 如何调优MyBatis 25倍性能
如何调优MyBatis 25倍性能

- 粗略的实验
- 最后
最近在压测一批接口,发现接口处理速度慢的有点超出预期,感觉很奇怪,后面定位发现是数据库批量保存这块很慢。
这个项目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。
我点进去看了下源码,感觉有点不太对劲:
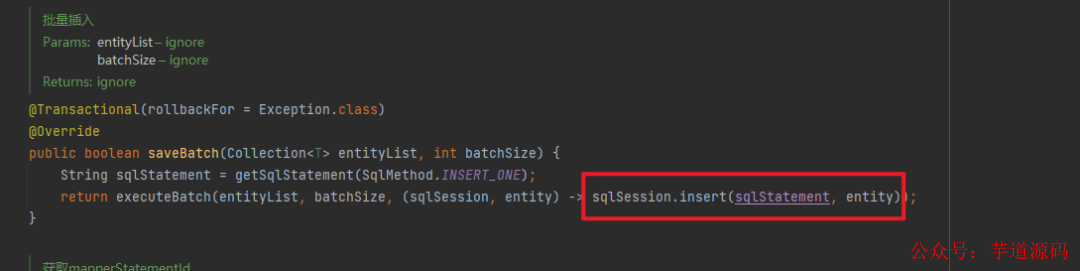
我继续追踪了下,从这个代码来看,确实是 for 循环一条一条执行了 sqlSession.insert,下面的 consumer 执行的就是上面的 sqlSession.insert:
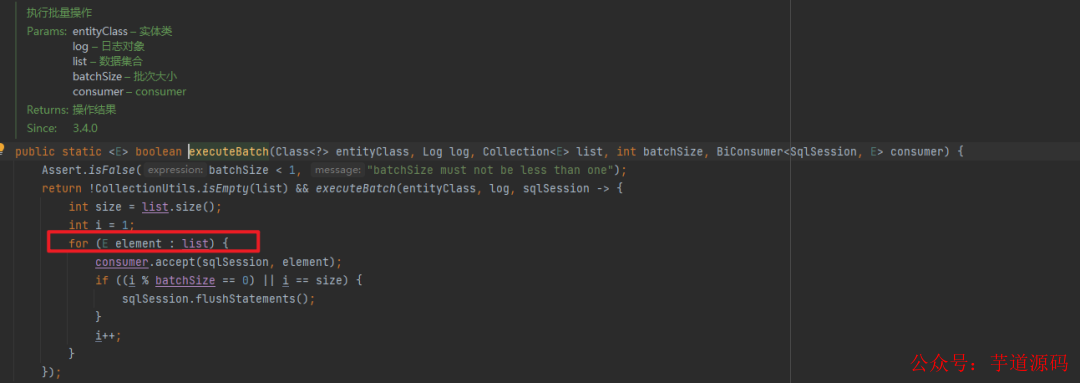
然后累计一定数量后,一批 flush。
从这点来看,这个 saveBach 的性能肯定比直接一条一条 insert 快。
我直接进行一个粗略的实验,简单创建了一张表来对比一波!
粗略的实验
1000条数据,一条一条插入
@Test
voidMybatisPlusSaveOne(){
SqlSessionsqlSession=sqlSessionFactory.openSession();
try{
StopWatchstopWatch=newStopWatch();
stopWatch.start("mybatisplussaveone");
for(inti=0;i< 1000;i++){
OpenTestopenTest=newOpenTest();
openTest.setA("a"+i);
openTest.setB("b"+i);
openTest.setC("c"+i);
openTest.setD("d"+i);
openTest.setE("e"+i);
openTest.setF("f"+i);
openTest.setG("g"+i);
openTest.setH("h"+i);
openTest.setI("i"+i);
openTest.setJ("j"+i);
openTest.setK("k"+i);
//一条一条插入
openTestService.save(openTest);
}
sqlSession.commit();
stopWatch.stop();
log.info("mybatis plus save one:"+stopWatch.getTotalTimeMillis());
}finally{
sqlSession.close();
}
}

可以看到,执行一批 1000 条数的批量保存,耗费的时间是 121011 毫秒。
1000条数据用 mybatis-plus 自带的 saveBatch 插入
@Test
voidMybatisPlusSaveBatch(){
SqlSessionsqlSession=sqlSessionFactory.openSession();
try{
ListopenTestList=newArrayList<>();
for(inti=0;i< 1000;i++){
OpenTestopenTest=newOpenTest();
openTest.setA("a"+i);
openTest.setB("b"+i);
openTest.setC("c"+i);
openTest.setD("d"+i);
openTest.setE("e"+i);
openTest.setF("f"+i);
openTest.setG("g"+i);
openTest.setH("h"+i);
openTest.setI("i"+i);
openTest.setJ("j"+i);
openTest.setK("k"+i);
openTestList.add(openTest);
}
StopWatchstopWatch=newStopWatch();
stopWatch.start("mybatisplussavebatch");
//批量插入
openTestService.saveBatch(openTestList);
sqlSession.commit();
stopWatch.stop();
log.info("mybatis plus save batch:"+stopWatch.getTotalTimeMillis());
}finally{
sqlSession.close();
}
}

耗费的时间是 59927 毫秒,比一条一条插入快了一倍,从这点来看,效率还是可以的。
然后常见的还有一种利用拼接 sql 方式来实现批量插入,我们也来对比试试看性能如何。
1000条数据用手动拼接 sql 方式插入
搞个手动拼接:
 来跑跑下性能如何:
来跑跑下性能如何:
@Test
voidMapperSaveBatch(){
SqlSessionsqlSession=sqlSessionFactory.openSession();
try{
ListopenTestList=newArrayList<>();
for(inti=0;i< 1000;i++){
OpenTestopenTest=newOpenTest();
openTest.setA("a"+i);
openTest.setB("b"+i);
openTest.setC("c"+i);
openTest.setD("d"+i);
openTest.setE("e"+i);
openTest.setF("f"+i);
openTest.setG("g"+i);
openTest.setH("h"+i);
openTest.setI("i"+i);
openTest.setJ("j"+i);
openTest.setK("k"+i);
openTestList.add(openTest);
}
StopWatchstopWatch=newStopWatch();
stopWatch.start("mappersavebatch");
//手动拼接批量插入
openTestMapper.saveBatch(openTestList);
sqlSession.commit();
stopWatch.stop();
log.info("mapper save batch:"+stopWatch.getTotalTimeMillis());
}finally{
sqlSession.close();
}
}

耗时只有 2275 毫秒,性能比 mybatis-plus 自带的 saveBatch 好了 26 倍!
这时,我又突然回想起以前直接用 JDBC 批量保存的接口,那都到这份上了,顺带也跑跑看!
1000条数据用 JDBC executeBatch 插入
@Test
voidJDBCSaveBatch()throwsSQLException{
SqlSessionsqlSession=sqlSessionFactory.openSession();
Connectionconnection=sqlSession.getConnection();
connection.setAutoCommit(false);
Stringsql="insertintoopen_test(a,b,c,d,e,f,g,h,i,j,k)values(?,?,?,?,?,?,?,?,?,?,?)";
PreparedStatementstatement=connection.prepareStatement(sql);
try{
for(inti=0;i< 1000;i++){
statement.setString(1,"a"+i);
statement.setString(2,"b"+i);
statement.setString(3,"c"+i);
statement.setString(4,"d"+i);
statement.setString(5,"e"+i);
statement.setString(6,"f"+i);
statement.setString(7,"g"+i);
statement.setString(8,"h"+i);
statement.setString(9,"i"+i);
statement.setString(10,"j"+i);
statement.setString(11,"k"+i);
statement.addBatch();
}
StopWatchstopWatch=newStopWatch();
stopWatch.start("JDBCsavebatch");
statement.executeBatch();
connection.commit();
stopWatch.stop();
log.info("JDBC save batch:"+stopWatch.getTotalTimeMillis());
}finally{
statement.close();
sqlSession.close();
}
}

耗时是 55663 毫秒,所以 JDBC executeBatch 的性能跟 mybatis-plus 的 saveBatch 一样(底层一样)。
综上所述,拼接 sql 的方式实现批量保存效率最佳。
但是我又不太甘心,总感觉应该有什么别的法子,然后我就继续跟着 mybatis-plus 的源码 debug 了一下,跟到了 mysql 的驱动,突然发现有个 if 里面的条件有点显眼:
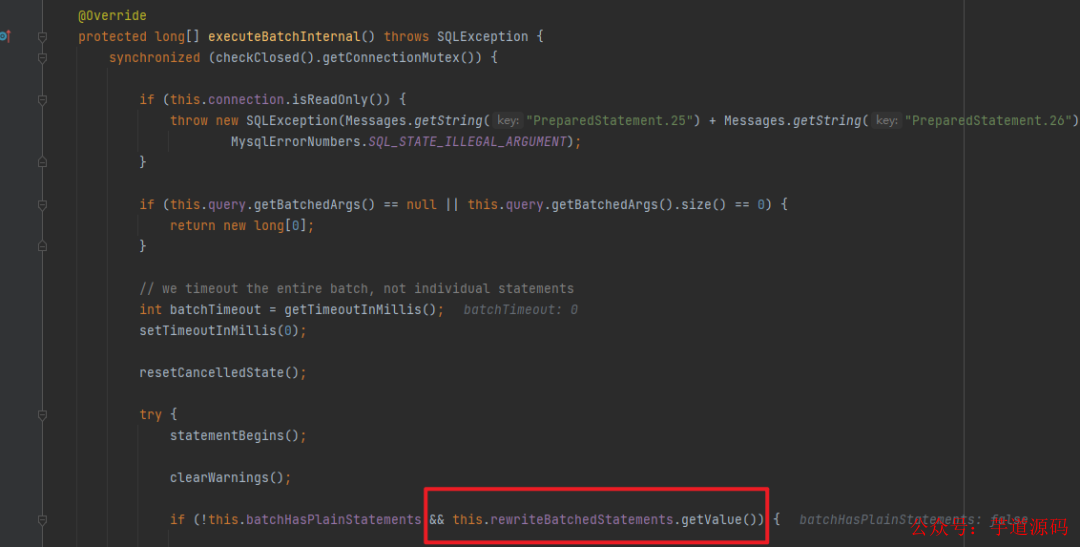
就是这个叫 rewriteBatchedStatements 的玩意,从名字来看是要重写批操作的 Statement,前面batchHasPlainStatements 已经是 false,取反肯定是 true,所以只要这参数是 true 就会进行一波操作。
我看了下默认是 false。
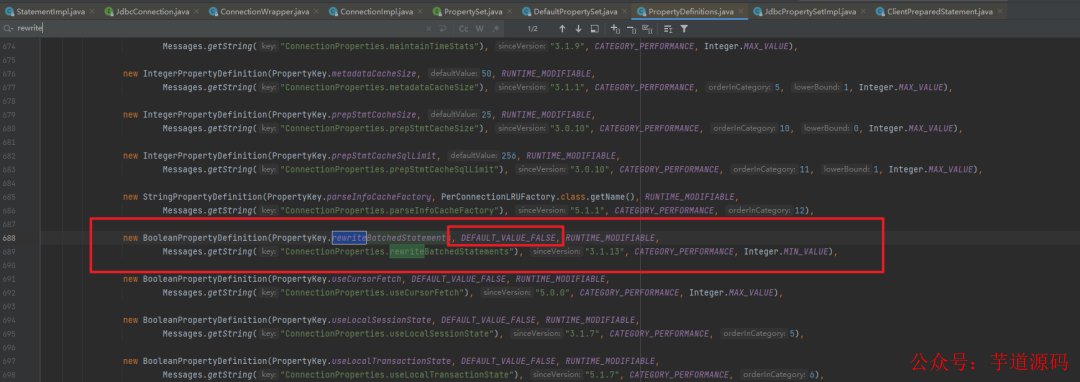
同时我也上网查了下 rewriteBatchedStatements 参数,好家伙,好像有用!我直接将 jdbcurl 加上了这个参数:

然后继续跑了下 mybatis-plus 自带的 saveBatch,果然性能大大提高,跟拼接 SQL 差不多!

顺带我也跑了下 JDBC 的 executeBatch ,果然也提高了。

然后我继续 debug ,来探探 rewriteBatchedStatements 究竟是怎么 rewrite 的!
如果这个参数是 true,则会执行下面的方法且直接返回:

看下 executeBatchedInserts 究竟干了什么:

看到上面我圈出来的代码没,好像已经有点感觉了,继续往下 debug。
果然!sql 语句被 rewrite了:
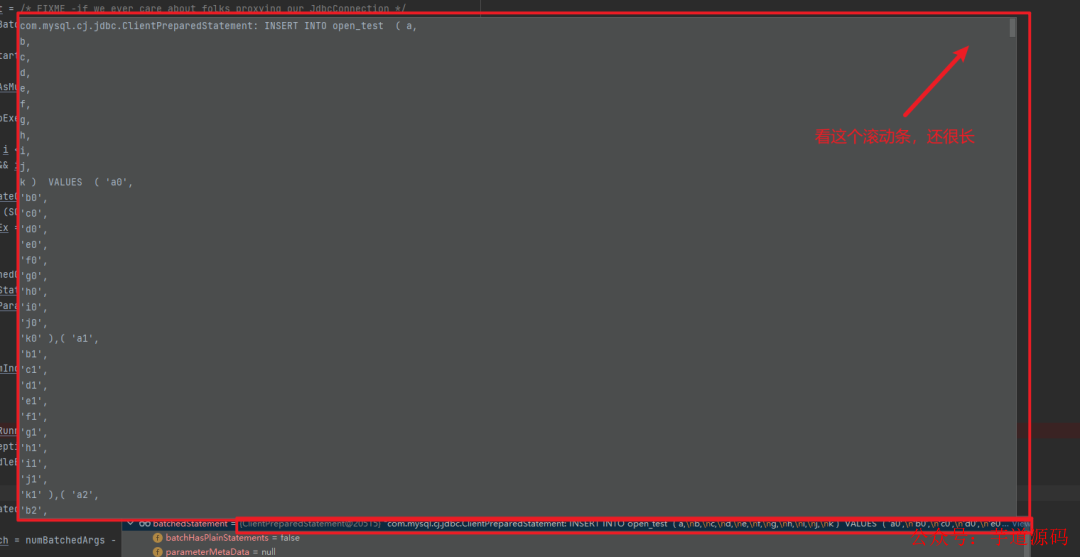
对插入而言,所谓的 rewrite 其实就是将一批插入拼接成 insert into xxx values (a),(b),(c)...这样一条语句的形式然后执行,这样一来跟拼接 sql 的效果是一样的。
那为什么默认不给这个参数设置为 true 呢?
原来是这样的:
- 如果批量语句中的某些语句失败,则默认重写会导致所有语句都失败。
- 批量语句的某些语句参数不一样,则默认重写会使得查询缓存未命中。
看起来影响不大,所以我给我的项目设置上了这个参数!
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
最后
稍微总结下我粗略的对比(虽然粗略,但实验结果符合原理层面的理解),如果你想更准确地实验,可以使用JMH,并且测试更多组数(如 5000,10000等)的情况。
| 批量保存方式 | 数据量(条) | 耗时(ms) |
|---|---|---|
| 单条循环插入 | 1000 | 121011 |
| mybatis-plus saveBatch | 1000 | 59927 |
| mybatis-plus saveBatch(添加rewtire参数) | 1000 | 2589 |
| 手动拼接sql | 1000 | 2275 |
| jdbc executeBatch | 1000 | 55663 |
| jdbc executeBatch(添加rewtire参数) | 1000 | 324 |
所以如果有使用 jdbc 的 Batch 性能方面的需求,要将 rewriteBatchedStatements 设置为 true,这样能提高很多性能。
然后如果喜欢手动拼接 sql 要注意一次拼接的数量,分批处理。
-
源码
+关注
关注
8文章
689浏览量
31544 -
接口处理
+关注
关注
0文章
3浏览量
6522 -
mybatis
+关注
关注
0文章
64浏览量
7188
原文标题:调优 MyBatis 25 倍性能
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Nginx高并发连接调优实战手册
Linux系统内核参数调优实战指南
性能测试调优实战与探索(存储模型优化+调用链路分析)

实战RK3568性能调优:如何利用迅为资料压榨NPU潜能-在Android系统中使用NPU




评论