 Arm发布Cortex X4,功耗可降低40%!
Arm发布Cortex X4,功耗可降低40%!
今天,ARM发布了新一代的移动处理器内核,包括Cortex-X4、Cortex-A720、Cortex-A520,预计将很快用于骁龙8 Gen 3以及天玑9300等处理器。值得一提的是,新的核心基于Arm v9.2架构,并且只支持64位指令集,不再支持32位移动应用。

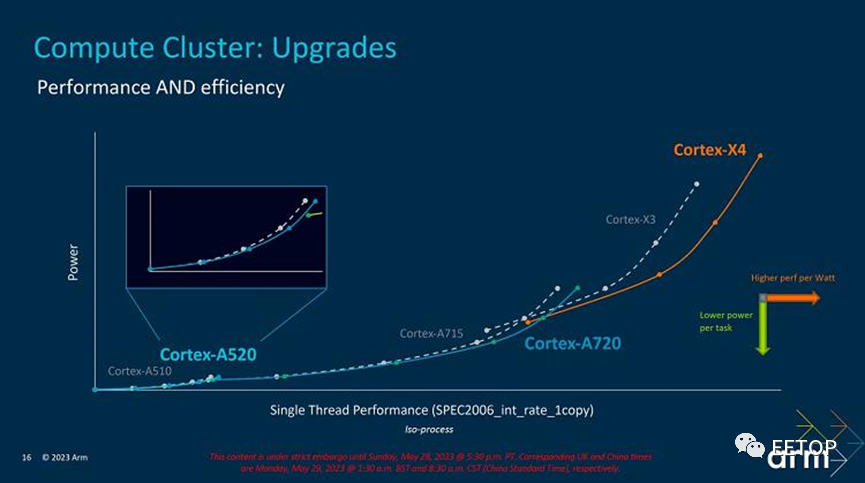
Arm Cortex-X4,这是该公司的下一代旗舰性能核心,也是迄今为止设计的最高性能Arm核心。
据了解,新发布的 Cortex-X4 超大核相比 Cortex-X3 在性能上提升了 15% 左右,但是在能耗方面有比较大的改善,宣称在相同频率下可以降低 40% 的功耗。而 A720 作为 A715 性能核心的升级迭代版本,效率提升了 20%。Cortex-A520 相比上代的 Cortex-A510 效率提升 22%。
网上此前已经爆出骁龙 8 Gen 3 采用的是 1+5+2 的丛集结构,其中 "1" 指的是 Cortex-X4 超大核,而 "5" 猜测是 Cortex-A720 性能核心,而 "3" 则是 Cortex-A520 的能效核心,安兔兔跑分更是达到了 160 万分,相比骁龙 8 Gen 2 提升明显。而天玑 9300 处理器预计同样会采用 ARM 发布的新移动处理器内核,性能表现令人期待。
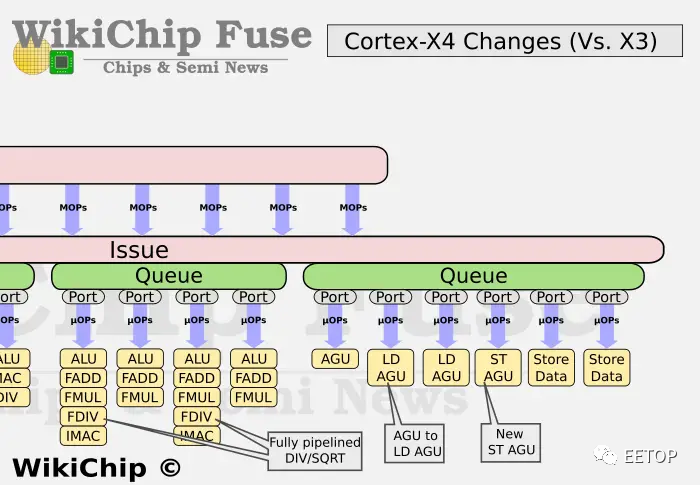
Arm表示,Cortex-X4的前端已经发生了一些重大变化。指令获取传递已经被完全重新设计了。与Cortex-A715一样,Cortex-X似乎也紧随其后,也完全放弃了宏操作缓冲区。相反,Cortex-X4拓宽了流水线,支持多达10条指令。指令缓存也得到了相应的增强。带宽增加到每周期10条指令。
新的分支预测器的准确性也得到了提高,在实际工作负载中观察到的停滞现象明显减少。随着指令高速缓存和宏操作高速缓存的变化,分支预测错误的惩罚被统一起来,并减少到10个周期。
后端部分也得到了增强。在执行单元的整数方面,Arm将之前几代的MUL单元更新为完整的MAC单元。这意味着X4现在有2个整数MAC单元。还增加了第三个分支单元。最后,还添加了两个额外的整数ALU,总共有8个——其中6个位于专用流水线上。


Cortex-X4的乱序缓冲区从Cortex-X3的320增加了20%,达到了384个。事实上,Arm每一代都会将ROB增加10%至30%左右。从一个角度来看,Cortex-X4的ROB现在比英特尔的Sunny Cove核心更大,后者只有352个条目,尽管远远不及令人惊叹的Golden Cove的512个条目ROB。
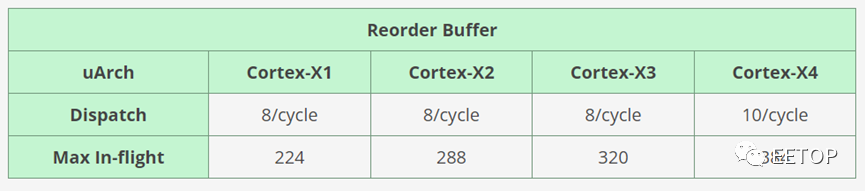
在浮点数方面,Arm对除法器/平方根单元进行了完全流水线化。管道和单元本身保持不变。
在内存子系统方面,Arm重新平衡了流水线。以前,Cortex-X3具有两个通用的地址生成单元(AGU)和一个专用的加载AGU,而现在的Cortex-X4只有一个通用AGU,同时配备了两个加载AGU和一个存储AGU。
Cortex-X4上的私有L2缓存也得到了扩大。系统集成商现在可以选择集成高达2 MiB的L2缓存,这将使L2缓存与上一代相比翻倍。如果需要的话,在更受限制的环境下,系统设计师可以选择使用较小的缓存大小。Arm表示,较大缓存不会增加延迟。这个选项可以在具有大内存占用的应用程序中实现更高的性能,因为它可以更频繁地引用靠近核心的内存。
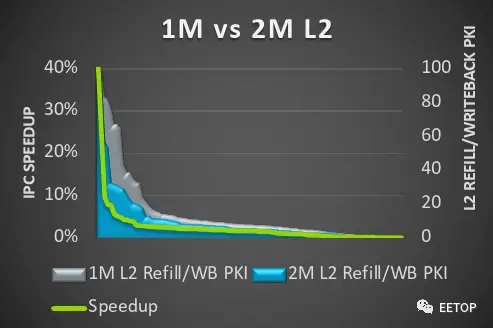
总的来说,Cortex-X4在ISO频率和L3(尽管具有较大的L2缓存)方面提供了约13%的IPC改进。
审核编辑 :李倩
-
ARM
+关注
关注
134文章
9084浏览量
367388 -
移动处理器
+关注
关注
0文章
132浏览量
22887 -
骁龙
+关注
关注
2文章
1006浏览量
36814
原文标题:Arm发布Cortex X4,功耗可降低40%!
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MAX32675C超低功耗Arm® Cortex®-M4F MCU

基于TI AM62x的Debian系统正式发布,丰富的软件生态,让您的应用开发更便利!
Arm Cortex-X925为用户实际需求提供强劲性能
实际项目开发中为何选择ARM® Cortex®-M4 内核的HK32MCU?
Arm Cortex-X925 树立全新性能标杆,实现人工智能、游戏和多任务处理的先进功能

国产!全志科技T507-H工业核心板( 4核ARM Cortex-A5)规格书
从AI手机到AI PC,Arm拿什么打造AI盛宴?
ARM发布旗舰手机芯片:性能提升、AI性能增强、节能减耗
天玑9300旗舰芯:全大核CPU架构,性能与能效的提升
宝马(中国)召回部分进口X3、2系和X4车型
Arm®Cortex®-M4 32位MCU GD32F303xB数据手册

Arm®Cortex®-M4 32位MCU GD32F303xx数据手册
HOLTEK新推出HT32F67742 Arm® Cortex®-M0+蓝牙5.2低功耗MCU
Arm Cortex-M52的主要特性和规格






 工商网监
工商网监
评论