 惊!大脑视觉信号被Stable Diffusion复现成视频!
惊!大脑视觉信号被Stable Diffusion复现成视频!
例如你坐在副驾所欣赏到的沿途美景信息,AI分分钟给重建了出来:

看到过的水中的鱼儿、草原上的马儿,也不在话下:


这就是由新加坡国立大学和香港中文大学共同完成的最新研究,团队将项目取名为MinD-Video。

Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity 主页:https://mind-video.com/ 论文:https://arxiv.org/abs/2305.11675 代码:https://github.com/jqin4749/MindVideo
这波操作,宛如科幻电影《超体》中Lucy读取反派大佬记忆一般:

引得网友直呼:
推动人工智能和神经科学的前沿。
值得一提的是,大火的Stable Diffusion也在这次研究中立了不小的功劳。
怎么做到的?
从大脑活动中重建人类视觉任务,尤其是功能磁共振成像技术(fMRI)这种非侵入式方法,一直是受到学界较多的关注。
因为类似这样的研究,有利于理解我们的认知过程。
但以往的研究都主要聚焦在重建静态图像,而以高清视频形式来展现的工作还是较为有限。
之所以会如此,是因为与重建一张静态图片不同,我们视觉所看到的场景、动作和物体的变化是连续、多样化的。
而fMRI这项技术的本质是测量血氧水平依赖(BOLD)信号,并且在每隔几秒钟的时间里捕捉大脑活动的快照。
相比之下,一个典型的视频每秒大约包含30帧画面,如果要用fMRI去重建一个2秒的视频,就需要呈现起码60帧。
因此,这项任务的难点就在于解码fMRI并以远高于fMRI时间分辨率的FPS恢复视频。
为了弥合图像和视频大脑解码之间差距,研究团队便提出了MinD-Video的方法。
整体来看,这个方法主要包含两大模块,它们分别做训练,然后再在一起做微调。
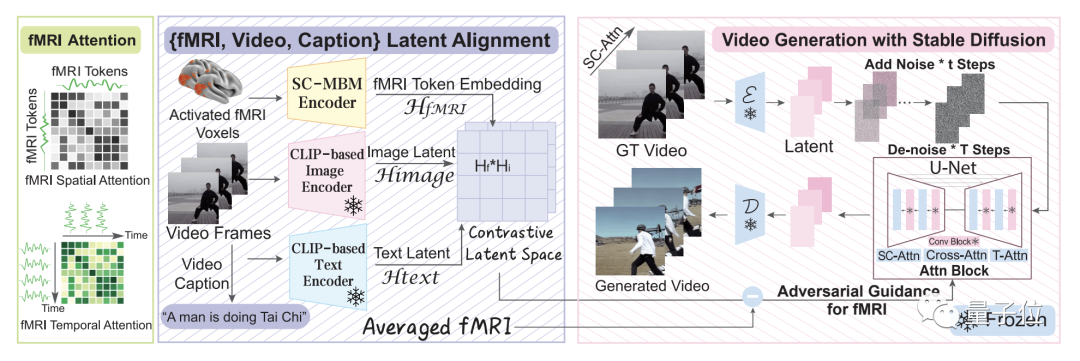
这个模型从大脑信号中逐步学习,在第一个模块多个阶段的过程,可以获得对语义空间的更深入理解。
具体而言,便是先利用大规模无监督学习与mask brain modeling(MBM)来学习一般的视觉fMRI特征。
然后,团队使用标注数据集的多模态提取语义相关特征,在对比语言-图像预训练(CLIP)空间中使用对比学习训练fMRI编码器。
在第二个模块中,团队通过与增强版Stable Diffusion模型的共同训练来微调学习到的特征,这个模型是专门为fMRI技术下的视频生成量身定制的。
如此方法之下,团队也与此前的诸多研究做了对比,可以明显地看到MinD-Video方法所生成的图片、视频质量要远优于其它方法。
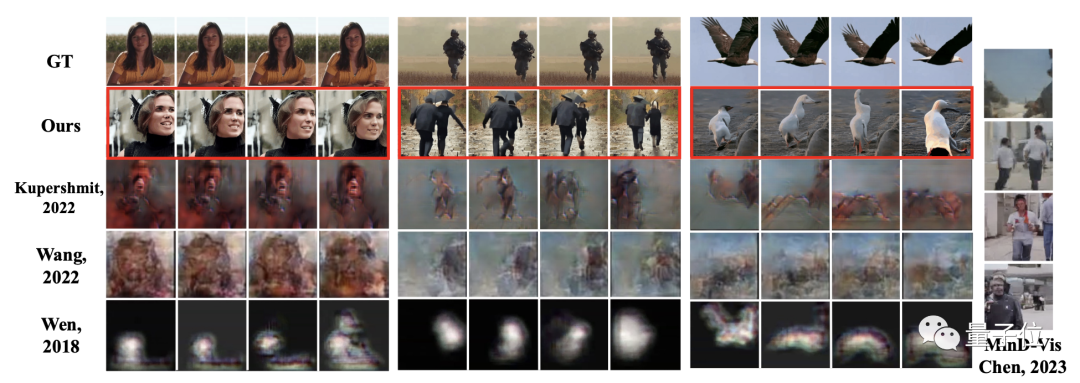
而且在场景连续变化的过程中,也能够呈现高清、有意义的连续帧。

研究团队
这项研究的共同一作,其中一位是来自新加坡国立大学的博士生Zijiao Chen,目前在该校的神经精神疾病多模式神经成像实验室(MNNDL_Lab)。
另一位一作则是来自香港中文大学的Jiaxin Qing,就读专业是信息工程系。
除此之外,通讯作者是新加坡国立大学副教授Juan Helen ZHOU。
据了解,这次的新研究是他们团队在此前一项名为MinD-Vis的功能磁共振成像图像重建工作的延伸。
MinD-Vis已经被CVPR 2023所接收。

审核编辑 :李倩
-
AI
+关注
关注
87文章
31000浏览量
269345 -
人工智能
+关注
关注
1792文章
47354浏览量
238837 -
视觉
+关注
关注
1文章
147浏览量
23977
原文标题:惊!大脑视觉信号被Stable Diffusion复现成视频!"AI读脑术"又来了!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

HDMI光端机:打造高清视频信号传输的桥梁
常见的视频接口有哪些
PCB视频板 —— 开启视觉盛宴的关键之匙
示波器的波形存储与复现,再也不怕瞬时信号抓不住了

实操: 如何在AirBox上跑Stable Diffusion 3

STM32F4在APP运行时导致IAP程序被修改怎么解决?
怎样检测被测电路的差分信号和单端信号?

UL Procyon AI 发布图像生成基准测试,基于Stable Diffusion
Stability AI推出全新Stable Video 3D模型
Stability AI推出Stable Video 3D模型,可制作多视角3D视频
韩国科研团队发布新型AI图像生成模型KOALA,大幅优化硬件需求
OpenAI视频模型Sora的架构及应用场景
Stability AI试图通过新的图像生成人工智能模型保持领先地位






 工商网监
工商网监
评论