 Layerscape LX2160A:小体积大算力
Layerscape LX2160A:小体积大算力

与大多数其他Layerscape处理器一样,LX2160A处理器面向无头嵌入式系统。它不适用于拥有强大CPU和流畅用户界面的计算机。诚然,它的大多数指标得分都很高,但最突出的是惊人的网络加速和I/O性能。它适用于无线传输卡和工业控制器等设计。为何要把LX2芯片连接到GPU上呢?
答案是,LX2对于计算机来说足够强大,但它是为高要求的嵌入式应用而设计。LX2擅长利用16个CPU进行通用计算。Cortex®-A72 CPU由Arm®授权,可用于其他Layerscape处理器和其他公司的ASIC。例如特斯拉采用12核CPU的“FSD计算机”以及亚马逊网络服务公司采用16核CPU的Graviton(与LX2一样)。我们的分析显示,16核LX2的性能与竞争对手架构(通常针对PC和服务器)的16线程/8核处理器相当。
需要这种性能的应用范围很广。其中包括Layerscape及其Power Architecture®前身长期瞄准的通信设备类型中的数据平面功能:基站中的传输卡、数据中心服务器的智能网卡以及路由器的第2层/第3层加速度传感器。这些应用可采用LX2的众多内核以及每个Layerscape处理器内置的连接和加密加速功能。
恩智浦在通信设备领域也有长期目标,特别是利用通信设备的高单线程性能方面。在这一方面,LX2也大放异彩——但在这种情况下,是由于LX2的CPU速度很快,可以穿透软件层。例如,网络功能虚拟化(NFV)将软件封装在以前运行在独立物理硬件上的虚拟机中。虽然虚拟化起源于服务器和工作站,但它在恩智浦处理器上可高效运行,这要归功于恩智浦的CPU内核和SoC机箱的虚拟化功能。自2008年QorIQ P系列问世以来,我们一直致力于这类组件的设计。
尽管如此,在典型的NFV系统中,各种因素共同消耗着CPU时钟周期。旧的物理系统是带精益系统软件的专用硬件。而虚拟化网络功能(VNF)是在类似计算机的通用硬件和系统软件上执行的,本质上效率较低。此外,这些平台还托管了多个VNF,它们通过虚拟交换机(软件上部署的以太网交换机)相互通信。数据平面开发工具套件(DPDK)等库减轻了操作系统开销,但依赖高速内核来运行并完成任务。Lx2拥有所需的内核,而恩智浦投资优化网络和虚拟化软件,如DPDK和Linux内核虚拟机(KVM)。恩智浦还投资容器化——成本更低的虚拟化替代方案。
然而,最重要的软件是Linux。是的,恩智浦仍然与Wind River等嵌入式操作系统专家合作。对于希望获得开源嵌入式体验的客户,恩智浦提供了Yocto嵌入式Linux开发环境。但是,许多开发人员(尤其但不限于具有IT背景的开发人员)更喜欢在计算机上使用类似的环境。恩智浦的Layerscape开发套件(LSDK)很受欢迎。它是一个参考集成,示范了客户如何将众多组件融合到系统映像或个性化Linux发行版中。
为了构建LSDK,恩智浦首先修改大量开源启动加载程序、内核、库和工具,以与特定器件(如LX2)配合使用。我们将这些修改作为补丁,提交给相关的开源项目。一旦上传,LSDK组件就可从kernel.org和GitHub等公共存储库下载。恩智浦会不时更新这些补丁,定期发布新版本,并为最新的两个长期支持版(LTS)内核提供支持。开发人员可以选择自己集成所需的组件。无需下载大量ISO文件或tarball。
LSDK参考集成非常便捷,包含了一个用户空间,其中包含从备受欢迎的Ubuntu发行版派生的文件和文件夹层次结构。这为开发人员提供了熟悉的操作环境。重要的是,它还提供了对大量二进制软件库的轻松访问。这些应用运行顺畅,因为LX2和其他Layerscape处理器使用标准Arm内核,最大限度地提高了兼容性。其他受欢迎的发行版也支持64位Arm处理器,使用LSDK打造自己发行版的开发人员可以调整这些用户空间,而不是我们提供的Ubuntu示例。图1是LX2上Linux桌面的截屏。
图1 Layerscape LX2160A处理器上运行的Linux桌面的截屏
LX2的性能和软件生态合作体系正将其推向通信以外的市场。高端辅助驾驶自动化系统(ADAS)中的服务器硬件通常会解决这类问题,即通过人工智能(AI)硬件集成从相机、激光雷达和其他传感器提取的信息的问题。这种硬件体积庞大、价格昂贵且容易发热。而LX2是个极具吸引力的替代方案,它具有相似的性能和更好的集成性,同时厂家在满足汽车制造商对长期供货计划、功能安全和恶劣环境耐受性的需求方面有着良好口碑。恩智浦与全球各大公司合作开展ADAS和自动驾驶工作。同样,客户也在工业机器视觉、航空航天和数控切割机中使用LX2。
即使在通信中,LX2也可以处理在通用处理器上未运行的工作负载。例如,5G移动通信标准支持各种功能拆分,包括在称为分布式单元(DU)的系统中而非传统宏基站的信道卡上实现上层PHY功能,包括信道编码、位操作、信道估计、均衡和预编码,可以在通用处理器上的软件中运行。然而,该处理器必须能够处理大量数据。恩智浦的分析表明,LX2可以胜任这项任务。
出于类似的原因,LX2甚至正进入数据中心,也就是终极计算设备200W+服务器芯片的大本营。LX2并没有取代服务器,而是通过插入服务器的网络接口卡与其进行互补。LX2将网络任务从那些昂贵且耗电的服务器内核中分流。Xilinx开发的FPGA + LX2 NIC组合就是一个例子。
要了解LX2如何提供如此具有竞争力的性能,我们先深入了解一下一般计算工作负载上影响其性能的一些因素。它有两个受ECC保护的64位DDR4内存接口,如图2所示。虽然这比服务器处理器少,但LX2的DDR4接口运行速度高达3200 GT/s,比市场上的其他处理器快约50%。因此不仅可以确保良好的内存吞吐量,还能降低成本(与采用的宽DDR端口较少有关)。
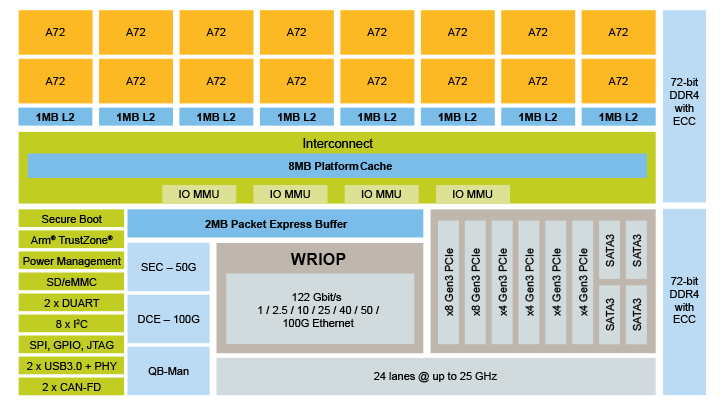
图2 LX2160A处理器结构框图
这得益于8MB的平台高速缓存,高速缓存缓冲CPU内核访问、网络加速度传感器和I/O控制器的片外内存。片上还集成了2MB数据包快速缓冲区,可最大限度地减少内置以太网交换机对DRAM的访问。每对CPU旁边都有1MB的二级缓存。这与Graviton的每核数量相同,Graviton没有L3缓存,比许多计算处理器都要多。与片外内存相比,高速缓存的访问速度更快,因此对于向CPU提供指令和数据来说,高速缓存必不可少。
如上所述,LX2使用Arm Cortex-A72 CPU。这些CPU属于该公司的“大”A系列内核。有些Layerscape使用“小”Arm Cortex-A53 CPU。这两种CPU相互兼容,可实现相同版本的Arm 64位指令集。在相同的时钟频率下,A72的速度大约是原来的两倍。它每个周期可解码三条指令,并且可以在八条管道的任意一条无序执行。A53一次只解码和执行两条指令,可以降低功耗和成本。A72以性能为导向,还拥有更快的浮点单元和更广泛的Neon SIMD执行单元,增强了其分割数学密集型计算工作负载(例如无线DU中的上层PHY函数)的能力。A72 的每个Neon单元(共两个)的每个周期都可以进行两个复杂的16位乘积累加运算。
总之,恩智浦Layerscape LX2160A处理器在计算方面表现出色。我们与一位希望更换其嵌入式系统PC处理器的客户取得了联系。他们想要类似的性能,但不想放弃他们的软件生态合作体系。LX2正好符合要求。工程师将得到一张标准GPU卡,插入系统的PCIe插槽。因为有开源社区和LSDK,软件安装轻而易举。LX2专为解决嵌入式系统的环境挑战而设计,并针对通信应用进行了优化,在计算工作负载方面也大放异彩。或许恩智浦已经找到了新的宣传口号:Layerscape LX2160A:小体积大算力。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
20329浏览量
254850 -
cpu
+关注
关注
68文章
11326浏览量
225870 -
gpu
+关注
关注
28文章
5271浏览量
136060
发布评论请先 登录



评论