 GLIGEN在开放世界泛化方面的有效性
GLIGEN在开放世界泛化方面的有效性

CVPR 2023:GLIGEN: Open-Set Grounded Text-to-Image Generation
1. 论文信息
论文题目:GLIGEN: Open-Set Grounded Text-to-Image Generation
作者:Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao,Chunyuan Li, Yong Jae Lee
论文链接:https://arxiv.org/abs/2301.07093
代码地址:https://github.com/gligen/GLIGEN
2. 引言
首先介绍一下open-set Grounded Text2Img Generation,它是一个框架,它可以根据文本描述和定位指令生成图像。定位指令提供有关图像的附加信息,例如边界框、深度图、语义地图等。所提出的框架可以在不同类型的定位指令上进行训练,例如检测数据、检测+字幕数据和定位数据。该模型在COCO2014数据集上进行评估,同时在图像质量和定位准确性方面均取得了最先进的性能。本文的一个限制是,虽然到目前为止的描述集中于使用文本作为实体e和边界框作为l(本文的主要setting),但是提出的定位指导是以一般形式表示的。然而,提出的框架可以扩展到其他定位条件。
如何做到这些呢?近年来,图像生成研究取得了巨大进展。过去几年,GANs是最先进的技术,其latent space和conditional inputs已经得到了深入研究,以实现可控的修改和生成。文本条件自回归和扩散模型已经展示出惊人的图像质量和概念覆盖,这是由于它们更稳定的学习目标和基于网络图像-文本对数据的大规模训练所致。这些模型甚至引起了公众的关注,因为它们具有实用的用例(例如艺术设计和创作)。尽管取得了令人兴奋的进展,但现有的大规模文本到图像生成模型不能以除文本之外的其他输入模态为条件,因此缺乏精确定位概念、使用参考图像或其他条件输入来控制生成过程的能力。目前的输入,即仅限自然语言,限制了信息表达的方式。例如,使用文本描述一个物体的精确位置是困难的,而边界框/关键点可以很容易地实现这一点。虽然存在以其他输入模态进行修复、布局到图像生成等的条件扩散模型和GANs,但它们很少将这些输入组合起来进行可控的文本到图像生成。
此外,先前的生成模型(不论生成模型家族)通常是在每个任务特定的数据集上独立训练的。相比之下,在识别领域,长期以来的范例是以在大规模图像数据或图像-文本对上预训练的基础模型为起点构建识别模型。由于扩散模型已经在数十亿个图像-文本对上进行了训练,自然而然的问题是:我们能否在现有预训练的扩散模型基础上构建新的条件输入模态?通过这种方式,类似于识别文献,由于预训练模型已经具有丰富的概念知识,我们可能能够在其他生成任务上实现更好的性能,同时获得对现有文本到图像生成模型的更多可控性。
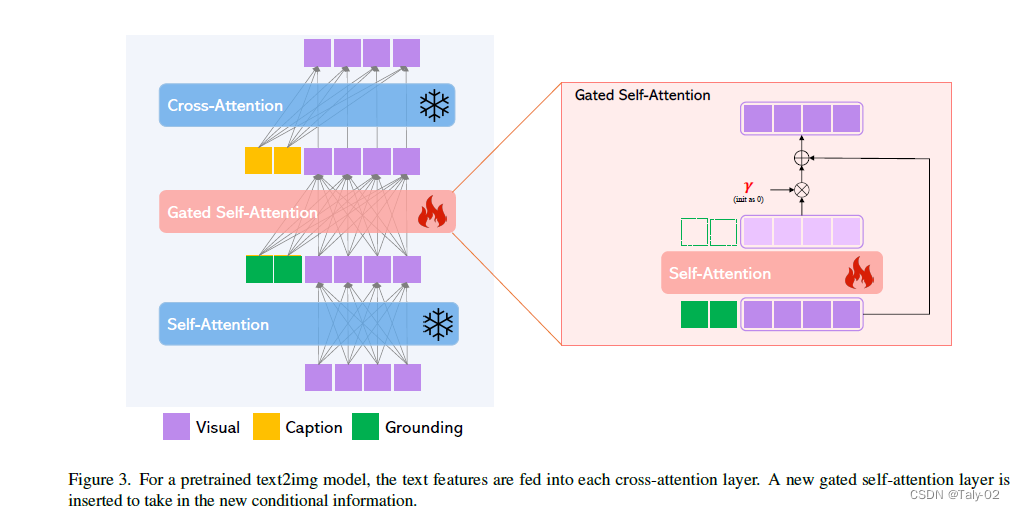
基于上述目标,我们提出了一种方法,为预训练的文本到图像扩散模型提供新的基础条件输入。我们仍然保留文本标题作为输入,但还启用其他输入模态,如边界框用于定位概念、引用图像用于定位、部分关键点定位等。关键挑战是在学习注入新的定位信息的同时保留预训练模型的原始丰富概念知识。为了防止知识遗忘,我们建议冻结原始模型权重,并添加新的可训练门控Transformer层,以接收新的定位输入(例如边界框)。在训练期间,我们逐渐使用门控机制将新的定位信息融合到预训练模型中。这种设计可在生成过程中实现灵活性,以提高质量和可控性;例如,我们展示了在前半部分采用全模型(所有层)进行采样步骤,而在后半部分仅使用原始层(不包括门控Transformer层)可以导致生成结果准确反映基础条件,同时具有高品质图像。
3. 方法
3.1 Grounding Instruction Input
定位指令输入是提供有关图像的信息的附加输入,例如边界框、深度图、语义地图等。该输入表示为一系列定位tokens,其中每个tokens对应于特定类型的定位信息。定位指令输入包括以下步骤:
从输入序列中提取定位tokens。
将每个tokens映射到其对应的定位信息。
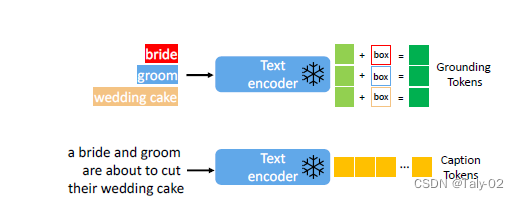
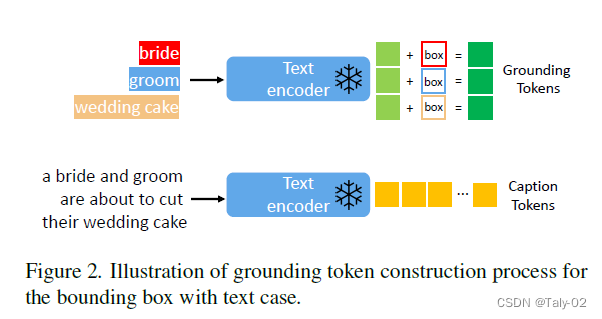
对于每个使用边界框表示的定位文本实体,我们将位置信息表示为l = [αmin, βmin, αmax, βmax],其中包含其左上角和右下角坐标。对于文本实体e,我们使用相同的预训练文本编码器来获取其文本特征ftext(e)(图2中的浅绿色标记),然后将其与其边界框信息融合以生成定位令tokens:
而keypoints相较于bounding box有什么特点呢?keypoints比bounding box的泛化能力要差,因为关键点表示物体的部分,在不同类别之间不能总是共享。另一方面,边界框仅指定图像中物体的粗略位置和大小,并可以跨所有对象类别共享。这意味着,虽然关键点比边界框提供了更细粒度的控制,但它们的泛化能力较差。本文的作者还提到,他们测试了人类学习的关键点定位信息是否可以转移到其他非人型类别,如猫或灯,用于关键点定位生成,但他们发现即使使用了计划采样,他们的模型在这些情况下也会遇到困难。
从Closed-set转换成Open-set:相较于open set的方法,现有的这种close-set环境下的布局到图像生成方法仅适用于封闭集设置,限制了模型推广到新实体的能力,也缺乏语言指令的语义结构。提出的定位指令采用通用形式,可以扩展到其他定位条件,例如图像提示、关键点和空间对齐条件。图像提示可以用于描述更抽象和精细的概念,而关键点和空间对齐条件则提供了更细粒度的可控性。而如图所示,采用了UNet的结构,其可以通过将条件映射输入到第一个卷积层中来加速。
3.2 Continual Learning for Grounded Generation
基于连续学习的定位生成是一种方法,使生成模型能够从新的定位信息中学习而不会忘记以前学习的信息。基于连续学习的定位生成的步骤包括:
在大型图像和captioning数据集上预训练生成模型。
在包含额外定位信息的较小图像和captioning数据集上fine-tuning模型。
使用回放缓冲区存储之前学习的信息,并在学习新的定位信息时使用它来防止遗忘。
使用连续学习方法训练模型,平衡学习新信息的重要性和保留以前学习的信息。
使用生成模型将文本描述与提取的定位信息相结合生成最终图像。
为了加快推理过程中的节奏,本文还提出了一种新的迭代模式,Scheduled Samplin。Scheduled Samplin是GLIGEN模型中使用的一种技术,通过设置一个称为beta的参数来安排推理时间的采样,其中beta可以设置为1(使用额外的定位信息)或0(降低到原始预训练扩散模型)。这允许模型在不同阶段利用不同的知识。通过将tau设置为0.2,可以使用计划采样来改善图像质量,并扩展模型以生成具有类似人形形状的其他对象。
计划采样的主要好处是提高了视觉效果的质量,因为粗略的概念位置和轮廓在早期阶段被确定,后续阶段则是细节的精细化处理。它还可以让我们将在一个领域(人类关键点)训练的模型扩展到其他领域(猴子卡通人物),如图1所示。
4. 实验
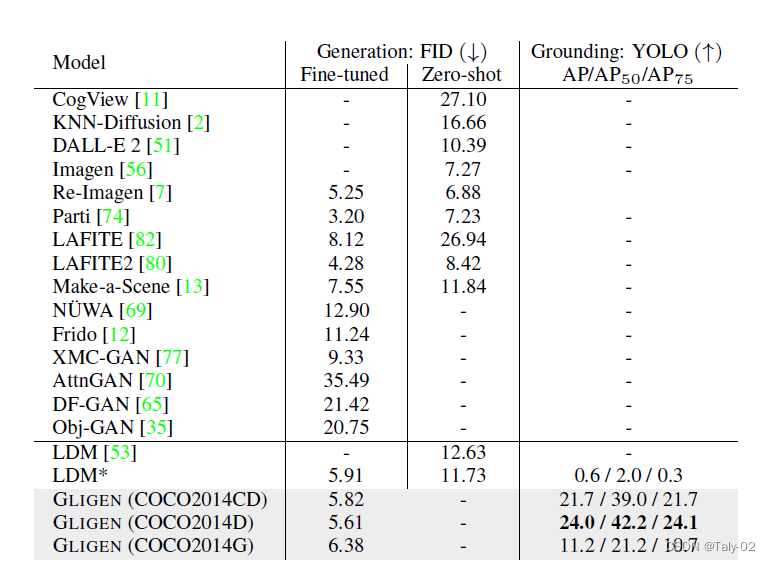
这段突出显示的文本呈现了表格1,该表格显示了在COCO2014验证集上图像质量和布局对应性的评估结果。表格中的数字来自相应的论文,是在COCO数据集上进行微调的模型。GLIGEN是建立在之上的模型。COCO2014数据集是文本到图像生成领域中使用的标准基准,用于在封闭集设置中评估模型的生成质量和定位准确性。评估不同类型的定位指令以查看它们对模型性能的影响。比较的指标就是Inception Score(IS)、Fréchet Inception Distance(FID)和Layout Distance Metric(LDM)这些常用的生成模型客观性评价指标。IS衡量生成图像的质量,FID衡量生成图像与真实图像的相似性,而LDM衡量生成的图像与给定布局的对应性。然后比较了使用COCO2014数据集的不同论文的结果,例如StackGAN++、AttnGAN和DM-GAN。这些论文对上述指标得分的表现不同。是在COCO数据集上进行微调的模型,它的得分比原始的LDM模型更好。GLIGEN是建立在L.DM之上的模型,它的得分比表格中提到的其他模型都要好。可见本文提出方法的有效性。
结合实验来看,本文提出的方法,在性能和泛化性上,都有特别出彩的点。
5. 讨论
本文的贡献在于提出了一种新的文本到图像生成方法GLIGEN,它赋予了现有的文本到图像扩散模型新的定位可控性。该模型使用边界框输入实现了开放世界的定位文本到图像生成,即合成训练中未观察到的新的局部概念。该模型在布局到图像任务的零样本表现显著优于之前的最新技术水平,展示了在大型预训练生成模型的基础上进行下游任务建模的强大能力。本文总结认为,GLIGEN是推进文本到图像合成领域和扩展预训练模型在各种应用中能力的有前途的方向。
本文的一个limitation是,所提出的GLIGEN模型需要大量的训练数据才能实现良好的性能。另一个限制是,模型的性能高度依赖于提供的定位信息的质量。此外,模型生成具有细节的图像的能力也受到限制。作者建议未来的工作重点应该放在改进模型处理复杂定位信息和生成更逼真、更详细图像的能力上。
6. 结论
GLIGEN是本文提出的一种方法,用于扩展预训练的文本到图像扩散模型的定位能力。该方法使用边界框、关键点、参考图像和空间对齐条件(例如边缘图、深度图等)来从文本描述生成图像。该模型使用多层感知机来提取定位信息,并将其与文本描述相结合生成最终图像。基于连续学习的定位生成被用于允许模型从新的定位信息中学习而不会忘记以前学习的信息。作者展示了GLIGEN在开放世界泛化方面的有效性,并表明它可以轻松扩展到其他定位条件。本文总结认为,GLIGEN是推进文本到图像合成领域和扩展预训练模型在各种应用中能力的有前途的方向。
-
LDM
+关注
关注
0文章
6浏览量
10799 -
模型
+关注
关注
1文章
3865浏览量
52324 -
数据集
+关注
关注
4文章
1242浏览量
26286
原文标题:论文解读 Open-Set Grounded Text-to-Image Generation
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
1553B总线产品有效性测试(VTP)平台
CS的有效性可以改编?
ATPG有效性是什么意思
特征选择在减少预测推理时间方面的有效性展示
高斯混合模型对乳腺癌诊断的有效性初探
如何检查Oracle数据库备份文件是否有效?备份文件有效性检测系统设计资料概述
什么是欺诈证明和有效性证明
PLC冗余系统的可行性和有效性分析

adc采集的电压值数值如何真有效性转换?
如何验证硬件冗余设计的有效性?




评论