 非常实用的Linux内存查看方法
非常实用的Linux内存查看方法
0. 引言
系统内存是硬件系统中必不可少的部分,定时查看系统内存资源运行情况,可以帮助我们及时发现内存资源是否存在异常占用,确保业务的稳定运行。
例如:定期查看公司的网站服务器内存使用情况,可以确保服务器的资源是否够用,或者发现服务器内存被占用异常可以及时解决,避免因内存不够导致无法访问网站或访问速度慢的问题。
因此,对于 Linux 管理员来说,在日常工作中能够熟练在 Linux 系统下检查内存的运行状况就变得尤为重要!
查看内存的运行状态并非难事,但是针对不同的情况使用正确的方式查看呢?
一口君整理了几个 个非常实用的 Linux 内存查看方法
1、free命令
2、 vmstat命令
3、 /proc/meminfo 命令
4、 top命令
5、 htop 命令
6、查看进程内存信息
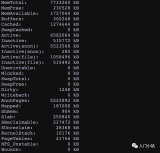
Linux内存总览图
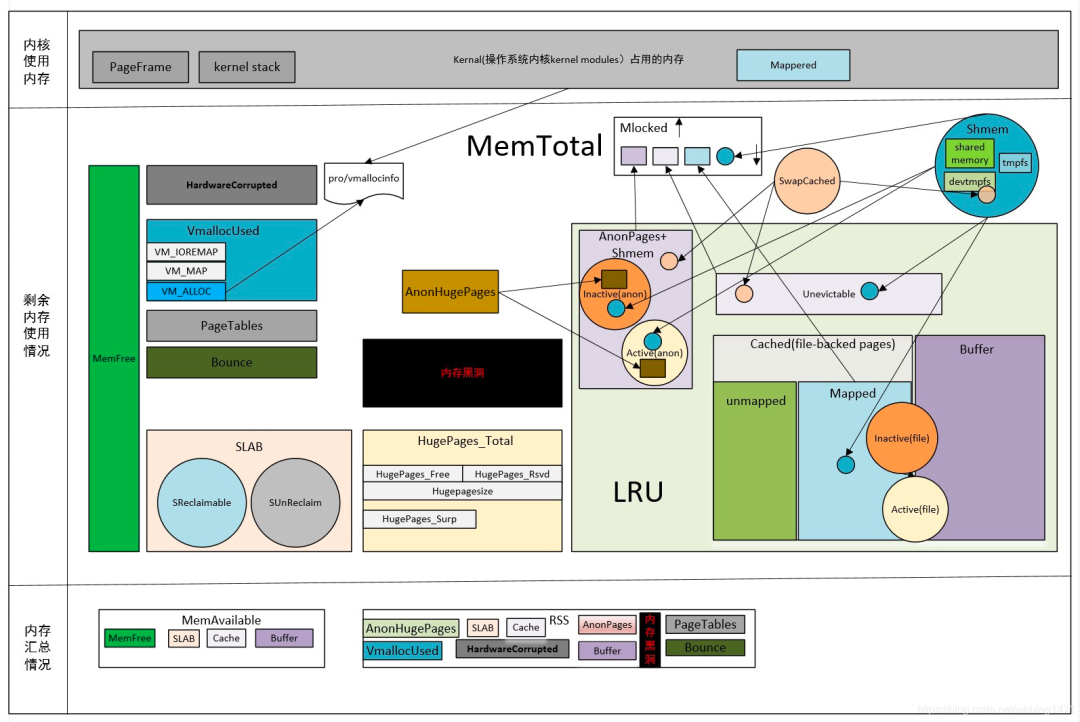 该图很好的描述了OS内存的使用和分配等详细信息。建议大家配合该图来一起学习和理解内存的一些概念。
该图很好的描述了OS内存的使用和分配等详细信息。建议大家配合该图来一起学习和理解内存的一些概念。
一、free命令
free 命令可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
1. free 命令语法:
free[options]
free 命令选项:
-b#以Byte为单位显示内存使用情况; -k#以KB为单位显示内存使用情况; -m#以MB为单位显示内存使用情况; -g#以GB为单位显示内存使用情况。 -o#不显示缓冲区调节列; -s<间隔秒数>#持续观察内存使用状况; -t#显示内存总和列; -V#显示版本信息。
2. free 命令实例
free-t#以总和的形式显示内存的使用信息 free-h-s10#周期性的查询内存使用信息,每10s执行一次命令 free-h-c10#输出10次 在版本 v3.2.8,就是输出一次!需要配合-s 使用。 在版本 v3.3.10,不加-s,就默认1秒输出一次。 free-V#查看版本号
v3.2.8

v3.3.10
下面先解释一下输出的内容:
| 内容 | 含义 |
|---|---|
| Mem | 行(第二行)是内存的使用情况 |
| Swap | 行(第三行)是交换空间的使用情况 |
| total | 总可用物理内存。一般是总物理内存除去一些预留的和操作系统本身的内存占用,是操作系统可以支配的内存大小。这个在v3.2.8和v3.3.10一样。这个值是/proc/meminfo中MemTotal的值。 |
| used | 列显示已经被使用的物理内存和交换空间。在v3.2.8,这个值是(total - free)得出来的。可以说是系统已经被系统分配,但是实际并不一定正在被真正的使用,其空间可以被回收再分配的。在v3.3.10,这个值是(total - free - cache - buffers)得出来的,是真正目前正在被使用的内存。 |
| free | 系统还未使用的物理内存。这个值是/proc/meminfo中MemFree的值 |
| shared | 共享内存的空间。这个值是/proc/meminfo中Shmem的值 |
| buff/cache | 列显示被 buffer 和 cache 使用的物理内存大小 |
| available | v3.3.10中的项。看起来这个值是可以使用的内存,不过(available + used) < total,也就是available < (free + cache + buffers)。而在v3.2.8中(free + cache + buffers)是一般认为的可用内存,既然在新版本中有这个available数据,应该是更准确的吧。毕竟并不是所有的未使用的内存就一定是可用的。这个值是取的/proc/meminfo中MemAvailable的值,如果meminfo中没有这个值,会依据meminfo中的Active(file),Inactive(file),MemFree,SReclaimable等值计算一个。 |
| -/+ buffers/cache | v3.2.8有这一行,v3.3.10 没有。其中,used 这一项是(used - buffers - cached)的值,即(total - free - buffers - cached)的值,是真正在使用的内存的值。free 这一项是(free + buffers + cached)的值,是真正未使用的内存的值。个人觉得有 -/+ buffers/cache,这一栏看的挺习惯。。不过新版本v3.3.10的used更明确。相信有不少人和我一样,刚看到v3.2.8里面的used占了这么多内存的时候,有点摸不着头脑。 |
二、vmstat 指令
vmstat命令是最常见的Linux/Unix监控工具,用于查看系统的内存存储信息,是一个报告虚拟内存统计信息的小工具,属于sysstat包。
vmstat 命令报告包括:进程、内存、分页、阻塞 IO、中断、磁盘、CPU。
可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
1. 命令格式:
vmstat-s(参数)
2. 举例
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@local:~#vmstat21 procs-----------memory-------------swap-------io-----system------cpu---- rbswpdfreebuffcachesisobiboincsussyidwa 10034984723158363819540000120001000
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如: 这表示vmstat每2秒采集数据,按下ctrl + c结束程序,这里采集了3次数据我就结束了程序。
这表示vmstat每2秒采集数据,按下ctrl + c结束程序,这里采集了3次数据我就结束了程序。
| 类别 | 项目 | 含义 | 说明 |
| Procs(进程) | r | 等待执行的任务数 | 展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
| B | 等待IO的进程数量 | ||
| Memory(内存) | swpd | 正在使用虚拟的内存大小,单位k | |
| free | 空闲内存大小 | ||
| buff | 已用的buff大小,对块设备的读写进行缓冲 | ||
| cache | 已用的cache大小,文件系统的cache | ||
| inact | 非活跃内存大小,即被标明可回收的内存,区别于free和active | 具体含义见:概念补充(当使用-a选项时显示) | |
| active | 活跃的内存大小 | 具体含义见:概念补充(当使用-a选项时显示) | |
| Swap | si | 每秒从交换区写入内存的大小(单位:kb/s) | |
| so | 每秒从内存写到交换区的大小 | ||
| IO | bi | 每秒读取的块数(读磁盘) | 块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
| bo | 每秒写入的块数(写磁盘) | 块设备每秒发送的块数量,单位是block | |
| system | in | 每秒中断数,包括时钟中断 |
这两个值越大,会看到由内核消耗的cpu时间sy会越多 秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 |
| cs | 每秒上下文切换数 | ||
| CPU(以百分比表示) | us | 用户进程执行消耗cpu时间(user time) | us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| sy | 系统进程消耗cpu时间(system time) | sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足 | |
| Id | 空闲时间(包括IO等待时间) | 一般来说 us+sy+id=100 | |
| wa | 等待IO时间 | wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
3. 常见问题处理
常见问题及解决方法
如果r经常大于4,且id经常少于40,表示cpu的负荷很重。
如果pi,po长期不等于0,表示内存不足。
如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
1.如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
2.如果r的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
3.如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺。
当发生以上问题的时候请先调整应用程序对CPU的占用情况.使得应用程序能够更有效的使用CPU.同时可以考虑增加更多的CPU. 关于CPU的使用情况还可以结合mpstat, ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间.一般情况下,应用程序的问题会比较大一些.比如一些sql语句不合理等等都会造成这样的现象.
4. 内存问题现象:
内存的瓶颈是由scan rate (sr)来决定的.scan rate是通过每秒的始终算法来进行页扫描的.如果scan rate(sr)连续的大于每秒200页则表示可能存在内存缺陷.同样的如果page项中的pi和po这两栏表示每秒页面的调入的页数和每秒调出的页数.如果该值经常为非零值,也有可能存在内存的瓶颈,当然,如果个别的时候不为0的话,属于正常的页面调度这个是虚拟内存的主要原理.
解决办法:
1.调节applications & servers使得对内存和cache的使用更加有效.
2.增加系统的内存.
3.Implement priority paging in s in pre solaris 8 versions by adding line "set priority paging=1" in /etc/system. Remove this line if upgrading from Solaris 7 to 8 & retaining old /etc/system file.
关于内存的使用情况还可以结ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的内存的使用情况,和那些进程在占用大量的内存.
一般情况下,如果内存的占用率比较高,但是,CPU的占用很低的时候,可以考虑是有很多的应用程序占用了内存没有释放,但是,并没有占用CPU时间,可以考虑应用程序,对于未占用CPU时间和一些后台的程序,释放内存的占用。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。
这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。
top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
5. 常见性能问题分析
IO/CPU/men连锁反应
1.free急剧下降 2.buff和cache被回收下降,但也无济于事 3.依旧需要使用大量swap交换分区swpd 4.等待进程数,b增多 5.读写IO,bibo增多 6.siso大于0开始从硬盘中读取 7.cpu等待时间用于IO等待,wa增加
内存不足
1.开始使用swpd,swpd不为0 2.siso大于0开始从硬盘中读取
io瓶颈
1.读写IO,bibo增多超过2000 2.cpu等待时间用于IO等待,wa增加超过20 3.sy系统调用时间长,IO操作频繁会导致增加>30% 4.waio等待时间长 iowait%<20% 良好 iowait% <35% 一般 iowait% >50% 5.进一步使用iostat观察
CPU瓶颈:load,vmstat中r列
1.反应为CPU队列长度 2.一段时间内,CPU正在处理和等待CPU处理的进程数之和,直接反应了CPU的使用和申请情况。 3.理想的load average:核数*CPU数*0.7 CPU个数:grep 'physicalid'/proc/cpuinfo|sort-u 核数:grep 'coreid'/proc/cpuinfo|sort-u|wc-l 4.超过这个值就说明已经是CPU瓶颈了
三、/proc/meminfo
用途:用于从/proc文件系统中提取与内存相关的信息。这些文件包含有 系统和内核的内部信息。其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息,只是看起来不太直观。
1. 查看方法:
cat/proc/meminfo
2. 实例及信息解释
peng@ubuntu:~$cat/proc/meminfo MemTotal:2017504kB//所有可用的内存大小, 物理内存减去预留位和内核使用。系统从加电开始到引导完成,firmware/BIOS要预留一 些内存,内核本身要占用一些内存,最后剩下可供内核支配的内存就是MemTotal。这个值 在系统运行期间一般是固定不变的,重启会改变。 MemFree: 511052 kB //表示系统尚未使用的内存。 MemAvailable:640336kB//真正的系统可用内存, 系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可 以回收,所以这部分可回收的内存加上MemFree才是系统可用的内存 Buffers:114348kB//用来给块设备做缓存的内存,(文件系统的metadata、pages) Cached:162264kB//分配给文件缓冲区的内存,例如vi一个文件,就会将未保存的内容写到该缓冲区 SwapCached:3032kB//被高速缓冲存储用的交换空间(硬盘的swap)的大小 Active:555484kB//经常使用的高速缓冲存储器页面文件大小 Inactive:295984kB//不经常使用的高速缓冲存储器文件大小 Active(anon):381020kB//活跃的匿名内存 Inactive(anon):244068kB//不活跃的匿名内存 Active(file):174464kB//活跃的文件使用内存 Inactive(file):51916kB//不活跃的文件使用内存 Unevictable:48kB//不能被释放的内存页 Mlocked:48kB//系统调用mlock SwapTotal:998396kB//交换空间总内存 SwapFree:843916kB//交换空间空闲内存 Dirty:128kB//等待被写回到磁盘的 Writeback:0kB//正在被写回的 AnonPages:572776kB//未映射页的内存/映射到用户空间的非文件页表大小 Mapped:119816kB//映射文件内存 Shmem:50212kB//已经被分配的共享内存 Slab:113700kB//内核数据结构缓存 SReclaimable:68652kB//可收回slab内存 SUnreclaim:45048kB//不可收回slab内存 KernelStack:8812kB//内核消耗的内存 PageTables:27428kB//管理内存分页的索引表的大小 NFS_Unstable:0kB//不稳定页表的大小 Bounce:0kB//在低端内存中分配一个临时buffer作为跳转,把位 于高端内存的缓存数据复制到此处消耗的内存 WritebackTmp:0kB//FUSE用于临时写回缓冲区的内存 CommitLimit:2007148kB//系统实际可分配内存 Committed_AS:3567280kB//系统当前已分配的内存 VmallocTotal:34359738367kB//预留的虚拟内存总量 VmallocUsed:0kB//已经被使用的虚拟内存 VmallocChunk:0kB//可分配的最大的逻辑连续的虚拟内存 HardwareCorrupted:0kB//表示“中毒页面”中的内存量 即hasfailed的内存(通常由ECC标记).ECC代表“纠错码”.ECCmemory能够纠正小错误并检测较大错误; 在具有非ECC内存的典型PC上,内存错误未被检测到.如果使用ECC检测到无法纠正的错误(在内存或缓存中, 具体取决于系统的硬件支持),则Linux内核会将相应的页面标记为中毒. AnonHugePages:0kB//匿名大页 【/proc/meminfo的AnonHugePages==所有进程的/proc//smaps中AnonHugePages之和】 ShmemHugePages:0kB//用于共享内存的大页 ShmemPmdMapped:0kB CmaTotal:0kB//连续内存区管理总量 CmaFree:0kB//连续内存区管理空闲量 HugePages_Total:0//预留HugePages的总个数 HugePages_Free:0//池中尚未分配的HugePages数量, 真正空闲的页数等于HugePages_Free-HugePages_Rsvd HugePages_Rsvd:0//表示池中已经被应用程序分配但尚未使用的HugePages数量 HugePages_Surp:0//这个值得意思是当开始配置了20个大页,现在修改配置为16,那么这个参数就会显示为4,一般不修改配置,这个值都是0 Hugepagesize:2048kB//大内存页的size //指直接映射(directmapping)的内存大小,从代码上来看,值记录管理页表占用的内存,就是描述线性映射空间中,有多个空间分别使用了2M/4K/1G页映射 DirectMap4k:96128kB DirectMap2M:2000896kB DirectMap1G:0kB
注意这个文件显示的单位是kB而不是KB,1kB=1000B,但是实际上应该是KB,1KB=1024B
还可以使用命令 less /proc/meminfo 直接读取该文件。通过使用 less 命令,可以在长长的输出中向上和向下滚动,找到你需要的内容。
从中我们可以很清晰明了的看出内存中的各种指标情况,例如 MemFree的空闲内存和SwapFree中的交换内存。
3. 代码实例
负责输出/proc/meminfo的源代码是:
fs/proc/meminfo.c:meminfo_proc_show()
staticintmeminfo_proc_show(structseq_file*m,void*v)
{
structsysinfoi;
unsignedlongcommitted;
longcached;
longavailable;
unsignedlongpages[NR_LRU_LISTS];
intlru;
si_meminfo(&i);
si_swapinfo(&i);
committed=percpu_counter_read_positive(&vm_committed_as);
cached=global_node_page_state(NR_FILE_PAGES)-
total_swapcache_pages()-i.bufferram;
if(cached< 0)
cached = 0;
for (lru = LRU_BASE; lru < NR_LRU_LISTS; lru++)
pages[lru] = global_node_page_state(NR_LRU_BASE + lru);
available = si_mem_available();
show_val_kb(m, "MemTotal: ", i.totalram);
show_val_kb(m, "MemFree: ", i.freeram);
show_val_kb(m, "MemAvailable: ", available);
show_val_kb(m, "Buffers: ", i.bufferram);
show_val_kb(m, "Cached: ", cached);
show_val_kb(m, "SwapCached: ", total_swapcache_pages());
show_val_kb(m, "Active: ", pages[LRU_ACTIVE_ANON] +
pages[LRU_ACTIVE_FILE]);
show_val_kb(m, "Inactive: ", pages[LRU_INACTIVE_ANON] +
pages[LRU_INACTIVE_FILE]);
show_val_kb(m, "Active(anon): ", pages[LRU_ACTIVE_ANON]);
show_val_kb(m, "Inactive(anon): ", pages[LRU_INACTIVE_ANON]);
show_val_kb(m, "Active(file): ", pages[LRU_ACTIVE_FILE]);
show_val_kb(m, "Inactive(file): ", pages[LRU_INACTIVE_FILE]);
show_val_kb(m, "Unevictable: ", pages[LRU_UNEVICTABLE]);
show_val_kb(m, "Mlocked: ", global_zone_page_state(NR_MLOCK));
#ifdef CONFIG_HIGHMEM
show_val_kb(m, "HighTotal: ", i.totalhigh);
show_val_kb(m, "HighFree: ", i.freehigh);
show_val_kb(m, "LowTotal: ", i.totalram - i.totalhigh);
show_val_kb(m, "LowFree: ", i.freeram - i.freehigh);
#endif
#ifndef CONFIG_MMU
show_val_kb(m, "MmapCopy: ",
(unsigned long)atomic_long_read(&mmap_pages_allocated));
#endif
show_val_kb(m, "SwapTotal: ", i.totalswap);
show_val_kb(m, "SwapFree: ", i.freeswap);
show_val_kb(m, "Dirty: ",
global_node_page_state(NR_FILE_DIRTY));
show_val_kb(m, "Writeback: ",
global_node_page_state(NR_WRITEBACK));
show_val_kb(m, "AnonPages: ",
global_node_page_state(NR_ANON_MAPPED));
show_val_kb(m, "Mapped: ",
global_node_page_state(NR_FILE_MAPPED));
show_val_kb(m, "Shmem: ", i.sharedram);
show_val_kb(m, "Slab: ",
global_node_page_state(NR_SLAB_RECLAIMABLE) +
global_node_page_state(NR_SLAB_UNRECLAIMABLE));
show_val_kb(m, "SReclaimable: ",
global_node_page_state(NR_SLAB_RECLAIMABLE));
show_val_kb(m, "SUnreclaim: ",
global_node_page_state(NR_SLAB_UNRECLAIMABLE));
seq_printf(m, "KernelStack: %8lu kB
",
global_zone_page_state(NR_KERNEL_STACK_KB));
show_val_kb(m, "PageTables: ",
global_zone_page_state(NR_PAGETABLE));
#ifdef CONFIG_QUICKLIST
show_val_kb(m, "Quicklists: ", quicklist_total_size());
#endif
show_val_kb(m, "NFS_Unstable: ",
global_node_page_state(NR_UNSTABLE_NFS));
show_val_kb(m, "Bounce: ",
global_zone_page_state(NR_BOUNCE));
show_val_kb(m, "WritebackTmp: ",
global_node_page_state(NR_WRITEBACK_TEMP));
show_val_kb(m, "CommitLimit: ", vm_commit_limit());
show_val_kb(m, "Committed_AS: ", committed);
seq_printf(m, "VmallocTotal: %8lu kB
",
(unsigned long)VMALLOC_TOTAL >>10);
show_val_kb(m,"VmallocUsed:",0ul);
show_val_kb(m,"VmallocChunk:",0ul);
#ifdefCONFIG_MEMORY_FAILURE
seq_printf(m,"HardwareCorrupted:%5lukB
",
atomic_long_read(&num_poisoned_pages)<< (PAGE_SHIFT - 10));
#endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
show_val_kb(m, "AnonHugePages: ",
global_node_page_state(NR_ANON_THPS) * HPAGE_PMD_NR);
show_val_kb(m, "ShmemHugePages: ",
global_node_page_state(NR_SHMEM_THPS) * HPAGE_PMD_NR);
show_val_kb(m, "ShmemPmdMapped: ",
global_node_page_state(NR_SHMEM_PMDMAPPED) * HPAGE_PMD_NR);
#endif
#ifdef CONFIG_CMA
show_val_kb(m, "CmaTotal: ", totalcma_pages);
show_val_kb(m, "CmaFree: ",
global_zone_page_state(NR_FREE_CMA_PAGES));
#endif
hugetlb_report_meminfo(m);
arch_report_meminfo(m);
return 0;
}
四、top 指令
用途:用于打印系统中的CPU和内存使用情况。输出结果中,可以很清晰的看出已用和可用内存的资源情况。top 最好的地方之一就是发现可能已经失控的服务的进程 ID 号(PID)。有了这些 PID,你可以对有问题的任务进行故障排除(或 kill)。
语法
top[-][ddelay][q][c][S][s][i][n][b]
参数说明:
d:改变显示的更新速度,或是在交谈式指令列(interactivecommand)按s q:没有任何延迟的显示速度,如果使用者是有superuser的权限,则top将会以最高的优先序执行 c:切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称 S:累积模式,会将己完成或消失的子进程(deadchildprocess)的CPUtime累积起来 s:安全模式,将交谈式指令取消,避免潜在的危机 i:不显示任何闲置(idle)或无用(zombie)的进程 n:更新的次数,完成后将会退出top b:批次档模式,搭配"n"参数一起使用,可以用来将top的结果输出到档案内
举例
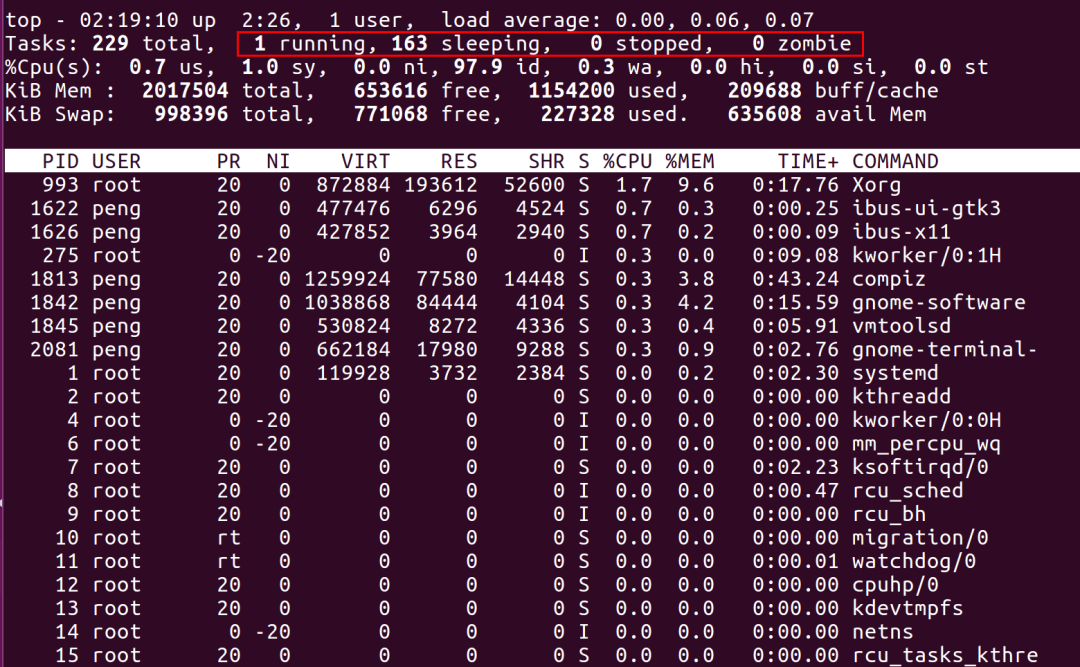 第一行,任务队列信息,同 uptime 命令的执行结果
第一行,任务队列信息,同 uptime 命令的执行结果
系统时间:0210运行时间:up 2:26 min,当前登录用户:1 user负载均衡(uptime) load average: 0.00, 0.06, 0.07average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
第二行,Tasks — 任务(进程)
总进程:229 total, 运行:1 running, 休眠:163 sleeping, 停止: 0 stopped, 僵尸进程: 0 zombie
第三行,cpu状态信息
0.7%us【user space】— 用户空间占用CPU的百分比。1.0%sy【sysctl】— 内核空间占用CPU的百分比。0.0%ni【】— 改变过优先级的进程占用CPU的百分比97.9%id【idolt】— 空闲CPU百分比0.3%wa【wait】— IO等待占用CPU的百分比0.0%hi【Hardware IRQ】— 硬中断占用CPU的百分比0.0%si【Software Interrupts】— 软中断占用CPU的百分比
第四行,内存状态
2017504 total, 653616 free, 1154200 used, 209688 buff/cache【缓存的内存量】
第五行,swap交换分区信息
998396 total, 771068 free, 227328 used. 635608 avail Mem
第七行以下:各进程(任务)的状态监控
PID — 进程idUSER — 进程所有者PR — 进程优先级NI — nice值。负值表示高优先级,正值表示低优先级VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR — 共享内存大小,单位kbS —进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU — 上次更新到现在的CPU时间占用百分比%MEM — 进程使用的物理内存百分比TIME+ — 进程使用的CPU时间总计,单位1/100秒COMMAND — 进程名称(命令名/命令行)
常用实例
显示进程信息
#top
显示完整命令
#top-c
以批处理模式显示程序信息
#top-b
以累积模式显示程序信息
#top-S
设置信息更新次数
top-n2
//表示更新两次后终止更新显示
设置信息更新时间
#top-d3
//表示更新周期为3秒
显示指定的进程信息
#top-p139
//显示进程号为139的进程信息,CPU、内存占用率等
显示更新十次后退出
top-n10
五、htop 指令
htop 它类似于 top 命令,但可以让你在垂直和水平方向上滚动,所以你可以看到系统上运行的所有进程,以及他们完整的命令行。
可以不用输入进程的 PID 就可以对此进程进行相关的操作 (killing, renicing)。
htop快照: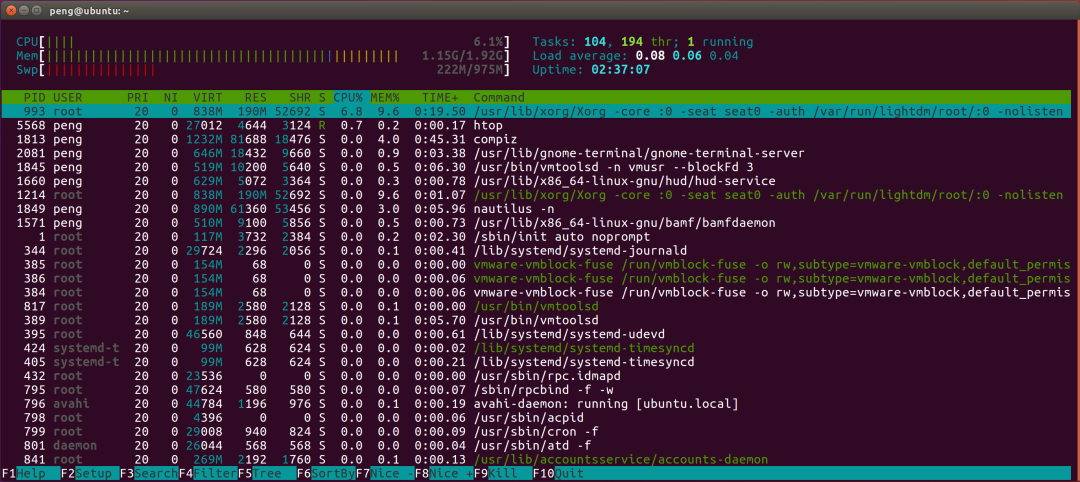 可以使用快捷键
可以使用快捷键
F1,h,?:查看htop使用说明, F2,s:设置选项 F3,/:搜索进程 F4,:过滤器,输入关键字搜索 F5,t:显示属性结构 F6,<,>:选择排序方式 F7,[,:减少进程的优先级(nice) F8,]:增加进程的优先级(nice) F9,k:杀掉选中的进程 F10,q:退出htop u:显示所有用户,并可以选中某一特定用户的进程 U:取消标记所有的进程
第1行-第4行:显示CPU当前的运行负载,有几核就有几行,我的是1核
Mem:显示内存的使用情况,3887M大概是3.8G,此时的Mem不包含buffers和cached的内存,所以和free -m会不同Swp:显示交换空间的使用情况,交换空间是当内存不够和其中有一些长期不用的数据时,ubuntu会把这些暂时放到交换空间中
其他信息可以参考top命令说明。
PS:如果你终端没安装 htop,先通过指令来安装。sudo apt-get updatesudo apt install htop
六、查看制定进程的内存
通过/proc/procid/status查看进程内存
peng@ubuntu:~$cat/proc/4398/status Name:kworker/0:0//进程名 Umask:0000 State:I(idle)//进程的状态 //R(running)","S(sleeping)","D(disksleep)","T(stopped)","T(tracingstop)","Z(zombie)",or"X(dead)" Tgid:4398//线程组的ID,一个线程一定属于一个线程组(进程组). Ngid:0 Pid:4398//进程的ID,更准确的说应该是线程的ID. PPid:2//当前进程的父进程 TracerPid:0//跟踪当前进程的进程ID,如果是0,表示没有跟踪 Uid:0000 Gid:0000 FDSize:64//当前分配的文件描述符,该值不是上限,如果打开文件超过64个文件描述符,将以64进行递增 Groups://启动这个进程的用户所在的组 NStgid:4398 NSpid:4398 NSpgid:0 NSsid:0 Threads:1 SigQ:0/7640 SigPnd:0000000000000000 ShdPnd:0000000000000000 SigBlk:0000000000000000 SigIgn:ffffffffffffffff SigCgt:0000000000000000 CapInh:0000000000000000 CapPrm:0000003fffffffff CapEff:0000003fffffffff CapBnd:0000003fffffffff CapAmb:0000000000000000 NoNewPrivs:0 Seccomp:0 Speculation_Store_Bypass:vulnerable Cpus_allowed:00000000,00000000,00000000,00000001 Cpus_allowed_list:0 Mems_allowed:00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001 Mems_allowed_list:0 voluntary_ctxt_switches:5 nonvoluntary_ctxt_switches:0
总结:
确定内存使用情况是Linux运维工程师必要的技能,尤其是某个应用程序变得异常和占用系统内存时。当发生这种情况时,知道有多种工具可以帮助你进行故障排除十分方便的。
-
Linux
+关注
关注
87文章
11342浏览量
210287 -
服务器
+关注
关注
12文章
9295浏览量
85983 -
内存
+关注
关注
8文章
3052浏览量
74268
原文标题:Linux内存占用分析的几个方法
文章出处:【微信号:strongerHuang,微信公众号:strongerHuang】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Linux的内存管理是什么,Linux的内存管理详解
查看Linux系统内存使用情况的几种方法
Linux 查看内存插槽数、最大容量和频率
Linux的CPU和内存占用率查看
Linux基础教程之Linux查看磁盘挂载有哪些方法详细方法概述
如何查看Linux中的ip地址






 工商网监
工商网监
评论