 在InnoDB如何选择从LRU_list
在InnoDB如何选择从LRU_list
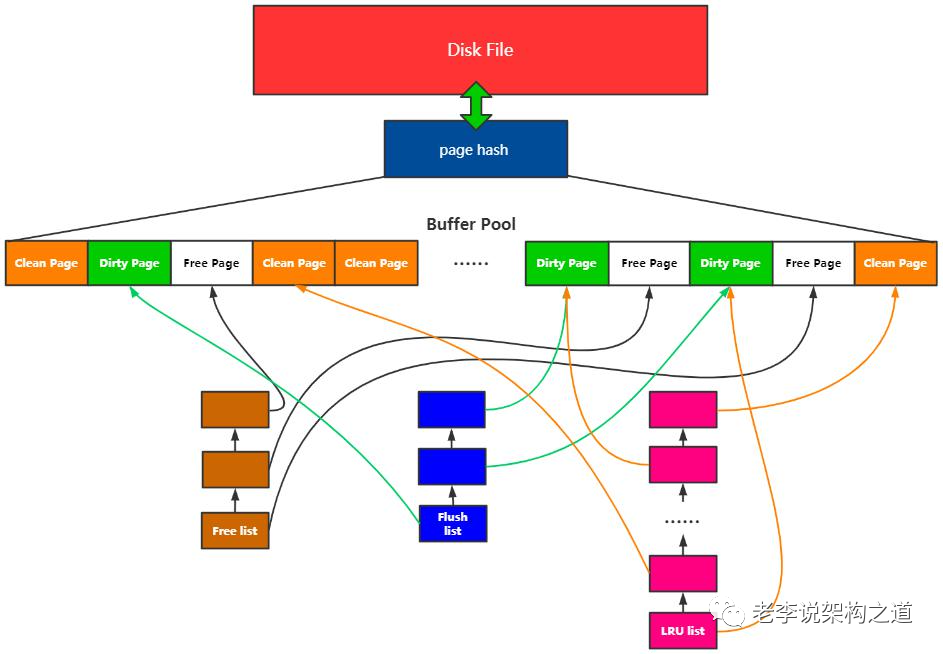
在InnoDB 如何选择从LRU_list 刷脏还是从flush_list 刷脏, 本质问题就是page replacement policies
fast path: 从LRU_list 刷脏, 依据的是哪些page 最老被访问过来排序, 由于有些 page 没有被修改过, 那么释放page 可以无需IO, 可以快速获得free page. 但是也有page 被修改, 那么就需要进行IO 了.
slow path: 从flush list 刷脏, 是按照 oldest_modification lsn来排序, 并且flush list 上面的page 都是脏页, 获得free page 必须进行一次IO, 但是刷脏下去以后checkpoint 就可以推进, redo 空间就可以释放, crash recovery 就更快.
另外由于page 的newest_modification lsn 有可能一直在涨, 需要等到redo log log_write_up_to lsn 以后该page 才可以刷下去, 具体函数 buf_flush_write_block_low() 里面, 因此对比LRU list 上刷脏获得free page 肯定慢很多.
page 从flush_list 上面刷脏以后是不会从lru list 上面删除, 也就不会释放, 需要等下一次lru list 刷脏的时候再进行释放.
所以InnoDB 是完全按照lru list 的顺序去获得free page, 但是不是按照lru list 的顺序进行刷脏.
我理解官方单一线程刷flush list 和 lru list 问题是把获得free page 和刷脏操作放在同一个线程中执行了, 导致在刷脏任务比较重的时候无法获得free page
buffer pool 对IO 优化很重要的一个作用是写入聚合, 对一个Page 多次修改合并成一个IO 写入. 所以对于系统而言保留一定的脏页率对性能是有收益的.
理论上如果只有不考虑redo log checkpoint 及时推进, 那么最好的推进策略一定是在LRU list 上面一直刷脏, 因为这样才充分发挥buffer pool IO 聚合以及LRU 策略.
我们提出一个足够简单的模型.
如果写入redo 速度不变, 那么生成page 速度不变, 如果刷脏能力极其快, 那么理论上LRU_scan_depth 的深度设置成用户每秒最大的page IO 生成能力即可, 那么系统最好的状态 page dirty pct = (buffer pool size - LRU_scan_depth page) / buffer pool size
进一步添加约束, 刷脏能力不如生成page 速度, 那么随着用户的写入脏页的百分比肯定最后会100%, 所以这个时候必然需要限制用户的写入速度, 使得 page 生成速度 < 刷脏速度, 那么脏页才可以稳定下来.
在dirty_page_pct < trigger_slow_user_written 的情况下, 不阻止用户写入
在dirty_page_pct > trigger_slow_user_written 的情况下, 那么需要阻止用户写入了.
trigger_slow_user_written 设置的越低, 那么越早开始阻止用户的写入, 那么能够容忍偶尔用户写入峰值的时间越长.
进一步增加flush list 的考虑, 考虑从flush list 上面刷脏其实降低刷脏能力.
比如redo 写入10MB, 生成page 100MB, 如果修改的是完全不同page, 也就是buffer pool 没有起到IO 聚合作用, 那么刷flush list 和 lru list 是一样的, 但是实际因为有可能有些page 是重复修改, 理论上LRU list 上刷脏效率> flush list 刷脏效率.
所以在引入了flush list 以后, 考虑的策略是:
在dirty_page_pct < trigger_flush_list 的情况下, 应该完全从lru list 上面刷脏
在dirty_page_pct > trigger_flush_list 的情况下, 那么优先从flush list 上面刷脏了
在dirty_page_pct > trigger_slow_user_written 的情况下, 那么需要阻止用户写入了.
那么增加考虑flush list 以后, 实际刷脏策略是 lru list + flush list, 实际刷脏效率进一步降低, 那么就需要更早的对用户的写入进行阻止.
在PolarDB 上, 由于需要考虑ro 节点尽可能可以将parse buffer 让出, 会触发rw 节点尽快刷脏, 降低了buffer pool IO聚合作用, 那么会进一步降低了刷脏的效率.
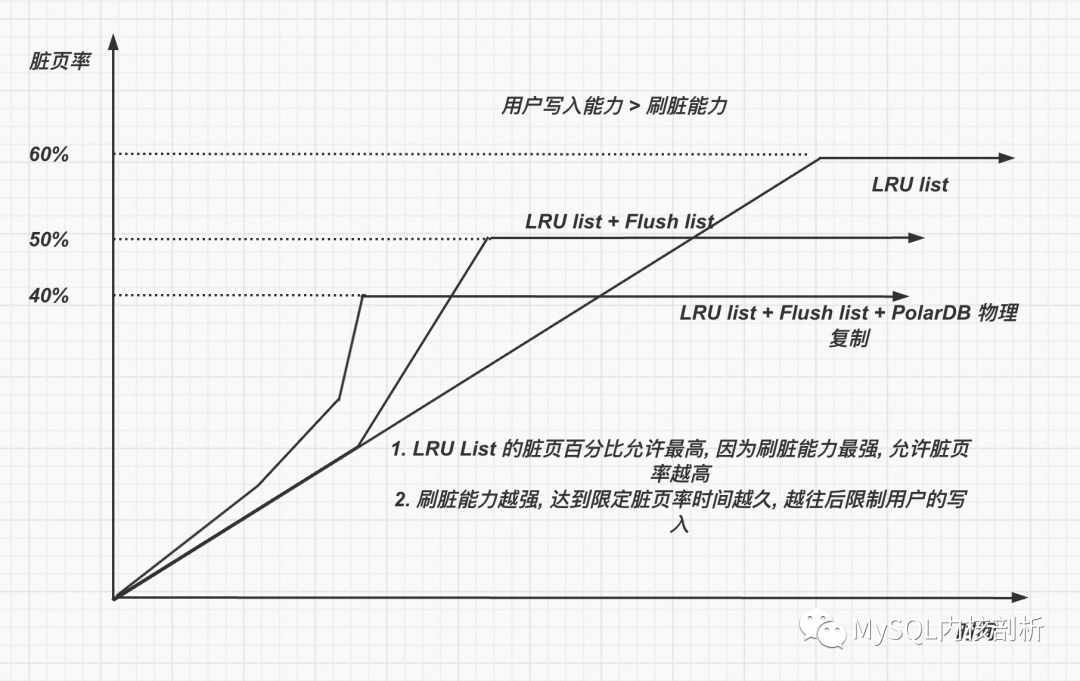
那么这里脏页率多少合适触发阻止用户写入呢?
触发trigger_slow_user_writtern 还需要考虑用户需要使用free page 场景. 如果脏页百分比特别低, 那么容易在LRU list 上获得free page, 如果脏页百分比高, 那么就不容易获得free page.
在我们上述的模型里面只考虑到了用户的写入和刷脏之间的关系, 并没有考虑到在有一定脏页比例的情况, 用户读取请求如何获得 free page 的问题.
如果没有合理实现, 那么用户请求读取的时候需要遍历大量dirty page 才可以找到空闲页, 影响用户访问性能.
另外这里为了找free page 性能, 也不能把dirty_page_pct 设置的过高.
这里的topic 是, 在有一定脏页的情况下, 如何合理组织page 使得能够高效获得free page.
目前InnoDB 的做法是:
分两种情况:
-
在系统正常运行的过程中, 后台page cleaner 线程不断通过 buf_flush_LRU_list_batch() 函数对LRU list 上面old page 进行回收, 添加到free list 里面.
-
在用户发现free list 没有free page 以后, 通过buf_LRU_get_free_block() 主动从LRU list 上面获取free page
还有一个问题: 用户线程从LRU_list 上获得free page 需要持有LRU_list_mutex, 但是后台的page cleaner 线程也同样需要持有LRU_list_mutex 进行清理操作, 这里就会有一个争抢.
并且 LRU_list 释放block 的过程并不是一直持有LRU_list_mutex, 是对于每一个block 而言, 持有LRU_list_mutex, 释放 mutex, 进行具体的IO 操作, IO操作完又加上LRU_list_mutex.
为什么这样操作, 而不是一直持有LRU_list_mutex 释放完指定number block 以后, 再释放LRU_list_mutex?
这样的话用户线程就获得不到LRU_list_mutex 了, 那么就会导致用户请求卡主, 但是这里用户请求大部分是从free list 上面获得page, 只有free page 上面没有page 的时候才会从LRU_list 上面去获得page.
具体代码 buf_page_free_stale => buf_LRU_free_page() 在进行IO 操作之前, 释放 LRU_list_mutex, 结束之后退出buf_page_free_stale() 重新加LRU_list_mutex.
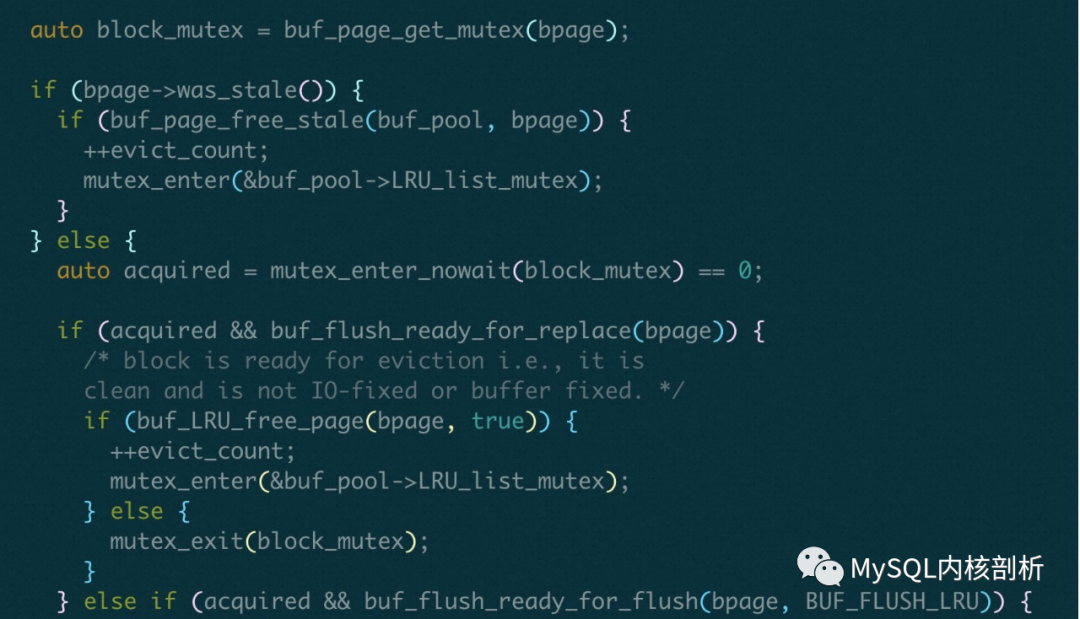
另外, 这里尝试释放某一个block 的时候是用mutex_enter_nowait(pthread_mutex_trylock), 不会去等待, 也就是如果某一个page_block 被别人使用, 是不会去释放这个block 的. 也可以理解, 这个mutex被人持有, 那么大概率这个block 正在使用, 那么可能又是一个新的page 了, 不需要被释放
1. buf_flush_LRU_list_batch()
后台对LRU_list 的批量刷脏只会只会扫描 srv_LRU_scan_depth 深度, 在LRU list 末尾 srv_LRU_scan_depth 长度内, 遇到的page 如果是dirty page, 那么就执行 buf_flush_page_and_try_neighbors() 进行刷脏操作, 如果是non-dirty page, 那么就直接踢除就可以.
如果page non-dirty page, 在buf_flush_ready_for_replace() 函数中进行判断, 然后执行 buf_LRU_free_page() 逻辑
这里判断一个page 是否能够被replace, 也就是被释放的方法
如果这个page 是被写过, 那么oldest_modification == 0, 表示这个page已经被flush 到磁盘了.
bpage->buf_fix_count 表示的是记录这个bpage 被引用次数, 每次访问bpage,都对引用计数buf_fix_count + 1, 释放的时候 -1. 也就是这个bpage 没有其他人访问以后,才可以被replace
并且这个page 的io_fix 状态是 BUF_IO_NONE, 表示的是page 要从LRU list 中删除, 在page 用完以后, 都会设置成 BUF_IO_NONE.如果是BUF_IO_READ, BUF_IO_WRITE 表示的是这个page 要从底下文件中读取或者写入, 肯定还在使用, 所以不能被replace
如果可以replace, 则执行 buf_LRU_free_page()
如果page 是dirty page, 在 buf_flush_ready_for_flush() 中判断, 最后执行buf_flush_page() 逻辑.
这个page 的oldest_modification != 0, 表示这个page 肯定已经被修改过了, 并且 io_fix == NONE, 不然这个page 可能正要被read/write
如果可以flush, 则执行 buf_flush_page()
这里扫描LRU list 末尾 srv_LRU_scan_depth长度, 如果末尾的page 都是dirty page, 那么获取free page 就不够高效.
2. 具体用户请求获得free page 的策略方法在函数 buf_LRU_get_free_block() 中. 具体策略
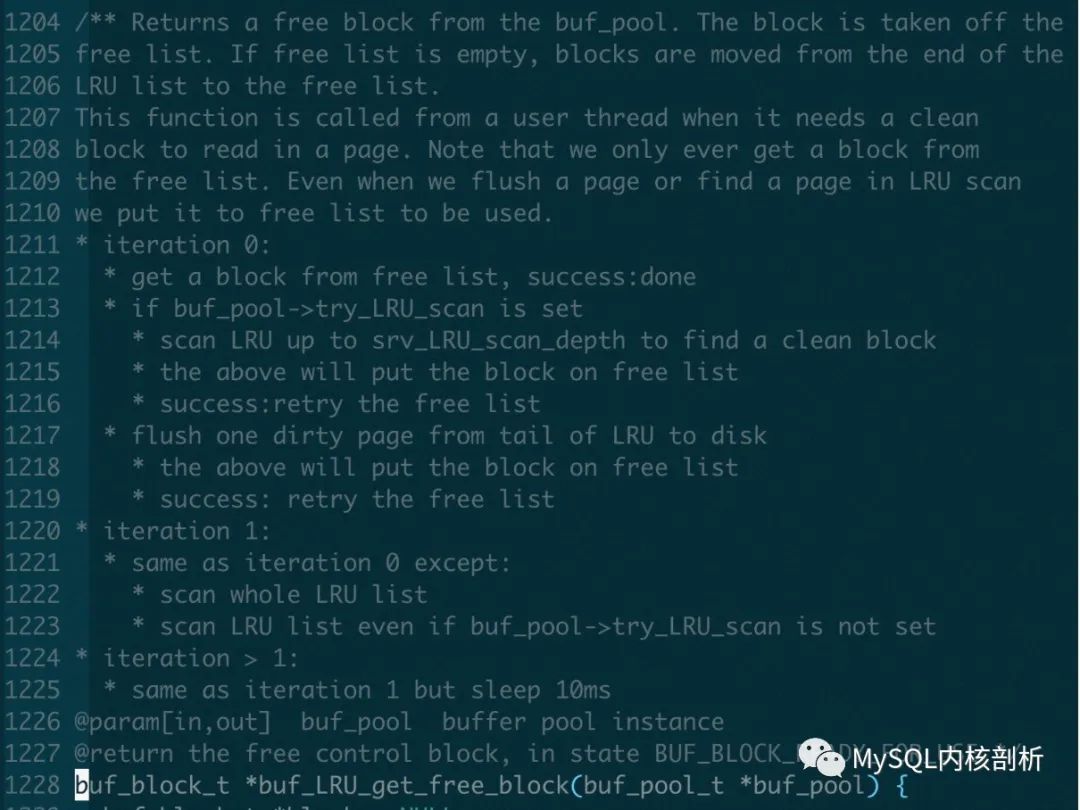
和page cleaner 刷脏区别的地方在于 第2次scan 的时候会扫描整个LRU list 去获得free page, 在第2次scan 以后, 会sleep 10ms, 并且超过20次以后会打印没有free page 信息.
为什么不直接从LRU list 上面拿出一个被modify 并且未执行flush 的page 执行flush 呢?
因为在LRU list 上是按照access_time 排序的, 所有有可能page 被修改以后, 又有读, 因为这个page 被排在了很前面. 但是有可能这个page 很早被修改, 但是一直没有读, 反而排在了后面了, 因此从flush_list 里面找page 进行flush 是更靠谱的, 保证flush 的是最早修改过的page
那么什么时候会从flush_list 上面去执行flush page 操作呢?
在系统正常运行的过程中, 就不断会有page clean 线程对page 执行 flush 操作, 这样可以触发用户从LRU list 里面找page 的时候, 只需要replace 操作, 不需要flush single page 操作, 因为flush single page 操作如果触发, 对用户的请求性能影响很大.
所以在page cleaner thread 执行flush 操作以后, 在写IO 完成以后, 是否会把page 同时从flush_list, LRU list 同时删除, 还是只是将oldest_modification lsn 设置成0 就可以了?
这里分两种场景考虑:
-
如果这个page 是从flush_list 上面写IO 完成, 那么就不需要从flush_list上面删除, 因为从flush list 上面删除要完成的操作是刷脏,既然只是为了刷脏, 那么就没必要让他从lru list 上面删除, 有可能这个page 被刷脏了, 还是一个热page 是需要访问的
-
如果这个page 是从lru_list 上面写IO 完成, 那就需要从lru list 上面删除
原因: 从lru_list 上面删除的page 肯定说明这个page 不是hot page 了,更大的原因可能是buffer pool 空间不够, 需要从lru list 上面淘汰一些page了, 既然这些page 是要从lru list 上面淘汰的, 那么肯定就需要从LRU list 上面移除
具体代码在buf_page_io_complete() 中
Q&A
另外在刷脏里面最大的一个问题是InnoDB 刷脏过程是需要持有page sx lock, 有两个地方导致可能持有page latch 时间过长
-
进行刷脏的时候有可能page newest_modification lsn 比较大, 那么刷脏的时候需要等redo log 已经写入到 log_write_up_to 到这个lsn 才可以, 那么加锁的时间就大大加长了
-
进行刷脏的时候持有latch 的时间是加入到simulated AIO 队列就算上了, 因此整体持有latch 的时间是 在simulated AIO 上等待的时间 + IO 时间
通过Single Page flush 或者通过用户Thread wait LRU manager thread 获得空闲Page区别?
通过Single Page flush 或者通过用户Thread wait LRU manager thread 获得空闲Page, 解决的都是在脏页百分比较高情况下, 获得free page 的工程上的方法, 只不过Single page flush 在用户线程比较多的情况下, 非常多个用户线程去抢占同一个LRU list mutex, 而通过wait LRU manager thread 的方法, 因为thread number 有限, 不会有过多的线程抢占同一个LRU list mutex, 所以在工程上会更好一些.
但是其实用户用Single Page flush 和引入不引入LRU manager thread 其实是无关的.
审核编辑 :李倩
-
磁盘
+关注
关注
1文章
380浏览量
25261 -
模型
+关注
关注
1文章
3298浏览量
49184 -
线程
+关注
关注
0文章
505浏览量
19747
原文标题:InnoDB page replacement policies
文章出处:【微信号:inf_storage,微信公众号:数据库和存储】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
LRU缓存模块最佳实践
Redis的LRU实现和应用
基于修正LRU的压缩Cache替换策略
关于InnoDB的内存结构及原理详解
innodb究竟是如何存数据的
MySQL5.6 InnoDB支持全文检索
剖析MySQL InnoDB存储原理(下)
详细总结下InnoDB存储引擎中行锁的加锁规则
什么是list?
设计并实现一个满足LRU约束的数据结构
redis的lru原理
关于LRU(Least Recently Used)的逻辑实现






 工商网监
工商网监
评论