 使用AWS Graviton处理器优化的PyTorch 2.0推理
使用AWS Graviton处理器优化的PyTorch 2.0推理
作者:Sunita Nadampalli
新一代的CPU因为内置了专门的指令,在机器学习(ML)推理方面提供了显著的性能提升。结合它们的灵活性、高速开发和低运营成本,这些通用处理器为其他现有硬件解决方案提供了一种替代选择。
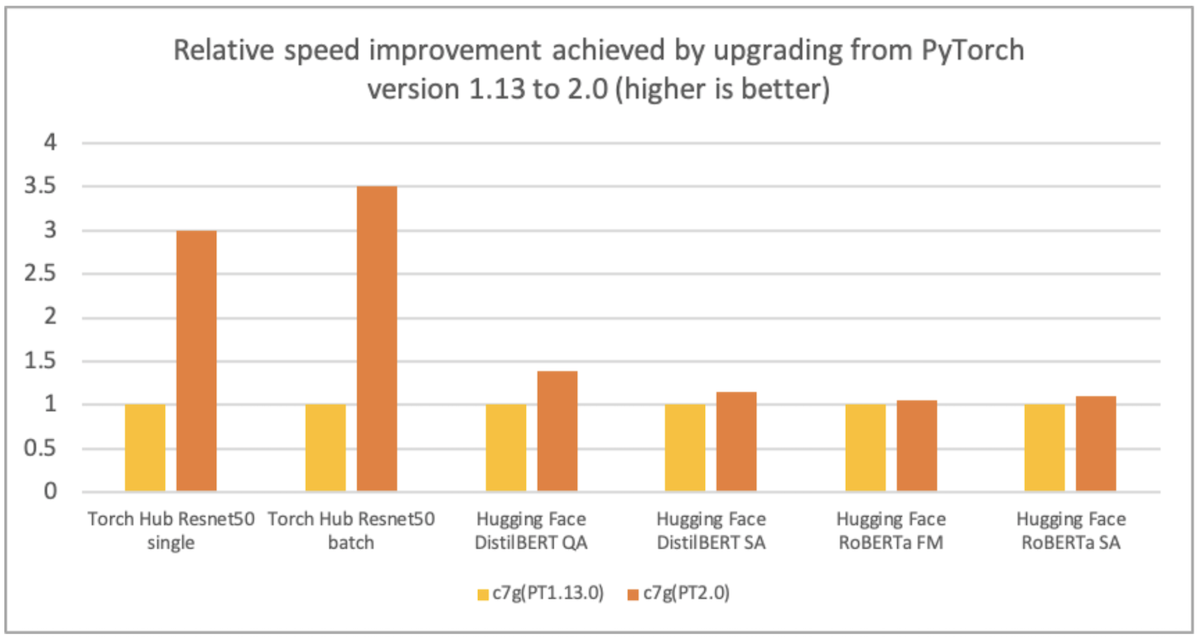
AWS、Arm、Meta等公司帮助优化了基于Arm处理器的PyTorch 2.0推理性能。因此,我们很高兴地宣布,AWS Graviton基于实例的PyTorch 2.0推理性能比之前的PyTorch版本提高了3.5倍,Resnet50的速度(请参见下图),BERT的速度提高了1.4倍,使Graviton基于实例成为AWS上这些模型最快的计算优化实例。
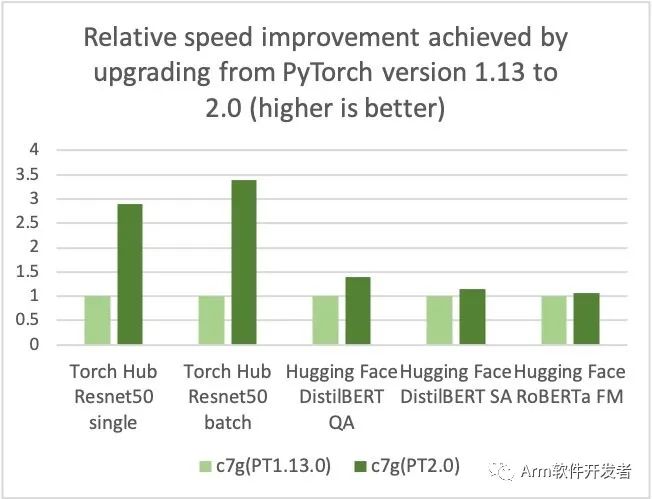
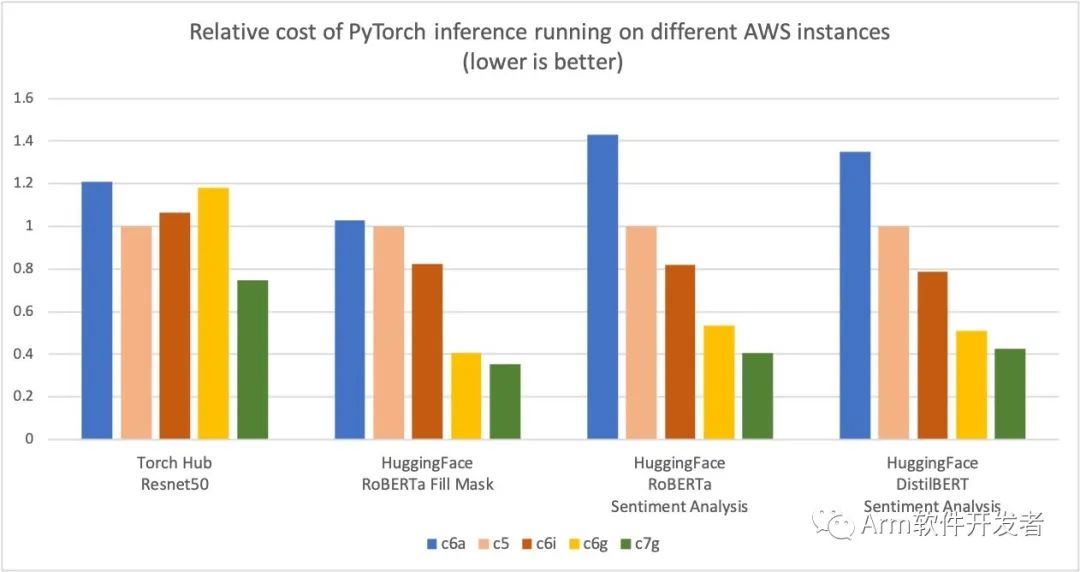
AWS使用基于AWS Graviton3的Amazon Elastic Cloud Compute C7g实例进行PyTorch推理,相对于可比较的EC2实例,跨Torch Hub Resnet50和多个Hugging Face模型,可节省高达50%的成本,如下图所示。
这是因为AWS Graviton3处理器是最新一代定制的AWS Graviton处理器,可为Amazon Elastic Compute Cloud(Amazon EC2)中的工作负载提供最佳价格性能。它们提供高达2倍的浮点性能、高达2倍的加密性能和高达3倍的ML性能,包括对PyTorch的支持。
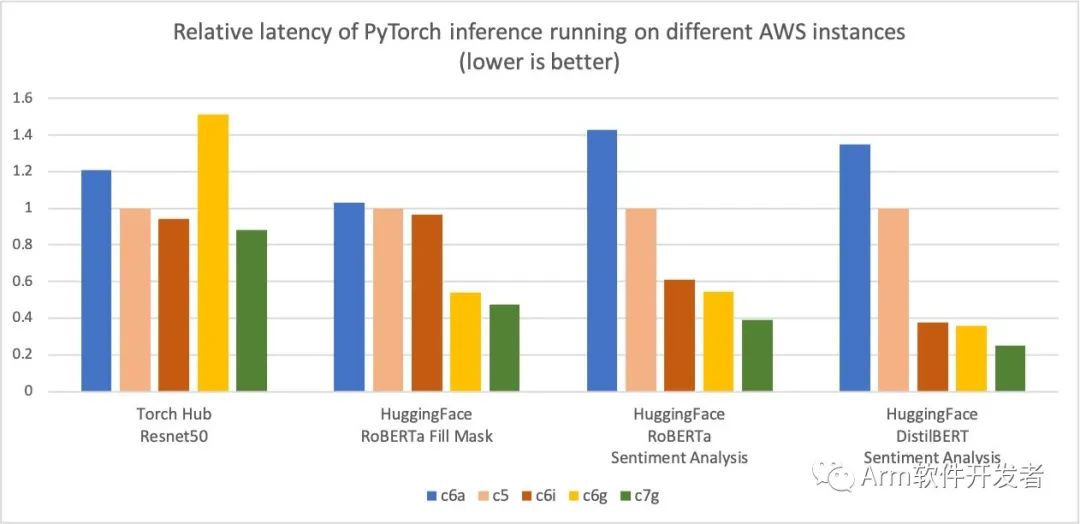
此外,推理的延迟也减少了,如下图所示。
我们在Graviton上的其他工作负载中也看到了类似的价格性能优势趋势,例如使用FFmpeg进行视频编码(https://aws.amazon.com/blogs/opensource/optimized-video-encoding-with-ffmpeg-on-aws-graviton-processors/)。
优化细节
优化集中在三个关键领域:
-
GEMM内核 - PyTorch通过OneDNN后端(以前称为MKL-DNN)支持Arm Compute Library(ACL)GEMM内核,用于基于Arm的处理器。ACL库为Neon和SVE优化了GEMM内核,适用于fp32和bfloat16格式。这些内核提高了SIMD硬件利用率并降低了端到端推理延迟。
-
bfloat16支持 - Graviton3中的bfloat16支持允许有效部署使用bfloat16,fp32和AMP(自动混合精度)训练的模型。标准fp32模型通过OneDNN快速数学模式使用bfloat16内核,无需模型量化,与不带bfloat16快速数学支持的现有fp32模型推理相比,性能提高了两倍。
-
原始缓存 - 我们还为conv、matmul和inner product运算符实现了原始缓存,以避免冗余的GEMM内核初始化和张量分配开销。
如何利用这些优化
最简单的方法是使用Amazon Elastic Compute Cloud(Amazon EC2)C7g实例或Amazon SageMaker上的AWS Deep Learning Containers(DLC)。DLC可在Amazon Elastic Container Registry(Amazon ECR)上提供AWS Graviton或x86。有关SageMaker的更多详细信息,请参阅在基于AWS Graviton的实例上运行机器学习推理工作负载(https://aws.amazon.com/blogs/machine-learning/run-machine-learning-inference-workloads-on-aws-graviton-based-instances-with-amazon-sagemaker/)以及Amazon SageMaker添加了八个基于Graviton的实例以进行模型部署(https://aws.amazon.com/about-aws/whats-new/2022/10/amazon-sagemaker-adds-new-graviton-based-instances-model-deployment/)。
使用AWS DLC
要使用AWS DLC,请使用以下代码:
udo apt-get update
sudo apt-get -y install awscli docker
# Login to ECR to avoid image download throttling
aws ecr get-login-password --region us-east-1
| docker login --username AWS
--password-stdin 763104351884.dkr.ecr.us-east-1.amazonaws.com
# Pull the AWS DLC for pytorch
# Graviton
docker pull 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference-graviton:2.0.0-cpu-py310-ubuntu20.04-ec2
# x86
docker pull 763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-inference:2.0.0-cpu-py310-ubuntu20.04-ec2如果您喜欢通过pip安装PyTorch,请从官方repo安装PyTorch 2.0 wheel。在这种情况下,在启动PyTorch之前,您将需要设置两个环境变量,如下面的代码所述,以激活Graviton优化。
使用Python wheel
要使用Python wheel,请参考以下代码:
# Install Python
sudo apt-get update
sudo apt-get install -y python3 python3-pip
# Upgrade pip3 to the latest version
python3 -m pip install --upgrade pip
# Install PyTorch and extensions
python3 -m pip install torch
python3 -m pip install torchvision torchaudio torchtext
# Turn on Graviton3 optimization
export DNNL_DEFAULT_FPMATH_MODE=BF16
export LRU_CACHE_CAPACITY=1024
运行推断
可以使用PyTorch TorchBench测量CPU推理性能改进,或比较不同的实例类型:
# Pre-requisite:
# pull and run the AWS DLC
# or
# pip install PyTorch2.0 wheels and set the previously mentioned environment variables
# Clone PyTorch benchmark repo
git clone https://github.com/pytorch/benchmark.git
# Setup Resnet50 benchmark
cd benchmark
python3 install.py resnet50
# Install the dependent wheels
python3 -m pip install numba
# Run Resnet50 inference in jit mode. On successful completion of the inference runs,
# the script prints the inference latency and accuracy results
python3 run.py resnet50 -d cpu -m jit -t eval --use_cosine_similarity
性能基准测试
您可以使用AmazonSageMaker推理推荐实用程序(https://docs.aws.amazon.com/sagemaker/latest/dg/inference-recommender.html)来自动化不同实例之间的性能基准测试。使用推理推荐程序,您可以找到实时推理端点,该端点可以为给定的ML模型以最低的成本提供最佳性能。我们通过在生产端点上部署模型,使用推理推荐器笔记本收集了前面的数据。有关推理推荐程序的更多详细信息,请参阅GitHub repo(https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-inference-recommender/huggingface-inference-recommender/huggingface-inference-recommender.ipynb)。我们为这篇文章测试了以下模型:ResNet50图像分类(https://pytorch.org/hub/pytorch_vision_resnet/)、DistilBERT情绪分析(https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)、RoBERTa填充掩码(https://huggingface.co/roberta-base)和RoBERTa情绪分析(https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment)。
结论
AWS通过Torch Hub Resnet50中基于AWS Graviton3的亚马逊弹性云计算C7g实例,以及相对于可比EC2实例的多个拥抱人脸模型,为PyTorch推理节省了高达50%的成本。这些实例可在SageMaker和AmazonEC2上获得。AWS Graviton技术指南(https://github.com/aws/aws-graviton-getting-started)提供了优化的库和最佳实践列表,这些库和最佳做法将帮助您在不同的工作负载中使用Graviton实例实现成本效益。
如果您发现在AWS Graviton上没有观察到类似性能提升的用例,请在AWS Gravaton技术指南(https://github.com/aws/aws-graviton-getting-started)上提交问题,让我们了解它。我们将继续添加更多性能改进,使Graviton成为使用PyTorch进行推理的最具成本效益和效率的通用处理器。
-
cpu
+关注
关注
68文章
10947浏览量
213895 -
机器学习
+关注
关注
66文章
8460浏览量
133411 -
AWS
+关注
关注
0文章
434浏览量
24665 -
pytorch
+关注
关注
2文章
808浏览量
13500
原文标题:使用AWS Graviton处理器优化的PyTorch 2.0推理
文章出处:【微信号:Arm软件开发者,微信公众号:Arm软件开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
强悍的AWS Graviton4处理器及其背后的Arm Neoverse
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用
在AWS云中使用Arm处理器设计Arm处理器
基于亚马逊自研的 Arm 处理器 Graviton2
AWS Arm 架构处理器首次落地中国区域:比同配置 X86 实例性价比提高 40%
亚马逊云原生自研处理器Graviton 2正式落地中国
AWS基于Arm架构的Graviton 2处理器落地中国
专用处理能力驱动基于Arm架构的云计算时代并支持AWS Graviton不断创新

使用AWS Graviton降低Amazon SageMaker推理成本


亚马逊网络服务即将推出第四代Graviton处理器
Arm与AWS合作深化,AWS Graviton4展现显著进展
在AWS Graviton4处理器上运行大语言模型的性能评估






 工商网监
工商网监
评论