 阿里&华科大提出ONE-PEACE:更好的通用表征模型,刷新多个SOTA!
阿里&华科大提出ONE-PEACE:更好的通用表征模型,刷新多个SOTA!
上次介绍ImageBind给大家预告了我们近期会推出一个新工作,今天正式推出我们的通用多模态表征模型ONE-PEACE,拿到多个SOTA,展现emergent zeroshot的能力。正式放arxiv,github repo刚开,欢迎关注以及给个star支持下!

ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities
论文:https://arxiv.org/abs/2305.11172
代码:https://github.com/OFA-Sys/ONE-PEACE
为什么是通用多模态表征模型
表征模型的重要性无需多言,尤其CLIP之后大家都意识到一个好的多模态表征模型在很多单模态任务上都会发挥着至关重要的基础模型的作用。学习了大量模态alignment的数据之后的模型逐渐在学会去理解各个模态和模态间蕴含的知识。但过去大部分模型,基本都把重点关注在图文数据上了,主要还是得益于社区贡献了大量高质量的如LAION这类的数据集。然而如果想更进一步去理解世界,我们希望能够把全世界各种模态的信息关联在一起,至少我们希望看到一个prototype来说明怎么实现一个不限模态(unlimited modalities)的通用表征模型。
ImageBind算是跨出了重要的一步,但我之前文章提了我的个人观点,就是采用小规模其他模态和图像的对齐数据来实现其他模态encoder和CLIP的vision encoder的方案,这类取巧的方案成本低实现容易,也能拿到不错的结果,但真想做到足够好,还有一定距离。
我们大概去年意识到这个问题开始尝试做这个事情,相对来说两位核心输出的同学做起来有点苦哈哈,辛苦去收集数据和吭吭搞大规模预训练。不过功夫不负有心人,我们还是一把输出了一个4B规模的通用表征模型(图文音三模态统一),在语义分割、音文检索、音频分类和视觉定位几个任务都达到了新SOTA表现,在视频分类、图像分类图文检索、以及多模态经典benchmark也都取得了比较领先的结果。另外,模型展现出来新的zeroshot能力,即实现了新的模态对齐,比如音频和图像的对齐,或者音频+文字和图像的对齐,而这类数据并没有出现在我们的预训练数据集里。下面我来具体介绍下方法实现
ONE-PEACE的方法
总体而言,ONE-PEACE的模型结构核心还是基于transformer,只不过针对多模态做了特殊的设计,当然这里也得感谢前人的很多工作积累了非常多有用的经验。预训练任务的思路就是几个重要的多任务训练,围绕contrastive learning展开。模型架构和训练方法整体如下图所示:
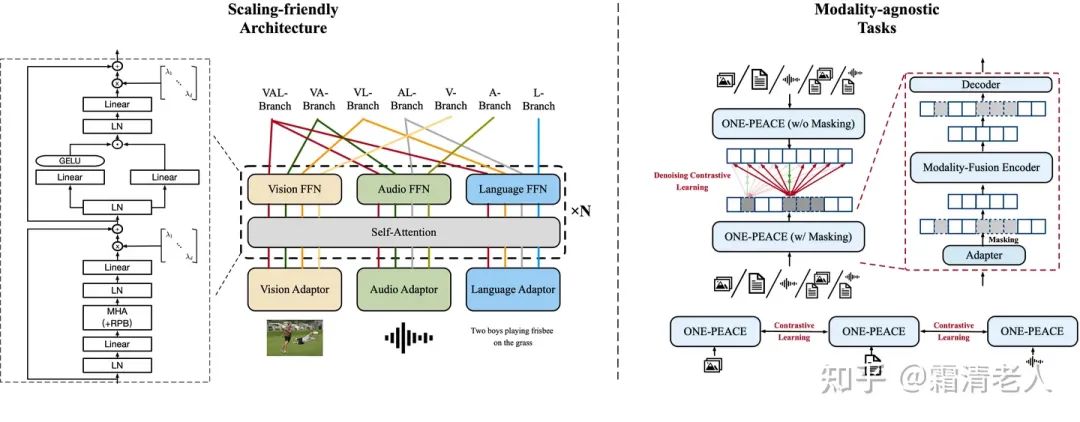
模型结构本质上还是transformer,处理方法和我们之前做OFA接近,通过各自模态的adaptor实现信息的向量化,传入Transformer engine。这里language adaptor就是最简单的word embedding,vision adaptor采用了hierarchical MLP,相比过去使用ResNet或者CLIP ViT成本更低,audio adaptor采用的是convolutional feature extractor。输入Transformer模型后,我们希望模型既有统一处理的部分,也有模态特定的处理部分。参考VLMo和BeiT-3的成功经验,我们将FFN部分设计成multiway(Modality-specific MoE)的方式,每个模态包含各自的FFN层。而在Transformer内部,主要实现了几处改动。一是GeGLU的引入,相比GeLU能实现更好的效果;二是相对位置编码,实现更好的position表示;三是使用了Magneto的方案,在attention和FFN均新增layernorm增加训练稳定性,四是使用LayerScale,同样能够提升训练稳定性。
训练方法上,我们主要围绕对比学习展开,只不过实际实现并非只使用一个模态一个embedding然后做InfoNCE的方案。这部分主要分为两类任务:
跨模态对比学习:这部分可以认为和CLIP的训练方法类似,只不过扩展到更多的模态组合,从而实现模态和模态之间的对齐。这里我们同样没有遍历所有模态的两两组合,而选用文本作为中介。
模态内去噪对比学习:名字有点拗口,这里用的词是intra-modal denoising contrastive learning。这个任务的本质是masked element(language/image/audio)modeling,但走的是feature distillation的路线。之后有机会整理下feature distillation这条线的工作,在表征学习上还是取得不错的进展。那么这里的masked element modeling,用的是拿没被mask的输入得到的表征作为teacher指导被mask输入得到的表征这个student。有别于对应位置向量做L1/L2 loss的经典方案,这里用的是对比学习。
整个训练分为两个阶段,第一个阶段可以理解为奠定基础的训练,即经典的图文数据预训练。在这一部分图文相关的参数都会被更新,包括self attention以及这两个模态各自的FFN。而训练完备后,如果要增加新的模态,比如语音,只需要使用语音-文本对数据继续预训练,而这个阶段就只有语音相关的参数会被更新,比如语音adaptor和语音FFN等。这种增加模态的方案同样可以不断拓展到更多模态上,只要使用上能够align上其中一个模态的配对数据即可,而且因为很多参数共用,相比重新训一个modality specific的encoder更容易拿到好结果。
实验效果
实验分为finetuning和zeroshot两个部分,其中finetuning更多追求效果上的绝对提升,而zeroshot则是观测其本身作为通用模型的表现,尤其是emergent zeroshot capabilities这个部分更是展现这种模型能够达到类比无监督训练的效果。
这里我调换下顺序先介绍下比较有趣的emergent zeroshot capabilities。这里我们没有合适的benchmark去评估,但是可以看不少有趣的例子。可以看到,模型不仅实现了新的模态对齐,还学会组合不同模态的元素去对齐新的模态。比如一个经典的例子就是语音+文本召回图片,比如snow这个文本配上鸟叫的声音,就能召回鸟在雪中的图片,挺有意思。下面给出更多例子:

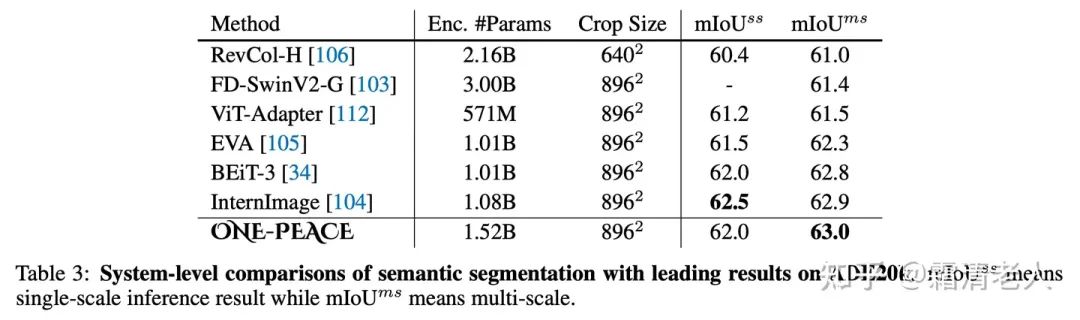
再看finetuning部分,ONE-PEACE主要在CV的任务上表现比较突出。其中在ADE20K上做语义分割,超出了EVA、BeiT-3、InternImage等一众SOTA模型:
在MSCOCO上做物体检测和实例分割仅次于RevCol,并且ONE-PEACE并没有做Object365的intermediate finetuning:

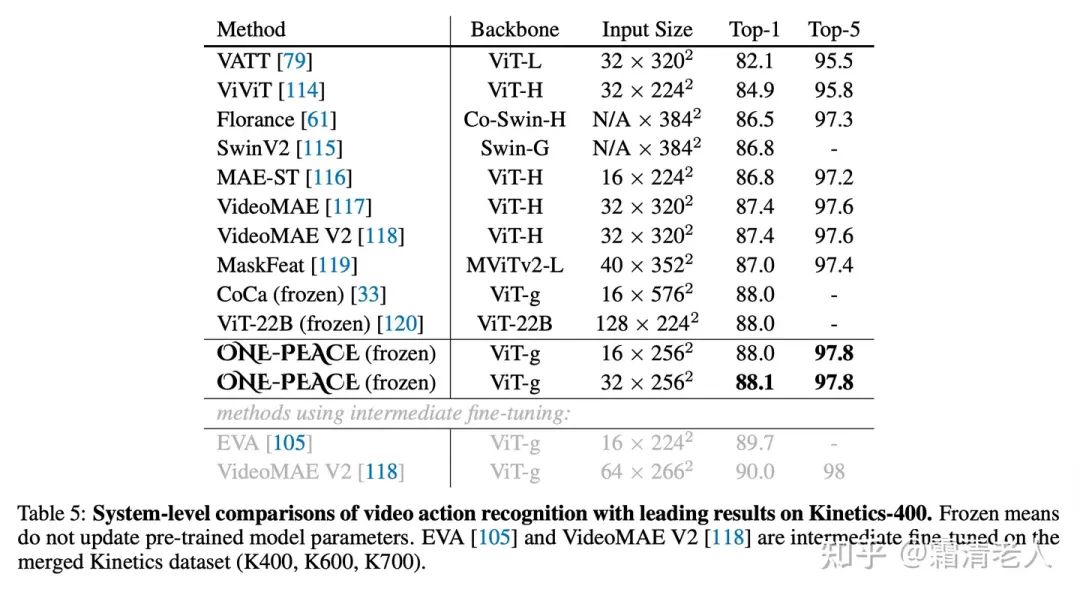
视频分类的K400上,也达到88.1,超过了之前诸如CoCa的模型:
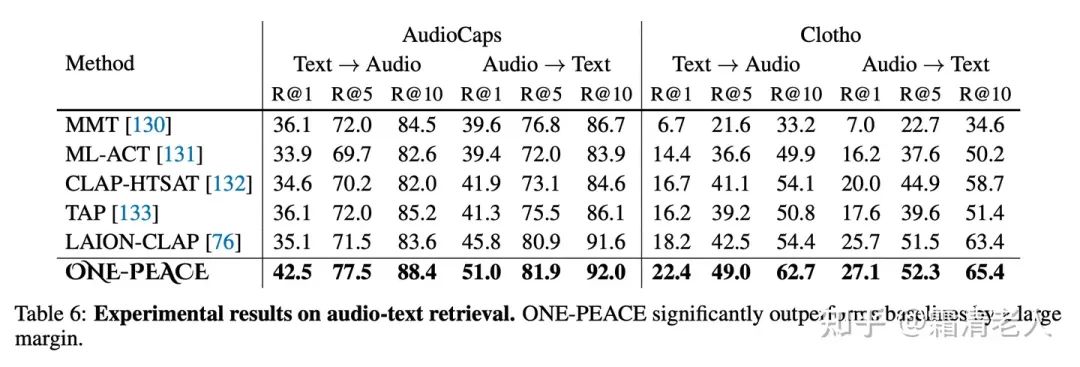
而落到语音领域,不管在音文检索、音频分类还是语音VQA上,都实现了新的SOTA,超过了LAION的LAION-CLAP:
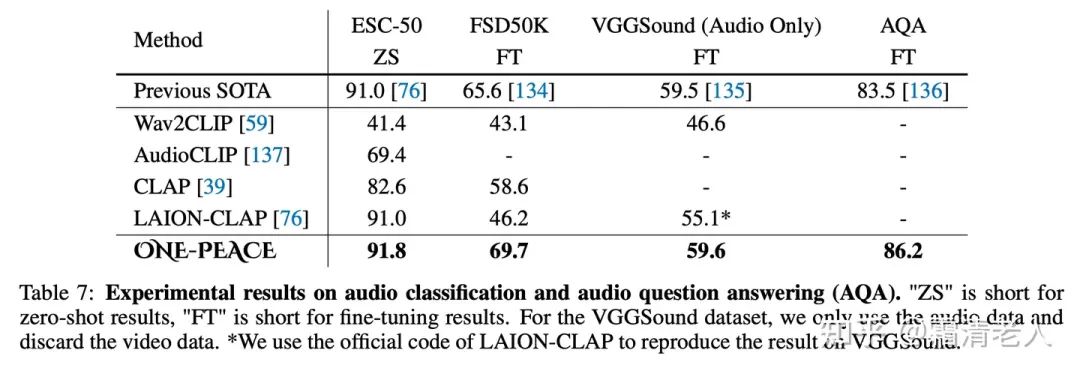
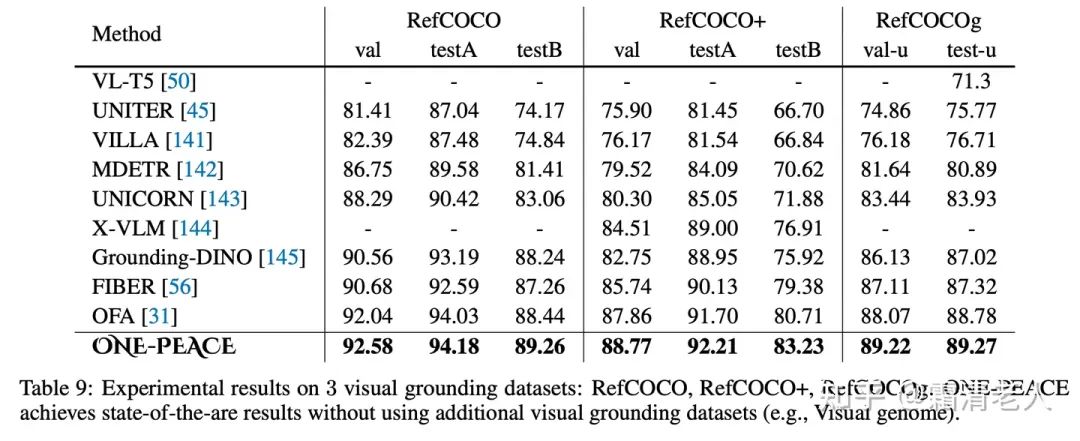
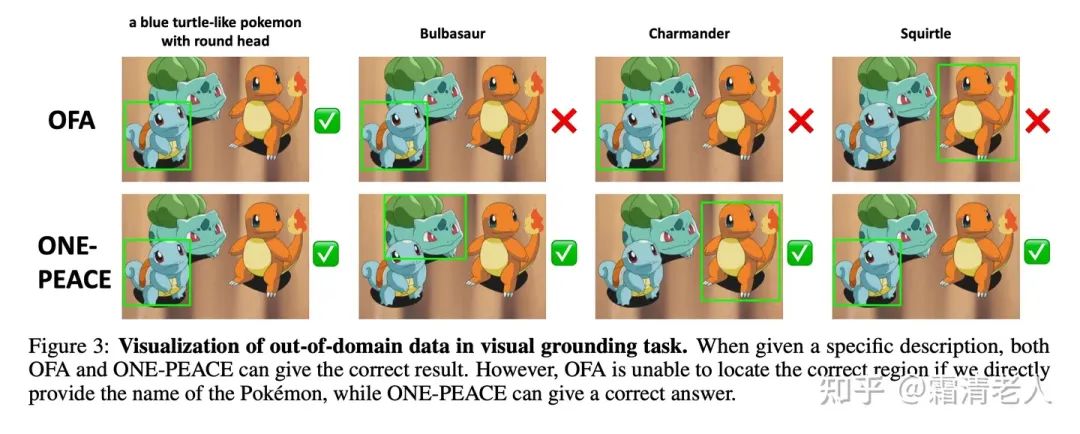
经典的多模态benchmark上,在视觉定位这个任务上ONE-PEACE直接达到了SOTA表现,并且在out-of-domain的setup下面也有很robust的表现:
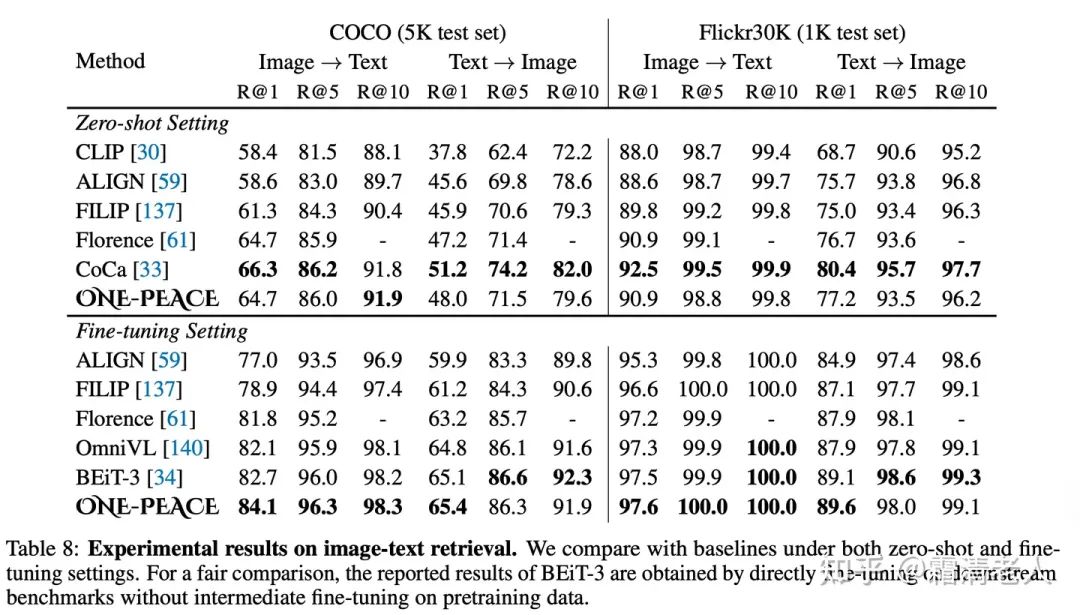
图文检索上,我们主要和没有经过intermediate finetuning的模型进行比较,主要对标的是双塔召回模型,同样可以看到ONE-PEACE不俗的表现:
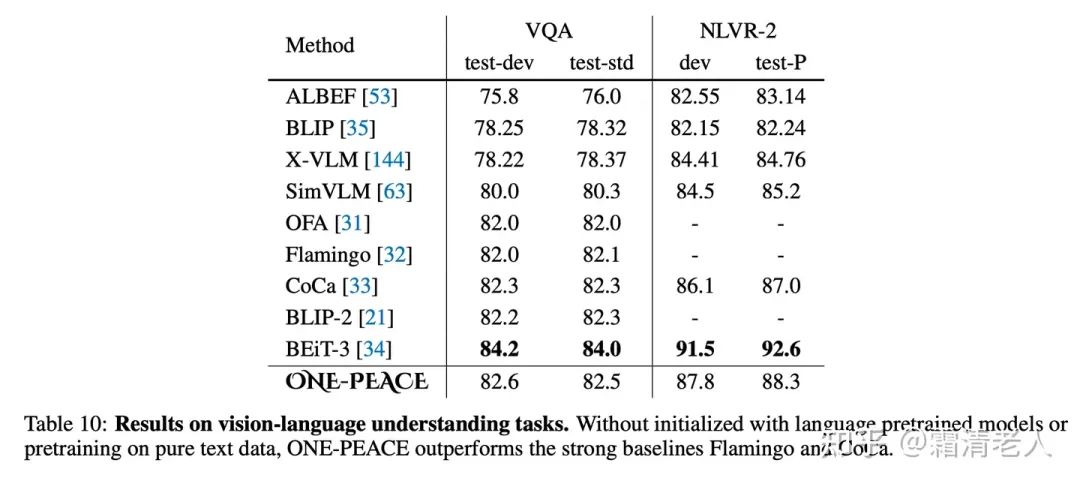
VQA和NLVR-2属实肝不动BeiT-3,不过相比其他基本都有明显优势:
当然,说这么多效果方面的东西,只是为了证明这个模型还是比较能打的。虽然没法全部刷新那么狠,但可以看到一个模型可以做到整体这个效果,应该拉出去实际场景用用还是可以的。
不足与未来工作
不足之处其实上文也可以看到确实有些效果没太做到顶,但仅仅追求SOTA意义其实不大。下一步我们要做的,其实是给出更多成功的实践将这个模型扩展更多模态,尤其是对比如视频这类复杂模态,怎么在真正高难度的任务上做得更好。另外,表征模型的潜力绝不仅仅只是在finetuning,也不在单纯的zeroshot检索,而在于其良好的对齐从而通过通用大模型做更复杂的人物,比如结合LLM。当前多模态LLM这个赛道发展如火如荼,ONE-PEACE怎么实现和强大的LLM结合,从而实现对世界的跨模态复杂任务的处理,也许相比追求benchmark更加关键。
审核编辑 :李倩
-
图像
+关注
关注
2文章
1086浏览量
40492 -
模型
+关注
关注
1文章
3254浏览量
48893 -
数据集
+关注
关注
4文章
1208浏览量
24726
原文标题:阿里&华科大提出ONE-PEACE:更好的通用表征模型,刷新多个SOTA!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
IGBT的物理结构模型—BJT&MOS模型(1)
厉害了!阿里安全图灵实验室在ICDAR2017 MLT竞赛刷新世界最好成绩
Slew Rate of Op Amp Circuits
存储类&作用域&生命周期&链接属性

如何区分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),为true,你敢信?

摄像机&amp;amp;雷达对车辆驾驶的辅助
中科大&amp;字节提出UniDoc:统一的面向文字场景的多模态大模型
低成本扩大输入分辨率!华科大提出Monkey:新的多模态大模型

高分工作!Uni3D:3D基础大模型,刷新多个SOTA!






 工商网监
工商网监
评论