 如何使用triton的language api来实现gemm的算子
如何使用triton的language api来实现gemm的算子
前言
通过前两章对于triton的简单介绍,相信大家已经能够通过从源码来安装triton,同时通过triton提供的language前端写出自己想要的一些计算密集型算子。这章开始,我们通过构建一套比较标准的batch gemm的benchmark,来看看目前这些主流的代码生成工具,高性能模板库,与厂商提供的vendor library的差距。因为只有明确了目前的差距,后期关于针对性的优化才能做到点上。这一章,我将使用一个batch的gemm作为例子,来看看triton目前对其的优化能力。选batch gemm的原因是因为目前的LLM中不可避免会有对应的attention操作,而attention操作中,核心的计算密集型算子就是batch的gemm,如果你能够对batch的gemm有一个很好的优化思路,那么在MLSys中大部分的算子优化类的工作对你来说将不会显得那么无从下手。
通过Triton实现一个batch GEMM算子
在triton的官方tutorial中给出了如何使用triton的language api来实现gemm的算子,在上一章的最后,我也给出了对应的例子以及他通过和调用torch.matmul实现的gemm在3090上的性能比较。最终可以发现,针对某些size的gemm,triton在TFLOPS这个指标层面是能够超过cublas的实现,但是后面我通过nsight system对每个kernel的具体执行时间进行了profiling,发现在torch.matmul或者torch.bmm底层所调用的cuBLAS的kernel并不是对应输入输出datatype以及computetype中最快的那个。所以,这样的比较就显得有些没有意义。不过,没事,这对我们建立起如何优化一个计算密集型算子来说是一个不错的入门。
其实想要通过triton实现一个batch的gemm非常简单,我们只需要将triton中原先例子里的tl.program_id(axis=0),在这个program_id上再添加一个axis来表示batch维度的并行就可以了,然后针对每个数组的变化由单batch到多batch,只用增加一个大小为矩阵size的stride偏置即可,这种实现方式其实也是cuBLAS中cublasGemmStridedBatched命名的得来。具体的代码如下所示:
@triton.jit defmatmul_kernel( #Pointerstomatrices A_ptr,B_ptr,C_ptr, #Matrixdimensions B,M,N,K, #Thestridevariablesrepresenthowmuchtoincreasetheptrbywhenmovingby1 #elementinaparticulardimension.E.g.stride_amishowmuchtoincreasea_ptr #bytogettheelementonerowdown(AhasMrows) stride_ab,stride_am,stride_ak, stride_bb,stride_bk,stride_bn, stride_cb,stride_cm,stride_cn, #Meta-parameters BLOCK_SIZE_M:tl.constexpr,BLOCK_SIZE_N:tl.constexpr,BLOCK_SIZE_K:tl.constexpr, GROUP_SIZE_M:tl.constexpr, ACTIVATION:tl.constexpr, ): pid=tl.program_id(axis=0) offs_b=tl.program_id(axis=1) num_pid_m=tl.cdiv(M,BLOCK_SIZE_M) num_pid_n=tl.cdiv(N,BLOCK_SIZE_N) num_pid_k=tl.cdiv(K,BLOCK_SIZE_K) num_pid_in_group=GROUP_SIZE_M*num_pid_n group_id=pid//num_pid_in_group first_pid_m=group_id*GROUP_SIZE_M group_size_m=min(num_pid_m-first_pid_m,GROUP_SIZE_M) pid_m=first_pid_m+(pid%group_size_m) pid_n=(pid%num_pid_in_group)//group_size_m offs_m=pid_m*BLOCK_SIZE_M+tl.arange(0,BLOCK_SIZE_M) offs_n=pid_n*BLOCK_SIZE_N+tl.arange(0,BLOCK_SIZE_N) offs_k=tl.arange(0,BLOCK_SIZE_K) A_ptr=A_ptr+(offs_b*stride_ab+offs_m[:,None]*stride_am+offs_k[None,:]*stride_ak) B_ptr=B_ptr+(offs_b*stride_bb+offs_k[:,None]*stride_bk+offs_n[None,:]*stride_bn) #initializeanditerativelyupdateaccumulator acc=tl.zeros((BLOCK_SIZE_M,BLOCK_SIZE_N),dtype=tl.float32) forkinrange(0,K,BLOCK_SIZE_K): a=tl.load(A_ptr) b=tl.load(B_ptr) acc+=tl.dot(a,b) A_ptr+=BLOCK_SIZE_K*stride_ak B_ptr+=BLOCK_SIZE_K*stride_bk c=acc.to(tl.float16) C_ptr=C_ptr+(offs_b*stride_cb+offs_m[:,None]*stride_cm+offs_n[None,:]*stride_cn) c_mask=(offs_b< B) & (offs_m[:, None] < M) & (offs_n[None, :] < N) tl.store(C_ptr, c, mask=c_mask)
然后写一个简单的单元测试,确保通过triton写出来的kernel能够和torch.matmul/torch.bmm对上即可。
torch.manual_seed(0)
a=torch.randn((4,512,512),device='cuda',dtype=torch.float16)
b=torch.randn((4,512,512),device='cuda',dtype=torch.float16)
torch_output=torch.bmm(a,b)
triton_output=matmul(a,b,activation=None)
print(f"triton_output={triton_output}")
print(f"torch_output={torch_output}")
iftorch.allclose(triton_output,torch_output,atol=1e-2,rtol=0):
print("TritonandTorchmatch")
else:
print("TritonandTorchdiffer")
其实triton的language语法确实很简单,相比较cuda来说,它能够帮我们快速验证一些idea,同时给出比cublas性能相当的算子。如果你想要用CUDA从0开始实现一个batch GEMM并且调用tensor core,借助shared memory,register files去帮你加速运算或者优化data movement,那么这个过程是非常需要一定的高性能计算和架构的经验,你才可能拿到和cuBLAS的kernel接近的性能。OK,有了triton的具体kernel实现,接下来其实就是要去写一个triton需要被调优的模版,需要triton从你定义的这个比较小的搜索空间中,去得到对应的最优解,从而作为本次batch gemm的最优实现,我在autotuner这块并没有花太大的精力去改进,依旧GEMM例子中的模版拿来作为一个参考,具体代码如下:
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':256,'BLOCK_SIZE_K':64,'GROUP_SIZE_M':8},num_stages=3,num_warps=8),
triton.Config({'BLOCK_SIZE_M':64,'BLOCK_SIZE_N':256,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4),
triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':128,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4),
triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':64,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4),
triton.Config({'BLOCK_SIZE_M':64,'BLOCK_SIZE_N':128,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4),
triton.Config({'BLOCK_SIZE_M':128,'BLOCK_SIZE_N':32,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=4,num_warps=4),
triton.Config({'BLOCK_SIZE_M':64,'BLOCK_SIZE_N':32,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=5,num_warps=2),
triton.Config({'BLOCK_SIZE_M':32,'BLOCK_SIZE_N':64,'BLOCK_SIZE_K':32,'GROUP_SIZE_M':8},num_stages=5,num_warps=2),
],
key=['M','N','K'],
)
然后通过调用Triton的do_bench就可以将你写的算子跑起来了,do_bench处在python/triton/testing.py下,其中会对每个kernel进行25次的warm_up和100次iteration,最后会根据你设置的分位数得到一个相对稳定的性能。切记,在测试每个kernel的运行情况的时候,需要将GPU的频率锁在最高频,通过下面的代码就可以做到,由于我用到的A10,A10最大频率在1695 MHz
sudonvidia-smi--lock-gpu-clocks=1695,1695
这是通过对fp16的输入,acc_type = fp32,最终输出为fp16的batch gemm (16x4096x4096, 16x4096x4096)
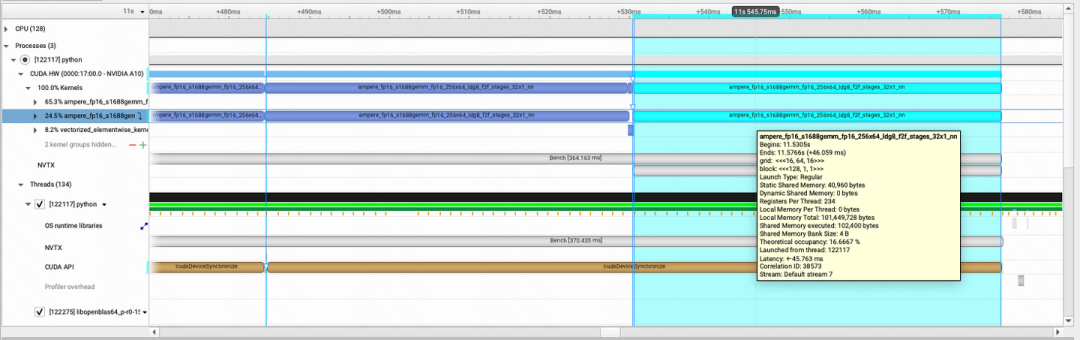
通过nsight system + nvtx就可以看到每个kernel的具体实现情况:
 img
img
添加图片注释,不超过 140 字(可选)
使用torch.bmm/torch.matmul来实现batch-gemm,其中调用的kernel名字为ampere_fp16_s1688gemm_fp16_256x64_Idg8_f2f_stages_32x1_nn,该kernel运行的时间是46.059ms
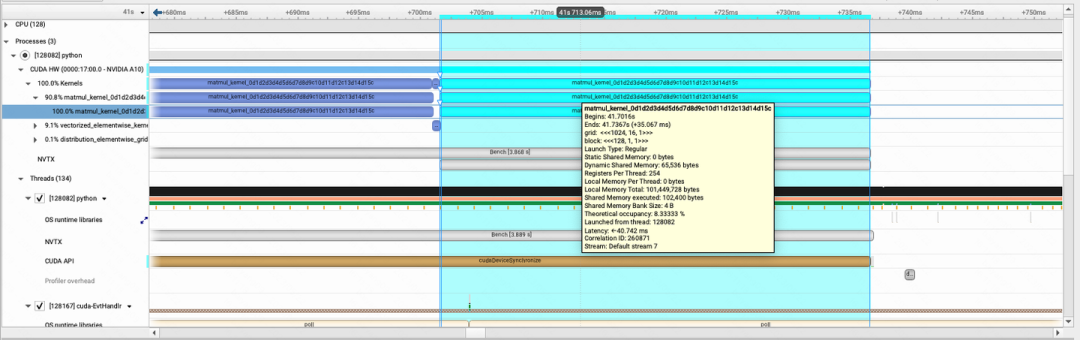
那么,当我们运行triton的时候,通过同样的方式来得到同样迭代次序的kernel,nsight分析如下
 img
img
该kernel的名字为matmul_kernel_0d1d2d3d4d5d6d7d8d9c10d11d12c13d14d15c,运行时间为35.067ms
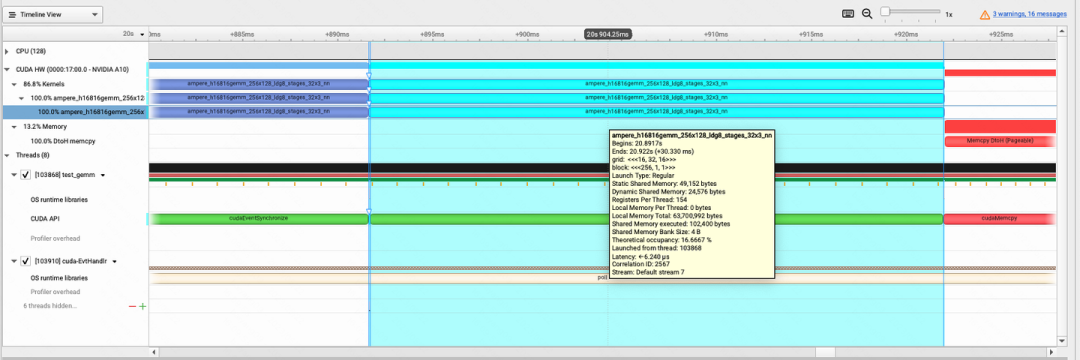
当然通过torch.matmul调用的cuBLAS这个算子,显然不是我们想要的那个,我们就需要去深入到cuBLAS的具体文档,翻一翻,找出其最快的API。在后面的benchmark中,我选用了cublasHgemmStridedBatched和cublasGemmStrideBatchedEx这两个API来分别实现batch GEMM。通过cublasHgemmStridedBatched启动kernel名字为ampere_h16816gemm_256x128_Idg8_stages_32x3_nn,其运行时间为30.330ms
 img
img
通过cuBLAS的cublasGemmStridedBatchedEx API构建算子性能标准
在cuBLAS中,针对batch gemm的实现有很多种方式,我也踩了不少坑。第一次调用成了cublasHgemmStridedBatched,该kernel的性能其实是不如cublasGemmStridedBatchedEx,因为cublasGemmStridedBatchedEx给了一个cublasGemmAlgo_t algo的参数,该参数可以帮我们选择对应batch gemm的不同实现,关于algo又具有如下这么多种:
CUBLAS_GEMM_DEFAULT, CUBLAS_GEMM_ALGO0, CUBLAS_GEMM_ALGO1, CUBLAS_GEMM_ALGO2, CUBLAS_GEMM_ALGO3, CUBLAS_GEMM_ALGO4, CUBLAS_GEMM_ALGO5, CUBLAS_GEMM_ALGO6, CUBLAS_GEMM_ALGO7, CUBLAS_GEMM_ALGO8, CUBLAS_GEMM_ALGO9, CUBLAS_GEMM_ALGO10, CUBLAS_GEMM_ALGO11, CUBLAS_GEMM_ALGO12, CUBLAS_GEMM_ALGO13, CUBLAS_GEMM_ALGO14, CUBLAS_GEMM_ALGO15, CUBLAS_GEMM_ALGO16, CUBLAS_GEMM_ALGO17, CUBLAS_GEMM_DFALT_TENSOR_OP, CUBLAS_GEMM_ALGO0_TENSOR_OP, CUBLAS_GEMM_ALGO1_TENSOR_OP, CUBLAS_GEMM_ALGO2_TENSOR_OP, CUBLAS_GEMM_ALGO3_TENSOR_OP, CUBLAS_GEMM_ALGO4_TENSOR_OP, CUBLAS_GEMM_ALGO18, CUBLAS_GEMM_ALGO19, CUBLAS_GEMM_ALGO20, CUBLAS_GEMM_ALGO21, CUBLAS_GEMM_ALGO22, CUBLAS_GEMM_ALGO23, CUBLAS_GEMM_ALGO5_TENSOR_OP, CUBLAS_GEMM_ALGO6_TENSOR_OP, CUBLAS_GEMM_ALGO7_TENSOR_OP, CUBLAS_GEMM_ALGO8_TENSOR_OP, CUBLAS_GEMM_ALGO9_TENSOR_OP, CUBLAS_GEMM_ALGO10_TENSOR_OP, CUBLAS_GEMM_ALGO11_TENSOR_OP, CUBLAS_GEMM_ALGO12_TENSOR_OP, CUBLAS_GEMM_ALGO13_TENSOR_OP, CUBLAS_GEMM_ALGO14_TENSOR_OP, CUBLAS_GEMM_ALGO15_TENSOR_OP,
其中,带有_TENSOR_OP后缀的则为调用tensor core来加速运算的。看到这么多种实现,不要慌,通过一个for-loop的遍历,就可以方便的找到速度最快的那一个,然后对应就可以得到TFLOPS,对应实现如下:
floatmin_time=0xffff;
cublasGemmAlgo_talgo_index;
for(constauto&algo:algoList){
floattotal_time=0.0;
for(inti=0;i< iteration; i++) {
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start, 0);
cublasGemmStridedBatchedEx(
handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k, &alpha, d_a, CUDA_R_16F, k,
m * k, d_b, CUDA_R_16F, n, k * n, &beta, d_c, CUDA_R_16F, n, m * n,
batch_count, CUDA_R_16F, static_cast(algo));
cudaEventRecord(end,0);
cudaEventSynchronize(end);
floatelapsed_time;
cudaEventElapsedTime(&elapsed_time,start,end);
total_time+=elapsed_time;
}
floatcurrent_time=total_time/iteration;
std::cout<< "algo:" << algo << " " << current_time << " ms" << std::endl;
if( current_time < min_time ) {
min_time = current_time;
algo_index = algo;
}
}
std::cout << "best:" << algo_index << " " << min_time << " ms" << std::endl;
通过CUTLASS实现batch GEMM算子
CUTLASS这里就不花过多的篇幅进行介绍了,知乎上有很多比较详细的文章,建议做GPU性能优化的同学都能够好好研究下CUTLASS,不得不说,CUTLASS的抽象层级做的确实很好,通过暴露出对应的C++模版,就可以通过这些模版组合成很多工程开发实际中可以跑的很快的算子,而且相比于直接写CUDA嵌入PTX的汇编来说,开发的难易程度也被很大程度的降低,同时能带来和cuBLAS肩比肩的效果。在本次benchmark的构建中,我使用的是2.9.1版本的CUTLASS,在编译的时候一定要打开所有的kernel,然后通过下面的命令进行配置:
1.gitclonehttps://github.com/NVIDIA/cutlass.git 2.gitcheckoutv2.9.1 3.exportCUDACXX=/usr/local/cuda/bin/nvcc 4.mkdirbuild&&cdbuild 5.cmake..-DCUTLASS_NVCC_ARCHS=80-DCUTLASS_LIBRARY_KERNELS=all 6.makecutlass_profiler-j16
然后我们可以通过使用cutlass_profiler来找到目前CUTLASS中针对应尺寸算子的TFLOPS最优的那个实现。这里直接使用如下代码就可以得到CUTLASS对应的实现,同时只要在对应的workload添加不同尺寸的GEMM。
Triton, CUTLASS, cuBLAS性能对比
通过上述的讲解,我们将所有的输入和计算过程与cublasGemmStridedBatchedEx中的参数对齐,输入为fp16,输出为fp16,Accumulator_type也改为fp16。在triton中需要将如下代码进行替换:
#acc=tl.zeros((BLOCK_SIZE_M,BLOCK_SIZE_N),dtype=tl.float32) acc=tl.zeros((BLOCK_SIZE_M,BLOCK_SIZE_N),dtype=tl.float16) #acc+=tl.dot(a,b) acc+=tl.dot(a,b,out_dtype=tl.float16)
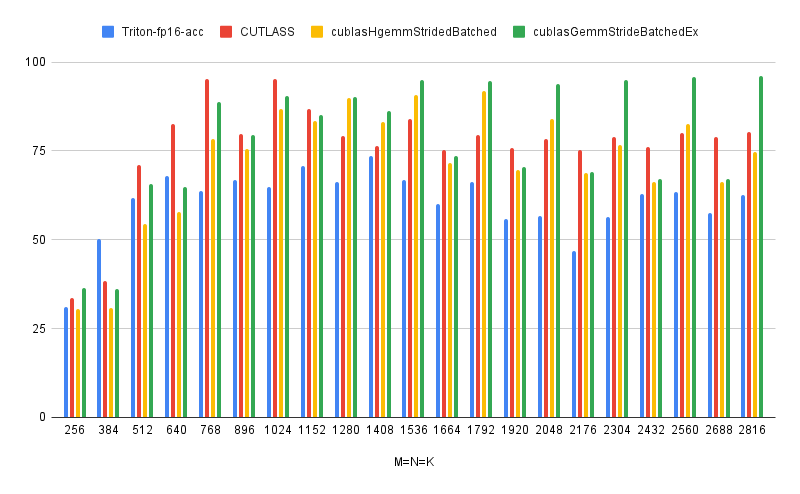
然后把他们全部画出来,纵坐标表示的TFLOPS,横坐标对应矩阵的shape,batch=16。我们可以看出来,目前我这个版本的tirton代码其实性能并不是很好,原因有很多,这个后面我给大家慢慢分析,最重要的其实就是triton.autotune中那些参数的选取和设定,以及后端的一些优化。cublasGemmStridedBatchedEx中最快的那个algo可以看出来目前基本上占据了领先位置,也就是为什么会被称为目前GPU上去做计算密集型算子优化的上届,CUTLASS在某些尺寸上的batch gemm还是表现的很优秀的,但是距离最快的cublasGemmStridedBatchedEx仍然有一些差距,不过只能说CUTLASS的优化真的牛逼,至少我知道目前国内很多HPC的组在开发对应的kernel的时候,都是选择直接魔改拼接CUTLASS的组件来加快整个开发流程。
 img
img
总结
通过上述对batch gemm性能的分析,我们可以看出来triton距离cuBLAS的性能还有一定的距离要走,在后续的教程中,我们将结合Triton Dialect, TritonGPU Dialect, 以及Triton中autotuner作为核心组件来对Triton的所有优化过程中有一个清晰的认识。以及通过编译手段,一步一步来逼近cuBLAS的性能,甚至超越他。
-
gpu
+关注
关注
28文章
4742浏览量
128968 -
源码
+关注
关注
8文章
642浏览量
29226 -
Triton
+关注
关注
0文章
28浏览量
7041 -
算子
+关注
关注
0文章
16浏览量
7261
原文标题:【连载】OpenAITriton MLIR 第二章 Batch GEMM benchmark
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
LOG算子在FPGA中的实现
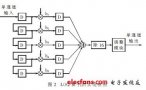
Laplacian算子的FPGA实现方法
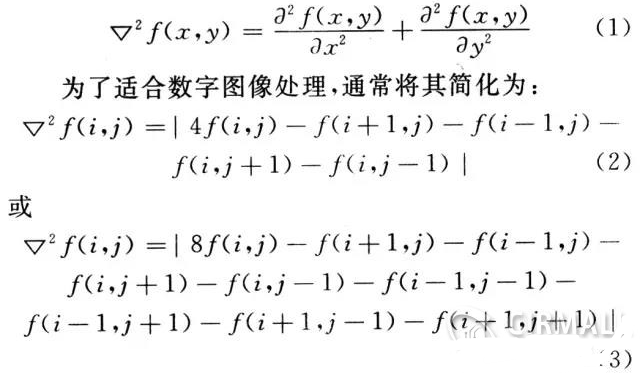
使用CUTLASS实现高性能矩阵乘法
Laplacian算子的硬件实现及结果
Sobel算子原理介绍与实现方法
如何通过ApiFox来构建API场景测试
NVIDIA Triton系列文章:开发资源说明
解析OneFlow Element-Wise算子实现方法

什么是Triton-shared?Triton-shared的安装和使用





 工商网监
工商网监
评论