 ChatGPT横空出世 人工智能进入大模型时代
ChatGPT横空出世 人工智能进入大模型时代

1.1、 ChatGPT 横空出世,引领人工智能新浪潮
人工智能历经多年发展,在诸多领域超越人类。自 1956 年 8 月达特茅斯会议上 “人工智能”概念诞生以来,行业几经起落不断发展壮大。临近新千年的 1997,IBM 深蓝计算机打败国际象棋大师卡斯帕罗夫成为首台打败国际象棋世界冠军的电脑。 2010 年,谷歌宣布自动驾驶汽车计划。2012 年卷积神经网络 AlexNet 在大规模视觉 识别挑战赛中以比第二名低 10.8 个百分点的错误率夺冠,引发轰动,开启了深度学 习黄金时代。2016 年 DeepMind 公司的 AlphaGo 以 4:1 大比分战胜当时世界冠军李 世石,人类将围棋冠军也让与计算机,掀起人工智能新一轮热潮。多年以来,像计 算器超越人类的计算能力一样,人工智能在越来越多领域超越人类,并被应用到千 行百业,未来将继续在更多的领域崭露头角,为人类赋能。
ChatGPT 横空出世,再次引发人工智能热潮。2022 年 11 月,ChatGPT 横空出 世,作为一种应用在对话场景的大语言模型,它可以通过更贴近人的方式与使用者 互动,可以回答问题、承认错误、挑战不正确的前提、拒绝不适当的请求,同时拥 有惊艳的思维链推理能力和零样本下处理问题能力。在理解人类意图、精准回答问 题、流畅生成结果方面远超人类预期,几乎“无所不能”,引发网络热潮。据瑞银数 据,ChatGPT 产品推出 2 个月后用户数量即过亿,而上一个现象级应用 TikTok 达到 1 亿用户花费了 9 个月时间。微软将 ChatGPT 整合到其搜索引擎必应中后,在 1 个 多月的时间内让必应日活跃用户数过亿。
GPT-4 能力进一步提升,安全性显著增强。Open AI 在当地时间 2023 年 3 月 14 日发布了 GPT-3.5(ChatGPT 基于 GPT3.5 开发)的升级版 GPT-4,性能全面超越 ChatGPT。其具备多模态能力,可以同时支持文本和图像输入。支持的文本输入数量 提升至约 32000 个 tokens,对应约 2.5 万单词。性能方面,(1)理解/推理/多语言能 力增强,在专业和学术考试中表现突出,全面超越 GPT3.5,通过了统一律师考试的 模拟版本,分数在考生中排名前 10%。(2)理解能力显著增强,可以实现“看图说话”, 甚至能够理解一些幽默的图片笑话。(3)可靠性相比 GPT3.5 大幅提升 19%。(4)安 全性指标相比 GPT3.5 有显著提升,对不允许和敏感内容的错误反应显著下降。
1.2、 算法是人工智能的基石,Transformer 逐步成为主流
1.2.1、 始于 NLP,延伸至各领域,Transformer 在人工智能行业展现统治力
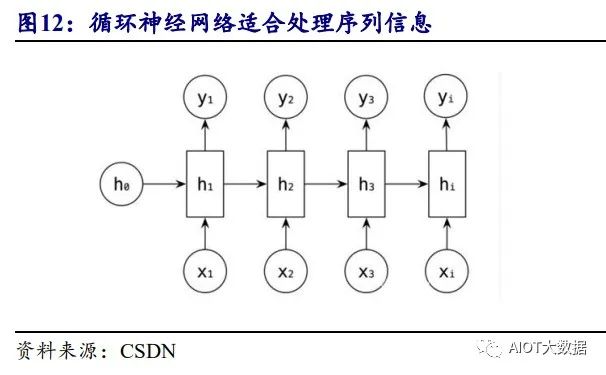
算法是构成模型的基石,循环神经网络(RNN)和卷积神经网络(CNN)曾为 自然语言处理和图像处理的领域主流算法。早年人工智能领域常见的算法包含循环 神经网络(RNN)和卷积神经网络(CNN),其中循环神经网络每个环节的输出与前 面的输出有关(有“记忆”),因此可更好的处理序列问题,如文本、股市、翻译等。 卷积神经网络则以图像识别为核心,通过卷积核进行窗口滑动来进行特征提取,进 而实现图像识别等功能。但两类算法均存在自身的问题,循环神经网络并行度低, 计算效率受限,同时输入的数据较为庞大时,早期的记忆容易丢失。而卷积神经网 络由于需要卷积核滑动来提取特征,面对距离较远的特征之间的关系识别能力有限。
Transformer 结构性能强大一经推出迅速得到认可。Transformer 在谷歌著名的 论文“Attention is all you need”首次出现,其优点在于并行度高,精度和性能上均优 于传统神经网络。该算法采用编码器解码器(Encoder-Decoder)架构,编码器接受 输入并将其编码为固定长度的向量,解码器获取该向量并将其解码为输出序列。该 算法早期被应用于翻译领域,相比传统 RNN 只关注句子相邻词之间的关系, Transformer 会将句子中的每个字与所有单词进行计算,得出他们之间的相关度,而 确定该词在句子里更准确的意义。因此 Transformer 拥有更优的全局信息感知能力。
始于 NLP,逐步延伸到各大应用领域。在计算机视觉领域,早年卷积神经网络 (CNN)几乎占据统治地位,Transformer 出现后,大量基于 Transformer 及 CNN 和 Transformer 算法的结合体涌现,诞生了最初应用在图像识别领域的 Vision Transformer,应用在目标检测领域的 DETR,应用在分割领域的 SETR 等等诸多算法。 此外在其他领域,Transformer 也开始崭露头角,观察 Transformer 有关的论文,几年 之内,其所覆盖的领域迅速泛化,涵盖文本、图像、语音、视频等。
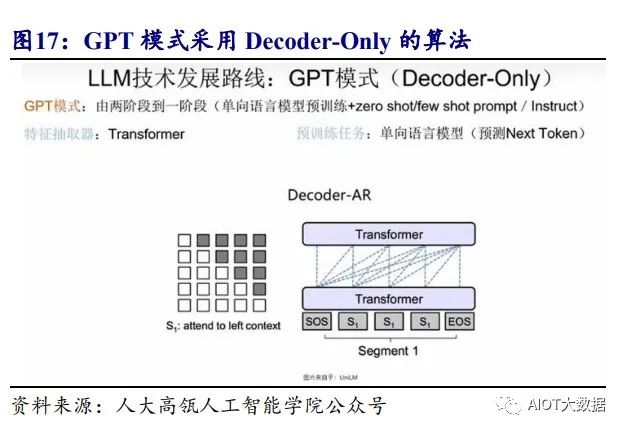
1.2.2、 大语言模型多基于 Transformer 构建,Decoder-Only 系列占优
大语言模型形成三大类别,Decoder-Only 系列占优。出色的性能让 Transformer 架构已经成为各种大语言模型的主干,前文提到 Transformer 结构由编码器和解码器 构成,而单独基于编码器或者解码器均可构建大语言模型,因此业内形成三类大模 型路线:Decoder-Only(仅解码器)、Encoder-Only(仅编码器)、Encoder-Decoder(编 码器-解码器)。其中采用 Encoder-Only 的有谷歌的 Bert、微软的 Deberta 等,其采用 “完形填空”式的预训练,再根据所需的应用领域用少量标注过的数据进行 Fine-tuning(微调)。采用 Decoder-Only 的有 GPT 等,其采用“预测下一个单词”的 方式进行预训练,之后通过指令微调等实现特定领域功能的激发。此外也有采用 Encoder-Decoder 架构的模型如谷歌的 T5、META 的 Bart、清华大学的 ChatGLM 等。 值得注意的是当 GPT3 推出后,大量基于 Decoder-Only 的算法涌现出来,成为主流 的大模型算法构建方式。
1.3、 大模型+预训练+人类反馈微调,大模型蓄势待发
1.3.1、 探求 ChatGPT 的能力来源,寻找构建大模型的有效方法
GPT 的能力来源于预训练+指令微调+基于人类反馈的强化学习。ChatGPT 的前 身为 GPT-3,基于 GPT-3,OpenAI 对大模型进行了诸多探索,开发出了多个可应用 于不同领域的模型。对比这些不同的模型,在初代的 GPT-3 上即展现出语言生成、 情景学习(in-context learning,遵循给定的示例为新的测试应用生成解决方案)、世 界知识(事实性知识和常识)等能力,而这些能力几乎都来自于大规模的预训练, 通过让拥有 1750 亿参数的大模型去学习包含 3000 亿单词的语料,大模型已经具备 了所有的基础能力。而通过指令微调(Instruction tuning),帮助大模型“解锁”特定领 域的能力如遵循指令来实现问答式的聊天机器人,或泛化到其他新的任务领域。而 基于人类反馈的强化学习(RLHF,Reinforcement Learning with Human Feedback)则 让大模型具备了和人类“对齐”的能力,即给予提问者详实、公正的回应,拒绝不当 的问题,拒绝其知识范围外的问题等特性。
1.3.2、 大参数+海量数据预训练+基于人类反馈的微调构成打造大语言模型的要素
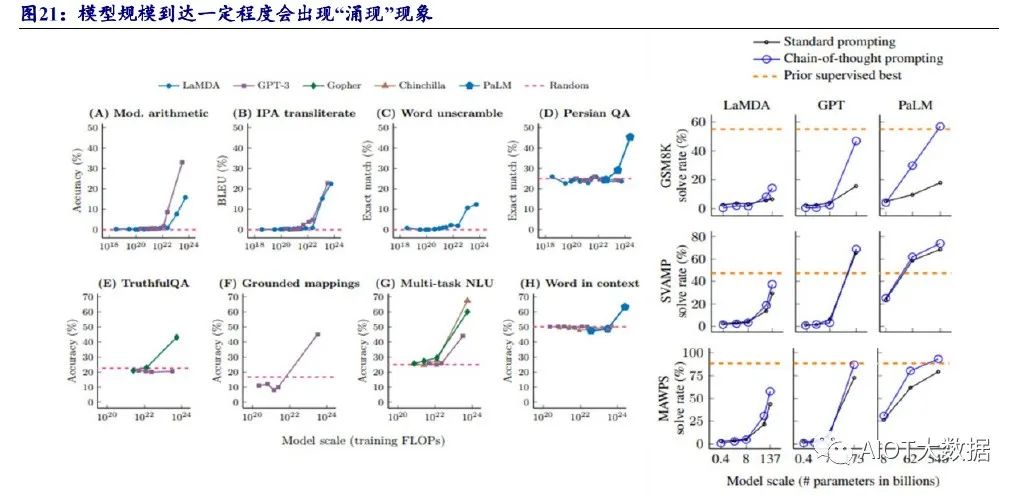
大参数量变带来质变,“涌现”现象带来大模型能力跃迁。当模型规模较小时, 模型的性能和参数大致符合比例定律,即模型的性能提升和参数增长呈现线性关系, 而当参数量上升到一定程度,模型的性能会突然跃迁,打破比例定律,实现质的飞 跃,这被称为模型的“涌现”能力。诸多研究发现,大参数量,配合海量数据训练, 大语言模型在 In-context learning(情景学习)、Instruct following(指令遵循)、Chain of thought(思维链,即可逐步解决问题)方面会出现“涌现”现象。因此模型拥有 较大参数量是其拥有超乎想象性能的前提。
海量数据预训练不可或缺。参数量庞大的大语言模型需要大量覆盖广泛内容的 高质量数据。目前的语料库包含网页、书籍、对话、百科、书籍、代码等。数据集 的规模和质量对模型的性能表现至关重要,大模型玩家采用独特的数据训练模型以 增强模型性能。如 Project Gutenberg(古腾堡计划)是一个经典的西方文学数据集, 其由超过 70000 本文学书籍组成,包括小说、诗歌、散文、戏剧、科学、哲学等诸 多类型作品,是目前最大的开源藏书之一,被用于 Meta 的大语言模型 LLaMA 以及 英伟达和微软联合推出的大语言模型 MT-NLG 的训练,而 GPT3 中所使用的 Books1 和 Books3 数据集则至今未公开发布。
恰当的模型微调亦尤为重要。预训练构筑模型强大的基础能力之后,恰当的模 型微调将赋予模型在特定领域的能力和与人类“对齐”的能力。在这里,模型调整 的方法繁多,以 ChatGPT 的训练过程为例,预训练好的基础模型进一步的训练通常 分为三步:(1)采用人工标注好的数据来训练模型;(2)通过人类对模型答案的排 序训练一个奖励模型;(3)使用奖励模型通过强化学习的方式训练 ChatGPT。其中 后两个步骤称为 RLHF(基于人类反馈的强化学习)。在 GPT4 的训练过程中,OpenAI 还进一步加入了基于规则的奖励模型(RBRMs)来帮助模型进一步生成正确的回答, 拒绝有害内容。可以看出模型微调对模型最终的效果实现至关重要,玩家独特的训 练和微调方法会让自己的模型形成独特的性能。
1.4、 多模态成为趋势,应用端千帆竞渡,人工智能迎来 iPhone 时刻
OpenAI 产品一经发布,全球掀起大模型研发的热潮,诸多巨头切入大模型开发 领域。在模型构建方面,ChatGPT 等产品提供良好范式,玩家可基于此方式构建自 己的产品。同时多模态的大模型已经成为玩家们的终极目标,而随着图像、视频数 据的介入,大模型的能力亦将实现进一步提升。在应用端,也呈现出繁荣发展的态 势,诸多玩家与大模型厂商合作以求探索新的业务和盈利模式。而随着后期多模态 等大模型的发展进一步加速,以及变得更准确、更可靠、更安全;基础大模型+特定 行业应用的业务形式会逐步铺开,人工智能赋能千行百业,有望再次引领新的“iphone” 时刻。
2、 大模型赋能自动驾驶,算法、数据闭环、仿真全面受益
2.1、 自动驾驶算法、数据不断迭代,长尾问题处理成为关键
自动驾驶算法从基于规则逐步走向神经网络,从模块化部署走向端到端一体化, Transformer+BEV 逐步成为主流。目前自动驾驶算法历经多年演变,呈现出几大特 点。首先,基于神经网络的算法逐步替代基于规则的算法,早年神经网络主要用于 感知环节,现在逐步在向规划控制环节渗透。其次,自动驾驶算法在早期以模块化 部署,每个模块拥有独立的优化目标,但整体模型的效果未必达到最优,因此端到 端的自动驾驶解决方案映入人们眼帘,学界和产业界均进行了诸多探索。最后,我 们看到行业玩家逐步认可 Transformer+BEV 的算法构建模式,模型架构上逐步走向 趋同,这无疑将推动包含芯片在内的整个产业链加速发展。
长尾问题处理是自动驾驶面临的主要挑战,数据驱动提供解药。当前,大部分 算法可以覆盖主要的行车场景,但驾驶环境纷繁复杂,仍有诸多罕见的长尾场景需 要算法识别和处理,这类场景虽不常见但无法忽视,成为制约自动驾驶成熟的主要 瓶颈。行业通常采用大量的数据去训练自动驾驶算法,以求让自动驾驶模型成为见 多识广的“老司机”。早期 Waymo 的路测、特斯拉的影子模式均希望通过获取大量 数据解决长尾问题。马斯克曾经在推特上赞同了实现超越人类的自动驾驶能力至少 需要 100 亿公里驾驶数据的说法。国内毫末智行将数据作为“自动驾驶能力函数” 的自变量,认为是决定能力发展的关键。Momenta 在其公众号上也表示 L4 要实现规 模化,至少要做到人类司机的安全水平,最好比人类司机水平高一个数量级,因此 需要至少千亿公里的测试,解决百万长尾问题。
自动驾驶在模型端仍需优化,数据闭环、仿真工具仍待完善。自动驾驶近年发 展迅猛,硬件预埋软件持续迭代的风潮下,车载算力急剧增长快速普及,但软件端 功能进化滞后于算力。软件端算法、数据闭环、仿真系统均有待完善。算法领域感 知、预测、决策、规划模型都在不断升级演进,精度、可靠性均有提升空间。数据 闭环系统方面,伴随有关车型量产,数据的挖掘、标注和处理工作量庞大,数据闭 环系统自动化高效运行决定模型能否由数据驱动持续迭代。仿真环节,理论上优质 仿真可替代实车数据收集,降低算法搭建成本并提升迭代速率,但逼真的仿真环境 的构建、诸多的长尾场景的复现难度大。
2.2、 大模型全面赋能,自动驾驶各大环节全面受益
蒸馏、剪枝、量化助力大模型在多场景应用。通常大型模型采用三种方式压缩: 蒸馏、剪枝、量化。蒸馏类似于老师教学生,将一个大模型或多个模型集学到的知 识迁移到另一个轻量级的模型上方便部署。剪枝可理解为将复杂的神经网络结构精 简使其变得轻量化。量化则为直接降低模型中的参数精度,进而实现模型轻量化。 基于多种模型压缩的方式,大模型也拥有了加速垂直行业的基础。
大模型可在算法、数据闭环、仿真等环节全面赋能自动驾驶。大模型具有良好 的认知和推理性能,作为人工智能最先落地的应用领域之一,自动驾驶有望得到全 面助力。首先在数据闭环和仿真环节,大模型的精准识别和数据挖掘以及数据生成 能力可对数据挖掘、数据标注、以及仿真场景构建赋能。其次在模块化的算法部署 模式下,感知算法、规控算法亦可受到大模型的加强而实现感知精度和规控效果的 提升。最后,端到端的感知决策一体化算法被认为是自动驾驶算法终局,但面临诸 多难以解决的问题,比如构建适合该算法的仿真换环境、端到端的数据标注等,而 在大模型时代以上问题或不再成为瓶颈,落地指日可待。
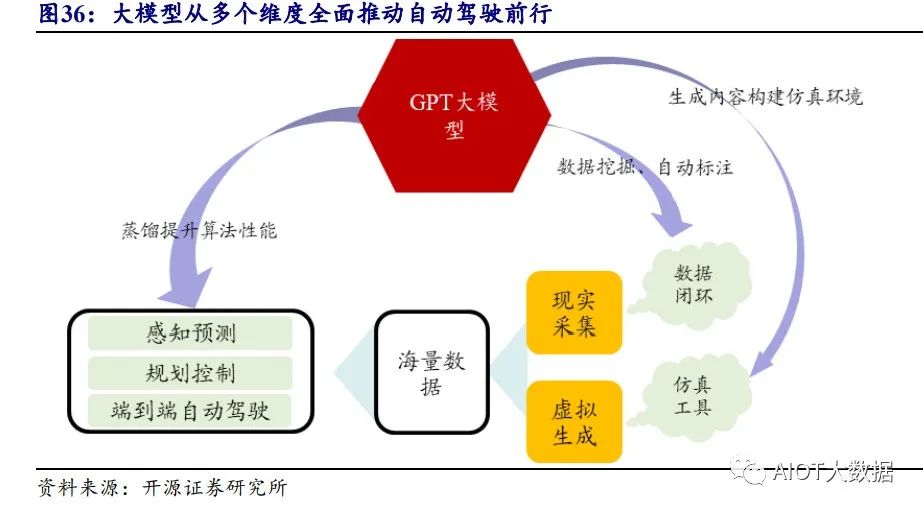
2.2.1、 大模型助力数据挖掘和自动标注,数据飞轮飞驰推动自动驾驶落地
在自动驾驶的数据闭环体系构建过程中存在数据挖掘和自动标注等难点。随着 量产车型数量增加,产生的数据量呈现指数级增长,一方面,高效的利用数据实现 预期的训练效果要求系统具有数据挖掘、处理能力。另一方面,海量数据的标注带 来高昂的成本,而部分 3D 场景人工标注较为困难,进一步限制算法模型迭代和应用, 大模型诞生后这两类问题有望迎刃而解。
数据挖掘:百度阿波罗应用大模型实现长尾数据挖掘
百度首先利用文字和图像输入编码器预训练一个原始模型用来实现向量搜索, 再利用算法将街景图像数据进行物体识别并定位和分割,经过图像编码器,形成底 库;简单来说就是基于街景建立一个拥有图片和文字信息对应的大模型。最后,面 向特定的场景(如快递车、轮椅、小孩等),可以通过文本、图像等形式进行搜索和 挖掘(类似向量数据库)。进而对自动驾驶模型进行定制化的训练,大幅提升存量数 据的利用效果。
自动标注:商汤毫末等玩家已经推动走向落地
商汤科技在大模型加持下,落地数据自动标注服务商汤明眸。公司多模态多任 务通用大模型书生 2.5 拥有强大的语义理解和图像处理能力,在 ImageNet 分类任务 开源模型中 Top1 准确率能超过 90%。基于此公司开发出商汤明眸自动标注服务,提 供结构化检测等 12 个行业专用大模型,涵盖超 1000 个不同的 2D、3D 目标类别, 大幅降低标注成本。
毫末智行开发 DriveGPT,并释放云端驾驶场景识别能力。毫末智行训练了 DriveGPT 大模型雪湖·海若,用户将驾驶场景上传到云端平台,平台能够快速将图 片中所有车道线、交通参与者(行人、自动车等)标注出来,单帧图像整体标注成 本降低至行业平均水平的十分之一。
2.2.2、 大模型推动算法迭代,感知规控全赋能
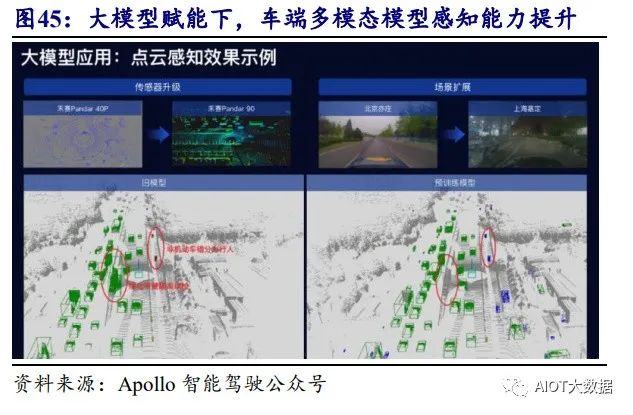
大模型在自动驾驶感知端算法的应用: 大模型作为车端算法的“老师”,通过“蒸馏(教授)”帮助小模型实现优异的 性能。百度将文心大模型的能力与自动驾驶感知技术结合,提升车载端侧模型的感 知能力。百度用半监督方法通过用 2D 和 3D 数据训练出一个感知大模型。其中“半 监督”是指首先利用标注好 2D 和 3D 数据训练一个感知大模型,再让大模型为未标 注的 3D 数据进行标注,接着用这些数据再次训练感知大模型,多次迭代后,大模型 的感知性能实现快速提升。应用这个大模型即可实现对视觉小模型、多模态模型感 知能力的加强。
(1)利用大模型赋能增强小模型远距离 3D 视觉感知:一方面通过大模型对图 像进行 3D 标注,投送给小模型学习。另一方面,在模型中编码器输出处、在 2D 和 3D 的头等位置,进行大模型到小模型的蒸馏帮助提升小模型性能。最后全面提升了 小模型的 3D 感知效果。
(2)利用大模型赋能多模态感知:面向车载端融合视觉激光雷达数据的自动驾 驶算法,同样使用伪标注(自动标注)、并在图像端和点云端进行知识蒸馏等方式, 全面提升了多模态模型的感知效果,识别出了此前没有识别出来的绿化带等信息。
大模型在规控端应用:毫末智行发布行业首个 DriveGPT
毫末智行推出 DriveGPT,可实现城市辅助驾驶、场景脱困、驾驶策略可解释等 功能。毫末智行在 2023 年 4 月的 AI DAY 上推出了业界首个 DriveGPT 大模型—— 雪湖·海若。模型训练过程参考 GPT,首先构建 1200 亿参数的大模型,预训练环节, 将自动驾驶空间的信息如车道线、感知环境等离散化后作为 Token 输入大模型,再 基于联合概率分布生成未来 Token 序列,将 4000 万公里中合适的数据放进大模型中。 即将外部环境作为预训练数据输入模型,训练模型预测未来情景演化的能力。人类 反馈强化学习(RLHF)环节,选取 5 万条人驾困难场景接管数据,输入预训练模型, 并将模型输出的行为进行排序,进行强化训练。同时在根据输入端的提示语及毫末 自动驾驶场景库的样本训练模型,让模型学习推理关系。最终训练好的模型,可将 完整的驾驶策略分拆为自动驾驶场景的动态识别过程,进而实现可理解、可解释的 推理逻辑链条。毫末智行的 DriveGPT 大模型将实现城市 NOH、街景推荐、智能陪 练、场景脱困等功能,云端,大模型将开放接口提供包括智驾能力、驾驶场景识别 等能力。
2.2.3、 生成海量数据,大模型助力仿真平台及端到端自动驾驶模型构建
大模型能够生成海量可训练数据,推动端到端自动驾驶模型落地。云骥智行认 为自动驾驶的终局会演进成为一个超大规模的端到端自动驾驶神经网络:AD-GPT。而为了实现它,自动驾驶神经网络、海量高价值数据、车端高算力平台缺一不可。 这些在模块化构建算法的时代难以实现,而当大模型诞生后,无论在车端一体化模 型的构建、还是端到端训练仿真数据的生成似乎都触手可及。究其本源,大模型本 质上是对输入信息作出反应,而自动驾驶则是这类行为中的一个子集。
商汤:公司提到,可以用 AIGC 生成真实的交通场景以及困难样本来训练自动 驾驶系统,以多模态数据作为大模型的输入,提升系统对 Corner Case 场景的感知能 力上限。同时自动驾驶多模态大模型可做到感知决策一体化集成,在输出端通过环 境解码器可对 3D 环境进行重建,实现环境可视化理解;行为解码器可生成完整的路 径规划;动机解码器可用自然语言对推理过程进行描述,使得自动驾驶系统变得更 加安全可靠可解释。
3、 自动驾驶渐行渐近,行业玩家乘风起
3.1、 科技巨头构筑自动驾驶行业“安卓”,技术鸿沟有望缩小
第三方玩家有望通过提供构建大模型的工具链,打造自动驾驶行业的“安卓系 统”,技术鸿沟有望缩小。特斯拉全栈自研的自动驾驶系统,包含算法、数据闭环系 统(自动标注、仿真、数据引擎)等,闭环的体系构成自动驾驶行业的“IOS”,海量的车队数据形成数据壁垒,其他玩家难以复制。而大模型时代,诸多第三方科技 巨头如微软、英伟达、百度、商汤等加入自动驾驶行列,可通过提供强大的大模型 构建能力以及完善的工具链帮助整车厂构建自己的自动驾驶算法和数据闭环系统, 同时依靠大模型的数据生成能力弥补与头部玩家在数据领域的差距,从而构建自动 驾驶领域的“安卓”,快速提升玩家自动驾驶能力。
科技巨头摩拳擦掌,微软、英伟达争相布局,有望加速行业发展。我们已经看 到,巨头如微软、英伟达在自动驾驶领域以及大模型领域都进行了深度布局,有望 将二者结合帮助车企实现能力飞跃。 微软:自动驾驶方面,微软通过微软云可提供覆盖全球的云计算和边缘计算能 力,借助云上的 PaaS 和 SaaS 软件可赋能各类算法和应用开发。2021 年,微软分别 投资通用旗下的自动驾驶子公司 Cruise 以及致力于构建端到端感知决策一体化算法 的自动驾驶创业公司 Wayve。微软打造完整的自动驾驶开发支持解决方案,帮助开 发者将数据进行导入分析,对模型进行训练仿真。微软基于虚幻引擎开发的 AirSim 仿真平台在无人机仿真领域扮演重要角色,该平台也同时可实现对无人驾驶汽车的 仿真。大模型方面,微软云推出了 Azure OpenAI 服务,企业可获得对大模型(含 GPT、Codex、嵌入模型)的访问权限并将其应用于新的场景如语言、代码、逻辑、 推理、理解等,同时也允许客户微调生成定制化的模型。而结合微软的认知搜索, 可以进一拓宽大模型的应用领域和提升应用效果。微软及 OpenAI 依托强有力的大模 型能力,未来或许能在自动驾驶算法、仿真领域擦出新的火花。
英伟达:自动驾驶方面,英伟达在自动驾驶领域布局已久,拥有从算法到底层 软件中间件再到芯片的全栈解决方案。英伟达 DriveSim 仿真平台基于虚幻引擎开发,能够提供核心模拟和渲染引擎,生成逼真的数据流,创建各种测试环境,模拟暴雨 和暴雪等各种天气条件,以及不同的路面和地形,还可以模拟白天不同时间的眩目 强光以及晚上有限的视野,达到“照片级逼真且物理精确”的传感器仿真。DriveSim 还拥有完善的工具链支持,如神经重建引擎(NER)可以将真实世界的数据直接带 入仿真中,开发者可在仿真环境中修改场景、添加合成对象,并应用随机化技术, 大大增加真实感并加快生产速度。大模型方面,英伟达进一步强化“卖铲人”地位, 帮助企业玩家构建自己的大模型产品。在 2023 年 GTC 大会上,英伟达推出 AI Foundations 云服务,用于帮助客户构建生成式 AI 模型如大语言模型、生物学模型、 AI 生成式图像模型等。而英伟达最新发布的两篇文献更展现了其在生成式 AI 及自 动驾驶领域的不懈探索,其中一篇推出了生成式视频模型 VideoLDM,可生成最高 分辨率 2048*1280,24 帧,最长 4.7 秒的视频,该模型拥有 41 亿个参数,可实现文 本生成视频等功能,在自动驾驶领域可生成驾驶场景视频以实现对特定场景的模拟, 也可以从同一个起始帧生成多个不同的事件演进方向来训练算法。而另一篇文献则 推出了神经场扩散模型 NeuralField-LDM,用于复杂世界开放世界 3D 场景生成,在 现有数据集中实现了最强性能,为高效实现自动驾驶仿真助力。
3.2、 行业分工加速,成本下降可期
行业分工加速,自动驾驶算法体系成本或迎下降。随着大模型逐步介入自动驾 驶,行业分工将进一步明确。第三方科技巨头的加持下,整车厂无需大规模搭建庞 杂的算法、数据等整个闭环体系的团队,即可拥有比肩全球一线水平的自动驾驶算 法模型体系。产业链分工合作,避免“重复造轮子”,自动驾驶的成本有望大幅降低, 渗透率将加速提升。同时,随着更多自动驾驶车型上路,数据收集效率和效果也会 进一步提升,反过来推动行业进步。
传感器和芯片加速迭代,自动驾驶系统整体成本亦有下降空间。大模型的推进 将加速芯片和传感器迭代,传感器方面,玩家有望能够以类似特斯拉的形式构建自 动驾驶系统,进而降低成本。算力芯片方面,大模型将进一步推升对芯片算力的需 求。而我们看到在车载高算力芯片领域,无论英伟达、高通还是本土的地平线、黑 芝麻均明确舱驾融合的芯片是未来的发展方向。这样的趋势将显著推动自动驾驶系 统降本,一方面,舱驾融合芯片通常会集成座舱、智驾甚至车身控制等域控制器功 能,大幅度缩减物料和线束成本;另一方面,AI 算力如果能在整车芯片层面“池化”, 在座舱、自动驾驶两大功能之间灵活调用,亦将提升 AI 算力的利用率,车上“冗余” 的算力可大幅缩减。大模型驱使下,行业舱驾融合产品上车趋势将加速,系统降本 紧随其后,自动驾驶渗透率也奖随之提升。
3.3、 大模型开发者、自动驾驶产业链玩家全面受益
3.3.1、 百度 Apollo:自动驾驶元老,文心大模型全面赋能
百度在自动驾驶领域的探索一马当先,大模型方面,在谷歌推出 Bert 后即开始 投入研发,起步较早,因此对于大模型在自动驾驶领域的应用深有心得。最新的 Apollo Day 及文心一言发布会上,百度表示将在自动驾驶感知算法、图文监督预训 练下的数据挖掘方案两个方向推动大模型赋能自动驾驶,全面助力自动驾驶能力提 升。同时百度亦拥有 Apollo 开放平台,对自动驾驶全流程开发体系拥有深厚积累, 并与诸多开发者形成紧密的互动,未来有望深度受益本轮技术变革。
3.3.2、 商汤科技:AI 算法领军,布局大模型探索自动驾驶新机遇
商汤利用大模型对小模型进行知识蒸馏,同时通过自动化标注实现感知和决策 端的数据闭环。此外大模型也可以生成困难图片,解码 3D 环境、路径规划、驾驶动 机等使得驾驶行为可解释。作为传统 AI 算法领域的领军,公司在自动驾驶算法领域 发力,目前产品已经落地多款车型。未来有望持续受益大模型在自动驾驶的应用。
3.3.3、 地平线:智驾芯片新星,对算法的深入理解指引芯片架构迭代完美适配需求
公司作为本土智能驾驶芯片领军,对算法及大模型理解深入,有望指引公司芯 片迭代以完美适应客户需求。地平线认为算法终将走向端到端的形式,因此公司也 在构建下一代的面向 Transformer 的统一计算架构,而其下一代 BPU 纳什架构将专 为大参数 Transformer 模型设计。地平线在 CVPR 中提出基于 Transformer 的端到端 的自动驾驶算法框架,该文章首次在检测、跟踪、预测、建图、轨迹预测、端到端 完成自动驾驶的算法,这可以让玩家用海量数据去训练整个自动驾驶系统。地平线 认为未来需继续用大数据和大模型无监督的预训练模型让其学习人类驾驶的常识。 语言模型是给定一个文本去预测下一个词的概率,同样给定当前交通环境/导航地图/ 驾驶员整个驾驶行为历史,模型亦可从大规模的无监督数据中学习,构建自回归的 大语言模型预测下一个驾驶动作。
3.3.4、 产业链玩家:自动驾驶落地加速,产业链各大环节全面受益
随着自动驾驶的全面加速,整个自动驾驶产业链包含域控制器、算法、传感器 等环节亦将加速渗透。
责任编辑:彭菁
-
人工智能
+关注
关注
1821文章
50367浏览量
267062 -
模型
+关注
关注
1文章
3831浏览量
52287 -
ChatGPT
+关注
关注
31文章
1600浏览量
10402
原文标题:智能汽车行业专题:大模型全面赋能,自动驾驶渐行渐近
文章出处:【微信号:AIOT大数据,微信公众号:AIOT大数据】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
诺基亚物联网平台横空出世 已经做了哪些布局?
国产8核5G芯片横空出世,不是华为是他
【「大模型启示录」阅读体验】+开启智能时代的新钥匙
科技大厂竞逐AIGC,中国的ChatGPT在哪?
塑料卡片电池横空出世(传统电池被颠覆)
还没完全普及的Wi-Fi 6 将迎来Wi-Fi 6E横空出世
Intel的第十代酷睿i7-10870H横空出世
ChatGPT浪潮下,看中国大语言模型产业发展

贾扬清质疑Groq CEO“其芯片价格接近免费” 前员工:不切实际!
针对高速光模块应用,小华半导体推出HC32F472系列模拟丰富MCU新品




评论