 从这颗3nm AI芯片,看RISC-V用在高性能计算上
从这颗3nm AI芯片,看RISC-V用在高性能计算上
虽然我们此前就多番探讨过现阶段RISC-V尝试入侵高性能计算市场的可能性,但起码现在提到RISC-V,大部分人的第一反应仍然是嵌入式应用。 其实RISC-V在高性能市场的探索,能够列举的例证还是比较多样的,不仅是这个市场前一阵比较热的Veteran。这次我们来看看另外一家准备在RISC-V高性能计算领域一展拳脚、而且算是含着金汤匙出生的企业Tenstorrent。 这家公司现在的CEO是鼎鼎大名的Jim Keller;另外很多人应该知道,前一阵Raja Koduri从Intel离职后准备搞自己的初创公司,但与此同时他也是Tenstorrent的董事会成员之一;是不是感觉这公司还挺有花头的?借着Tenstorrent的芯片路线图及技术规划,我们也能更进一步搞清楚RISC-V未来在HPC市场的可能性,以及AI芯片的发展趋势。
01.RISC-V核的超宽微架构
最早听说Tenstorrent,我们普遍说这是个做AI芯片的公司,但在去年的RISC-V Summit峰会上,Tenstorrent的CPU首席架构师Wei-han Lien特别谈到了自家在做的CPU产品,核心代号Ascalon。这是个基于RISC-V指令集、乱序执行超标量CPU,着力于AI与服务器的高性能市场。 其实能看到这家公司出现包括Wei-han Lien和Jim Keller在内的名字,应该就很容易想见,CPU甚至已经是Tenstorrent的重头戏了。
Jim Keller暂且不提,Wei-han Lien曾经在AMD、PA-Semi、苹果都扮演芯片设计的重要角色。Tom's Hardware在报道文章中说,此人参与了苹果A6、A7,甚至是M1 CPU微架构设计工作。 有兴趣的同学可以去油管看一看Wei-han Lien在去年RISC-V Summit峰会上的主题演讲。他谈到两个点给我们留下了比较深刻的印象,其一是推出CPU的出发点应当在于辅助AI芯片(所谓companion CPU)。所以Tenstorrent的自研架构CPU最重要职能就是“CPU for AI Computation”。 原因也很简单,“很多人可能并没有意识到在AI计算中,CPU扮演着非常非常重要的角色,尤其是在训练(training)方面。”Lien说,“有人知道数据中心AI训练过程中,CPU功耗多少吗?不是10%,也不是20%,时间和功耗都超过了50%,包括CPU对数据的预处理和后处理。”后文会谈到,Tenstorrent将Ascalon CPU核心集成到AI芯片上的方案。
其二是Lien谈了为什么在指令集上选了RISC-V,而不是Arm。他说在2021年加入公司时,对ML处理器的companion CPU做评估,他去找了Arm询问能否支持某种特定的数据类型,Arm的答复是不行。据说Arm对于这种程度的支持需要2年时间的内部讨论和与合作伙伴之间的磋商。所以RISC-V很快成为新选择——Tenstorrent的AI芯片选择的companion CPU IP就来自SiFive。 后续Tenstorrent又需要性能更高的CPU,于是就决定自己设计,也就有了Ascalon。HWcooling前不久发布的评论文章认为,Ascalon的超宽架构设计和苹果芯片很像。我们来看看Ascalon的一些设计大方向。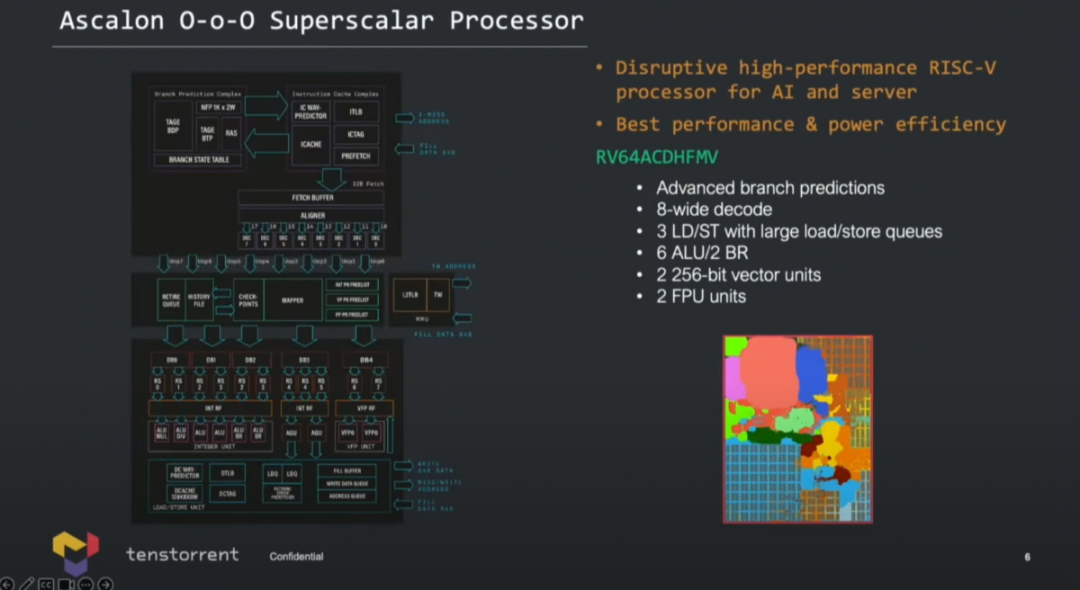
Tenstorrent的Ascalon核心具体为64bit的RV64ACDHFMV指令集架构,也就是说支持矢量指令集扩展——这在RISC-V世界来得算是比较迟的。 整体微架构前端8-wide解码(之前在谈Veteran的RISC-V超宽微架构时我们就提到了,其RISC-V核前端选配了8-wide取指),每周期能处理8个RISC-V指令——这个宽度和苹果Firestorm的设计就类似了。
另外Ascalon架构有6个整数ALU,2个分支执行单元;而load/store三条管线还是比苹果现行方案少了1个的(load/store分配情况未知),load/store队列深度比较深,但具体是多少未知; 核心有2条FPU管线,用于浮点运算,并同时用作SIMD矢量单元——位宽256bit。其实就这个数字来看,SIMD吞吐仍未达到x86服务器平台竞品的程度——虽然光看纸面位宽和管线数字并不可靠。
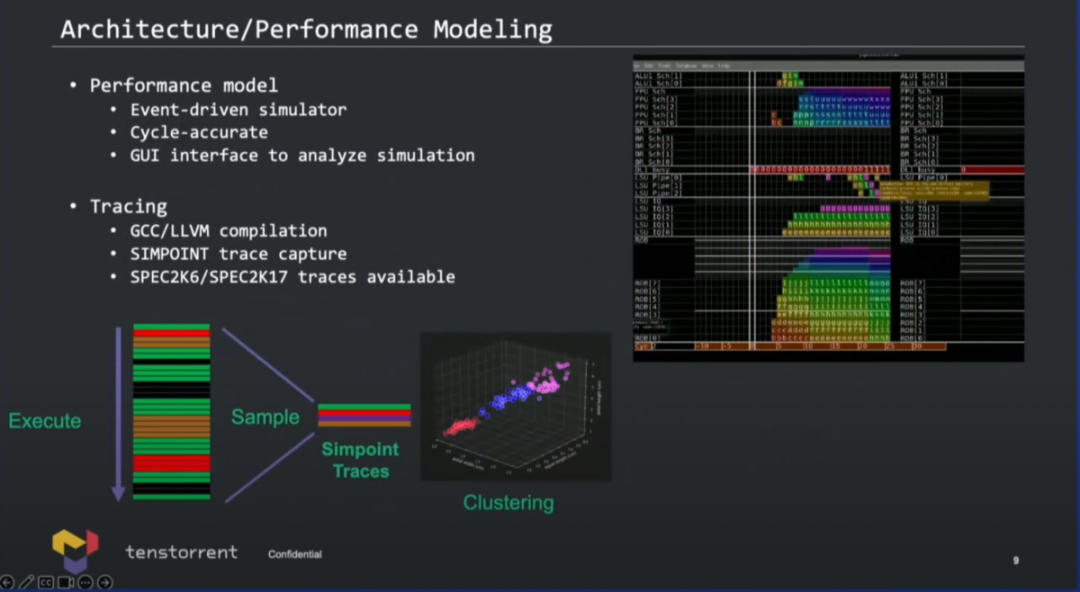
国外媒体还提到Tenstorrent采用了“先进的TAGE分支预测器”;cache容量情况未知,但“L1显然会和苹果的128KB, 8-way associativity类似”;“从指令cache取指应当为32bytes/cycle”;还有一些关键信息未知,例如ROB深度,有一定概率与苹果芯片的思路相似,即比较高的乱序度。则核心的IPC理论上就会很理想,不需要太高的频率。 演讲中,Lien提到目前工程师已经在搞RTL和物理设计,右下角那张图就是die photo。下面两张图给出了核心设计的难度、模块化方案、如何做性能建模等等...本文不再做展开,有兴趣的可以去看看演讲视频。
02.128核心的集群组成chiplet
实际上,根据decode解码宽度,Tenstorrent准备了5个不同的CPU IP,面向不同的应用:是同一方案的不同规模实施。按照解码宽度和性能,做了如下切分: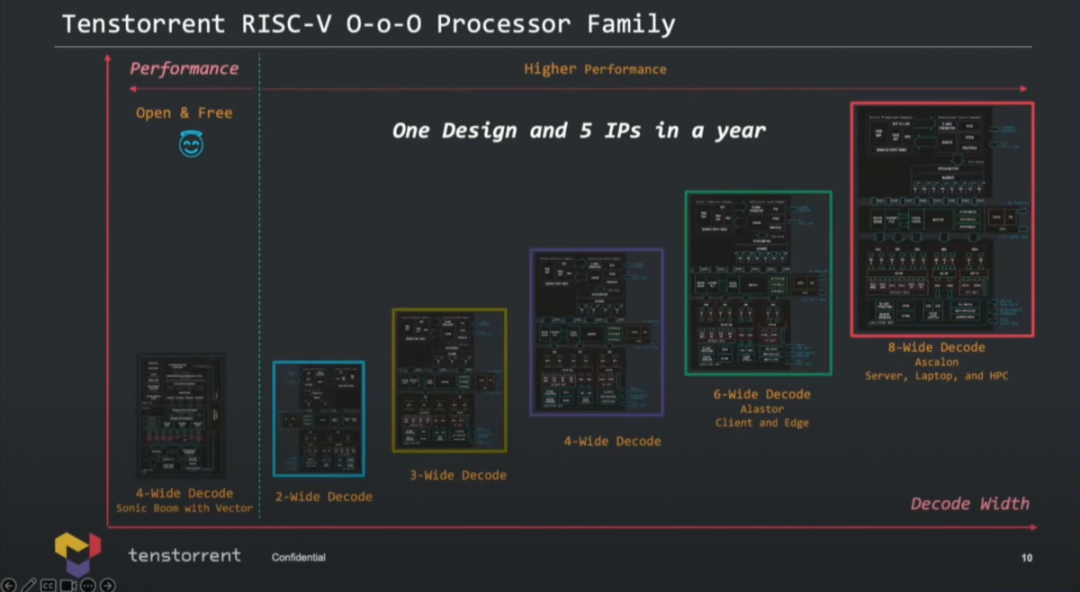
从2-wide解码,到8-wide解码,达成不同的PPA目标,也就面向不同的应用:涵盖了边缘设备、客户端PC、HPC高性能计算等,似乎还有一些更基础的应用。其实就核心层面就做这么多种设计,多少就有点IP公司的意思了——授权IP的确也是这家公司的盈利模式之一,后文会谈到。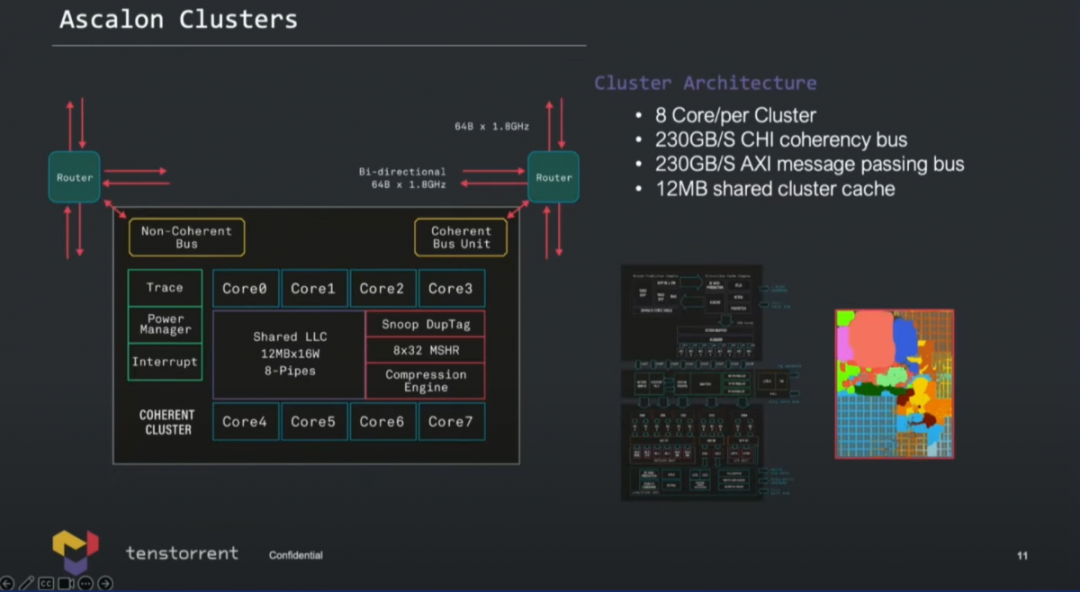
当Ascalon核心组成集群(cluster),多核方案形如上图所示——一个集群可以配8个Ascalon核心(也就是最大8-wide的那个核心);集群内12MB共享集群cache;此外走向集群外部fabric的CHI coherency bus带宽230GB/s;也有non-coherency bus,230GB/s,面向加速单元。 Lien特别提到,共享集群cache和scratchpad memory相关的存储一致性方案,“不仅让Ascalon核心非常适用于常规服务器的高性能核心,而且很适合用于AI计算”。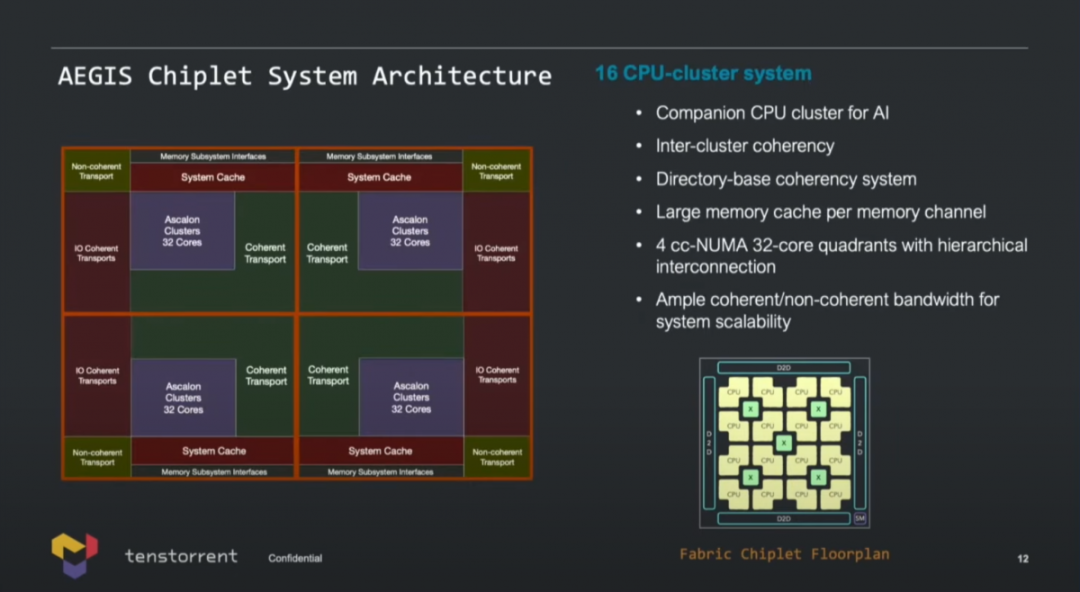
基于核心集群可以构成128个核心的设计(AEGIS Chiplet系统架构),作为AI的companion CPU集群。整个系统切分成了4块,每一块都是cc-NUMA(cache coherency non-uniform memory access)结构,Lien的原话是“fully coherency system”。
整颗chiplet本身配有die-to-die接口,ppt上只提到了针对可扩展性达成“充足的带宽”。后面Lien在介绍Black Hole系统的时候,似乎有提到双芯(dual-chip)的2TB/s die-to-die带宽。 上述方案以IP的方式对外提供授权(包括RTL、hard macro,甚至GDS(Graphic Data Stream));另外从国外媒体的报道来看,Tenstorrent也出售chiplet、机器学习加速卡,或者包含CPU和ML加速单元的解决方案,而且还卖服务器系统。
就说这个业务模式还真是多样化,作为IP供应商,又自己卖chiplet、卖芯片,还做系统,那是和不同层级的客户达成了竞争关系的。不过这也不是咱要讨论的重点。 实际上,就Tenstorrent出售的芯片和系统,上述CPU核心主要还是为AI服务的。
03.用作AI芯片的companion CPU
所以接下来我们谈谈Tenstorrent的AI芯片。过去2年,这家公司分别推出过Grayskull和Wormhole,详细配置情况如下图所示。这两款AI处理器很自然地需要搭配主CPU,系统层面产品形态是作为板卡插在Tenstorrent自己的服务器里面的。在Wormhole这代产品上,4U的Nebula服务器内有32块Wormhole板卡,6KW功率达成Int8的12 PFLOP算力。
不过这两颗芯片不是我们要关注的重点,上图中的Black Hole是这家公司的首款“CPU+ML解决方案”。注意看图中,除了标记“T”的加速单元(名为Tensix),右边还有标记为绿色“C”的CPU核心——这部分就是companion CPU。 不过Black Hole所用的14个CPU核心,用的是SiFive的X280——外围的8通道GDDR6、1200Gb/s以太网连接、32 lane PCIe Gen 5就不多谈了。今年Tenstorrent最新的PPT似乎更新了时间线,即上述所有产品均延后一年,所以Black Hole对应于2023年,Grendel对应于2024年。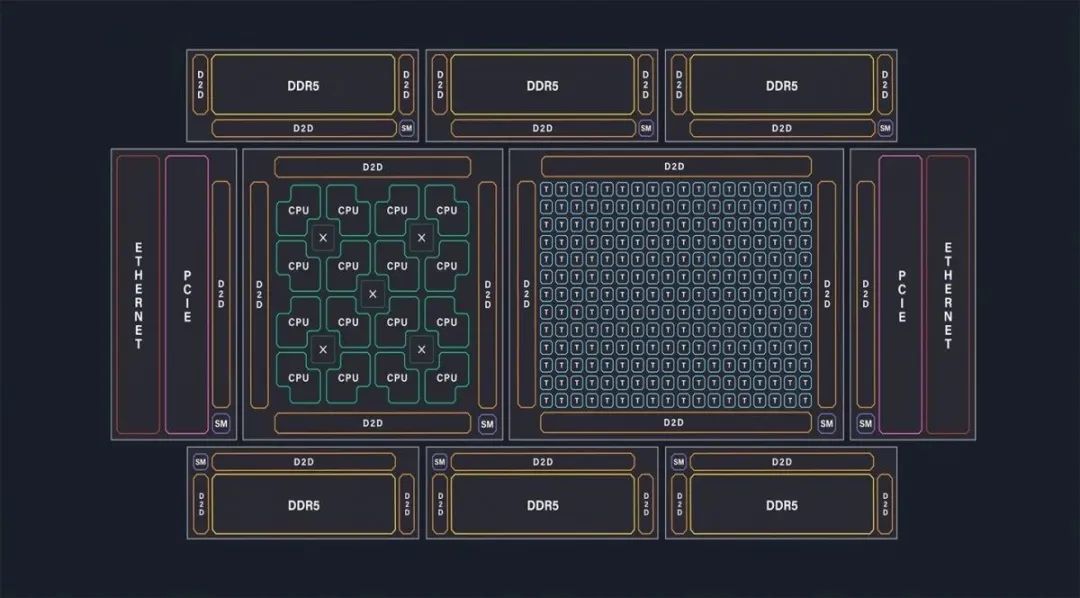
规划中的Grendel就会用上前文提到的来自Tenstorrent自己的Ascalon核心,也就是自研RISC-V CPU,前端8-wide解码那个。这颗芯片的AI和CPU chiplet都会选择3nm工艺——这可能是目前已知最早的应用尖端制造工艺的RISC-V芯片。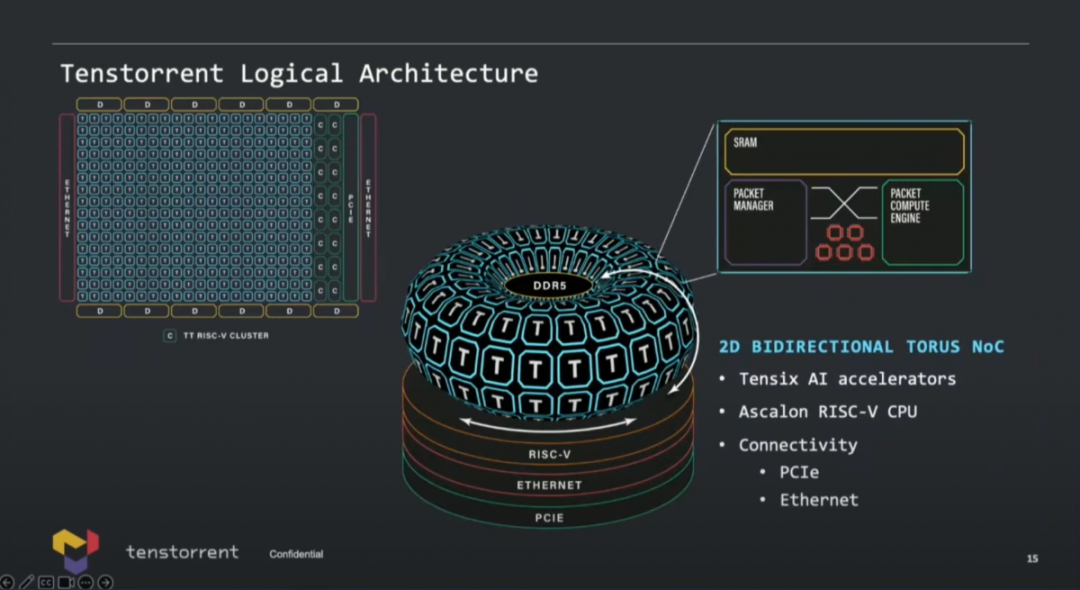
这张示意图画得还是挺有趣,AI加速单元是基于2D torus NoC互联,连接DDR内存(不支持HBM),连接RISC-V CPU,以太网用于扩展,当然还有PCIe连接。值得一提的是,因为Tenstorrent的角色定位,可能最终产品选择不同IP是存在灵活性的,比如说DRAM控制器、PHY之类的选配,据说Tenstorrent未来准备开发自己的内存控制器,现在用的还是三方的方案。
从今年Tenstorrent公布的框图来看,多chiplet方案的确让Grendel看起来就是个大规模芯片。Tom's Hardware在文章中说,实则基于业务需求以及经济性考量,这颗芯片的AI chiplet部分(也就是那一堆Tensix单元)可以用3nm工艺,或者也可以用Black Hole的chiplet,甚至也可能CPU部分就继续用SiFive X280。chiplet之间通讯如前所述可达成2TB/s的带宽。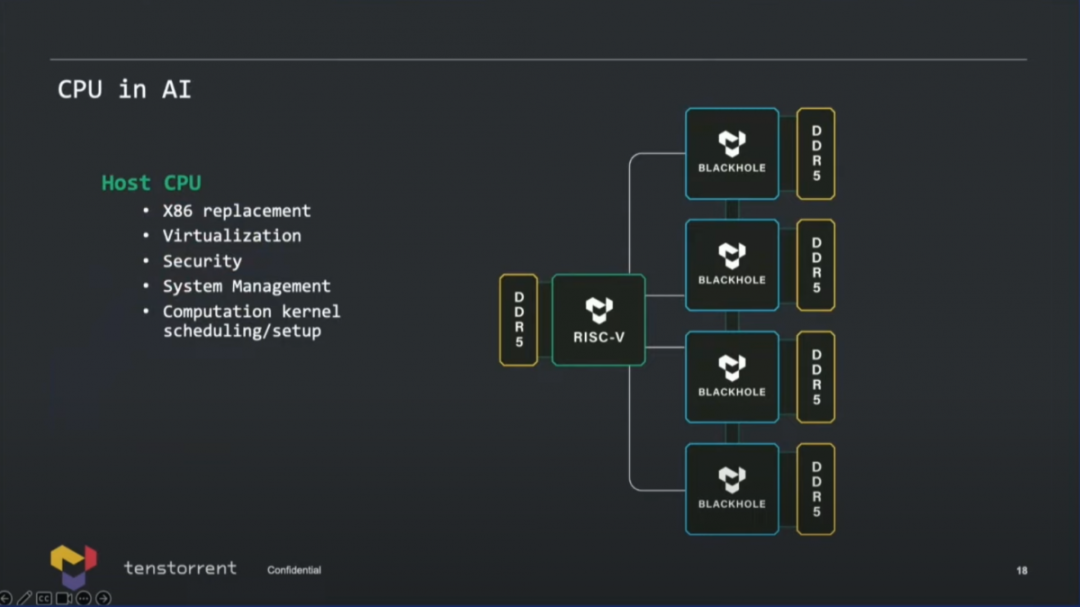
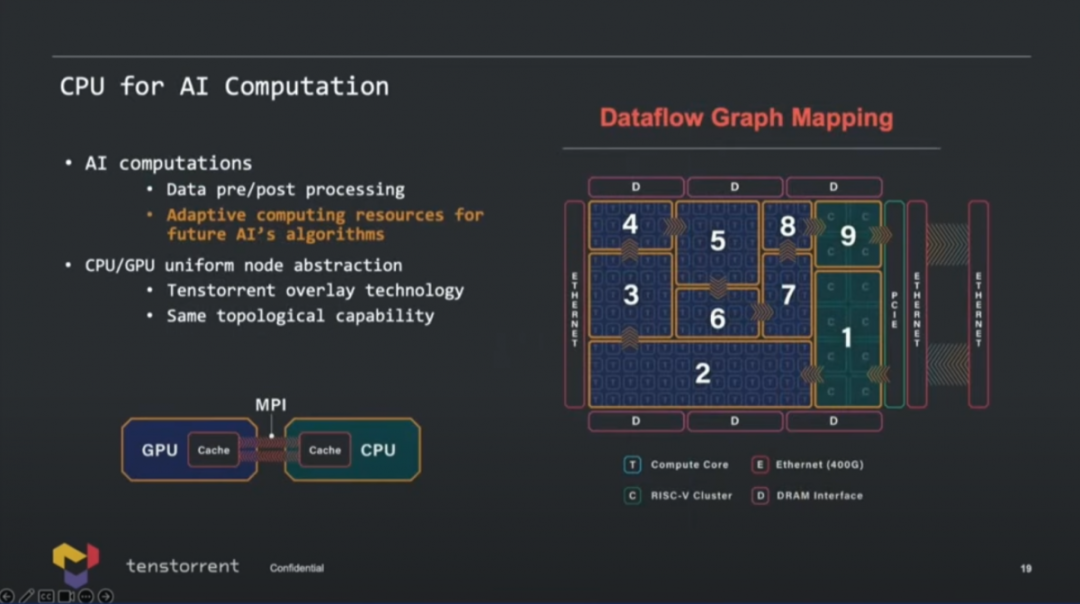
最后来谈一下Ascalon或者其他RISC-V CPU用在这样的AI芯片里,具体要干什么。实际上,Tenstorrent的CPU并不是单纯用于AI流程控制的,而是可以替代x86的主CPU。其职能涵盖了虚拟化、安全、系统管理、计算内核调度设置。 在用作辅助AI计算时,价值自然就包括了数据预处理,预防训练数据overfeeding之类的问题;还有当CPU的矢量单元比较强悍时,对于整个处理器适配未来的算法会很有价值,或者说CPU是整颗芯片弹性化的体现方式之一。另外两者之间的协同,也体现在了包括互连通讯与存储等的CPU微架构设计里,那么compiler要在加速器和CPU之间做计算迁移也会很容易。
这都是Tenstorrent自己要做CPU,且基于RISC-V的原因所在。 软件栈,以及系统搭建为服务器产品的部分这里就不谈了,毕竟我们这篇文章其实就是看一看当RISC-V指令集用于HPC时,CPU架构大概会长什么样的。不过其实在系统层面,Tenstorrent还考虑到大规模集群计算,需要做数据迁移势必要用到DPU的问题——毕竟这已经是个共识了;Tenstorrent就说RISC-V在此也成为相当棒的选择...
整体上,看一遍Tenstorrent的RISC-V CPU设计,仍有种对于具体应用而言,技术层面究竟选择何种“指令集”都不是什么重点,而在于设计和实施方案的感觉。而阻断x86和Arm成为其选择的原因并不在于指令集本身,而在于RISC-V开源体现出的灵活性。这大概也更便于Jim Keller这类人去施展拳脚。虽然就外围存储、互联的堆料看来,可能还是不能直接与英伟达硬碰硬,但灵活性和成本可能会是重要优势项。
当然Grendel这颗3nm AI芯片毕竟也还没有做出来,目前也还不清楚CPU的IP授权业务开展情况如何——其实就像前文提到的Tenstorrent的业务模式比较奇特,他们的上游供应商和下游客户又同时是竞争对手。比如SiFive既为其CPU提供IP,同时后代产品又直接形成了竞争对手关系。所以业务开展如何还有待观察。 不过那么多大佬入局,还是让Tenstorrent这家公司在开局成为了惹人注目的焦点。起码RISC-V未来成为市场竞争的主要角色之一已经不会再有疑问,而且绝对不光是低功耗和嵌入市场。
审核编辑:刘清
-
ARM处理器
+关注
关注
6文章
360浏览量
41770 -
HPC
+关注
关注
0文章
316浏览量
23801 -
RISC-V
+关注
关注
45文章
2292浏览量
46194 -
AI芯片
+关注
关注
17文章
1888浏览量
35058
原文标题:从这颗3nm AI芯片,看RISC-V用在高性能计算上
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
risc-v芯片在电机领域的应用展望
圣诞特辑 |开源芯片系列讲座第25期:RISC-V架构在高性能领域的进展与挑战

SiFive 推出高性能 Risc-V CPU 开发板 HiFive Premier P550

直播预约 |开源芯片系列讲座第25期:RISC-V架构在高性能领域的进展与挑战
RISC-V,即将进入应用的爆发期
希姆计算与开芯院签署生态合作伙伴协议,共同打造高性能RISC-V AI大算力芯片

RISC-V适合什么样的应用场景
RISC-V在中国的发展机遇有哪些场景?
国产RISC-V MCU推荐
Rivos完成2.5亿美元A轮融资,用于研发AI工作负载 RISC-V计算加速
RISC-V厂商正在AI领域积极布局!






 工商网监
工商网监
评论