 NSDI '23热点论文:可编程、RDMA、数据中心、GPU有哪些新动态?
NSDI '23热点论文:可编程、RDMA、数据中心、GPU有哪些新动态?
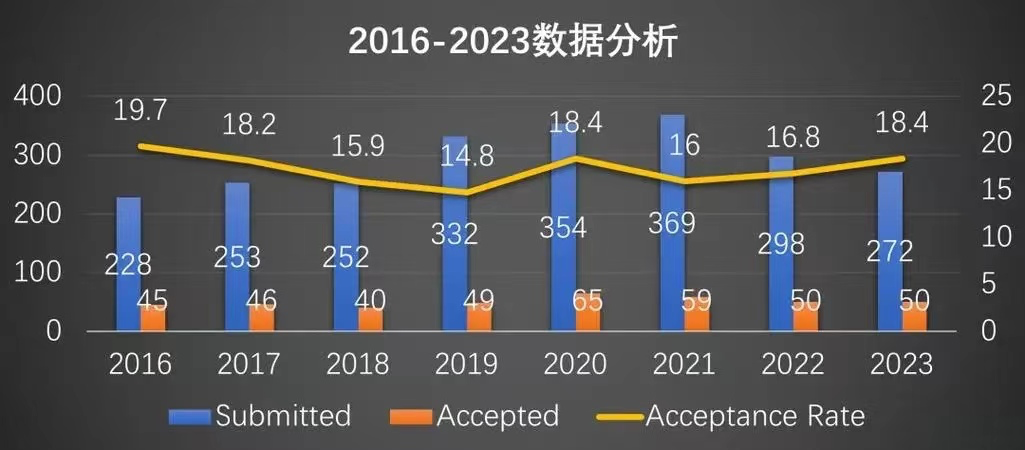 | NSDI 2016-2023论文数据分析,来源:网络NSDI常年录取率非常低,稳定在20%以下,有的年份甚至低于15%。投稿量来看,在早几年中呈现出缓慢上升的趋势,从16年的228到2021年的369篇,一路上升,然后有所下降,2022年和2023年分别为298和272篇。录取量也呈现出缓慢上升的趋势,到2020年的65篇,之后开始下降,至2022的50篇。录取率整体呈现浮动的趋势,但是相对稳定,2023年录取率为18.4%。NSDI重点关注计算机网络,但也覆盖了人工智能、机器学习、计算机视觉、无线和分布式计算等内容,是一个非常全面的会议。本文介绍了NSDI 2023中可编程、RDMA、数据中心、GPU方向的相关论文,文末附NSDI 2023全部论文下载链接。
可编程
标题:A High-Speed Stateful Packet Processing Approach for Tbps Programmable Switches
| NSDI 2016-2023论文数据分析,来源:网络NSDI常年录取率非常低,稳定在20%以下,有的年份甚至低于15%。投稿量来看,在早几年中呈现出缓慢上升的趋势,从16年的228到2021年的369篇,一路上升,然后有所下降,2022年和2023年分别为298和272篇。录取量也呈现出缓慢上升的趋势,到2020年的65篇,之后开始下降,至2022的50篇。录取率整体呈现浮动的趋势,但是相对稳定,2023年录取率为18.4%。NSDI重点关注计算机网络,但也覆盖了人工智能、机器学习、计算机视觉、无线和分布式计算等内容,是一个非常全面的会议。本文介绍了NSDI 2023中可编程、RDMA、数据中心、GPU方向的相关论文,文末附NSDI 2023全部论文下载链接。
可编程
标题:A High-Speed Stateful Packet Processing Approach for Tbps Programmable Switches作者:Mariano Scazzariello and Tommaso Caiazzi, KTH Royal Institute of Technology and Roma Tre University; Hamid Ghasemirahni, KTH Royal Institute of Technology; Tom Barbette, UCLouvain; Dejan Kostić and Marco Chiesa, KTH Royal Institute of Technology
>摘要高速 ASIC 交换机有望在高速数据平面中直接卸载复杂的数据包处理管道。然而,当今各种各样的数据包处理管道,包括有状态网络功能和数据包调度程序,都需要以编程的方式在短时间内存储一些(或所有)数据包。而如今的高速 ASIC 交换机缺少这种可编程缓冲功能。在这项工作中,我们提出了一种扩展可编程交换机系统——RIBOSOME。它具有外部存储器(用于存储数据包)和外部通用数据包处理设备(用于执行有状态操作),如 CPU 或 FPGA。由于当今的数据包处理设备受到网络接口速度的限制,RIBOSOME 只将相关数据比特传输到这些设备。RIBOSOME 利用直接连接的服务器的空闲带宽,通过RDMA存储传入的有效负载。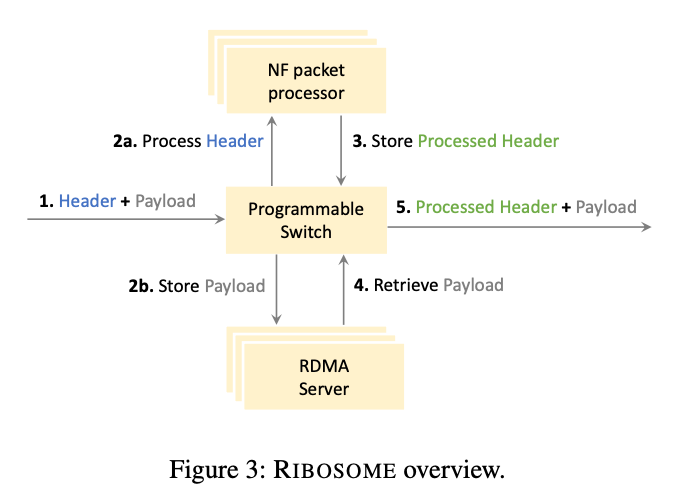 标题:ExoPlane: An Operating System for On-Rack Switch Resource Augmentation
标题:ExoPlane: An Operating System for On-Rack Switch Resource Augmentation作者:Daehyeok Kim, Microsoft and University of Texas at Austin; Vyas Sekar and Srinivasan Seshan, Carnegie Mellon University
>摘要在实际的部署中(例如云和 ISP),在网计算的承诺仍然没有实现,因为交换机的片上资源有限,在可编程交换机上服务并发有状态应用程序仍然具有挑战性。在这项工作中,我们设计并实施了 ExoPlane,这是一种用于机架交换机资源扩充的操作系统,可以支持多个并发应用程序。在设计 ExoPlane 时,我们提出了一个实用的运行时操作模型和状态抽象,以最小的性能和资源开销解决跨多个设备正确管理应用程序状态的挑战。我们对各种 P4 应用程序的评估表明,ExoPlane 可以为应用程序提供低延迟、可扩展吞吐量和快速故障转移,同时以较小的资源开销实现这些,并且无需或只需对应用程序进行少量修改。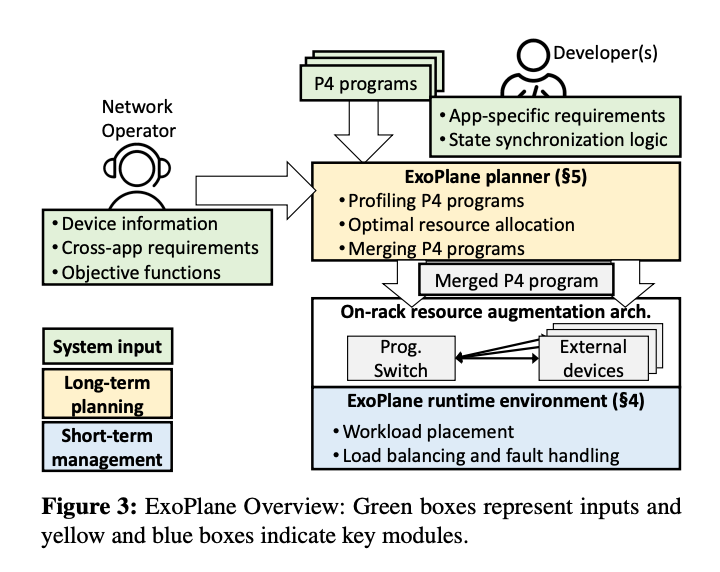 标题:Sketchovsky: Enabling Ensembles of Sketches on Programmable Switches
标题:Sketchovsky: Enabling Ensembles of Sketches on Programmable Switches作者:Hun Namkung, Carnegie Mellon University; Zaoxing Liu, Boston University; Daehyeok Kim, Microsoft Research; Vyas Sekar and Peter Steenkiste, Carnegie Mellon University
>摘要网络运营商需要在可编程交换机上运行各种测量任务,以支持管理决策(例如流量工程或异常检测)。虽然之前的工作已经表明运行单个sketch实例的可行性,但它们在很大程度上忽略了为一组测量任务运行多个sketch实例的问题。因此,现有的工作不足以有效地支持sketch实例的一般集合。在这项工作中,我们介绍了 Sketchovsky 的设计和实现,这是一种新颖的cross-sketch优化和构图框架。我们确定了五个新的cross-sketch优化构建块,以减少关键的交换机硬件资源。我们设计了有效的启发式方法来为任意集合选择和应用这些构建块。为了简化开发人员的工作,Sketchovsky 自动生成要输入到硬件编译器的组合代码。我们的评估表明,Sketchovsky 使多达 18 个sketch实例的集成变得可行,并且可以减少多达 45% 的关键硬件资源。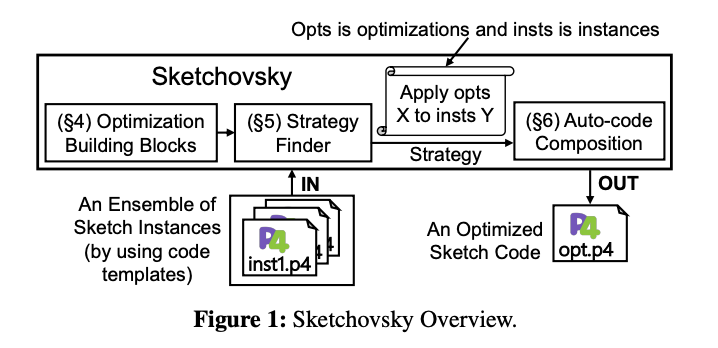 标题:RingLeader: Efficiently Offloading Intra-Server Orchestration to NICs
标题:RingLeader: Efficiently Offloading Intra-Server Orchestration to NICs作者:Jiaxin Lin, Adney Cardoza, Tarannum Khan, and Yeonju Ro, UT Austin; Brent E. Stephens, University of Utah; Hassan Wassel, Google; Aditya Akella, UT Austin
>摘要在数据中心服务器上周密的编排请求,对于满足严格的尾部延迟要求并确保高吞吐量和最佳 CPU 利用率至关重要。编排是多管齐下的,涉及到负载平衡和调度跨CPU资源属于不同服务的请求,以及调整 CPU 分配以适应突发请求。集中式服务器内编排提供了理想的负载平衡性能、调度精度和突发容错 CPU 重新分配。然而,现有的纯软件方法无法实现理想的编排,因为它们的可扩展性有限,并且浪费 CPU 资源。我们主张采用一种新方法,将服务器内编排完全卸载到网卡。我们提出了RingLeader,一个新的可编程网卡,具有新颖的硬件单元,用于软件通知请求负载平衡和可编程调度,以及一个新的轻量级 OS-NIC 接口,可实现 NIC-CPU 紧密协调并支持 NIC 辅助 CPU 调度。基于 100 Gbps FPGA 原型的详细实验表明,与包括 Shinjuku 和 Caladan 在内的最先进的纯软件协调器相比,我们获得了更好的可扩展性、效率、延迟和吞吐量。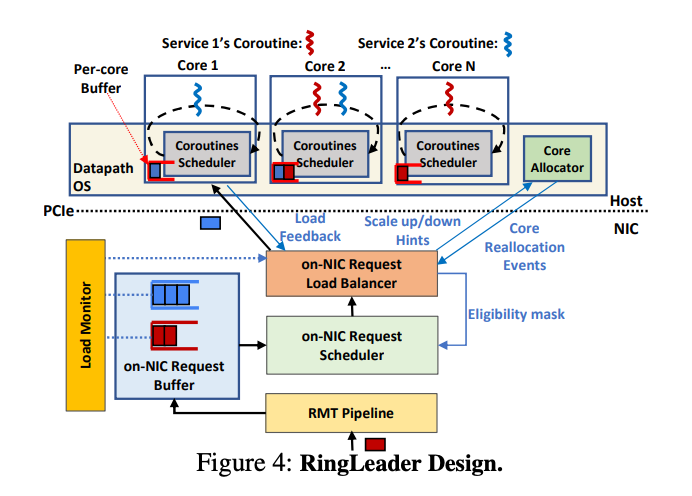 RDMA
标题:SRNIC: A Scalable Architecture for RDMA NICs
RDMA
标题:SRNIC: A Scalable Architecture for RDMA NICs作者:Zilong Wang, Hong Kong University of Science and Technology; Layong Luo and Qingsong Ning, ByteDance; Chaoliang Zeng, Wenxue Li, and Xinchen Wan, Hong Kong University of Science and Technology等
>摘要符合设想的RDMA需要具有高度可扩展性:在不可避免丢包的大型数据中心网络中表现良好(即高网络可扩展性),并支持每台服务器大量高性能连接(即高可扩展性)。商用RoCEv2 NIC(RNIC)缺乏可扩展性,因为它们依赖于无损、有限规模的网络结构,只支持少量高性能连接。在本文中,我们旨在通过设计SRNIC(一种可扩展RDMA NIC架构)来解决连接可扩展性挑战,同时保持商用RNIC的高性能和低CPU开销,以及IRN的高网络可扩展性。我们对SRNIC的关键见解是,通过仔细的协议和架构协同设计,可以将RNIC中的片上数据结构及其内存需求降至最低,从而提高连接可扩展性。在此基础上,我们分析了RDMA概念模型中涉及的所有数据结构,并通过RDMA协议头修改和架构创新(包括无缓存QP调度器和无内存选择性重传)尽可能多地删除它们。我们使用FPGA实现了一个功能齐全的SRNIC原型。实验表明,SRNIC在芯片上实现了10K性能连接,在标准化连接可扩展性(即每1MB内存的性能连接数)方面比商用RNIC高18倍,同时实现了97 Gbps吞吐量和3.3µs延迟,CPU开销低于5%,并保持了高网络可扩展性。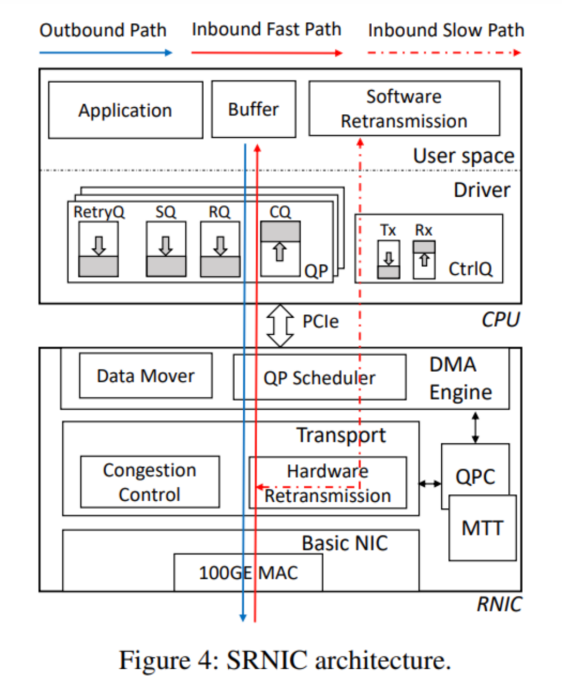 标题:Hostping: Diagnosing Intra-host Network Bottlenecks in RDMA Servers
标题:Hostping: Diagnosing Intra-host Network Bottlenecks in RDMA Servers作者:Kefei Liu, BUPT; Zhuo Jiang, ByteDance Inc.; Jiao Zhang, BUPT and Purple Mountain Laboratories; Haoran Wei, BUPT and ByteDance Inc.; Xiaolong Zhong, BUPT; Lizhuang Tan, ByteDance Inc.; Tian Pan and Tao Huang, BUPT and Purple Mountain Laboratories
>摘要在RDMA网络中,主机内网络被认为是健壮的,但很少受到关注。然而,随着RNIC(RDMA网卡)线路速率快速提升至数百G,主机内网络成为网络应用潜在的性能瓶颈。主机内网络瓶颈可能导致主机内带宽降低和主机内延迟增加,这会严重影响网络性能。然而,当发生主机内瓶颈时,由于缺乏监控系统,它们很难被发现。此外,现有的瓶颈诊断机制无法有效诊断主机内瓶颈。在本文中,我们根据长期的故障排除经验分析了主机内瓶颈的症状,并提出了 Hostping——首个专用于主机内网络的瓶颈监控和诊断系统,可实现低开销分钟级主机内故障定位,有效提升RDMA数据中心集群的算力平稳输出能力。Hostping 的核心思想是在主机内的 RNIC 和端点之间进行环回测试,以测量主机内延迟和带宽。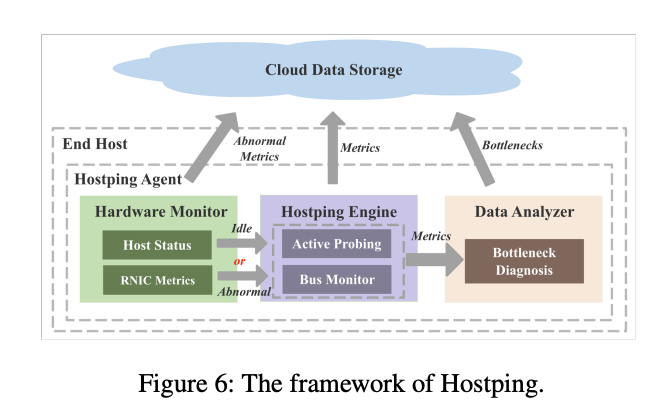 标题:Understanding RDMA Microarchitecture Resources for Performance Isolation
标题:Understanding RDMA Microarchitecture Resources for Performance Isolation作者:Xinhao Kong and Jingrong Chen, Duke University; Wei Bai, Microsoft; Yechen Xu, Shanghai Jiao Tong University; Mahmoud Elhaddad, Shachar Raindel, and Jitendra Padhye, Microsoft; Alvin R. Lebeck and Danyang Zhuo, Duke University
>摘要近年来,RDMA 在云中得到了广泛采用,以加速first-party workloads,并通过释放 CPU 周期来节省成本。现在,云提供商正致力于在通用客户VM 中支持 RDMA,以使 third-party workloads受益。为此,云提供商必须提供强大的性能隔离,以便一个租户的 RDMA 工作负载不会对另一个租户的 RDMA 性能产生不利影响。尽管在公有云中的网络性能隔离方面已经做出了很多努力,但我们发现 RDMA 因其复杂的 NIC 微架构资源(例如NIC 缓存)带来了独特的挑战。在本文中,我们旨在系统地了解 RNIC 微架构资源对性能隔离的影响。我们提出了一个模型来表示 RDMA 操作如何使用 RNIC 资源。使用此模型,我们开发了一个测试套件来评估 RDMA 性能隔离解决方案。最后,根据测试结果,我们总结了设计未来 RDMA 性能隔离解决方案的新见解。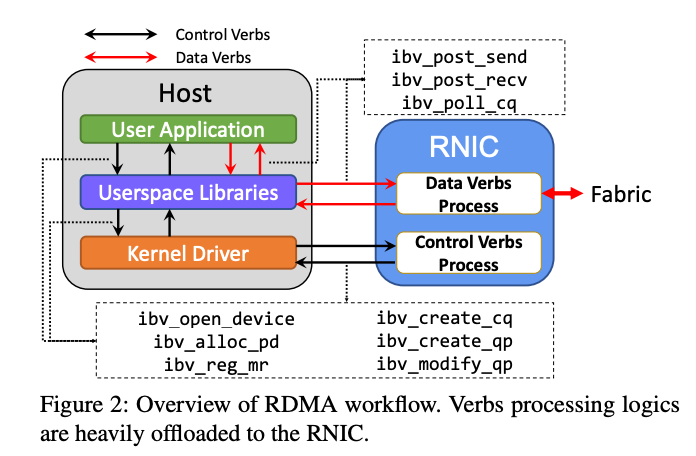 标题:Empowering Azure Storage with RDMA
标题:Empowering Azure Storage with RDMA作者:Wei Bai, Shanim Sainul Abdeen, Ankit Agrawal, Krishan Kumar Attre, Paramvir Bahl, Ameya Bhagat, Gowri Bhaskara, Tanya Brokhman, Lei Cao, Ahmad Cheema, Rebecca Chow, Jeff Cohen, Mahmoud Elhaddad等
>摘要网络是在云存储服务中实现高性能和高可靠性的关键。在Azure中,我们选择远程RDMA作为传输方式,旨在为存储前端流量(计算虚拟机和存储集群之间)和后端流量(存储集群内)启用它,以充分发挥其优势。由于计算和存储集群可能位于Azure区域内的不同数据中心,因此需要在区域范围内支持RDMA。这项工作展示了我们在部署区域内RDMA以支持Azure中的存储工作负载方面的经验。基础设施的高度复杂性和异构性带来了一系列新的挑战,例如不同类型的RDMA网络接口卡之间的互操作性问题。为了应对这些挑战,我们对网络基础设施做了一些更改。今天,Azure中大约70%的流量是RDMA,所有Azure公共区域都支持区域内RDMA。RDMA帮助我们实现了显著的磁盘I/O性能改进和CPU内核节省。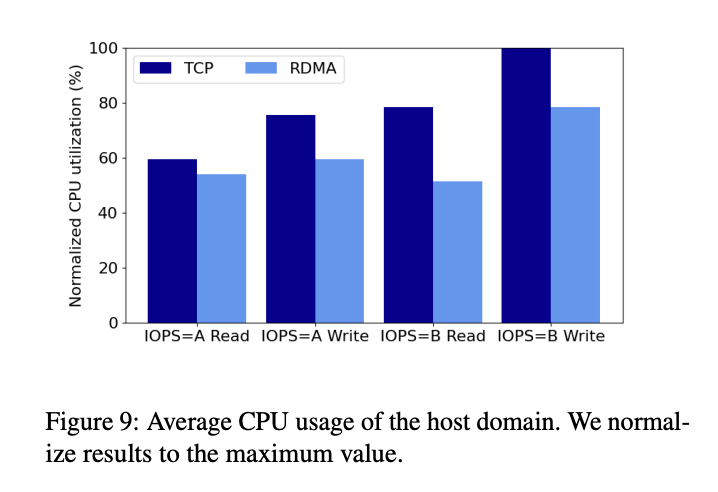 数据中心
标题:Flattened Clos: Designing High-performance Deadlock-free Expander Data Center Networks Using Graph Contraction
数据中心
标题:Flattened Clos: Designing High-performance Deadlock-free Expander Data Center Networks Using Graph Contraction作者:Shizhen Zhao, Qizhou Zhang, Peirui Cao, Xiao Zhang, and Xinbing Wang, Shanghai Jiao Tong University; Chenghu Zhou, Shanghai Jiao Tong University and Chinese Academy of Sciences
>摘要Flattened Clos (FC),一种拓扑/路由协同设计方法,用于消除expander网络中由 PFC 引起的死锁。FC的拓扑结构和路由设计分为三步:1)将每个ToR交换机在逻辑上划分为k个虚拟层,只在相邻虚拟层之间建立连接;2) 生成用于路由的虚拟上下路径;3) 利用图形收缩对虚拟多层网络和虚拟上下路径进行平面化。FC 的设计是无死锁的,并使用真实的测试平台和数据包级仿真验证了这一特性。与EDST(edge-disjoint-spanning-tree)路由相比,FC 将平均跳数减少了至少 50%,并将网络吞吐量提高了2 - 10倍以上。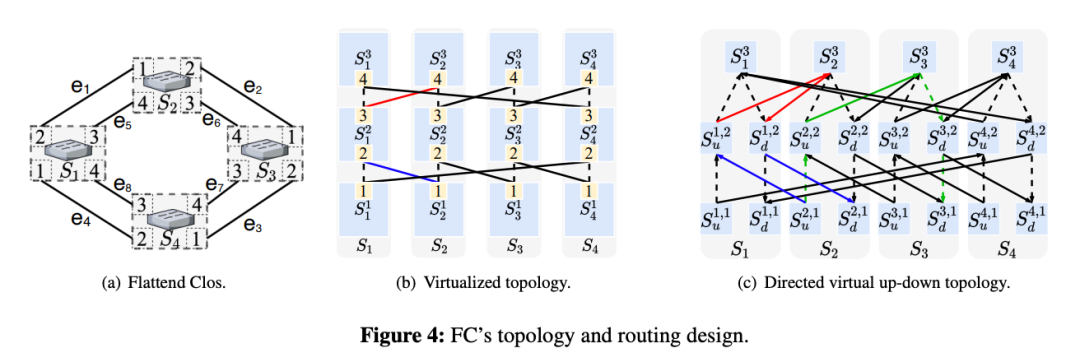 标题:Scalable Tail Latency Estimation for Data Center Networks
标题:Scalable Tail Latency Estimation for Data Center Networks作者:Kevin Zhao, University of Washington; Prateesh Goyal, Microsoft Research; Mohammad Alizadeh, MIT CSAIL; Thomas E. Anderson, University of Washington
>摘要该论文主要研究了如何为超大规模数据中心网络提供流级尾延迟性能的快速估计。网络尾部延迟通常是云应用性能的一个关键指标,它会受到多种因素的影响,包括网络负载、机架间流量偏差、流量突发、流量大小分布、超额订阅和拓扑不对称等。像ns-3 和 OMNeT++ 这样的网络模拟器可以提供准确的答案,但很难并行化,即使是中等规模的单个配置也需要数小时或数天来回答 what if 问题。MimicNet 展示了如何使用机器学习来提高模拟性能,不过每个配置都包含一个很长的训练步骤,并且对工作量和拓扑一致性的假设通常在实践中并不适用。本文主要介绍了解决上述问题的技术,为具有通用流量矩阵和拓扑的大型网络提供快速性能估计。其中一个关键步骤是将问题分解成大量并行独立的单链路模拟,通过仔细结合这些链路级模拟可以准确估计整个网络的端到端流量级性能分布。同时尽可能利用对称性来获得额外的加速,但不依赖机器学习,因此没有训练延迟。在 ns-3 需要 11到 27 小时来模拟 5 秒的网络行为的大规模网络上,新技术只需 1 到 2 分钟内便可完成运行,尾流完成时间的准确度在 9% 以内。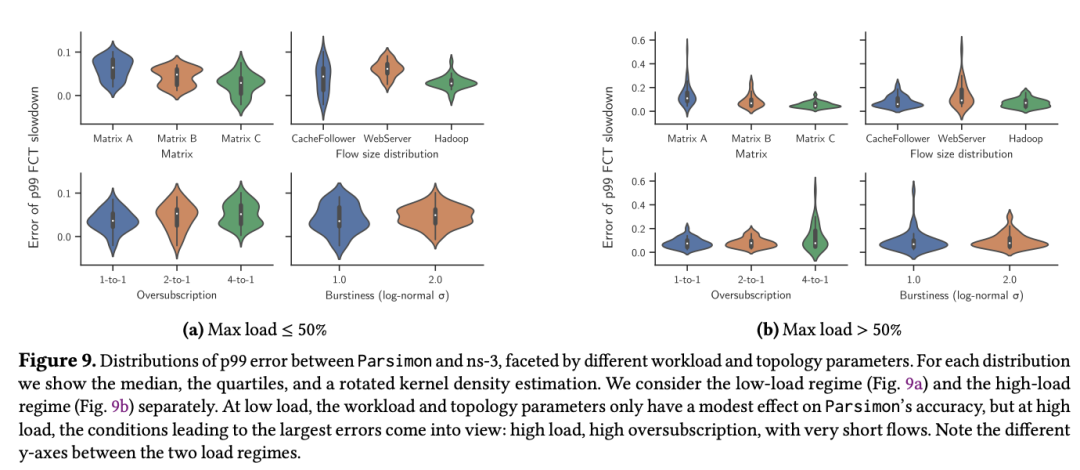 标题:Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning
标题:Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning作者:Pengfei Zheng and Rui Pan, University of Wisconsin-Madison; Tarannum Khan, The University of Texas at Austin; Shivaram Venkataraman, University of Wisconsin-Madison; Aditya Akella, The University of Texas at Austin
>摘要动态自适应已成为加速分布式机器学习 (ML) 训练的关键技术。最近的研究表明,动态调整模型结构或超参数可以在不牺牲准确性的情况下显著加速训练。然而,现有的 ML 集群调度器并不是为处理动态适应而设计的。研究表明,当训练吞吐量在动态适应下随时间变化时,现有方案无法提供公平性并降低系统效率。Shockwave是一个基于两个关键思想的未来规划调度程序。首先,Shockwave 将经典市场理论从静态设置扩展到动态设置,共同优化效率和公平性。第二,Shockwave 利用随机动态规划来处理动态变化。我们为 Shockwave 构建了一个系统,并通过跟踪驱动模拟和集群实验验证了其性能。结果表明,对于具有动态适应性的 ML 作业轨迹,与现有的公平调度方案相比,Shockwave 将 makespan 提高了 1.3 倍,公平性提高了 2 倍。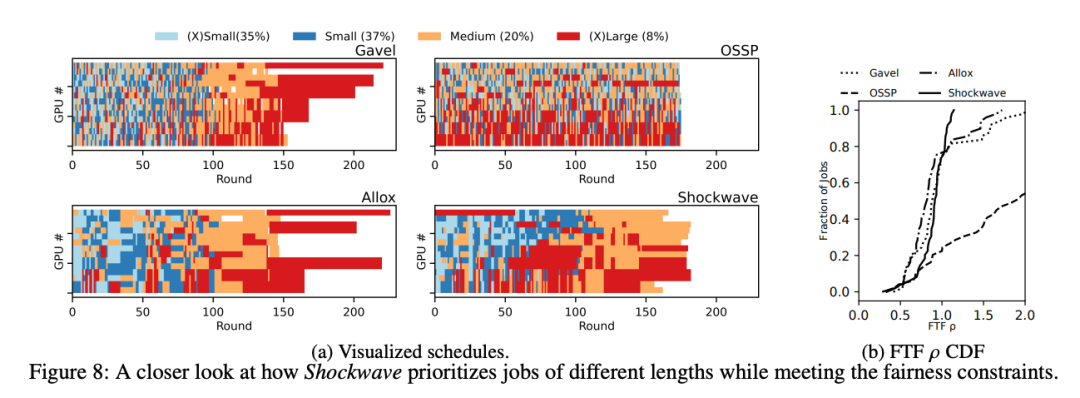 标题:Protego: Overload Control for Applications with Unpredictable Lock Contention
标题:Protego: Overload Control for Applications with Unpredictable Lock Contention作者:Inho Cho, MIT CSAIL; Ahmed Saeed, Georgia Tech; Seo Jin Park, Mohammad Alizadeh, and Adam Belay, MIT CSAIL
>摘要现代数据中心应用程序是并发的,因此它们需要同步来控制对共享数据的访问。本文介绍了Protego系统用于防止锁争用问题。Protego提供了一种新的准入控制策略,可以防止出现锁争用时的计算拥塞。关键思想是在基于信用的准入控制算法中使用观察到的吞吐量的边际改进,而不是 CPU 负载或延迟测量,该算法调节对服务器的传入请求的速率。Protego还引入了一种新的延迟感知同步抽象,称为ASQM(Active synchronization Queue Management),允许应用程序在延迟超过延迟目标时中止请求。Protego 目前已经应用于两个真实的应用程序 Lucene 和 Memcached,并表明它在避免拥塞崩溃的同时,比最先进的过载控制系统实现了高达3.3倍的吞吐量和低12.2倍的99%延迟。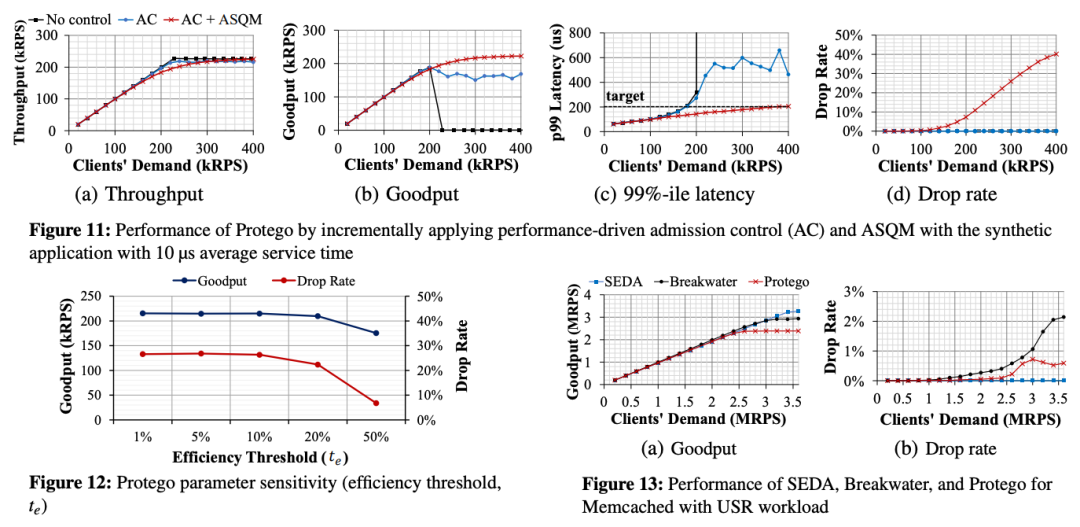 GPU标题:Transparent GPU Sharing in Container Clouds for Deep Learning Workloads
GPU标题:Transparent GPU Sharing in Container Clouds for Deep Learning Workloads作者:Bingyang Wu and Zili Zhang, Peking University; Zhihao Bai, Johns Hopkins University; Xuanzhe Liu and Xin Jin, Peking University
>摘要容器广泛用于数据中心的资源管理。在容器云中支持深度学习 (DL) 训练的一种常见做法是将 GPU 静态绑定到整个容器。由于生产中 DL 作业的资源需求多种多样,大量 GPU 未得到充分利用。因此,GPU 集群的 GPU 利用率较低,导致作业完成时间较长,因为需要排队。TGS(Transparent GPU Sharing)是一个为容器云中的 DL 训练提供透明 GPU 共享的系统。与最近用于 GPU 共享的应用层解决方案形成鲜明对比的是,TGS 在容器下的操作系统层运行。TGS 利用自适应速率控制和透明统一内存来同时实现高 GPU 利用率和性能隔离。它确保生产作业不会受到共享 GPU 上的机会作业的很大影响。我们构建了 TGS 并将其与 Docker 和 Kubernetes 集成。实验表明 (i) TGS 对生产作业的吞吐量影响很小;(ii) TGS为机会作业提供了与最先进的应用层解决方案AntMan相似的吞吐量,并且与现有的操作系统层解决方案MPS相比,其吞吐量提高了15倍。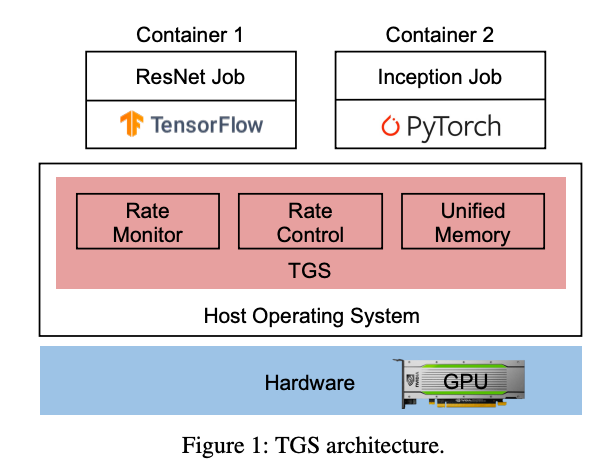 标题:ARK: GPU-driven Code Execution for Distributed Deep Learning
标题:ARK: GPU-driven Code Execution for Distributed Deep Learning作者:Changho Hwang, KAIST, Microsoft Research; KyoungSoo Park, KAIST; Ran Shu, Xinyuan Qu, Peng Cheng, and Yongqiang Xiong, Microsoft Research
>摘要目前最先进的深度学习 (DL) 应用程序倾向于横向扩展到大量并行 GPU。然而,我们观察到跨 GPU 的集体通信开销通常是分布式 DL 性能的关键限制因素。它通过频繁传输小数据块来充分利用网络带宽,这也会在 GPU 上产生大量 I/O 开销,从而干扰 GPU 上的计算。根本原因在于基于 CPU 的通信事件处理效率低下以及无法通过 GPU 线程控制 GPU 内部的 DMA 引擎。为了解决这个问题,我们提出了一个 GPU 驱动的代码执行系统,该系统利用 GPU 控制的硬件 DMA 引擎进行 I/O 卸载。我们的自定义 DMA 引擎流水线处理多个 DMA 请求以支持高效的小型数据传输,同时消除了 GPU 内核上的 I/O 开销。与仅由 CPU 启动的现有 GPU DMA 引擎不同,我们让 GPU 线程直接控制 DMA 操作,其中 GPU 驱动自己的执行流并自主处理通信事件,而无需 CPU 干预,更高效。我们的原型 DMA 引擎从小至 8KB 的消息大小(吞吐量提高 3.9 倍)的线速,通信延迟仅为 4.3 微秒(快 9.1 倍),同时它对 GPU 上的计算几乎没有干扰,在实际训练工作负载中实现了1.8倍的吞吐量。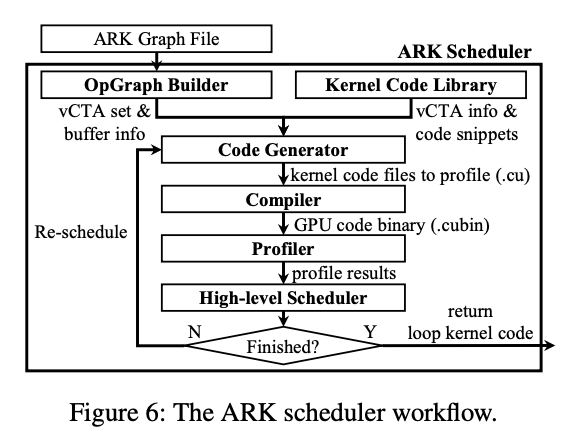 标题:BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
标题:BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing作者:Tianfeng Liu, Tsinghua University, Zhongguancun Laboratory, ByteDance; Yangrui Chen, The University of Hong Kong, ByteDance; Dan Li, Tsinghua University, Zhongguancun Laboratory; Chuan Wu, The University of Hong Kong; Yibo Zhu, Jun He, and Yanghua Peng, ByteDance; Hongzheng Chen, ByteDance, Cornell University; Hongzhi Chen and Chuanxiong Guo, ByteDance
>摘要现有系统在使用 GPU 训练具有数十亿个节点和边的大型图形时效率低下,主要瓶颈是为 GPU 准备数据的过程——子图采样和特征检索。本文提出了 BGL,一种分布式 GNN 训练系统,旨在通过几个关键思想解决瓶颈问题。首先是提出了一个动态缓存引擎来最小化特征检索流量。通过共同设计缓存策略和采样顺序,我们找到了低开销和高缓存命中率的最佳平衡点。其次改进了图分区算法,以减少子图采样期间的跨分区通信。最后,仔细的资源隔离减少了不同数据预处理阶段之间的争用。在各种 GNN 模型和大型图形数据集上进行的大量实验表明,BGL 的平均性能明显优于现有 GNN 训练系统 1.9 倍。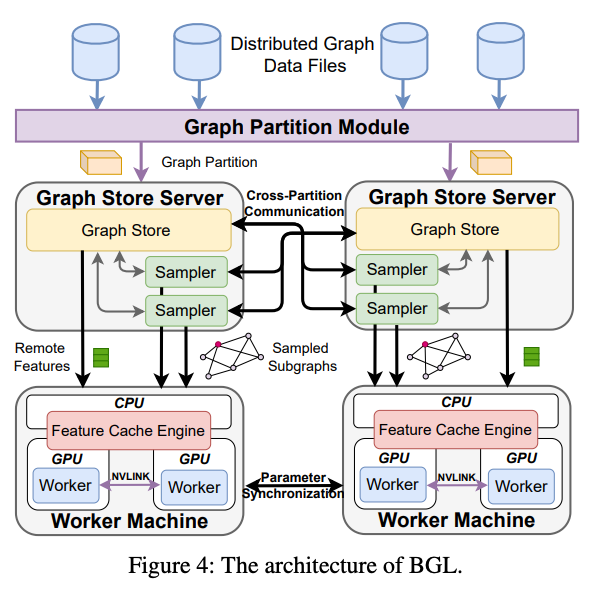 标题:Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training
标题:Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training作者:Jie You, Jae-Won Chung, and Mosharaf Chowdhury, University of Michigan
>摘要我们观察到优化深度神经网络((DNN)训练的常见做法通常会导致能效低下,而能源消耗和性能优化之间需要存在权衡。Zeus是一种优化框架,可通过自动为重复出现的 DNN 训练作业找到最佳作业和 GPU 级配置来进行权衡。Zeus 将在线探索-开发方法与实时能量分析相结合,避免了对昂贵的离线测量的需要,同时适应了数据随时间的变化。评估表明,Zeus 可以针对不同的工作负载将 DNN 训练的能效提高 15.3%–75.8%。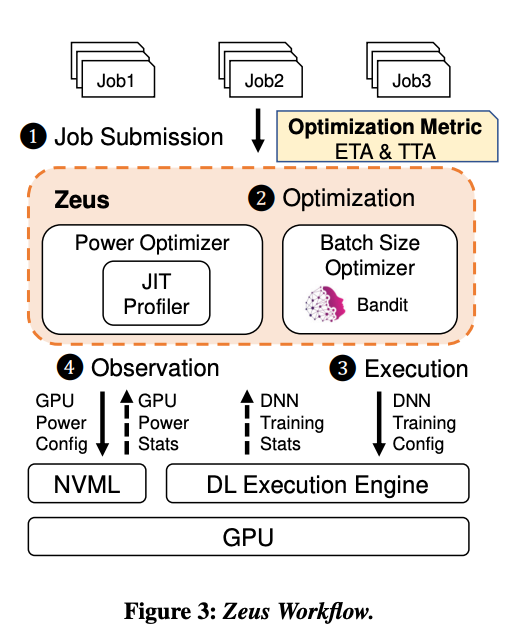
审核编辑 :李倩
-
gpu
+关注
关注
28文章
4727浏览量
128874 -
可编程
+关注
关注
2文章
859浏览量
39808 -
网络通信
+关注
关注
4文章
797浏览量
29794
原文标题:NSDI '23热点论文:可编程、RDMA、数据中心、GPU有哪些新动态?(附下载)
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
当CPU/GPU遭遇数据中心功耗天花板,SDAccel来了
数据中心是什么
Mali-Valhall系列GPU可编程内核
基于现场可编程芯片的动态下载应用研究
可编程SoC(SoPC),什么是可编程SoC(SoPC)
如何利用可编程逻辑实现数据中心互连 DCI互连盒架构解读
可编程逻辑实现数据中心互连







 工商网监
工商网监
评论