 它居然是决定存储要不要分层的关键
它居然是决定存储要不要分层的关键
背景
现有的计算机体系架构中通常采用层级缓存来弥补外存和内存之间的性能差距。但是,层缓存都有极限带宽和有限的命中率,在层级缓存下数据需要频繁的在各个层级缓存之前迁移,造成过高的数据拷贝开销。同时,随着高性能的外部存储设备的出现,外存的带宽并没有被充分的利用。这篇文章介绍了非分级缓存(NHC),这是一种在现代存储层次中进行缓存的新方法。与传统的缓存相比,NHC通过在有利的情况下将多余的负载重定向到层次结构中较低的设备来提高性能。NHC动态调整分配和访问决策,从而使性能最大化(例如,高吞吐量、低99%的延迟)。这篇文章在Orthus-CAS(一个块层缓存内核模块)和Orthus-KV(一个键值存储的用户级缓存层)中实现了NHC。通过全面的实证研究表明了NHC的有效性。Orthus-KV和Orthus-CAS在一系列现实的工作负载下,比各种现代层次的传统缓存提供了明显更好的性能(最高可达2倍)。
问题
1. 缓存还是分层
为了应对层次结构的性质,系统通常采用两种策略:缓存和分层,如图1所示。考虑一个有两个存储层的系统:一个(快、贵、小)性能层和一个(慢、便宜、大)容量层。通过缓存,所有的数据都驻留在容量层,而热数据的副本通过缓存替换算法被放置在性能层。分层也是将热门数据放在性能层;然而,与缓存不同的是,它在更长的时间范围内迁移数据(而不是复制)。如果有足够多的请求进入快速层,整体性能就会接近快速层的峰值性能。因此,传统的缓存和分层努力确保大多数的访问都能到达性能层。传统的缓存和分层都是为了最大限度地提高性能,努力确保大多数访问是由性能良好的设备提供的。因此,大多数缓存和分层策略都是为了最大限度地提高快速设备的点击率。在传统的层次结构中,高层的性能明显高于底层,这种方法提供了高性能。然而,随着存储环境的快速变化,现代设备的性能特征也在不断重叠,因此,必须重新思考如何管理这些设备。
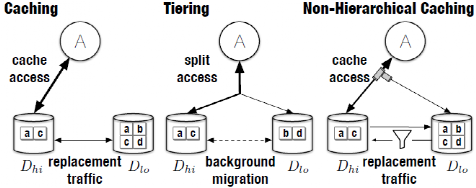
图1 缓存类型
2. 缓存之间存在性能特征重叠
虽然缓存和分层这种优化命中率的传统智慧对于传统的层次结构(例如,CPU缓存和DRAM,或DRAM和硬盘)来说可能仍然是正确的,但在现代存储层次结构中,存储设备的快速变化使这种叙述变得复杂。具体来说,许多新的非易失性存储器和低延迟固态硬盘的出现引入了具有(有时)重叠的性能特征的设备。因此,必须重新思考如何在存储层次中管理这些设备。为了更好地理解这些设备的性能重叠,图2显示了各种实际设备在4KB读/载和写/存时的吞吐量,同时改变了并发水平。该图显示了成对设备之间的性能比。DRAM/NVM绘制了内存(SK Hynix 16GB DDR4)与单个英特尔Optane DCPM(128GB)的带宽;NVM/Optane使用DCPM与英特尔905P Optane SSD;最后,Optane/Flash使用相同的Optane SSD和三星970 Pro Flash SSD。对于任何一对X/Y,如果X的性能大于Y,则绘出正比(YX);否则,绘出负比(-XY)(在灰色区域)。

图2 各个设备之间的性能比
总结一下,以下是存储时代层次结构的主要趋势。与传统的层次结构(如DRAM与HDD)不同,新的存储层次结构可能不是一个层次;两个相邻的层次(如NVM与Optane SSD)的性能可能相似。其次,新设备的性能取决于许多因素,包括不同的工作负载(读与写)和并发水平。用传统的缓存和分层来管理这些设备已不再有效。
方法和设计
1. 非分层缓存设计目标
这篇文章提出了非分级缓存(NHC),这是一个缓存框架,它利用了设备的性能,而这些设备在传统的缓存中只被视为一个容量层。NHC有以下目标:
- 表现与经典缓存一样好或更好。经典缓存通过优化上级设备的性能来优化存储层次结构的性能;这种性能是通过找到最大化命中率的工作集来优化的。NHC在最坏的情况下应该退化为经典的缓存,并且应该能够利用任何经典的缓存策略(例如,驱逐和写分配)。
- 不需要特殊知识或配置。NHC不应该比经典缓存做出更多的假设。NHC不应该要求事先了解工作负载或设备的详细性能特征。NHC应该能够管理任何存储层次结构。
- 对动态工作负载具有鲁棒性。工作负载随着时间的推移,在其负载量和工作集方面发生变化。NHC应该适应动态变化。
NHC的主要思想(图1)是将多余的负载转移到容量大的设备上,当这样做可以提高整体的缓存性能。NHC可以用三个步骤来描述。首先,在系统预热时(或在工作负载发生重大变化后),NHC利用经典缓存来识别当前的工作集并将数据加载到高性能设备中;这确保NHC的性能至少与经典缓存一样好。第二,在命中率稳定后,NHC通过向容量设备发送多余的负载来改进传统缓存。这种多余的负载有两部分组成:一是由于高性能设备已经达到最大性能,所以在高性能设备上没有提供额外的性能;二是导致两个设备之间不必要的数据移动的读取失误。传统的缓存在漏读发生时将数据从容量设备转移到性能设备,以提高命中率。然而,当性能设备已经达到最大性能时,提高命中率是没有好处的。因此,NHC减少了进入性能设备的数据量。使用基于反馈的方法,NHC确定了过剩的负载;它不需要对设备或工作负载有任何了解。最后,如果观察到工作负载的变化,NHC会返回到经典缓存;如果工作负载从未稳定下来,该算法就会退化为经典缓存。NHC可以利用与传统缓存相同的写分配策略(例如,绕写或回写)。
2. 非层级缓存架构
如图3所示,经典缓存可以通过在其缓存控制器和非分级缓存调度器上增加决策点来升级为NHC。传统的缓存控制器为用户/应用程序向存储设备的读写提供服务,并根据其替换策略(例如LRU)控制性能设备的内容。本文提出一个新的缓存调度器监控性能,并控制是否执行经典缓存,以及在哪里提供缓存读取命中。调度器优化目标性能指标,该指标可以由用户提供(例如,IOPS/s)或使用设备级指标(例如,请求延迟)。NHC调度器通过一个布尔值data_admit(da)和一个变量load_admit(la)进行控制。当性能设备上发生读取缺失时,da标志控制行为:当da被设置时,根据缓存替换策略,将缺失的数据项分配到性能设备中;当da未被设置时,缺失由容量设备处理,不分配到性能设备中。经典缓存对应的情况是,da标志为真。la变量控制如何处理读取命中,并指定了应该发送到性能设备的读取命中的百分比;当la为0时,所有的读取命中都被发送到容量设备。具体来说,对于每个读取命中,会产生一个随机数R∈[0,1.0];如果R<=la,请求被发送到性能设备中;否则,被发送到容量设备中。在经典缓存中,la总是1。NHC框架与任何传统的缓存写分配策略(由用户指定)一起工作,处理写命中/缺失。NHC根据政策将写缺失纳入性能设备;da、la不控制写命中/缺失。在回写的情况下,缓存写入会在性能设备中引入脏数据,而存储设备上的数据可能是过时的;在这种情况下,NHC不会向存储设备发送脏读。

图3 非层级缓存架构图
3. 缓存调度器算法
NHC调度器调整控制器的行为以优化目标性能指标。如图4所示,调度器有两种状态:增加性能设备上缓存的数据量以最大化命中率,或保持缓存的数据不变,同时调整发送到每个设备的负载。
状态1:提高命中率。NHC调度器首先让缓存控制器以其默认的替换策略(da为真,la为1)执行传统的缓存;在这个过程中,缓存被预热,随着工作集在性能设备上的缓存,命中率得到提高。NHC调度器监控性能设备的命中率,并在命中率相对稳定时结束这一阶段;此时,性能设备为工作负载提供的性能接近其峰值。
状态2:调整设备间的负载。在性能设备包含了高命中率和性能的工作集后,NHC调度器探测是否向存储设备发送一些请求会增加存储设备的性能,同时不会降低性能设备的性能。在这种状态下,da被设置为false,反馈被用来调整la以最大化目标性能指标。具体来说,调度器(第6-18行)修改la;在每个迭代中,用la +/-步在一个时间间隔(例如,5ms)内测量性能。la的值在三个数据点所指示的方向上进行调整。当la的当前值导致最佳性能时,调度器坚持使用当前值。la的值被保持在可接受的[0, 1.0]范围内,有一个负的惩罚函数。如果调度器发现最佳的la是1,它就会放弃调度,回到状态1;直观地说,这意味着NHC已经将当前的工作负载的访问压力并没有达到性能设备的极限,因此需要经典缓存来提高命中率,以进一步提高性能。
由于NHC依靠经典缓存来实现可接受的命中率,所以当工作负载位置发生变化时,它会重新启动优化过程。NHC调度器在运行时监控缓存命中率;如果当前命中率下降,调度器会重新进入状态1,用当前工作集重新配置缓存。如果工作负载从未稳定下来,NHC的行为就像传统的缓存。

图4 缓存调度器算法执行流程
实验结果
实验性能对比包含三个方面,分别为吞吐量、动态适应工作负载和与以前的工作对比。
吞吐量性能 :图5中展示了Open CAS和Orthus-CAS在不同层次、负载量和命中率的只读工作负载下的标准化吞吐量。Load-1.0定义为最小的读取负载,以实现缓存设备的最大读取带宽;通过扩展Load-1.0产生Load-0.5、1.5和2.0。研究的层次包括DRAM、NVM、Optane SSD和Flash。还使用FlashSim模拟了具有两种性能差异(50:10和50:25)的层次结构;我们对FlashSim进行了配置,以模拟最高速度为50MB/s、25MB/s和10MB/s的设备。我们从图中观察到以下几点。首先,当负载较轻时(例如,负载-0.5),缓存设备的性能总是优于容量设备。在这种情况下,NHC不会绕过任何负载,其表现与经典缓存相同。第二,当工作负载可以充分利用缓存设备时,Orthus-CAS会提高性能。直观地说,较高的命中率和负载使NHC有更多机会绕过请求,提高性能。图5证明了这一直觉:在95%的命中率和Load-2.0的情况下,NHC在DRAM+NVM、NVM+Optane和Optane+Flash方面分别获得了21%、32%、54%的改善。在80%的命中率下,这种改进会略有减少。

图5 吞吐量实验结果图
动态工作负载性能 :如图6(a)所示,Orthus-KV在白天的表现好,最高可达100%,但在夜间负荷较低时表现相似。图6(a)显示了Orthus-KV如何调整数据和负载的承认率。在夜间,两者都在100%左右;当命中率稳定时,Orthus-KV偶尔会调整负载接纳率,但在发现没有改善后,很快就回到了传统的缓存。在白天,Orthus-KV将数据接受率保持在0,并调整负载接受率以适应动态负载。图12(b)中证明NHC对工作集的突然变化反应良好。实验以YCSB-C为基础,从一个工作集开始,然后在时间10s时改变。图中显示,当工作集发生变化时(时间=10s),Orthus-KV迅速检测到命中率的变化,并切换到经典缓存:负载和数据接纳比率增加到1.0。在命中率开始稳定后(时间=11s),Orthus-KV调整了负载接受率。最初(11s-28s),由于命中率还不够高,Orthus-KV经常将1.0确定为最佳的负载接纳,并返回到传统的数据移动的缓存中。在工作负载变化后约20秒,命中率稳定下来,Orthus-KV达到了稳定的性能,比经典缓存高出60%。图12(c)显示了Orthus-KV在YCSB-D上的表现(95%读取,5%插入),在这里,由于对最近插入的值进行读取,位置性会随着时间而改变。由于位置性的变化和不接纳新数据到缓存中,Orthus-KV的命中率随着时间的推移而下降,直到NHC确定1.0是最佳的负载接纳率。然后Orthus-KV返回到传统的缓存,并提高命中率。一旦命中率恢复稳定,Orthus-KV就会恢复循环,调整负载接纳率。

图6 动态工作负载实验结果
现有工作对比:SIB的目标是具有许多SSD和HDD的HDFS集群,在这种情况下,HDD的总吞吐量是非同小可的:SIB将SSD作为一个写缓冲区(不提升任何读缺失),并建议使用HDD来处理额外的读流量。LBICA确定性能层何时处于 "突发负载 "状态,此时它不会向性能层分配新的数据;与NHC不同,LBICA不会重定向任何读取命中。如图7(a)所示,SIB+表现不佳,因为它不提升Optane中的读缺失。SIB++表现较好,但当工作负载发生变化时,如图7(b)所示,就会受到影响;在这些工作负载中,写流量每隔一段时间就会发生变化,时间在10到0.5秒之间。

图7 现有工作对比
总结
这篇文章引入了非分级缓存,这是一种优化的方法,可以从设备中提取峰值性能。NHC是基于一种新的缓存调度算法,该算法考虑了工作负载和设备特性,以做出分配和访问决定。通过实验,我们展示了NHC在各种设备、高速缓存配置和工作负载上的优势。同时,NHC通过将部分负载卸载到容量设备上,动态调整卸载工作量,利用容量设备的带宽,在性能上有很大改进。
-
存储
+关注
关注
13文章
4265浏览量
85677 -
计算机
+关注
关注
19文章
7428浏览量
87727 -
分层缓存管理
+关注
关注
0文章
2浏览量
926
发布评论请先 登录
相关推荐

测控类要不要学习板卡!!!!!
我的项目要不要跑RTOS?
揭秘iPhone7上的iOS10系统体验 看完这一篇再决定要不要升级iOS10
电脑固态硬盘到底要不要分区
存储要不要分层,关键要看它!








 工商网监
工商网监
评论