 STM32采集传感器数据通过冒泡排序取稳定值
STM32采集传感器数据通过冒泡排序取稳定值
一、前言
在物联网、单片机开发中,经常需要采集各种传感器的数据。比如:温度、湿度、MQ2、MQ3、MQ4等等传感器数据。这些数据采集过程中可能有波动,偶尔不稳定,为了得到稳定的值,我们可以对数据多次采集,进行排序,去掉最大和最小的值,然后取平均值返回。
二、排序算法
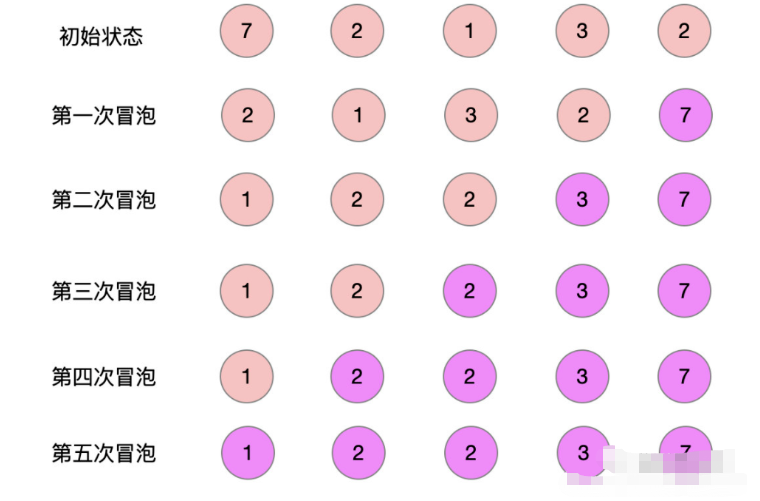
【1】冒泡排序
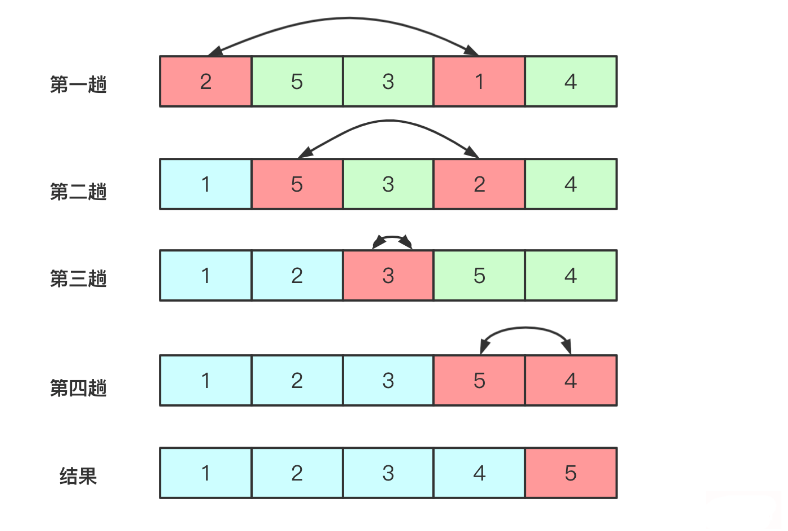
冒泡排序(Bubble Sort)是一种简单的排序算法,也是最基础、最容易理解的一种排序算法。它会遍历要排序的数组,依次比较相邻两个元素的大小,如果前一个元素比后一个元素大,就交换这两个元素的位置。
冒泡排序的过程如下:
- 从数组的第一个元素开始,依次比较相邻的两个元素,如果前一个元素比后一个元素大,则交换这两个元素的位置。
- 继续比较相邻的元素,直到数组的最后一个元素。
- 重复执行步骤1和步骤2,直到整个数组都按照从小到大的顺序排列好。
冒泡排序的时间复杂度是O(N^2),其中N是数组中元素的数量。在实际应用中,由于其时间复杂度较高,冒泡排序很少被用于大规模数据的排序,但它仍然是一种优秀的教学工具,因为它容易理解和实现,并且可以帮助初学者理解排序算法的基本思想。
以下是C语言代码的实现,封装为名为calculateAverage的函数。
#define ARRAY_SIZE 20
// 冒泡排序算法函数
void bubbleSort(int arr[], int n) {
for(int i = 0; i < n-1; i++) {
for(int j = 0; j < n-i-1; j++) {
if(arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
// 计算平均值函数,去除最大值和最小值
int calculateAverage() {
int arr[ARRAY_SIZE];
// 连续读取20次数据
for(int i = 0; i < ARRAY_SIZE; i++) {
arr[i] = ReadADC();
}
// 对数组进行排序
bubbleSort(arr, ARRAY_SIZE);
// 去掉最大值和最小值
int sum = 0;
for(int i = 1; i < ARRAY_SIZE-1; i++) {
sum += arr[i];
}
// 计算平均值并返回
return sum / (ARRAY_SIZE-2);
}
在函数中,首先定义了一个常量ARRAY_SIZE表示需要读取的数据的数量。然后,使用一个循环读取20次数据,并将它们存储到一个数组中。接着,用冒泡排序算法对数组进行排序。在排序完成后,计算数组中除去最大值和最小值的元素之和,并计算平均值。最后,返回计算得到的平均值。
【2】插入排序
插入排序(Insertion Sort)是一种简单直观的排序算法,它的基本思想是将一个元素插入到已排序好的序列中的适当位置,使得插入后仍然有序。
插入排序的过程如下:
- 假设第一个元素已经是排好序的序列,从第二个元素开始,依次将每个元素插入到已经排好序的序列中。
- 每次从未排序的部分中取出一个元素,与已排序的序列中的元素从后向前依次比较,找到插入的位置,即找到一个比当前元素小的值或者已经到了开头位置。
- 将当前元素插入到已排序序列的合适位置上,重新调整已排序的序列,继续对未排序的序列进行排序。
- 重复执行步骤2和步骤3,直到整个数组都按照从小到大的顺序排列好。
插入排序的时间复杂度是O(N^2),其中N是数组中元素的数量。在实际应用中,插入排序通常适用于处理小规模数据或者已经接近有序的数据,因为此时插入排序的效率高于其他排序算法。
以下是C语言代码的实现,封装为名为calculateAverage的函数。
#define ARRAY_SIZE 20
// 插入排序算法函数
void insertionSort(int arr[], int n) {
for(int i = 1; i < n; i++) {
int key = arr[i];
int j = i-1;
while(j >= 0 && arr[j] > key) {
arr[j+1] = arr[j];
j--;
}
arr[j+1] = key;
}
}
// 计算平均值函数,去除最大值和最小值
int calculateAverage() {
int arr[ARRAY_SIZE];
// 连续读取20次数据
for(int i = 0; i < ARRAY_SIZE; i++) {
arr[i] = ReadADC();
}
// 对数组进行排序
insertionSort(arr, ARRAY_SIZE);
// 去掉最大值和最小值
int sum = 0;
for(int i = 1; i < ARRAY_SIZE-1; i++) {
sum += arr[i];
}
// 计算平均值并返回
return sum / (ARRAY_SIZE-2);
}
在函数中,首先定义了一个常量ARRAY_SIZE表示需要读取的数据的数量。然后,使用一个循环读取20次数据,并将它们存储到一个数组中。接着,用插入排序算法对数组进行排序。在排序完成后,计算数组中除去最大值和最小值的元素之和,并计算平均值。最后,返回计算得到的平均值。
【3】希尔排序
希尔排序(Shell Sort)是一种由Donald Shell在1959年发明的排序算法,它是插入排序的一种变体,旨在减少排序中元素的移动次数,从而使算法更快。希尔排序的基本思想是把数组中相距某个“增量”的元素组成一个子序列,对每个子序列进行插入排序,然后逐步缩小增量,重复进行上述操作,直到增量为1,最后再对整个数组进行一次插入排序。
希尔排序的过程如下:
- 选择一个增量序列,将待排序的数组按照这个增量序列分成若干组(子序列)。通常,在第一次排序时,增量取数组长度的一半,以后每次将增量减半,直到增量为1。
- 对每个子序列进行插入排序,即将每个子序列中的元素按照递增的顺序插入到已排序好的序列中。
- 重复执行步骤2,改变增量,直到增量为1。
- 最后再对整个数组进行插入排序。
希尔排序的时间复杂度与所选取的增量序列有关。最坏情况下的时间复杂度为O(N^2),其中N是数组中元素的数量。但在大多数情况下,希尔排序的时间复杂度优于O(N^2),可以达到O(N log N)的级别。希尔排序的空间复杂度为O(1),因为它在排序过程中只需要常数个额外的存储空间。
以下是C语言代码实现,封装为名为calculateAverage的函数。
#define ARRAY_SIZE 20
// 希尔排序算法函数
void shellSort(int arr[], int n) {
for(int gap = n/2; gap > 0; gap /= 2) {
for(int i = gap; i < n; i++) {
int temp = arr[i];
int j;
for(j = i; j >= gap && arr[j-gap] > temp; j -= gap) {
arr[j] = arr[j-gap];
}
arr[j] = temp;
}
}
}
// 计算平均值函数,去除最大值和最小值
int calculateAverage() {
int arr[ARRAY_SIZE];
// 连续读取20次数据
for(int i = 0; i < ARRAY_SIZE; i++) {
arr[i] = ReadADC();
}
// 对数组进行排序
shellSort(arr, ARRAY_SIZE);
// 去掉最大值和最小值
int sum = 0;
for(int i = 1; i < ARRAY_SIZE-1; i++) {
sum += arr[i];
}
// 计算平均值并返回
return sum / (ARRAY_SIZE-2);
}
在函数中,首先定义了一个常量ARRAY_SIZE表示需要读取的数据的数量。然后,使用一个循环读取20次数据,并将它们存储到一个数组中。接着,用希尔排序算法对数组进行排序。在排序完成后,计算数组中除去最大值和最小值的元素之和,并计算平均值。最后,返回计算得到的平均值。
审核编辑:汤梓红
-
传感器
+关注
关注
2550文章
51042浏览量
753105 -
单片机
+关注
关注
6035文章
44554浏览量
634702 -
数据
+关注
关注
8文章
7006浏览量
88945 -
物联网
+关注
关注
2909文章
44571浏览量
372838 -
STM32
+关注
关注
2270文章
10896浏览量
355766
发布评论请先 登录
相关推荐
冒泡排序
常用排序法之一 ——冒泡排序法和选择排序法
嵌入式stm32实用的排序算法 - 交换排序
基于STM32单片机水质检测PH值检测采集传感器模块设计资料分享
冒泡排序的基本思想
php版冒泡排序是如何实现的?

怎样运用Java实现冒泡排序和Arrays排序出来
jwt冒泡排序的原理





 工商网监
工商网监
评论