 RISC-V处理器优化,不可依赖于放之四海而皆准的方法
RISC-V处理器优化,不可依赖于放之四海而皆准的方法
随着对高性能处理器的需求不断增长,半导体的缩放定律不断显示其极限,对处理器的优化需求变得不可避免。正如我在之前的博客中解释的那样,RISC-V的设计就是为了实现这一点。然而,在处理器优化方面没有一个放之四海而皆准的方法。由于每个工作负载和应用程序都有自己的要求,因此优化方法也因个体而异。我们可以在不同的层面上修改处理器IP,每一种都有自己的优势。在这篇博文中,让我们来定义和探索处理器优化的不同层次。从配置到定制,如何使用它们来创建满足特定要求的优化过的品质处理器。
首先定义三个不同级别的处理器优化,它们有着不同的优势和使用场景。所有三个级别不但不相互排斥,还可以将三者结合起来,以实现PPA目标。

3 levels of processor customization. Source: Codasip
配置:将标准内核的RTL参数设置为预先定义的值
每个处理器IP都有一套可调整的、预先定义的参数。它们在交付时有一个默认值,该默认值可以修改并设置为特定用例所需的值。大家通常可以在RTL级别设置并轻松修改这些参数。这种级别的优化在业界非常普遍,而且广泛传播。这些参数可能包括中断次数,是否存在简单的功能或缓存的大小等。
在RTL级别的调整对于任何处理器IP来说都是可以预期的,并且可以通过Codasip以RTL形式提供的标准Codasip RISC-V核来实现。该IP是经过完全验证的,简化后的集成,但是参数的范围和可能的值是有限的,探索空间也相对有限。
虽然这些参数是必要的,但不足以为特定需求创造一个真正独特的差异化产品。原因是它们既是有限的选项集,同时也是在RTL层面的实现的,而RTL级别的实现是难以参数化的,这在业界众所周知。因此,配置只能给予对最终设计的有限控制。
高级配置:结构性变化以适应设计
除了配置之外,还有高级配置可以运用。在高级别配置上,这个概念看起来很相似。但我们的想法是启用更大、更复杂的参数,从而得到明显差异化的RTL 。配置选项的例子包括:
1. 缓存和TCM的增加
2. 浮点单元的存在
3. 或分支预测器的存在
这种灵活性对于处理器IP来说虽然不太常见,但是可以使用Codasip IP来实现。所有的Codasip RISC-V内核都是用一种叫做CodAL的高级语言设计的,并且可以用Codasip Studio设计自动化进行配置。只需从配置器GUI中选择高级参数,该工具就会自动生成只包含自定义优化配置的RTL。
处理器的CodAL源代码可向用户提供所有选项。然后,Codasip Studio工具将CodAL合成为RTL。
Codasip提供大量的CodAL配置选项,也意味着客户不需要任何关于CodAL的具体知识(尽管这种类似C语言的编程语言很简单和直接)。这中方法为实现特定应用定制产品提供了保证。并完全可以从同一个源代码中同时优化硬件和软件。
定制:更深层次的处理器IP优化
更深层次的IP优化实际上是设计师对IP的修改,以便为目标应用获得更高的效率性能。这是定制计算的领域,也是Codasip提供的具有竞品优势的解决方案。其他IP供应商可能会宣称处理器也可以进行定制,但如果没有自动化设计流程,这种期待只能停留在理论上,而且可定制范围非常有限。
Codasip RISC-V内核的定制意味着对IP进行细粒度的修改,能够在架构和微架构层面上修改需要的任何东西。可以增加或删除指令,改变寄存器集或增加全新的功能或接口,而不仅仅是修改现有的参数。CodAL语言的使用使这些修改变得快速而简单。Codasip Studio的分析功能指出了需要改进的潜在领域,并能非常快速地反馈应用程序在这些修改后的表现,这对快速迭代和获得最佳结果至关重要。
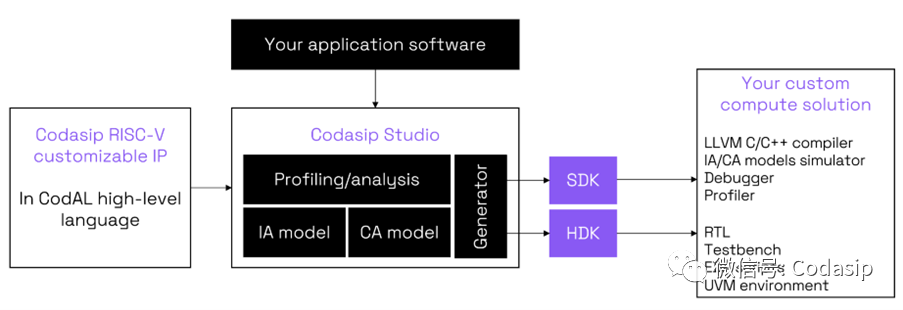
Automated approach to custom compute. Source: Codasip
而从一个经过完整验证的RISC-V内核开始,也使这个定制过程变得更快,并可以大大减少验证工作,而验证环节通常是设计项目中最耗时的任务。在Codasip Studio中用CodAL对Codasip RISC-V内核进行全面优化,是为应用获得定制计算的一种实用方法。它最大的优势在于整个设计流程是自动化的,而且该工具会自动生成一个SDK和HDK,这些SDK和HDK并已知与定制内核相匹配的相关。而不需要手动来创建一切!
处理器优化案例
可以想象一下,如果想为特定的机器学习工作负载优化一个处理器,以卷积神经网络(CNN)为例。
随着向设备级人工智能处理的重要转变,在为物联网应用选择SoC或MC时,运行人工智能/机器学习任务的能力成为必须具备的条件。但是嵌入式设备通常受到资源限制,因此很难在嵌入式平台上运行人工智能算法。
使用Codasip L31 RISC-V内核和Codasip Studio,我们可以探索和定制处理器设计,以提高其运行机器学习算法时的效率。Codasip Studio中包含的剖析工具使设计者能够比较标准内核和优化内核的性能,突出神经网络定制指令的好处。
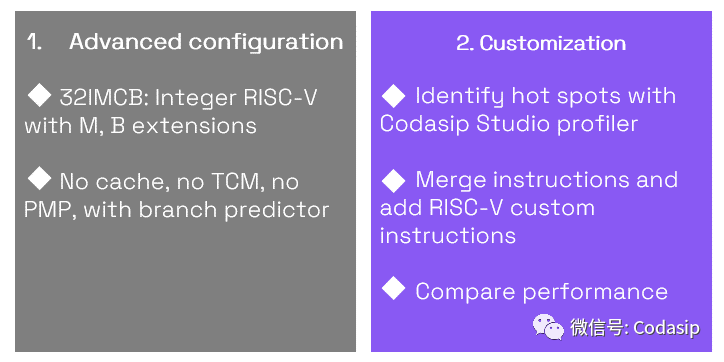
Our approach to processor optimization for ML workloads (use case). Source: Codasip
Codasipde的方法是在不同的层次上对处理器进行调整:
我们为ML工作负载优化处理器的Codasip方法(使用案例):高级配置和定制
通过对图像识别的基准应用进行分析,我们用Codasip Studio工具证实,图像卷积是一个主要的瓶颈,占用了89%以上的CPU时间。不到200行的CodAL代码足以实现一个紧密集成在Codasip L31内核的卷积加速器。在对最大频率影响不到10%的情况下,这种修改提供了大于5倍的性能提升和小于3倍的能耗。Codasip Studio自动生成一个优化的编译器,在不改变软件的情况下实现了效率的提高!
如果您对神经网络加速器技术白皮书感兴趣,请移步该链接下载英文原版:https://codasip.com/papers/compact-nn-accelerator-in-codal-technical-paper/
各种处理器优化方法相结合以求最佳结果
正如我们所说,在处理器优化方面没有一个放之四海而皆准的方法。处理器IP修改可以在不同层面进行,每个层面都可以带来不同的优势。这种组合的相结合则能协助客户在开发独特产品时实现最佳的PPA目标。

审核编辑 :李倩
-
处理器
+关注
关注
68文章
19286浏览量
229873 -
内核
+关注
关注
3文章
1372浏览量
40293 -
RISC-V
+关注
关注
45文章
2277浏览量
46163
原文标题:RISC-V处理器优化,不可依赖于放之四海而皆准的方法。
文章出处:【微信号:Codasip 科达希普,微信公众号:Codasip 科达希普】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
晶心科技推出突破性的RISC-V 27系列处理器及向量扩展指令处理器
开放性与碎片化,RISC-V能否撼动处理器架构的格局?
关于RISC-V和开源处理器的一些解读
学习RISC-V入门 基于RISC-V架构的开源处理器及SoC研究
RISC-V开源处理器核介绍
优化的关键,RISC-V中的性能监控
RISC-V工具链简介
香山处理器 RISC-V的典范
RISC-V是通用RISC处理器还是可定制的处理器?
美国芯片企业开发出全球最快的64位Risc-V处理器
基于形式验证的高效RISC-V处理器验证方法
基于形式的高效 RISC-V 处理器验证方法





 工商网监
工商网监
评论