 【核芯观察】ChatGPT背后的算力芯片(二)
【核芯观察】ChatGPT背后的算力芯片(二)
【核芯观察】是电子发烧友编辑部出品的深度系列专栏,目的是用最直观的方式令读者尽快理解电子产业架构,理清上、中、下游的各个环节,同时迅速了解各大细分环节中的行业现状。以ChatGPT为首的AI大模型在今年以来可以说是最热的赛道,而AI大模型对算力的需求爆发,也带动了AI服务器中各种类型的芯片需求,所以本期核芯观察将关注ChatGPT背后所用到的算力芯片产业链,梳理目前主流类型的AI算力芯片产业上下游企业以及运作模式。
接上期ChatGPT背后的算力芯片(一)
AI大模型领域中,用于训练和推理的AI服务器主要用到CPU、GPU、FPGA、ASIC等这几类芯片,因此本期主要针对该几类芯片的细分产业链,以及AI服务器整体市场格局做具体的分析。
AI服务器市场格局
根据IDC的数据,2022年全球服务器市场规模1230亿美元,同比增长20.0%,预计到2027年全球服务器市场规模将达到1780亿美元。中国市场方面,2022年服务器市场规模为273.4亿美元。
AI服务器方面,2022年市场规模202亿美元,同比增长29.8%,占服务器市场规模的比例为16.4%,同比提升1.2个百分点。在2022年上半年的数据中,浪潮、戴尔、惠普、联想、新华三分别位居全球AI服务器市场前五,市场份额分别为15.1%、14.1%、7.7%、5.6%、4.7%。
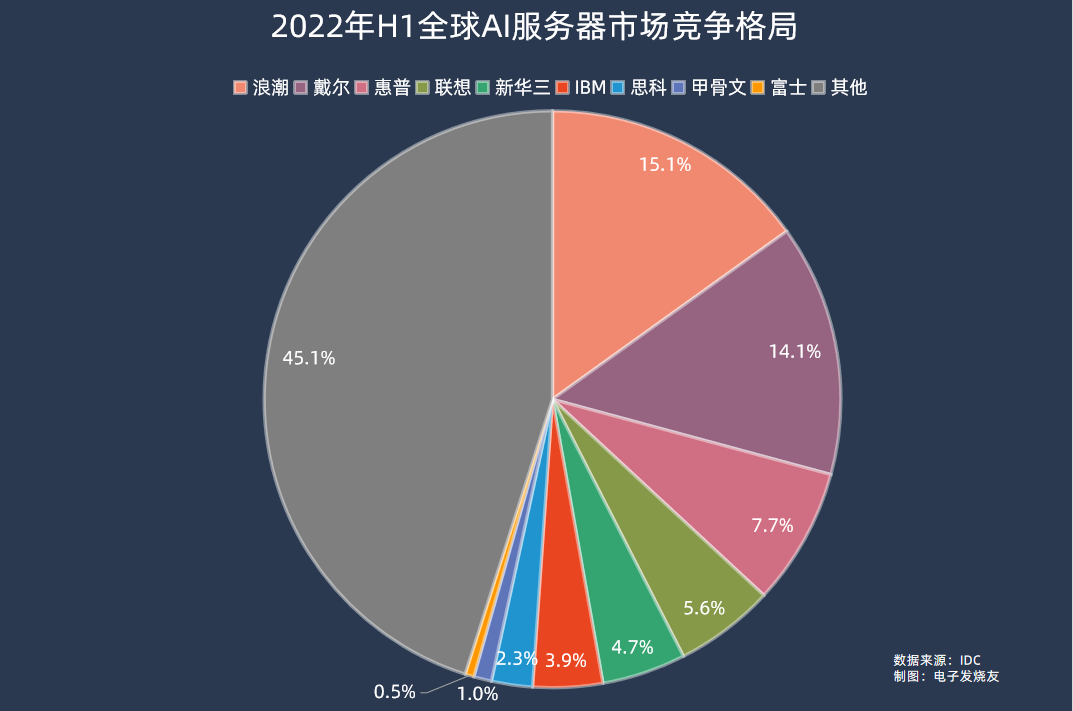
IDC预计,到2026年全球AI服务器市场规模将达到355亿美元,对应2022-2026年的复合年均增长率为15.1%。
不过,2023年以来对于AICG大模型训练和推理的需求开始进入爆发期,相关应用对于AI服务器的部署需求激增,因此AI服务器占到整个服务器市场的比例将稳步上升,AI服务器市场规模在未来几年的复合年均增长率将有望突破20%。
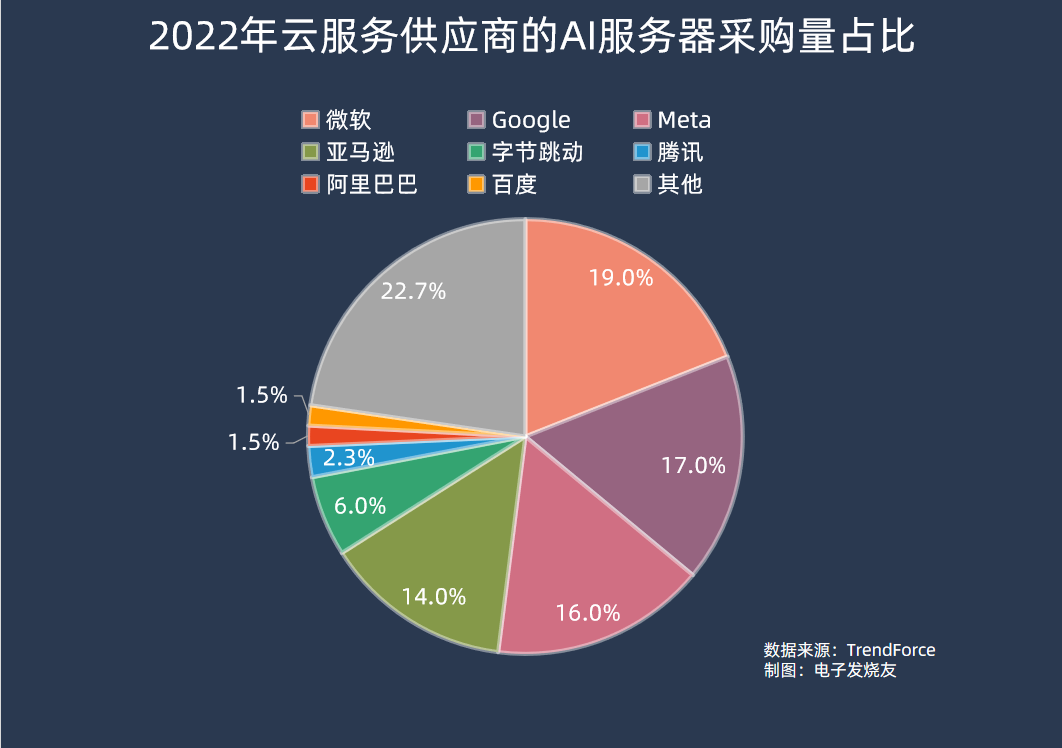
在采购端,集邦咨询数据显示,2022年AI服务器采购量中,北美四大云端供应商Microsoft、Google、Meta、AWS合计占比66.2%;而国内厂商方面,字节跳动采购力度最大,占比达6.2%,其余腾讯、阿里巴巴、百度分别占2.3%、1.5%、1.5%。
从当前生成式AI大模型的进展来看,去年在AI服务器采购量中排名较前的公司,部分也是在生成式AI大模型上较为领先的。ChatGPT所属的OpenAI公司正是由微软独家提供云计算支持,而谷歌也有自己的PaLM 2、Meta自家的LLaMA等AI大模型,排名第四的亚马逊则是传统云计算大厂。
国内厂商尽管此前也有布局相关的AI大模型技术,不过投入规模普遍较小,直到今年ChatGPT的爆火,可能才真正带动国内厂商往大规模落地的方向投入,AI服务器采购量也将会在今年有明显增幅。
AI服务器产业链
我们将AI服务器产业链分拆成上中下游,上游主要包括三个方面,数据处理(CPU、GPU、FPGA、ASIC)、传输(光模块)、存储(DRAM、NAND Flash);中游主要是服务器整机供应商;下游则是云服务供应商、互联网、AI软件公司等。
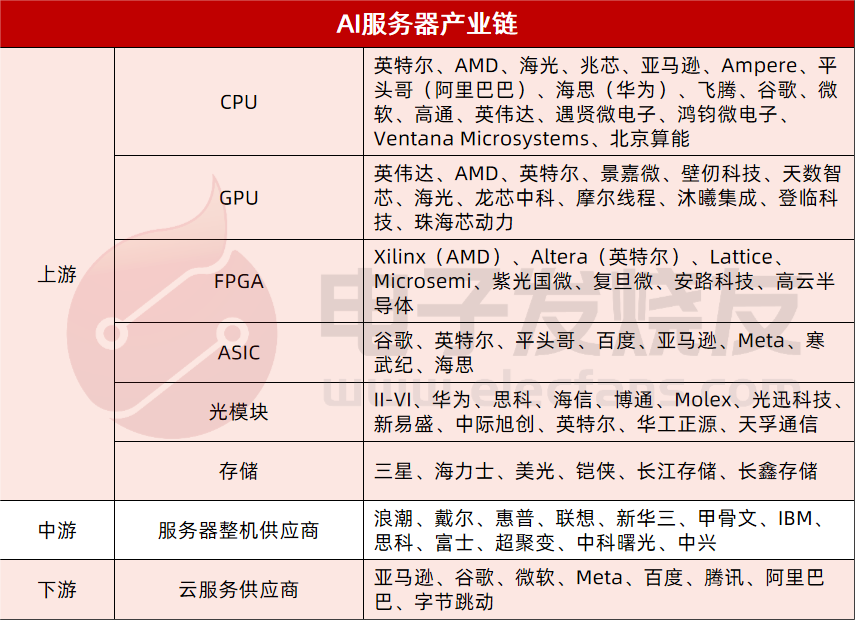
上游
CPU:英特尔、AMD、海光、兆芯、亚马逊、Ampere、平头哥(阿里巴巴)、海思(华为)、飞腾、谷歌、微软、高通、英伟达、遇贤微电子、鸿钧微电子、Ventana Microsystems、北京算能
GPU:英伟达、AMD、英特尔、景嘉微、壁仞、天数智芯、海光、龙芯中科、摩尔线程、沐曦集成、登临科技、珠海芯动力
FPGA:Xilinx(AMD)、Altera(英特尔)、Lattice、Microsemi、紫光国微、复旦微、安路科技、高云半导体
ASIC:谷歌、英特尔、平头哥、百度、亚马逊、Meta、寒武纪、海思
光模块:II-VI、华为、思科、海信、博通、Molex、光迅科技、新易盛、中际旭创、英特尔、华工正源、天孚通信
存储:三星、海力士、美光、铠侠、长江存储、长鑫存储
中游
服务器整机供应商:浪潮、戴尔、惠普、联想、新华三、甲骨文、IBM、思科、富士、超聚变、中科曙光、中兴
下游
亚马逊、谷歌、微软、Meta、百度、腾讯、阿里巴巴、字节跳动、
AI服务器中的主要算力芯片之CPU
服务器CPU市场现状
前文提到,在AI大模型领域中包括训练和推理两个不同领域,而训练和推理所需要进行的操作是不同的。在训练过程中,AI模型需要进行大规模矩阵运算,在构建神经网络的过程中需要并行计算能力;在推理的过程中,需要对大量已经训练好的模型进行实时推理以及预测工作,主要用到的是逻辑控制、串行计算能力,并对响应速度有较高要求。因此更加适合推理和预测的CPU,在推理服务器中的使用量较大。
这从成本分析中也能够看到,根据IDC的报告,CPU在推理型服务器中的成本占比为25%,在训练型服务器中的成本占比则仅为9.8%。而在对AI服务器进行推理和训练工作的负载比例预测中,IDC数据显示2021年AI服务器用于推理和训练的负载占比分别是40.9%和59.1%,预测到2025年推理和训练的比例将变为60.8%和39.2%,也就是说随着AI大模型的成熟,AI服务器用于推理的比例会越来越高。
那么按照这个数据估算,2021年CPU在整体AI服务器中的成本占比平均约为16%,到2025年这个数字则会上升至19%左右。因此,在整体AI服务器市场高速增长的情况下,CPU需求的增长更是较为可观的。
目前x86依然是服务器CPU市场的绝对主流,主要的两家服务器CPU厂商英特尔和AMD在2021年和2022年分别占据服务器CPU市场份额的92.5%和90.6%,不过可以看到随着Arm架构服务器CPU的崛起,x86架构CPU在服务器市场的份额即将跌破9成。
细分看x86服务器CPU市场,目前是由英特尔和AMD两大玩家垄断,当然国内也有海光、兆芯获得x86永久授权,目前也有推出x86服务器CPU,但性能劣势较大,市场份额可以忽略。
早在2013年左右,市场就有传闻称AMD放弃x86服务器CPU业务,AMD的退出,导致英特尔在x86服务器CPU中出货量占比一度超过99%。而2017年伴随Zen架构的EPYC CPU推出,AMD重返服务器CPU市场,并在几年间快速抢占英特尔原有的市场份额。

Counterpoint数据显示,2021年英特尔在服务器CPU市场中的份额为80.71%,而到了2022年份额下降至70.77%;另一边的AMD,2021年在服务器CPU市场中的份额为11.74%,到了2022年份额几乎翻倍,逼近20%。
另外Arm架构CPU在服务器市场近年来增长迅速。根据Counterpoint的调研,2022年仅亚马逊以及Ampere两家的Arm CPU在服务器市场中已经占据4.7%的市场份额,而2021年这两家的Arm服务器CPU仅有2.9%的份额,尽管基数较小,但同比增速超过60%,显然未来还有很大增长空间。
目前Arm服务器CPU的玩家众多,由于自研Arm 服务器CPU能够带来效率提升,不少云服务供应商也开始自研Arm CPU。除了前面提到的亚马逊外,阿里巴巴、华为已经将自研的Arm服务器CPU应用在自家云服务器上,谷歌、微软等也早有传闻正在开发自研Arm服务器CPU。
芯片厂商方面,Ampere目前是Arm服务器CPU市场中占比较高的,另外还有英伟达、高通、飞腾等厂商目前推出了Arm服务器CPU产品,国内近年也有遇贤微电子和鸿钧微电子两家初创公司正在基于Arm Neoverse N2开发云原生服务器CPU。
另外RISC-V架构的CPU也正在进军服务器领域,芯片初创企业Ventana Microsystems在2022年12月发布了全球首款面向服务器的RISC-V CPU Veyron V1;北京算能在今年平头哥玄铁RISC-V生态大会上发布了首款64核RISC-V服务器处理器SOPHON SG2042。
服务器CPU发展趋势
CPU目前的发展趋势主要是围绕微架构和制造工艺持续升级迭代。以x86服务器CPU的两大巨头为例,按照两家的服务器产品路线规划图,一般都会以1-2年为周期进行换代升级,从英特尔数据中心(DCG)业务收入来看,通常新产品上市会带动相关业务持续2-3个季度的高增长。
纵观服务器CPU的发展,核心数量是一个较为明显的变化。2023年1月英特尔发布的第四代Xeon服务器处理器系列中最高定位的W9-3495X配备了56个核心,睿频为4.8 GHz,L3缓存为105MB,支持112条PCIe通道及八通道DDR5-4800内存。
AMD在2022年年11月发布了最新的第四代EPYC系列服务器CPU,最高定位的9654P配备了高达96个核心,共192线程,最高频率3.7GHz,L3缓存高达384MB,支持128条PCIe 5.0通道以及12通道DDR5-4800内存。
而在2017年AMD推出第一代EPYC处理器的时候,最多能提供32个核心。不过除了堆核心之外,更重要的是如何实现集成多核心。在第一代EPYC中,AMD就采用了MCM(multi-chip module多芯片模块)架构,由4个相同的die(晶片)构成一个CPU,单个die包含8个核心加上缓存、Infinity Fabric总线控制器等,也被称为CCD(Core Complex Die)。在每个CCD中包含2个由核心和缓存组成的CCX(Core Complex)、2个DDR内存控制器、用于CCD间互联和CPU间互联的Infinity Fabric总线。
这样设计的好处是,由于大规模的芯片面积通过多个CCD来达成,所以与相同核心性能下的大型单一芯片相比,尽管面积要大10%以上,但由于小die良率高,制造测试成本大幅降低。以32核CPU为例,采用多CCD设计要比大规模单芯片成本下降40%以上,同时也就更容易做到多核心。
而第二代EPYC中AMD进一步将I/O功能模块从CCD中剥离出来,单独做成一个I/O die位于芯片中间,最多可以有8个CCD围绕I/O die,这也被称为Chiplet(芯粒),这种做法让第二代EPYC的CCD数量最高相比一代翻倍。
正是由于多核设计,以及成本上的优势,Chiplet的设计也成为了当下服务器CPU的一个大趋势,英特尔在今年的第四代Xeon服务器CPU中也采用了Chiplet设计,按照英特尔的路线图,未来第五代 Xeon SierraForest更是将会有144个内核。
另一方面是,随着大数据时代中AI、边缘计算等场景下网络数据更加海量,同时还需要更加实时的处理,所以除了使用CPU资源来进行高速协议处理和运算之外,还可以将网卡集成到芯片上,比如CPU、FPGA、ASIC等。于是包含CPU、高性能网络接口和可编程加速引擎等的芯片被称为DPU(数据处理芯片)。
通常基于多核CPU的DPU是基于Arm架构的CPU,目前包括英伟达、博通等厂商都在大力推动DPU在数据中心的应用。
AI服务器中的主要算力芯片之 GPU
市场现状
GPU最初是为了处理计算器图形或游戏画面渲染等工作而被开发出来,但由于其高并行计算的特性和处理大规模数据的能力强,也被拓展用于通用计算等领域。
所有目前GPU主要是分成传统GPU以及GPGPU(通用GPU)两个领域,GPU主要是为图像服务,因此内置了多种模块,包括视频编解码加速核心、2D加速核心等;GPGPU则专为专业计算领域服务,相比于传统GPU,GPGPU削减了图形处理能力,将其并行计算的能力全部投入到通用计算领域,增加比如专用向量、张量、矩阵运算指令等,着重提升浮点运算的精度和性能,在服务器中作为加速卡,通过CPU协调进行计算,在AI、高性能计算等领域广泛应用。
今年以来由于生成式AI大模型的火爆,AI服务器中使用到的高端GPGPU产品持续短缺,有企业表示AI服务器价格不到一年时间涨幅近20倍。英伟达A100 GPU市场价格也随着暴涨,两个月涨幅高达50%。
在AI服务器中,GPU的使用量相比其他应用的服务器要更高,比如一般的AI服务器单台会配备2颗CPU以及4-8颗GPGPU,部分高端服务器甚至可以配备16颗GPGPU。而高端GPU的单价较高,因此在AI服务器中的价值量也较高。电子发烧友网推算,GPU在训练型AI服务器中的成本占比平均超过70%,在推理型服务器中的占比也有25%左右。
按照2021年AI服务器用于推理和训练的负载占比分别是40.9%和59.1%推算,GPU在AI服务器中的成本占比平均为51.6%,随着AI大模型训练的成熟,对训练服务器需求下降,到2025年这个比例预计会降至42.6%。但可能由于整体服务器规模的提升,依然保持GPU单位数量需求的高速增长。
据Verified Market Research数据,2021年,全球GPU市场规模为334.7亿美元,预计2030年将达到4773.7亿美元,2021年到2030年的复合年均增长率高达34.35%。
3D Center数据显示,英伟达在2022年第二季度独立GPU市场份额为79%,AMD则占20%的市场份额,合计99%。英特尔则凭借在PC端的优势占据剩下1% 的市场份额。
而在企业细分市场,根据IDC的数据,2021年英伟达的市场份额高达91.4%,AMD份额仅为8.5%,英伟达GPU产品几乎垄断企业市场。
国内方面,2021年GPU服务器以91.9%的份额占国内加速服务器市场的主导地位,IDC预计2024年中国GPU服务器市场规模将达到64亿美元。
但目前国内市场同样是以英伟达为主导,国内GPU厂商普遍营收不高,产品市场化处于起步阶段。其中国内GPU龙头景嘉微目前产品主要应用在军用、信创等领域,民用产品与国际领先水平差距较大。同时自2017年起,国内开始诞生不少GPU初创企业,普遍集中于GPGPU赛道,比如天数智芯、壁仞科技、沐曦集成电路、登临科技、摩尔线程等,部分产品已经量产,并可应用于AI服务器。
比如去年9月浪潮AI服务器搭载壁仞科技高端通用GPU芯片BR104,在权威AI基准评测MLPerf V2.1的自然语言处理(BERT)和图像识别(ResNet50)两项AI任务中取得了8卡和4卡整机的全球最佳性能。
总体来看,国内GPU厂商在AI服务器市场目前竞争力还不足,但随着美国对高端GPU的出口管制,以及ChatGPT带动的生成式AI大模型热潮,国产GPGPU或许会迎来新一轮的发展机会。
AI服务器GPU发展趋势
GPU用于通用计算的概念最早是在2003年SIGGRAPH大会上首次被提出,随后的几年里,业界通过用统一的流处理器取代GPU中原有的不同着色单元的设计释放了GPU的计算能力,可编程的GPU也就随之诞生。
后续伴随线性代数、物理仿真和光线跟踪等各类算法向GPU芯片移植,GPU由专用图形显示向通用计算逐渐转型。2007年,英伟达首次推出通用并行计算架构CUDA(Compute Unified Device Architecture,统一计算设备架构),正式令GPU作为通用并行数据处理加速器,也就是GPGPU。
CUDA架构对于GPGPU而言意义非凡,进行通用计算无需先映射到图形API中,大大降低了CUDA的开发门槛,为GPGPU的应用起到了巨大的推动作用,这也为英伟达筑建起了高不可及的生态壁垒。
随后,GPU的发展就在架构迭代中进行,一般来说,评价一个GPU的性能参数包括微架构、制程、图形处理器数量、流处理器数量、显存容量/位宽/带宽/频率、核心频率等等,其中微架构的设计是GPU性能提升的关键所在。
GPU微架构(Micro Architecture)是兼容特定指令集的物理电路构成,由流处理器、纹理映射单元、光栅化处理单元、光线追踪核心、张量核心、缓存等部件共同组成。图形渲染过程中的图形函数主要用于绘制各种图形及像素、实现光影处理、3D坐标变换等过程,期间涉及大量同类型数据(如图像矩阵)的密集、独立的数值计算,而GPU结构中众多重复的计算单元就是为适应于此类特点的数据运算而设计的。
微架构的设计对GPU性能的提升发挥着至关重要的作用,也是GPU研发过程中最关键的技术壁垒。以英伟达为例,其最新的H100GPU相比于A100,1.2倍的性能提升来自于核心数目的提升,5.2倍的性能提升则来自于微架构的设计。
除此之外,由于海量数据的需求,GPU的互联以及显存带宽都需要持续提升,包括HBM显存、英伟达NVLink高速GPU互连技术等,都在快速迭代中。目前最新的NVLink-C2C可以提供处理器与加速器之间高达900GB/s的高带宽数据传输,以及快速同步和高频更新下的超低延迟性能。最新的HBM 3高带宽显存标准则可以提供最高819GB/s的数据传输速率,目前英伟达H100、AMD Instinct MI300加速卡已经采用了HBM3标准的显存。
下一期内容,我们将会继续对AI大模型中使用到的FPGA、ASIC这些细分领域产业做进一步的分析梳理,记得关注我们~
值得一提的是,电子发烧友网主办的第七届人工智能大会将在2023年8月23日正式召开,
在过去的三届大会中,我们举办的“中国人工智能卓越创新奖”评选活动得到了业界的普遍认可和广泛好评。2023年我们将继续这一殊荣的评选,举办“2023第四届中国人工智能卓越创新奖”评选活动,旨在发掘和表彰人工智能领域优秀人才、企业、技术以及产品。
“2023第四届中国人工智能卓越创新奖”奖项提名于即日起到6月30日截至,提名详情可扫描下方二维码了解。

-
算力
+关注
关注
1文章
1026浏览量
15001 -
ChatGPT
+关注
关注
29文章
1574浏览量
8140
发布评论请先 登录
相关推荐
DeepSeek对芯片算力的影响

AI算力:智能时代的核心驱动力


算智算中心的算力如何衡量?
AI算力芯片供电电源测试利器:费思低压大电流系列电子负载

存算一体架构创新助力国产大算力AI芯片腾飞
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
浅析三大算力之异同
从多核到众核, 赛昉科技RISC-V+NoC IP子系统为算力芯片赋能

揭秘芯片算力:为何它如此关键?
【核芯观察】IMU惯性传感器上下游产业梳理(二)

【核芯观察】充电桩上下游产业梳理(二)
高算力芯片:未来科技的加速器?






 工商网监
工商网监
评论