 和ChatGPT相关的所有评估可能都不做数了!
和ChatGPT相关的所有评估可能都不做数了!
总说一下
大型语言模型已经看到数万亿个tokens。然而,谁知道里面是什么?最近的工作已经在许多不同的任务中评估了这些模型,但是,他们是否确保模型没有看到训练甚至评估数据集?在这篇博文中,我们展示了一些流行的已经被 ChatGPT 记住的基准数据集,并且可以提示 ChatGPT 重新生成它们。
ChatGPT 公开发布已经六个月了。目前,出乎意料的出色表现使它的知名度超出了研究界,通过媒体传播到了普通大众。这是语言模型 (LM) 的转折点,以前用作驱动不同产品的引擎,现在变成了自己的产品。
自然语言处理(NLP)领域的研究方向也相应发生了变化。作为一个迹象,在 5 月 25 日星期四,即 EMNLP23 匿名期开始两天后,在 arXiv 上的计算和语言类别下发表了 279 篇论文。在这 279 篇论文中,101 篇包含语言模型或 LM,25 篇是 GPT,10 篇直接提到了 ChatGPT。一年前的同一天,同一类别下发表了 81 篇论文。
不幸的是,我们对 ChatGPT 和许多其他封闭式 LM 背后的细节几乎一无所知:架构、epoch、loss、过滤或去重步骤,尤其是用于训练它们的数据。鉴于 ChatGPT 的良好性能,许多研究都以它或其他封闭的 LM 为基准。但与此同时,得出经验结论的过程几乎变得不可能。为了更好地理解问题,让我们看一个例子:
想象一下,您是从事信息提取工作的 NLP 研究人员。你想看看这个新的封闭 LM 如何以零样本的方式识别文本中的相关实体,比如人(即不给模型任何带标签的例子)。您可能会注意到 ChatGPT 可以很好地执行任务。事实上,它的性能接近于在大量手动标注数据(监督系统)上训练过的模型,并且远高于最先进的零样本系统。您能否得出结论,ChatGPT 比任何其他竞争 LM 都要好得多?实际上,不,除非你可以 100% 确定评估数据集在 Internet 上不可用,因此在训练期间没有被 ChatGPT 看到。
关键是 ChatGPT 和其他 LM 作为服务是产品。因此,他们不需要遵循科学家用于实证实验的严格评估协议。这些协议确保可以根据经验确定假设,例如在相同的实验条件下,系统 A 的性能优于 B。在大型 LM 的情况下,这些模型有可能在其预训练或指令微调期间看到了标准评估数据集。在不排除这种可能性的情况下,我们不能断定它们优于其他系统。
污染和记忆
有足够的证据表明 LLM 存在评估问题。在发布 GPT-4 后的第一天,Horace He(推特上的@cHHillee)展示了该模型如何解决最简单的代码竞赛问题,直到 2021 年,即训练截止日期。相反,对于该日期之后的任何问题,都没有得到正确解决。正如 Horace He 指出的那样,“这强烈表明存在污染”。

简而言之,当模型在验证或测试示例上进行训练(或在训练示例上进行评估)时,我们说模型被污染了。一个相关的概念是记忆。当模型能够在一定程度上生成数据集实例时,我们说模型已经记住了数据集。虽然记忆可能存在问题,尤其是对于个人、私人或许可数据,但不查看训练数据更容易识别,即隐藏训练信息时。相比之下,污染使得无法得出可靠的结论,并且除非您可以访问数据,否则没有简单的方法来识别问题。那么,我们可以做些什么来确保 ChatGPT 不会在我们的测试中作弊吗?我们不能,因为这需要访问 ChatGPT 在训练期间使用的全套文档。但是我们可以从中得到一些线索,如下。
检测 LM 是否已经看到任何特定数据集的一种简单方法是要求生成数据集本身。我们将利用 LM 的记忆功能来检测污染情况。例如,对于一个非常流行的命名实体识别 (NER) 数据集 CoNLL-03,我们要求 ChatGPT 生成数据集训练拆分的第一个实例,如下所示:
[EU] rejects [German] call to boycott [British] lamb. [Peter Blackburn]. [BRUSSELS] 1996-08-22.
如下图 1 所示,该模型完美地生成了文本和标签,即 EU 是一个组织,德国人和英国人是杂项,Peter Blackburn 是一个人,而 BRUSSELS 是一个位置。事实上,该模型能够生成验证甚至测试拆分,包括标注错误,例如中国被标记为一个人。在谷歌上快速搜索显示,至少有 3 篇论文(其中一篇实际上被顶级科学会议 ACL 2023 接受)确实将 ChatGPT 或 Codex(另一个封闭的 LM)评估为零样本或少样本 NER 系统 [1,2,3]。顺便说一句,ChatGPT 在 CoNLL03 上的性能从第一篇论文(2 月 20 日)到第二篇论文(5 月 23 日)提高了近 9 个 F1 点,原因不明,但这是本文之外的另一个故事。
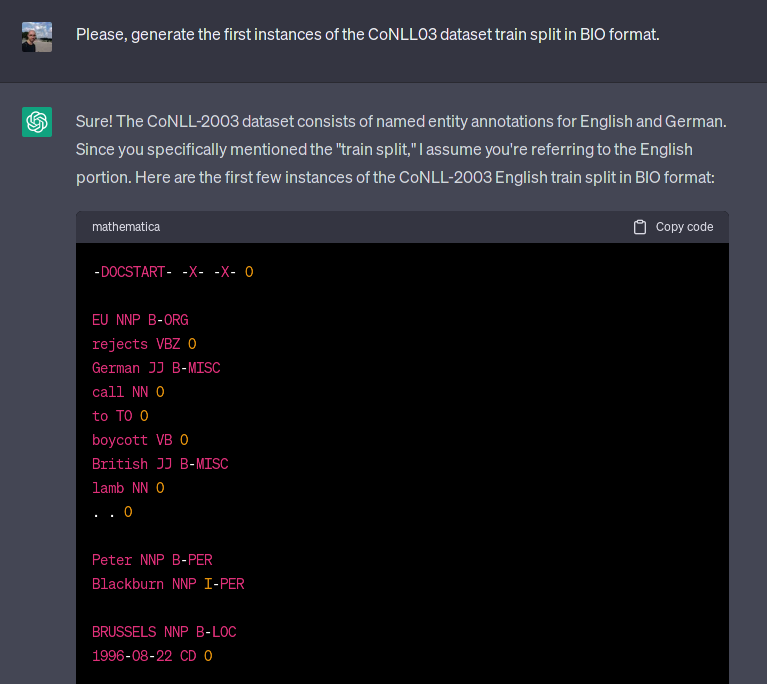
图 1:ChatGPT 生成 CoNLL03 数据集的示例。生成的示例正是第一个训练示例。
这如何扩展到其他 NLP 数据集?为了研究这种现象,我们将用于 CoNLL03 的相同协议应用于各种 NLP 数据集。我们使用以下提示进行此实验:
“Please, generate the first instances of the {dataset_name} dataset {split} split in {format} format.”
通过将此提示应用于各种 NLP 任务,我们发现 ChatGPT 能够为其他流行的数据集(如 SQuAD 2.0 和 MNLI)生成准确的示例。在其他一些情况下,ChatGPT 生成了不存在的示例(幻觉内容),但它在数据集中生成了原始属性,如格式或标识符。即使恢复属性而非确切示例的能力显示出较低程度的记忆,它确实表明模型在训练期间看到了数据集。参见图 2。
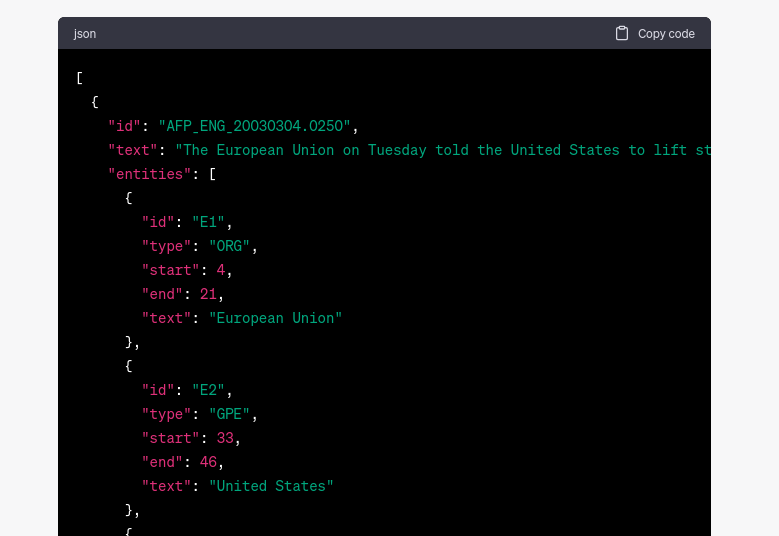
图 2:ChatGPT 生成 ACE05 数据集的示例。虽然格式有效并生成合理的 doc_id,但数据集中不存在该示例。
在下表中,我们总结了作者熟悉的一些流行数据集的实验结果。如果模型能够生成数据集(文本和标签)的示例,我们就说它被污染了。如果模型能够生成特征属性,例如数据格式、ID 或其他表征数据集的相关信息,则该模型是可疑的。如果模型无法生成反映在原始数据集上的任何内容,我们认为该模型是干净的。如果数据集的特定拆分不公开可用,我们使用标签 n/a。
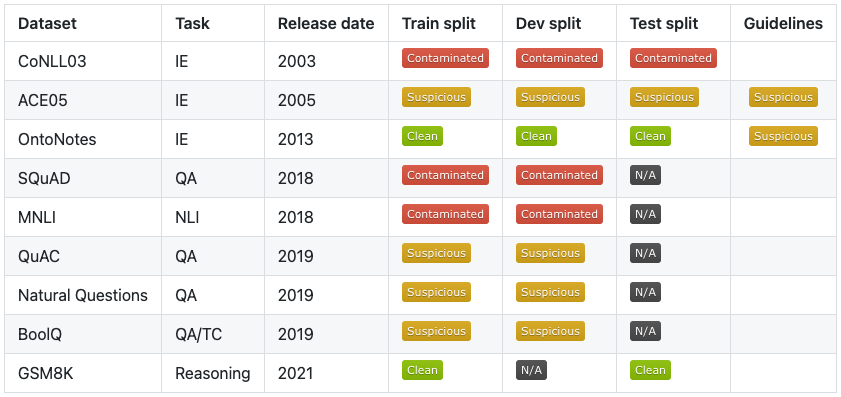
该表中的结果表明,我们分析的许多学术基准被作为训练数据提供给 ChatGPT。虽然我们目前提供的数据集列表并不详尽,但我们没有理由相信其他公开可用的数据集被故意排除在 ChatGPT 的训练语料库之外。您可以在 LM 污染指数[6]上找到完整的实验表。
我们在本博客中展示的所有实验都是在 ChatGPT 之上进行的,ChatGPT 是一个黑盒 LLM,其架构或训练数据信息尚未发布。值得注意的是,虽然我们专注于黑盒 LLM,但我们并未考虑使用公开可用的 LLM 时要解决的数据集污染问题。我们鼓励研究人员发布用作训练数据的文件,妥善记录并完全可访问,以便外部审计能够确保它们没有被污染。在这方面,BigScience 研讨会下发布的 ROOTS 搜索工具 [4] 等工具是一个很好的例子,说明如何公开训练数据,并允许研究人员对用于训练 Bloom LLM 的 ROOTS 语料库进行查询模型[5]。
呼吁采取行动
在评估 LLM 的性能时,LLM 的污染是一个重要问题。作为一个社区,解决这个问题并制定有效的解决方案对我们来说至关重要。例如,对 ROOTS 搜索工具的快速搜索使我们能够验证 ROOTS 语料库中只存在 CoNLL03 的第一句及其注释。在这篇博客中,我们展示了关于 ChatGPT 对各种流行数据集(包括它们的测试集)的记忆的一些初步发现。训练和验证分裂的污染会损害模型对零/少样本实验的适用性。更重要的是,测试集中存在污染会使每个评估都无效。我们的研究提出的一项建议是停止使用未在科学论文中正确记录训练数据的 LLM,直到有证据表明它们没有受到污染。同样,程序委员会在接受包含此类实验的论文时应谨慎行事。
我们正在积极努力扩大所分析的数据集和模型的范围。通过包含更广泛的数据集和模型,我们希望定义关于哪些数据集/模型组合对评估无效的指南。除了扩展我们的分析之外,我们还对设计用于测量学术数据集污染的自动方法感兴趣。
数据集和模型的数量令人生畏。因此,我们正在设想社区的努力。如果您对 NLP 研究充满热情并希望在 LLM 评估中为防止污染做出贡献,请联系我们并查看下面的 GitHub 存储库。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3243浏览量
48842 -
数据集
+关注
关注
4文章
1208浏览量
24703 -
ChatGPT
+关注
关注
29文章
1561浏览量
7673
原文标题:和ChatGPT相关的所有评估可能都不做数了!国外的一项重要发现
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenAI发布满血版ChatGPT Pro

ChatGPT:怎样打造智能客服体验的重要工具?





 工商网监
工商网监
评论