 优化 Stable Diffusion 在 GKE 上的启动体验
优化 Stable Diffusion 在 GKE 上的启动体验

以下文章来源于谷歌云服务,作者 Google Cloud
背景
现如今随着 AIGC 这个话题越来越热,越来越多优秀的开源项目基于文生图的 AI 模型如 MidJourney,Stable Diffusion 等应运而生。Stable Diffusion 是一个文字生成图像的 Diffusion 模型,它能够根据给定任何文本输入生成逼真的图像。我们在 GitHub Repo 中提供了三种不同的解决方案 (可参考https://github.com/nonokangwei/Stable-Diffusion-on-GCP),可以快速地分别在 GCP Vertex AI,GKE,和基于 Agones 的平台上部署 Stable Diffusion,以提供弹性的基础设施保证 Stable Diffusion 提供稳定的服务。本文将重点讨论 Stable Diffusion 模型在 GKE 上的实践。
提出问题
在实践中,我们也遇到了一些问题,例如 Stable Diffusion 的容器镜像较大,大约达到 10-20GB,导致容器在启动过程中拉取镜像的速度变慢,从而影响了启动时间。在需要快速扩容的场景下,启动新的容器副本需要超过 10 分钟的时间,严重影响了用户体验。

我们看到容器的启动过程,按时序排列:
●触发 Cluster Autoscaler 扩容 + Node 启动并调度 Pod: 225s
●启动 Pull Image:4s
●拉取镜像: 5m 23s
●启动 Pod:1s
●能够提供 sd-webui 的服务 (大约): > 2m
在这段时序分析中,我们可以看到,在 Stable Diffusion WebUI 运行在容器上启动慢主要面临的问题是由于整个 runtime 依赖较多,导致容器镜像太大从而花费了很长时间拉取下载、也造成了 pod 启动初始化加载时间过长。于是,我们考虑优化启动时间从以下三个方面入手:
●优化 Dockerfile,选择正确的 base image,精简 runtime 的依赖安装,减小镜像大小。
●借助基础环境与 runtime 依赖分离方式,通过磁盘复制方式加速运行环境的创建。
●通过 GKE Image Streaming 优化镜像加载时间,利用 Cluster Autoscaler 提升弹性扩缩容速度。
本文着重为大家介绍通过基础环境与 runtime 依赖分离方式,借助磁盘复制的高性能来优化 Stable Diffusion WebUI 容器启动时间的方案。
优化 Dockerfile
首先,我们可以参考官方 Stable Diffusion WebUI 安装说明,生成其 Dockerfile。在这里给大家一个参考: https://github.com/nonokangwei/Stable-Diffusion-on-GCP/blob/main/Stable-Diffusion-UI-Agones/sd-webui/Dockerfile
在初始构建的 Stable Diffusion 的容器镜像中,我们发现除了基础镜像 nvidia runtime 之外,还安装了大量的库和扩展等。
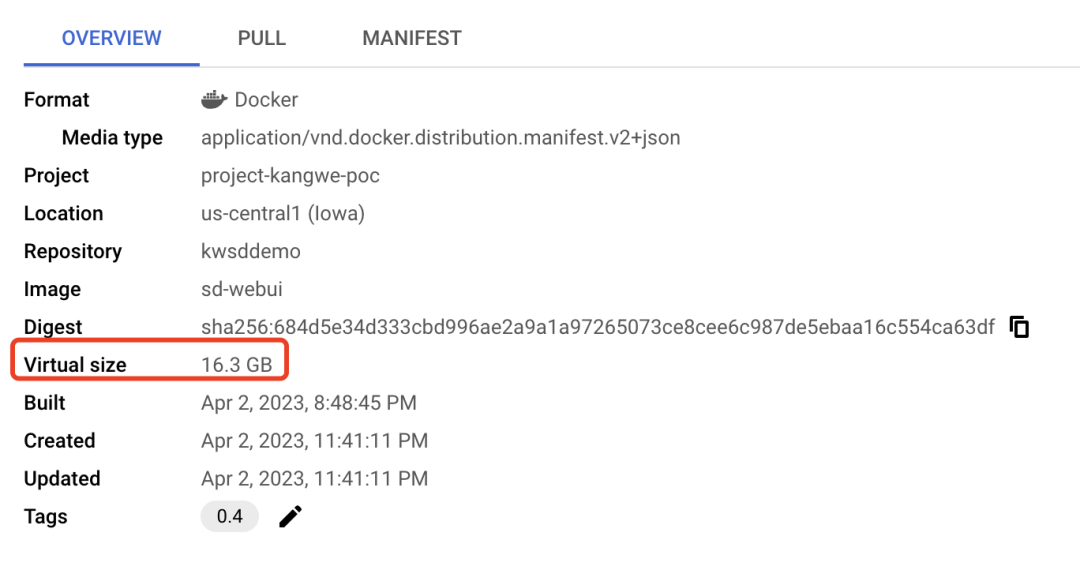
▲调优之前容器镜像大小为 16.3GB
在 Dockerfile 优化方面,我们对 Dockerfile 进行分析后,发现 nvidia runtime 约占 2GB,而 PyTorch 库是一个非常大的包,约占 5GB。另外 Stable Diffusion 及其扩展等也占据了一定的空间。因此,我们按照最小可用环境为原则,去除环境中不必要的依赖。将 nvidia runtime 作为基础镜像,然后把 PyTorch、Stable Diffusion 的库和扩展等从原始镜像中分离出来,单独存放在文件系统中。
以下是初始的 Dockerfile 的片段。
我们在移除 Pytorch 的库和 Stable Diffusion 之后,我们只保留了基础镜像 nvidia runtime 在新的 Dockerfile 中。

▲基础镜像变成了 2GB
其余的运行时类库和 extension 等存放在磁盘镜像中,磁盘镜像的大小为 6.77GB。采用磁盘镜像的好处是,它可以最多支持同时恢复 1,000 块磁盘,完全能满足大规模扩缩容的使用场景。

挂载磁盘到 GKE 节点
然而,问题来了,如何将这个单独的文件系统挂载到容器运行时中呢?一种想法是使用 Persistent VolumeClaim (PVC) 进行挂载,但由于 Stable Diffusion WebUI 在运行时既需要读取又需要写入磁盘,而 GKE 的 PD CSI 驱动程序目前不支持多写入 ReadWriteMany,只有像 Filestore 这样的 NFS 文件系统才能支持,但是通过网络挂载的 Filestore 就延迟来说仍然无法达到快速启动的效果。同时,由于 GKE 目前不支持在创建或更新 Nodepool 时挂载磁盘,所以我们考虑使用 DaemonSet 在 GKE 节点启动时挂载磁盘。具体做法如下:
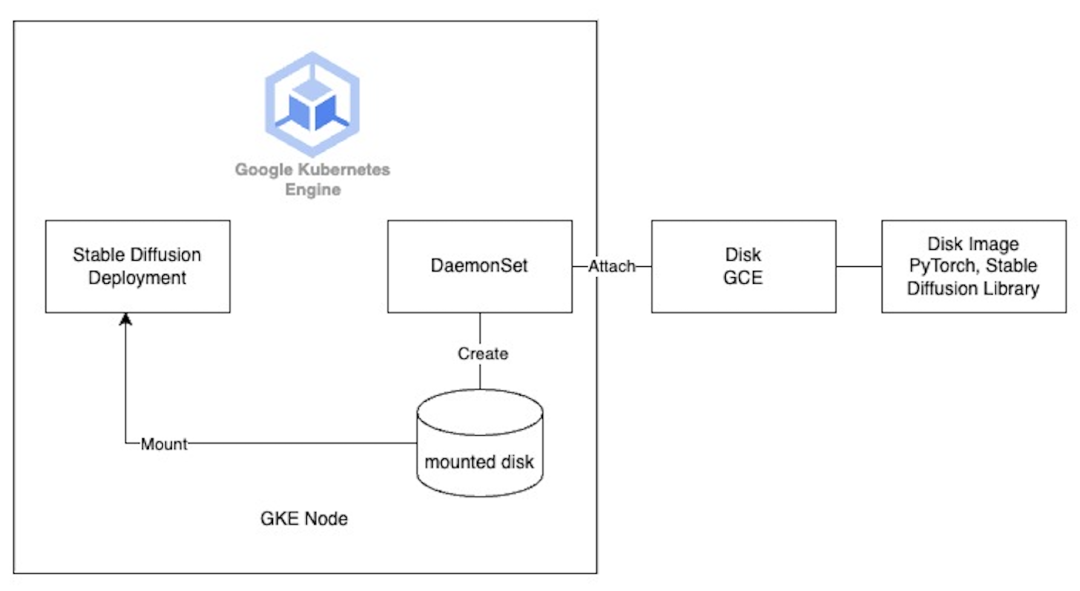
那么如何将磁盘挂载到 GKE 的节点上呢?可以直接调用 Cloud SDK,创建基于磁盘镜像的磁盘。
利用 GKE Image Streaming
和 Cluster Autoscaler
另外,正如我们前面提到的那样,在优化镜像下载和加载时间方面,我们还启用了 GKE Image Streaming 来加速镜像的拉取速度。它的工作原理是使用网络挂载将容器数据层挂载到 containerd 中,并在网络、内存和磁盘上使用多个缓存层对其进行支持。一旦我们准备好 Image Streaming 挂载,您的容器就会在几秒钟内从 ImagePulling 状态转换为 Running (无论容器大小);这有效地将应用程序启动与容器映像中所需数据的数据传输并行化。因此,您可以看到更快的容器启动时间和更快速的自动缩放。
我们开启了 Cluster Autoscaler 功能,让有更多的请求到来时,GKE 节点自动进行弹性扩展。通过 Cluster Autoscaler 触发并决定扩展到多少个节点来接收新增的请求。当 CA 触发了新的一轮扩容,新的 GKE 节点注册到集群以后,Daemonset 就会开始工作,帮助挂载存储了 runtime 依赖的磁盘镜像,而 Stable Diffusion Deployment 则会通过 HostPath 来访问这个挂载在节点上的磁盘。
我们还使用了 Cluster Autoscaler 的 Optimization Utilization Profile 来缩短扩缩容时间、节省成本并提高机器利用率。
最后的启动效果如下:
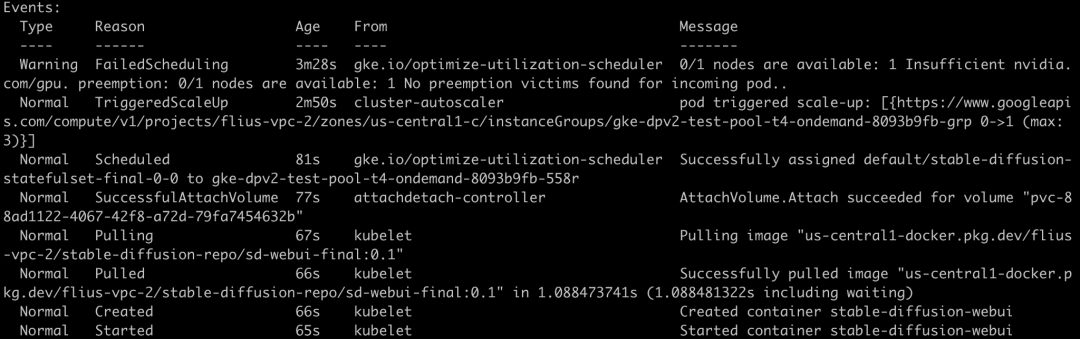
按时序排列
●触发 Cluster Autoscaler 扩容:38s
●Node 启动并调度 Pod:89s
●挂载 PVC:4s
●启动 Pull Image:10s
●拉取镜像:1s
●启动 Pod:1s
●能够提供 sd-webui 的服务 (大约): 65s
总共经历了大约 3 分钟的时间,就完成了启动一个新的 Stale Diffusion 容器实例,并在一个新的 GKE 节点上进行正常服务的过程。相比于之前的 12 分钟,可以看见,明显的提升启动速度改善了用户体验。
完整代码: https://github.com/nonokangwei/Stable-Diffusion-on-GCP/tree/main/Stable-Diffusion-UI-Agones/optimizated-init
通过 VolumeSnapshot
除了挂载 Disk 到 GKE 节点上,还有一种尝试,我们可以使用 StatefulSet 来挂载 PVC。
具体做法如下:先定义一个 storageclass,注意我们使用DiskImageType: images来指定 PVC从 Disk Image 来恢复,而不是 Snapshot。
●Snapshot 每 10 分钟只能恢复一次,一小时以内恢复 6 次 Disk 的限制。
●而 Image 可以支持每 30 秒恢复一次,最多 1,000 个 Disk。
再定义一个 VoluemSnapShotContent,它指定了 source 为一个 Disk Image sd-image。
接下来,我们再创建一个 VolumeSnapShot,指定它的 source 是刚刚定义的VoluemSnapShotContent。
最后,我们创建一个 StatefulSet 来挂载这个 VolumeSnapShot。
我们尝试扩容更多的副本。
可见 GKE 可以支持并行的启动这些 Pod,并且分别挂载相应的磁盘。
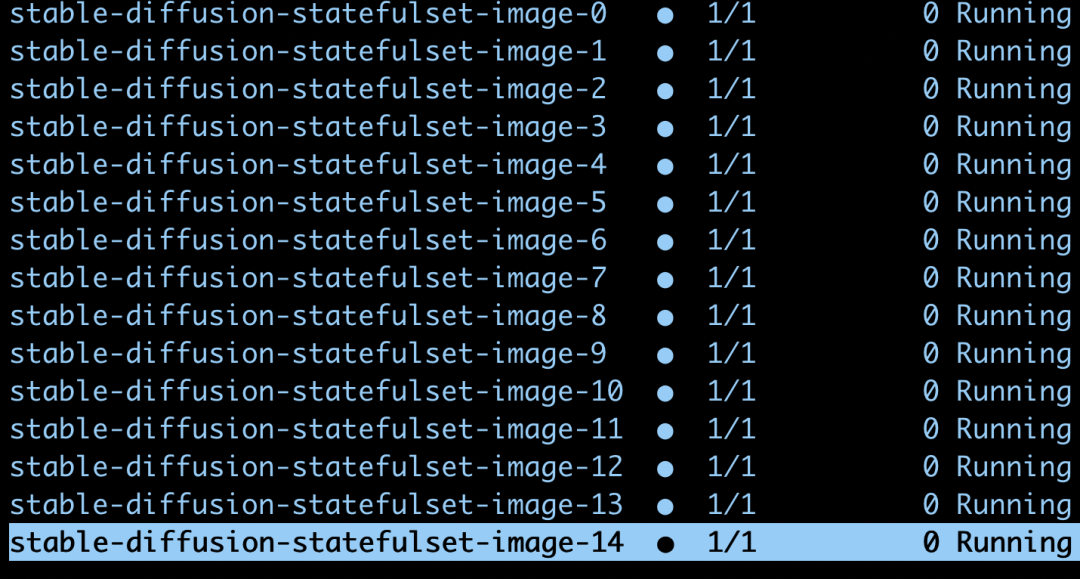
PersistentVolumeClaims

完整代码:
https://github.com/Leisureroad/volumesnapshot-from-diskimage
最终,我们可以看见如下的 Stable Diffusion 的 WebUI。

 点击屏末|阅读原文|了解更多 Google Cloud 技术趋势与最新解读
点击屏末|阅读原文|了解更多 Google Cloud 技术趋势与最新解读


原文标题:优化 Stable Diffusion 在 GKE 上的启动体验
文章出处:【微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
-
谷歌
+关注
关注
27文章
6265浏览量
112157
原文标题:优化 Stable Diffusion 在 GKE 上的启动体验
文章出处:【微信号:Google_Developers,微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何使用SD卡启动模式在 LS1046ardb 上测试 SPI 环回?
慧荣科技于Embedded World 2026展示AI优化的启动存储与企业级解决方案

PyTorch 中RuntimeError分析

LDO性能优化的应用技巧
GM9-2003/D3000主板图形适配方案:Ventoy启动与显卡兼容性优化指南

Linux系统冗余设计裁剪开机时间优化
CW32时钟的启动过程
润和软件优化昇腾310B启动时间

【Sipeed MaixCAM Pro开发板试用体验】基于MaixCAM-Pro的AI生成图像鉴别系统
无感FOC算法在电机启动时具体如何优化性能?--【其利天下】
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?
如何在MCXN947微控制器上配置安全启动和生命周期



评论