 PyTorch教程-4.1. Softmax 回归
PyTorch教程-4.1. Softmax 回归
在3.1 节中,我们介绍了线性回归,在3.4 节中从头开始实现 ,并在3.5 节中再次使用深度学习框架的高级 API来完成繁重的工作。
回归是我们想回答多少的时候伸手去拿的锤子? 或者有多少?问题。如果你想预测房子的售价(价格),或者一支棒球队可能获胜的次数,或者病人出院前住院的天数,那么你可能是寻找回归模型。然而,即使在回归模型中,也存在重要的区别。例如,房屋的价格永远不会是负数,并且变化可能通常与其基准价格有关。因此,对价格的对数进行回归可能更有效。同样,患者住院的天数是 离散的非负数随机变量。因此,最小均方可能也不是理想的方法。这种时间-事件建模伴随着许多其他并发症,这些并发症在称为生存建模的专门子领域中处理。
这里的重点不是要让你不知所措,而只是让你知道,除了简单地最小化平方误差之外,还有很多东西需要估计。更广泛地说,监督学习比回归要多得多。在这一节中,我们重点关注分类问题,我们搁置了多少?问题,而是关注哪个类别?问题。
这封电子邮件属于垃圾邮件文件夹还是收件箱?
该客户是否更有可能注册或不注册订阅服务?
这个图像描绘的是驴、狗、猫还是公鸡?
阿斯顿接下来最有可能看哪部电影?
您接下来要阅读本书的哪一部分?
通俗地说,机器学习从业者重载了单词 分类来描述两个细微不同的问题:(i)那些我们只对将示例硬分配给类别(类)感兴趣的问题;(ii) 那些我们希望进行软分配的地方,即评估每个类别适用的概率。这种区别往往会变得模糊,部分原因是,即使我们只关心硬分配,我们仍然经常使用进行软分配的模型。
更重要的是,在某些情况下,不止一个标签可能是真实的。例如,一篇新闻文章可能同时涵盖娱乐、商业和太空飞行等主题,但不会涵盖医学或体育主题。因此,将其单独归入上述类别之一并不是很有用。这个问题通常被称为多标签分类。参见Tsoumakas 和 Katakis ( 2007 )的概述和 Huang等人。( 2015 )用于标记图像时的有效算法。
4.1.1. 分类
让我们先从一个简单的图像分类问题开始。这里,每个输入包含一个2×2灰度图像。我们可以用一个标量表示每个像素值,给我们四个特征x1,x2,x3,x4. 此外,假设每个图像属于类别“猫”、“鸡”和“狗”中的一个。
接下来,我们必须选择如何表示标签。我们有两个明显的选择。也许最自然的冲动是选择 y∈{1,2,3},其中整数代表 {dog,cat,chicken}分别。这是在计算机上存储此类信息的好方法。如果类别之间有一些自然顺序,比如说我们是否试图预测 {baby,toddler,adolescent,young adult,adult,geriatric},那么将其转换为有序回归问题并以这种格式保留标签甚至可能是有意义的。参见 Moon等人。( 2010 )概述了不同类型的排名损失函数和Beutel等人。( 2014 ) 用于解决具有多个模式的响应的贝叶斯方法。
一般而言,分类问题并不伴随着类别之间的自然排序。幸运的是,统计学家很久以前就发明了一种表示分类数据的简单方法:one-hot encoding。one-hot 编码是一个向量,其分量与我们的类别一样多。对应于特定实例类别的组件设置为 1,所有其他组件设置为 0。在我们的例子中,标签y 将是一个三维向量,具有(1,0,0) 对应“猫”,(0,1,0)到“鸡”,和 (0,0,1)对“狗”:
(4.1.1)y∈{(1,0,0),(0,1,0),(0,0,1)}.
4.1.1.1. 线性模型
为了估计与所有可能类别相关的条件概率,我们需要一个具有多个输出的模型,每个类别一个。为了解决线性模型的分类问题,我们需要与输出一样多的仿射函数。严格来说,我们只需要少一个,因为最后一类必须是 1和其他类别的总和,但出于对称的原因,我们使用了稍微冗余的参数化。每个输出对应于它自己的仿射函数。在我们的例子中,由于我们有 4 个特征和 3 个可能的输出类别,我们需要 12 个标量来表示权重(w带下标)和 3 个标量来表示偏差(b带下标)。这产生:
(4.1.2)o1=x1w11+x2w12+x3w13+x4w14+b1,o2=x1w21+x2w22+x3w23+x4w24+b2,o3=x1w31+x2w32+x3w33+x4w34+b3.
对应的神经网络图如图4.1.1所示 。就像在线性回归中一样,我们使用单层神经网络。并且由于每个输出的计算, o1,o2, 和o3, 取决于所有输入,x1, x2,x3, 和x4,输出层也可以描述为全连接层。

图 4.1.1 Softmax 回归是一个单层神经网络。
为了更简洁的表示法,我们使用向量和矩阵: o=Wx+b更适合数学和代码。请注意,我们已将所有权重收集到一个3×4矩阵和所有偏差 b∈R3在一个向量中。
4.1.1.2。Softmax
假设有一个合适的损失函数,我们可以直接尝试最小化两者之间的差异o和标签 y. 虽然事实证明,将分类处理为向量值回归问题的效果出奇地好,但它仍然缺乏以下方面:
无法保证输出oi总结为 1以我们期望概率表现的方式。
无法保证输出oi甚至是非负的,即使它们的输出总和为1,或者他们不超过1.
这两个方面都使估计问题难以解决,并且解决方案对异常值非常脆弱。例如,如果我们假设卧室数量与某人购买房屋的可能性之间存在正线性相关性,则概率可能超过 1买豪宅的时候!因此,我们需要一种机制来“压缩”输出。
我们可以通过多种方式来实现这一目标。例如,我们可以假设输出o是损坏的版本y,其中通过添加噪声发生损坏ϵ从正态分布中提取。换句话说,y=o+ϵ, 在哪里 ϵi∼N(0,σ2). 这就是所谓的 probit 模型,首先由Fechner ( 1860 )提出。虽然很吸引人,但与 softmax 相比,它的效果并不好,也不会导致特别好的优化问题。
实现此目标(并确保非负性)的另一种方法是使用指数函数P(y=i)∝expoi. 这确实满足了条件类概率随着增加而增加的要求oi,它是单调的,所有概率都是非负的。然后我们可以转换这些值,使它们加起来1通过将每个除以它们的总和。这个过程称为规范化。将这两个部分放在一起可以得到softmax函数:
(4.1.3)y^=softmax(o)wherey^i=exp(oi)∑jexp(oj).
注意最大坐标o对应于最有可能的类别y^. 此外,因为 softmax 操作保留了其参数之间的顺序,我们不需要计算 softmax 来确定哪个类别被分配了最高概率。
(4.1.4)argmaxjy^j=argmaxjoj.
softmax 的想法可以追溯到 Gibbs,他改编了物理学的想法( Gibbs, 1902 )。追溯到更早以前,现代热力学之父玻尔兹曼就使用这个技巧来模拟气体分子中的能量状态分布。特别是,他发现热力学系综中能量状态的普遍存在,例如气体中的分子,与exp(−E/kT). 这里, E是一种状态的能量,T是温度,并且 k是玻尔兹曼常数。当统计学家谈论增加或降低统计系统的“温度”时,他们指的是变化T为了有利于较低或较高的能量状态。按照吉布斯的想法,能量等同于错误。基于能量的模型( Ranzato et al. , 2007 )在描述深度学习中的问题时使用了这种观点。
4.1.1.3. 矢量化
为了提高计算效率,我们将计算向量化为小批量数据。假设我们得到了一个小批量 X∈Rn×d的n维度示例(输入数量)d. 此外,假设我们有q输出中的类别。那么权重满足 W∈Rd×q偏差满足 b∈R1×q.
(4.1.5)O=XW+b,Y^=softmax(O).
这将主导操作加速为矩阵矩阵乘积 XW. 此外,由于每一行 X表示一个数据示例,softmax 操作本身可以按行计算:对于每一行O,对所有条目取幂,然后用总和对它们进行归一化。但是请注意,必须注意避免对大数取幂和取对数,因为这会导致数值溢出或下溢。深度学习框架会自动处理这个问题。
4.1.2. 损失函数
现在我们有了来自特征的映射x概率y^,我们需要一种方法来优化此映射的准确性。我们将依赖最大似然估计,这与我们在第 3.1.3 节中为均方误差损失提供概率论证时遇到的概念完全相同 。
4.1.2.1. 对数似然
softmax 函数给了我们一个向量y^,我们可以将其解释为每个类的(估计的)条件概率,给定任何输入x, 例如y^1= P(y=cat∣x). 在下文中,我们假设对于具有特征的数据集X标签 Y使用单热编码标签向量表示。给定以下特征,我们可以根据我们的模型检查实际类别的可能性,从而将估计值与现实进行比较:
(4.1.6)P(Y∣X)=∏i=1nP(y(i)∣x(i)).
我们被允许使用因式分解,因为我们假设每个标签都是独立于其各自的分布绘制的 P(y∣x(i)). 由于最大化项的乘积很尴尬,我们取负对数来获得最小化负对数似然的等价问题:
(4.1.7)−logP(Y∣X)=∑i=1n−logP(y(i)∣x(i))=∑i=1nl(y(i),y^(i)),
任何一对标签在哪里y和模型预测 y^超过q类,损失函数 l是
(4.1.8)l(y,y^)=−∑j=1qyjlogy^j.
由于稍后解释的原因, (4.1.8)中的损失函数通常称为交叉熵损失。自从y是长度的单热向量q,其所有坐标的总和j除了一个任期外,所有的人都消失了。注意损失l(y,y^)从下面被限制0每当y^是一个概率向量:没有一个条目大于1, 因此它们的负对数不能低于0; l(y,y^)=0仅当我们确定地预测实际标签时。对于任何有限的权重设置,这永远不会发生,因为将 softmax 输出朝向1 需要采取相应的输入oi到无穷大(或所有其他输出oj为了j≠i到负无穷大)。即使我们的模型可以分配一个输出概率0,分配如此高的置信度时出现的任何错误都会导致无限损失(−log0=∞).
4.1.2.2. Softmax 和交叉熵损失
由于 softmax 函数和相应的交叉熵损失非常普遍,因此有必要更好地了解它们的计算方式。将(4.1.3)代入(4.1.8)中损失的定义并使用我们获得的 softmax 的定义:
(4.1.9)l(y,y^)=−∑j=1qyjlogexp(oj)∑k=1qexp(ok)=∑j=1qyjlog∑k=1qexp(ok)−∑j=1qyjoj=log∑k=1qexp(ok)−∑j=1qyjoj.
为了更好地理解正在发生的事情,请考虑关于任何 logit 的导数oj. 我们得到
(4.1.10)∂ojl(y,y^)=exp(oj)∑k=1qexp(ok)−yj=softmax(o)j−yj.
换句话说,导数是我们的模型分配的概率(由 softmax 操作表示)与实际发生的概率(由 one-hot 标签向量中的元素表示)之间的差异。从这个意义上讲,它与我们在回归中看到的非常相似,其中梯度是观察值之间的差异y并估计y^. 这不是巧合。在任何指数族模型中,对数似然的梯度恰好由此项给出。这个事实使得计算梯度在实践中变得容易。
现在考虑这样一种情况,我们不仅观察到单个结果,而且观察到结果的整个分布。我们可以对标签使用与之前相同的表示y. 唯一的区别是,而不是只包含二进制条目的向量,比如说 (0,0,1),我们现在有一个通用的概率向量,比如说 (0.1,0.2,0.7). 我们之前用来定义损失的数学l在(4.1.8)中仍然可以正常工作,只是解释稍微更笼统。它是标签分布的损失的预期值。这种损失称为交叉熵损失,它是分类问题中最常用的损失之一。我们可以通过介绍信息论的基础知识来揭开这个名字的神秘面纱。简而言之,它测量对我们看到的内容进行编码的位数y 相对于我们预测应该发生的事情y^. 我们在下面提供了一个非常基本的解释。有关信息论的更多详细信息,请参阅Cover 和 Thomas ( 1999 )或 MacKay 和 Mac Kay ( 2003 )。
4.1.3. 信息论基础
许多深度学习论文使用信息论中的直觉和术语。为了理解它们,我们需要一些共同语言。这是一本生存指南。信息论处理编码、解码、传输和操作信息(也称为数据)的问题。
4.1.3.1. 熵
信息论的中心思想是量化数据中包含的信息量。这限制了我们压缩数据的能力。对于分配P它的熵定义为:
(4.1.11)H[P]=∑j−P(j)logP(j).
信息论的基本定理之一指出,为了对从分布中随机抽取的数据进行编码P,我们至少需要H[P]“nats”对其进行编码(香农,1948 年)。如果您想知道“nat”是什么,它相当于位,但是当使用带有 base 的代码时e而不是基数为 2 的一个。因此,一个 nat 是1log(2)≈1.44少量。
4.1.3.2. 惊喜
您可能想知道压缩与预测有什么关系。想象一下,我们有一个要压缩的数据流。如果我们总是很容易预测下一个标记,那么这个数据就很容易压缩。举一个极端的例子,流中的每个标记总是取相同的值。那是一个非常无聊的数据流!不仅无聊,而且很容易预测。因为它们总是相同的,所以我们不必传输任何信息来传达流的内容。易于预测,易于压缩。
然而,如果我们不能完美地预测每一件事,那么我们有时可能会感到惊讶。当我们分配一个较低概率的事件时,我们的惊喜更大。克劳德·香农决定 log1P(j)=−logP(j)量化一个人 在观察事件时的惊讶程度j赋予它一个(主观)概率P(j). (4.1.11)中定义的熵 是当分配真正匹配数据生成过程的正确概率时的预期意外。
4.1.3.3. 重温交叉熵
因此,如果熵是知道真实概率的人所经历的惊奇程度,那么您可能想知道,什么是交叉熵?交叉熵来自 P 到 Q, 表示H(P,Q), 是具有主观概率的观察者的预期惊喜Q在看到实际根据概率生成的数据时P. 这是由 H(P,Q)=def∑j−P(j)logQ(j). 当达到最低可能的交叉熵时P=Q. 在这种情况下,交叉熵来自P到Q是 H(P,P)=H(P).
简而言之,我们可以通过两种方式来考虑交叉熵分类目标:(i)最大化观察数据的可能性;(ii) 最小化传达标签所需的意外(以及位数)。
4.1.4. 总结与讨论
在本节中,我们遇到了第一个非平凡的损失函数,使我们能够优化离散输出空间。其设计的关键是我们采用了概率方法,将离散类别视为从概率分布中抽取的实例。作为副作用,我们遇到了 softmax,这是一种方便的激活函数,可将普通神经网络层的输出转换为有效的离散概率分布。我们看到交叉熵损失的导数与 softmax 结合时的行为与平方误差的导数非常相似,即取预期行为与其预测之间的差异。而且,虽然我们只能触及它的表面,但我们遇到了与统计物理学和信息论的令人兴奋的联系。
虽然这足以让您上路,并希望足以激发您的胃口,但我们几乎没有深入探讨。除其他外,我们跳过了计算方面的考虑。具体来说,对于任何具有d输入和q输出,参数化和计算成本是O(dq),这在实践中可能高得令人望而却步。幸运的是,这种改造成本d输入到q可以通过近似和压缩来减少输出。例如 Deep Fried Convnets ( Yang et al. , 2015 )使用排列、傅里叶变换和缩放的组合来将成本从二次降低到对数线性。类似的技术适用于更高级的结构矩阵近似(Sindhwani等人,2015 年)。最后,我们可以使用类似四元数的分解来降低成本 O(dqn),同样,如果我们愿意根据压缩因子 为计算和存储成本牺牲少量准确性 (Zhang等人,2021 年)n. 这是一个活跃的研究领域。具有挑战性的是,我们不一定要争取最紧凑的表示或最少数量的浮点运算,而是要寻求可以在现代 GPU 上最有效地执行的解决方案。
4.1.5. 练习
我们可以更深入地探索指数族和 softmax 之间的联系。
计算交叉熵损失的二阶导数 l(y,y^)对于 softmax。
计算由给出的分布的方差 softmax(o)并证明它与上面计算的二阶导数相匹配。
假设我们有三个以等概率出现的类,即概率向量是 (13,13,13).
如果我们尝试为它设计二进制代码,会出现什么问题?
你能设计出更好的代码吗?提示:如果我们尝试对两个独立的观察结果进行编码,会发生什么情况?如果我们编码怎么办n 共同观察?
在对通过物理线路传输的信号进行编码时,工程师并不总是使用二进制代码。例如, PAM-3使用三个信号电平{−1,0,1}而不是两个级别 {0,1}. 传递范围内的整数需要多少个三元单位{0,…,7}?为什么这在电子学方面可能是一个更好的主意?
Bradley -Terry 模型 使用逻辑模型来捕捉偏好。为了让用户在苹果和橙子之间做出选择,一个假设分数 oapple和oorange. 我们的要求是得分越大,选择相关项目的可能性就越大,得分最高的项目最有可能被选中 (Bradley 和 Terry,1952 年)。
证明softmax满足这个要求。
如果您希望允许默认选项既不选择苹果也不选择橙子,会发生什么情况?提示:现在用户有 3 个选择。
Softmax 的名称来源于以下映射: RealSoftMax(a,b)=log(exp(a)+exp(b)).
证明 RealSoftMax(a,b)>max(a,b).
你能使这两个函数之间的差异有多小?提示:不失一般性,您可以设置b=0和 a≥b.
证明这适用于 λ−1RealSoftMax(λa,λb), 前提是λ>0.
表明对于λ→∞我们有 λ−1RealSoftMax(λa,λb)→max(a,b).
软敏是什么样子的?
将其扩展到两个以上的数字。
功能 g(x)=deflog∑iexpxi 有时也称为对数分区函数。
证明函数是凸的。提示:为此,使用一阶导数等于 softmax 函数的概率这一事实,并证明二阶导数是方差。
显示g是平移不变的,即 g(x+b)=g(x).
如果某些坐标会发生什么xi很大吗?如果它们都非常小会怎样?
证明如果我们选择b=maxixi我们最终得到了一个数值稳定的实现。
假设我们有一些概率分布P. 假设我们选择另一个分布Q和 Q(i)∝P(i)α为了α>0.
选择哪个α对应温度翻倍?哪个选择对应减半?
如果我们让温度收敛到0?
如果我们让温度收敛到∞?
Discussions
-
pytorch
+关注
关注
2文章
808浏览量
13202 -
Softmax
+关注
关注
0文章
9浏览量
2506
发布评论请先 登录
相关推荐
OneFlow Softmax算子源码解读之WarpSoftmax
OneFlow Softmax算子源码解读之BlockSoftmax
基于Softmax回归的通信辐射源特征分类识别方法
机器学习的Softmax定义和优点
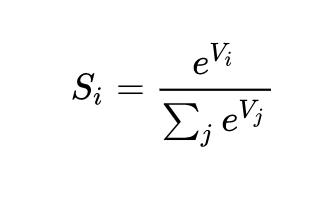
使用Softmax的信息来教学 —— 知识蒸馏
cosFormer:重新思考注意力机制中的Softmax
PyTorch教程4.4之从头开始实现Softmax回归

PyTorch教程-3.1. 线性回归

PyTorch教程-4.4. 从头开始实现 Softmax 回归






 工商网监
工商网监
评论