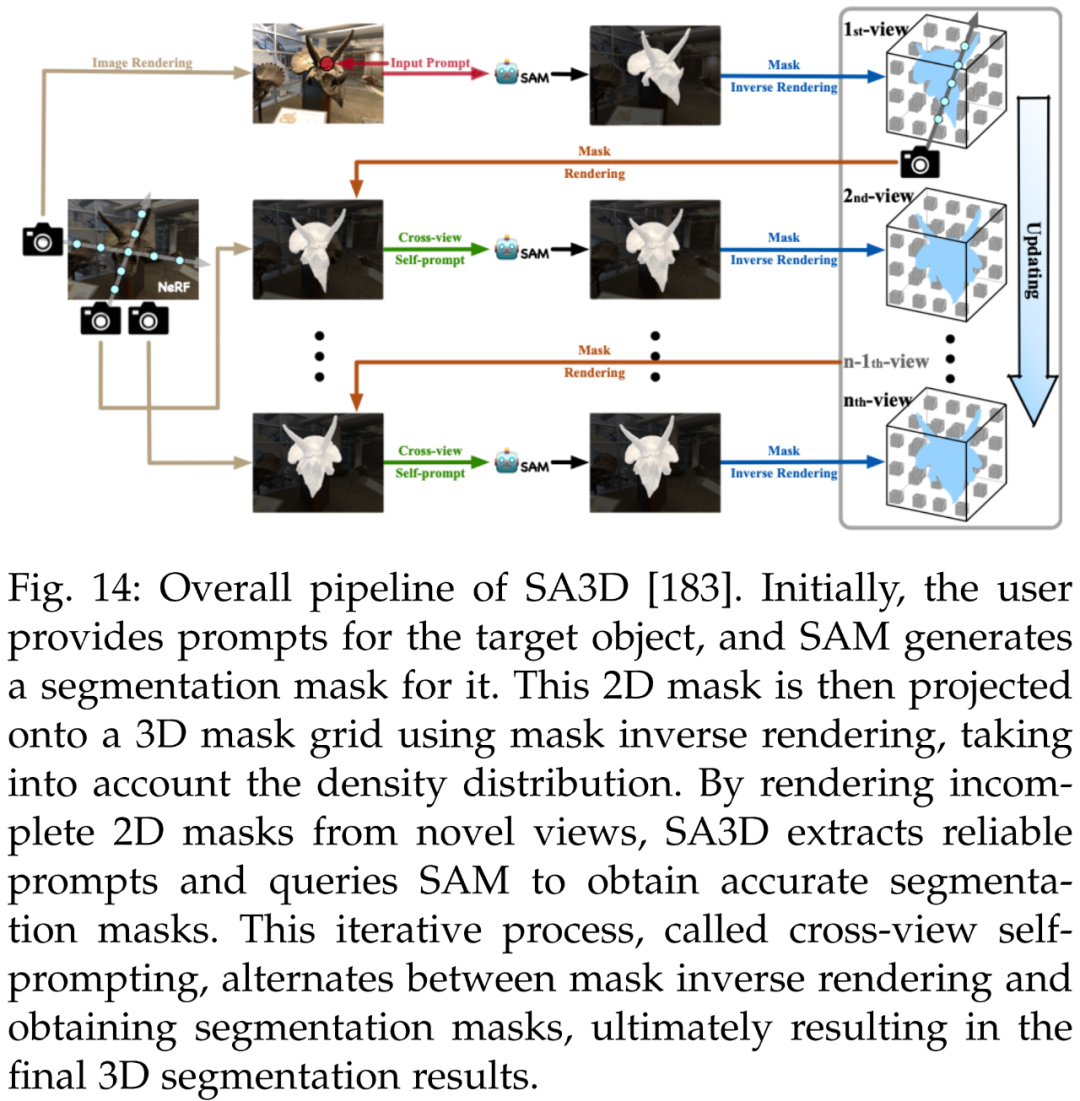
首先是 3D 重建。除了实现细粒度的 3D 分割,SA3D [183] 可以用于 3D 重建。利用 3D 掩码网格,研究者可以确定物体在 3D 中的占用空间,并以各种方式重建。下图 14 为 SA3D 的整体 pipeline。
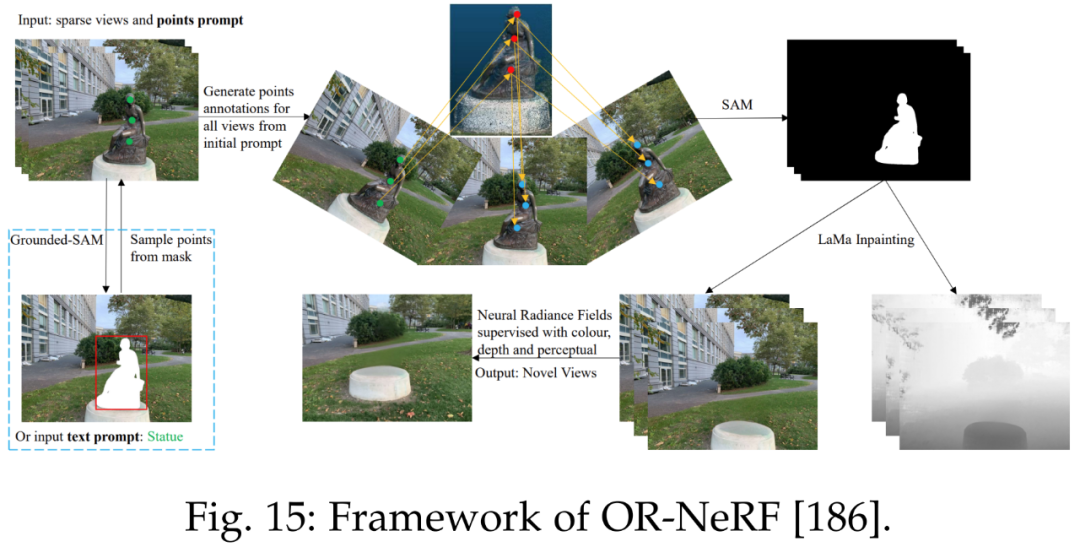
参考文献 [186] 提出了一种新的对象移除 pipeline ORNeRF,它使用单个视图上的点或文本 prompt 从 3D 场景中移除对象。通过使用点投影策略将用户注释快速传播给所有视图,该方法使用比以往工作更少的时间实现了更好的性能。下图 15 为 ORNeRF 的框架。
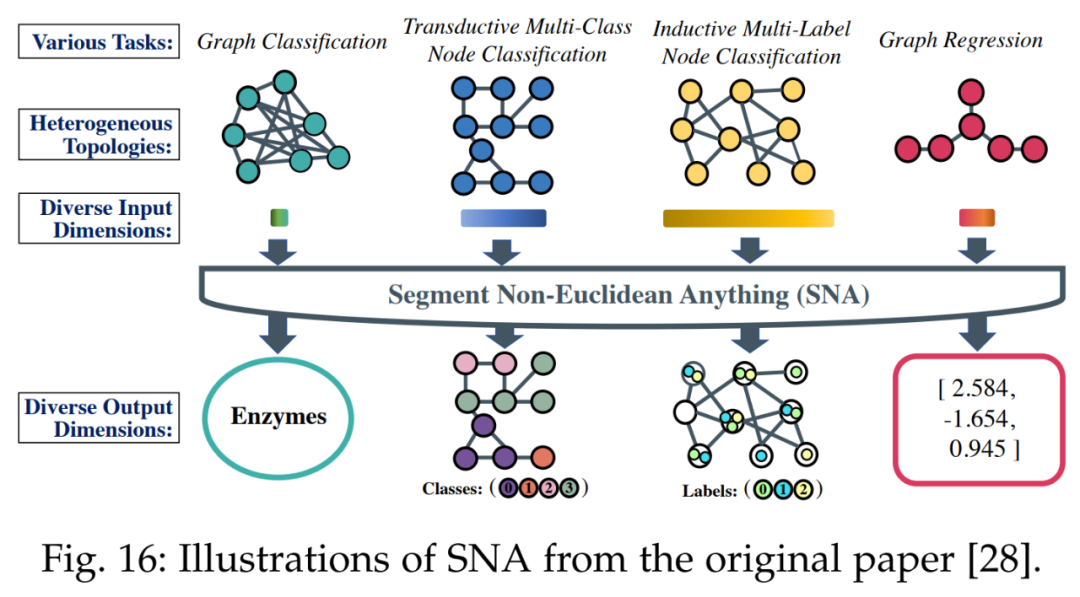
其次是非欧式域。为了为不同任务处理不同特征维度,下图 16 中所示的 SNA 方法引入了一个专门的可精简图卷积层。该层可以根据输入的特征维度进行通道的动态激活或停用。
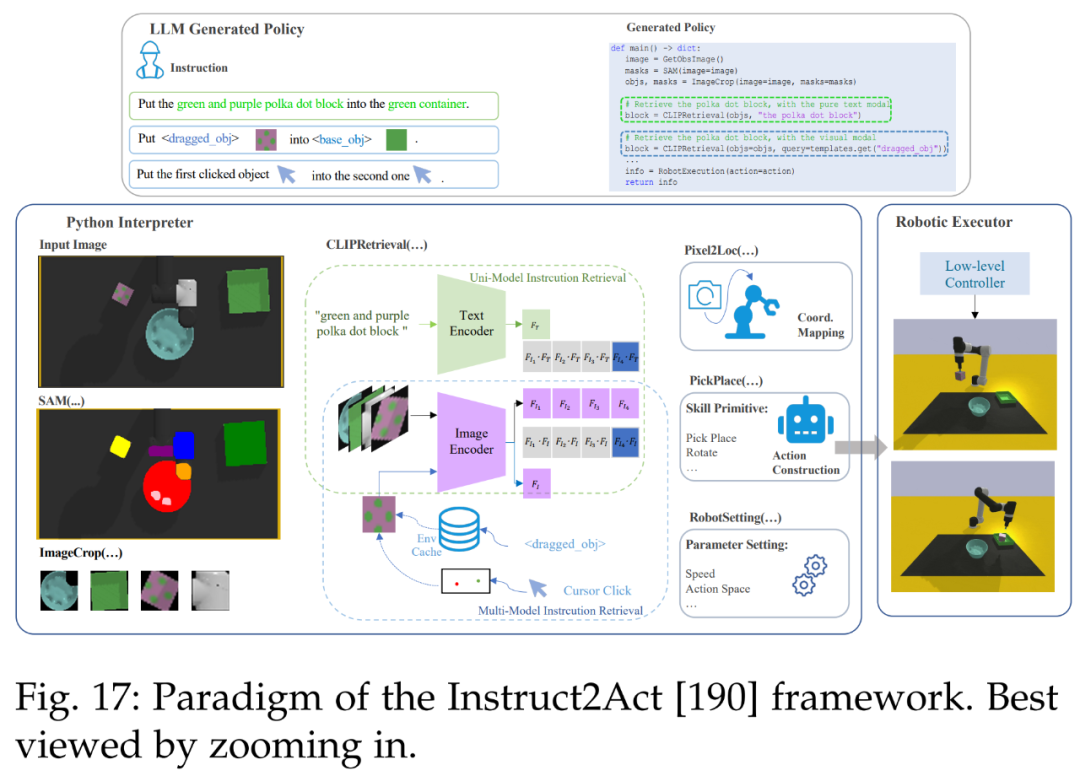
然后是机器人。下图 17 展示了 Instruct2Act [190] 的整体流程。在感知部分,预定义的 API 用于访问多个基础模型。SAM [20] 准确定位候选对象,CLIP [13] 对它们进行分类。该框架利用基础模型的专业知识和机器人能力将复杂的高级指令转换为精确的策略代码。
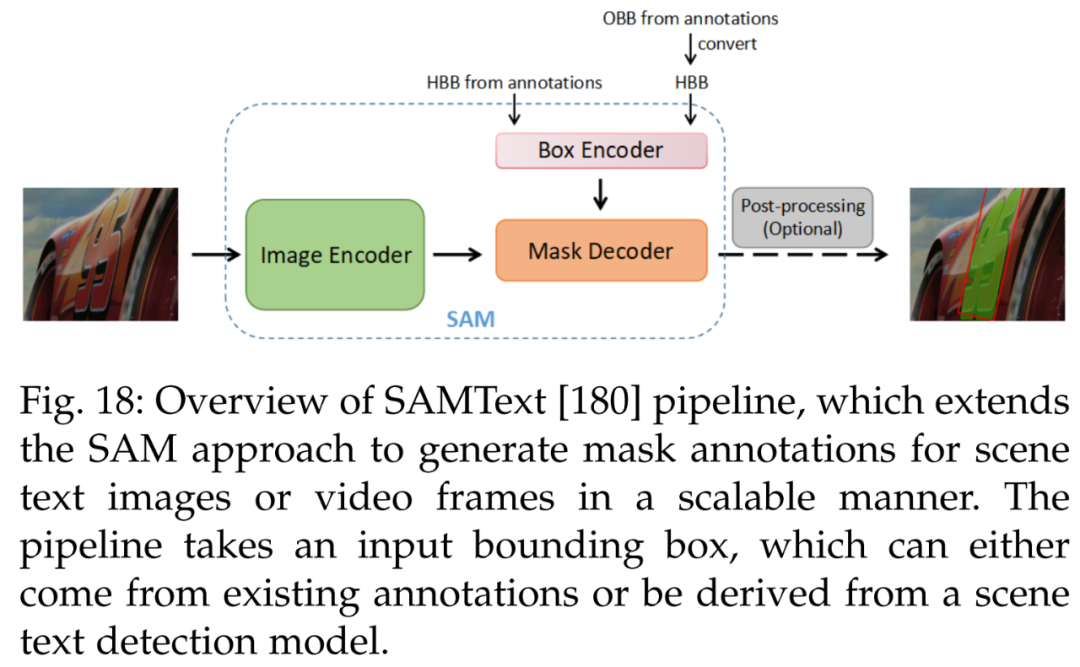
接着是视频文本定位。下图 18 展示了一种为视频文本定位任务生成掩码注释的可扩展高效解决方案 SAMText [180]。通过将 SAM 模型应用于边界框注释,它可以为大规模视频文本数据集生成掩码注释。
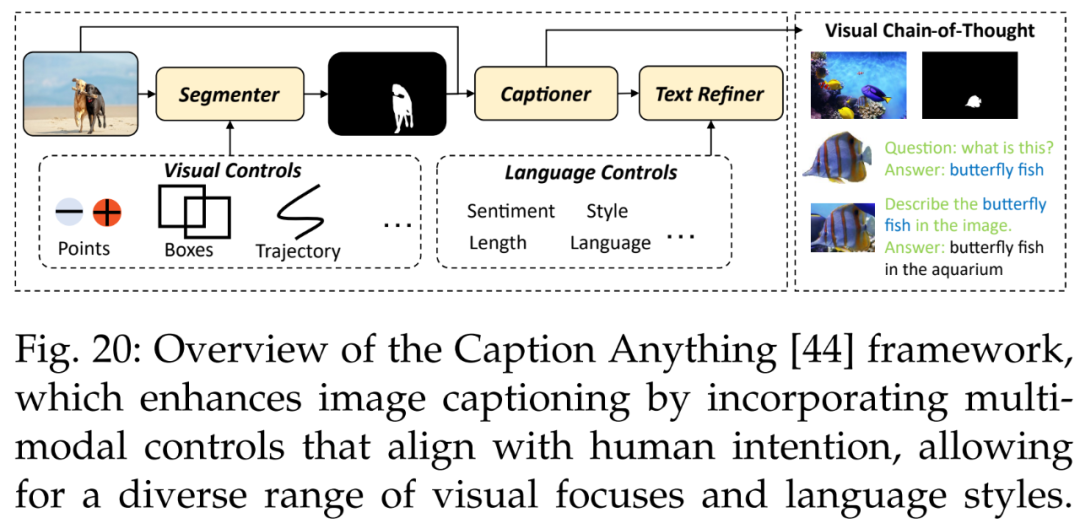
此外还有图像字幕。Wang et al. [44] 提出了一种用于可控图像字幕的方法 Caption Anything(CAT),如下图 20 所示,CAT 的框架将多模态控制引入图像字幕,呈现符合人类意图的各种视觉焦点和语言风格。
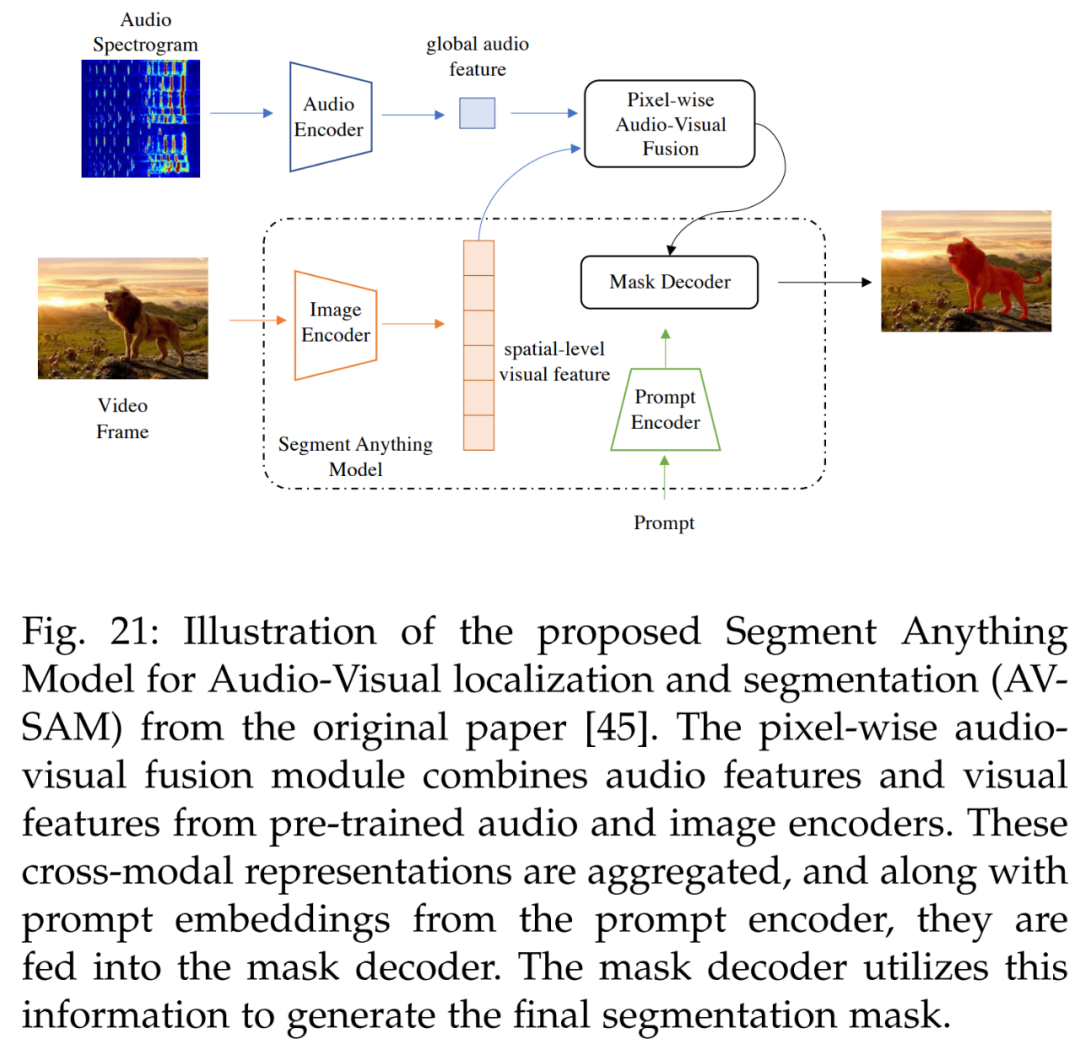
视听也有涉及。参考文献 [45] 的视听定位和分割方法用于学习可以对齐音频和视觉信息的跨模态表示,具体如下图 21 所示。AV-SAM 利用预训练音频编码器和图像编码器中跨音频和视觉特征的像素级视听融合来聚合跨模态表示。然后将聚合的跨模态特征输入 prompt 编码器和掩码解码器,生成最终的视听分割掩码。
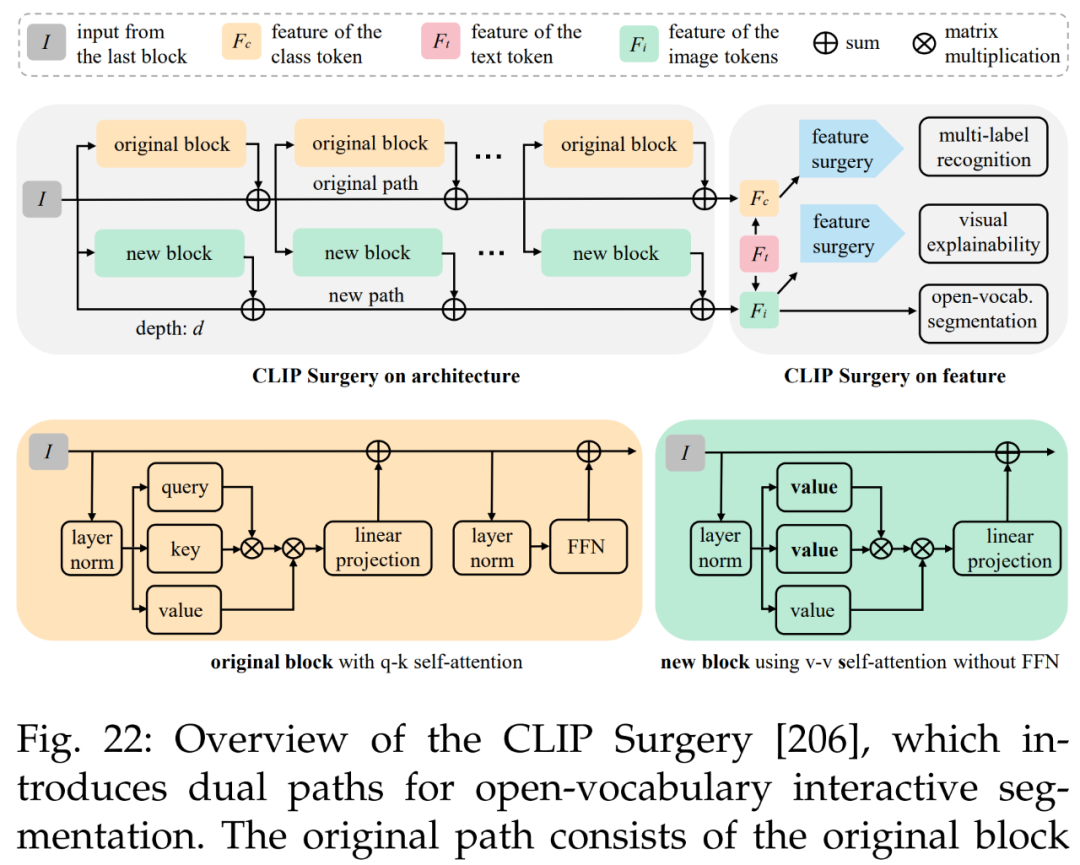
最后是多模态视觉和开放词汇交互分割。参考文献 [44] 的方法如下图 22 所示,旨在使用仅文本输入的 CLIP 策略来完全取代手动点(manual point)。这种方法提供来自文本输入的像素级结果,可以很容易地转换为 SAM 模型的点 prompt。
结语
本文首次全面回顾了计算机视觉及其他领域 SAM 基础模型的研究进展。首先总结了基础模型(大语言模型、大型视觉模型和多模态大模型)的发展历史以及 SAM 的基本术语,并着重于 SAM 在各种任务和数据类型中的应用,总结和比较了 SAM 的并行工作及其后续工作。研究者还讨论 SAM 在广泛的图像处理应用中的巨大潜力,包括软件场景、真实世界场景和复杂场景。
此外,研究者分析和总结了 SAM 在各种应用程序中的优点和局限性。这些观察结果可以为未来开发更强大的基础模型和进一步提升 SAM 的稳健性和泛化性提供一些洞见。文章最后总结了 SAM 在视觉和其他领域的大量其他令人惊叹的应用。
审核编辑 :李倩
-
图像处理
+关注
关注
27文章
1307浏览量
56944 -
模型
+关注
关注
1文章
3374浏览量
49326 -
SAM
+关注
关注
0文章
113浏览量
33601
原文标题:第一篇综述!分割一切模型(SAM)的全面调研
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

NAS:一篇完整讲述AutoML整个流程的综述
AI分割一切——用OpenVINO™加速Meta SAM大模型

SAM 到底是什么

分割一切?Segment Anything量化加速实战

中科院提出FastSAM快速分割一切模型!比Meta原版提速50倍!
基于 Transformer 的分割与检测方法

一种新的分割模型Stable-SAM






 工商网监
工商网监
评论