 PyTorch教程-9.2. 将原始文本转换为序列数据
PyTorch教程-9.2. 将原始文本转换为序列数据
在本书中,我们经常会使用表示为单词、字符或单词序列的文本数据。首先,我们需要一些基本工具来将原始文本转换为适当形式的序列。典型的预处理流水线执行以下步骤:
将文本作为字符串加载到内存中。
将字符串拆分为标记(例如,单词或字符)。
构建一个词汇词典,将每个词汇元素与一个数字索引相关联。
将文本转换为数字索引序列。
import collections import random import re import torch from d2l import torch as d2l
import collections import random import re from mxnet import np, npx from d2l import mxnet as d2l npx.set_np()
import collections import random import re import jax from jax import numpy as jnp from d2l import jax as d2l
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
import collections import random import re import tensorflow as tf from d2l import tensorflow as d2l
9.2.1. 读取数据集
在这里,我们将使用 HG Wells 的The Time Machine,这是一本 30000 多字的书。虽然实际应用程序通常会涉及大得多的数据集,但这足以演示预处理管道。以下_download方法将原始文本读入字符串。
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
'时间机器,HG Wells [1898]nnnnnInnnThe Time Tra'
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
'The Time Machine, by H. G. Wells [1898]nnnnnInnnThe Time Tra'
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
'The Time Machine, by H. G. Wells [1898]nnnnnInnnThe Time Tra'
class TimeMachine(d2l.DataModule): #@save
"""The Time Machine dataset."""
def _download(self):
fname = d2l.download(d2l.DATA_URL + 'timemachine.txt', self.root,
'090b5e7e70c295757f55df93cb0a180b9691891a')
with open(fname) as f:
return f.read()
data = TimeMachine()
raw_text = data._download()
raw_text[:60]
'The Time Machine, by H. G. Wells [1898]nnnnnInnnThe Time Tra'
为简单起见,我们在预处理原始文本时忽略标点符号和大写字母。
@d2l.add_to_class(TimeMachine) #@save def _preprocess(self, text): return re.sub('[^A-Za-z]+', ' ', text).lower() text = data._preprocess(raw_text) text[:60]
'the time machine by h g wells i the time traveller for so it'
@d2l.add_to_class(TimeMachine) #@save
def _preprocess(self, text):
return re.sub('[^A-Za-z]+', ' ', text).lower()
text = data._preprocess(raw_text)
text[:60]
'the time machine by h g wells i the time traveller for so it'
@d2l.add_to_class(TimeMachine) #@save
def _preprocess(self, text):
return re.sub('[^A-Za-z]+', ' ', text).lower()
text = data._preprocess(raw_text)
text[:60]
'the time machine by h g wells i the time traveller for so it'
@d2l.add_to_class(TimeMachine) #@save
def _preprocess(self, text):
return re.sub('[^A-Za-z]+', ' ', text).lower()
text = data._preprocess(raw_text)
text[:60]
'the time machine by h g wells i the time traveller for so it'
9.2.2. 代币化
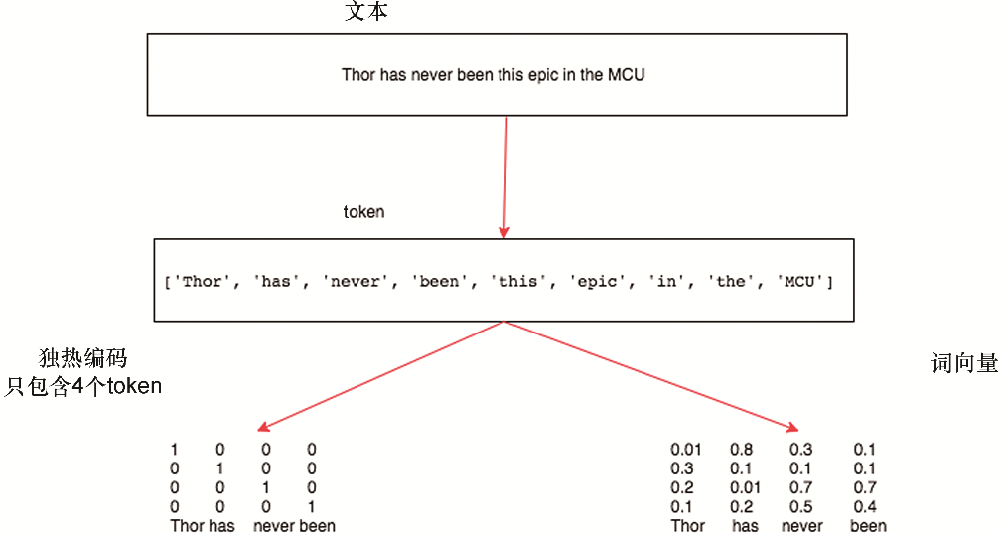
标记是文本的原子(不可分割)单元。每个时间步对应 1 个 token,但究竟什么是 token 是一种设计选择。例如,我们可以将句子“Baby needs a new pair of shoes”表示为一个包含 7 个单词的序列,其中所有单词的集合包含一个很大的词汇表(通常是数万或数十万个单词)。或者我们将同一个句子表示为更长的 30 个字符序列,使用更小的词汇表(只有 256 个不同的 ASCII 字符)。下面,我们将预处理后的文本标记为一系列字符。
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
@d2l.add_to_class(TimeMachine) #@save def _tokenize(self, text): return list(text) tokens = data._tokenize(text) ','.join(tokens[:30])
't,h,e, ,t,i,m,e, ,m,a,c,h,i,n,e, ,b,y, ,h, ,g, ,w,e,l,l,s, '
9.2.3. 词汇
这些标记仍然是字符串。然而,我们模型的输入最终必须由数值输入组成。接下来,我们介绍一个用于构建词汇表的类,即,将每个不同的标记值与唯一索引相关联的对象。首先,我们确定训练语料库中的唯一标记集。然后我们为每个唯一标记分配一个数字索引。为方便起见,通常会删除不常用的词汇元素。Whenever we encounter a token at training or test time that had not been previously seen or was dropped from the vocabulary, we represent it by a special “” token, signifying that this is an unknown value.
class Vocab: #@save
"""Vocabulary for text."""
def __init__(self, tokens=[], min_freq=0, reserved_tokens=[]):
# Flatten a 2D list if needed
if tokens and isinstance(tokens[0], list):
tokens = [token for line in tokens for token in line]
# Count token frequencies
counter = collections.Counter(tokens)
self.token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# The list of unique tokens
self.idx_to_token = list(sorted(set([''] + reserved_tokens + [
token for token, freq in self.token_freqs if freq >= min_freq])))
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if hasattr(indices, '__len__') and len(indices) > 1:
return [self.idx_to_token[int(index)] for index in indices]
return self.idx_to_token[indices]
@property
def unk(self): # Index for the unknown token
return self.token_to_idx['']
我们现在为我们的数据集构建一个词汇表,将字符串序列转换为数字索引列表。请注意,我们没有丢失任何信息,并且可以轻松地将我们的数据集转换回其原始(字符串)表示形式。
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
vocab = Vocab(tokens)
indices = vocab[tokens[:10]]
print('indices:', indices)
print('words:', vocab.to_tokens(indices))
indices: [21, 9, 6, 0, 21, 10, 14, 6, 0, 14] words: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ' ', 'm']
9.2.4. 把它们放在一起
使用上述类和方法,我们将所有内容打包到build该类的以下方法中TimeMachine,该方法返回 corpus,一个标记索引列表,以及, The Time Machinevocab语料库的词汇表 。我们在这里所做的修改是:(i)我们将文本标记为字符,而不是单词,以简化后面部分的训练;(ii)是单个列表,而不是标记列表的列表,因为时间机器数据集中的每个文本行不一定是句子或段落。corpus
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
@d2l.add_to_class(TimeMachine) #@save def build(self, raw_text, vocab=None): tokens = self._tokenize(self._preprocess(raw_text)) if vocab is None: vocab = Vocab(tokens) corpus = [vocab[token] for token in tokens] return corpus, vocab corpus, vocab = data.build(raw_text) len(corpus), len(vocab)
(173428, 28)
9.2.5. 探索性语言统计
使用真实的语料库和Vocab在单词上定义的类,我们可以检查有关语料库中单词使用的基本统计数据。下面,我们根据时间机器中使用的单词构建一个词汇表,并打印出 10 个最常出现的单词。
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
words = text.split() vocab = Vocab(words) vocab.token_freqs[:10]
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
请注意,十个最常用的词并没有那么具有描述性。你甚至可以想象,如果我们随机选择任何一本书,我们可能会看到一个非常相似的列表。诸如“the”和“a”之类的冠词,“i”和“my”之类的代词,以及“of”、“to”和“in”之类的介词经常出现,因为它们具有共同的句法作用。这些既常见又特别具有描述性的词通常称为停用词,在前几代基于词袋表示的文本分类器中,它们最常被过滤掉。然而,它们具有意义,在使用现代基于 RNN 和 Transformer 的神经模型时,没有必要过滤掉它们。如果您进一步查看列表,您会注意到词频衰减很快。这 10th最常见的词小于1/5和最受欢迎一样普遍。当我们沿着排名下降时,词频倾向于遵循幂律分布(特别是 Zipfian)。为了更好地理解,我们绘制了词频图。
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')

freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
在将前几个词作为例外处理后,所有剩余的词在对数-对数图上大致沿着一条直线。Zipf 定律捕捉到了这种现象,该定律指出频率ni 的ith出现频率最高的词是:
(9.2.1)ni∝1iα,
这相当于
(9.2.2)logni=−αlogi+c,
在哪里α是表征分布的指数,并且c是一个常数。如果我们想通过计算统计数据来建模单词,这应该已经让我们停下来了。毕竟,我们会显着高估尾部的频率,也称为不常见词。但是其他单词组合呢,比如两个连续的单词(bigrams)、三个连续的单词(trigrams)等等?让我们看看二元组频率的行为方式是否与单个单词(一元组)频率的行为方式相同。
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
bigram_tokens = ['--'.join(pair) for pair in zip(words[:-1], words[1:])] bigram_vocab = Vocab(bigram_tokens) bigram_vocab.token_freqs[:10]
[('of--the', 309),
('in--the', 169),
('i--had', 130),
('i--was', 112),
('and--the', 109),
('the--time', 102),
('it--was', 99),
('to--the', 85),
('as--i', 78),
('of--a', 73)]
这里值得注意的一件事。在十个最常见的词对中,有九个由停用词组成,只有一个与实际书籍相关——“时间”。此外,让我们看看三元组频率是否以相同的方式表现。
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
trigram_tokens = ['--'.join(triple) for triple in zip( words[:-2], words[1:-1], words[2:])] trigram_vocab = Vocab(trigram_tokens) trigram_vocab.token_freqs[:10]
[('the--time--traveller', 59),
('the--time--machine', 30),
('the--medical--man', 24),
('it--seemed--to', 16),
('it--was--a', 15),
('here--and--there', 15),
('seemed--to--me', 14),
('i--did--not', 14),
('i--saw--the', 13),
('i--began--to', 13)]
最后,让我们可视化这三个模型中的标记频率:unigrams、bigrams 和 trigrams。
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])

bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
这个数字相当令人兴奋。首先,除了 unigram 单词之外,单词序列似乎也遵循 Zipf 定律,尽管指数较小α在(9.2.1)中,取决于序列长度。二、数量不同n-克不是那么大。这给了我们希望,语言中有相当多的结构。三、多n-grams 很少出现。这使得某些方法不适用于语言建模,并激发了深度学习模型的使用。我们将在下一节讨论这个问题。
9.2.6. 概括
文本是深度学习中最常见的序列数据形式之一。构成标记的常见选择是字符、单词和单词片段。为了预处理文本,我们通常 (i) 将文本拆分为标记;(ii) 构建词汇表以将标记字符串映射到数字索引;(iii) 将文本数据转换为标记索引,供模型操作。在实践中,单词的出现频率往往遵循齐普夫定律。这不仅适用于单个单词(unigrams),也适用于 n-克。
9.2.7. 练习
在本节的实验中,将文本标记为单词并改变实例min_freq的参数值Vocab。定性地描述变化如何min_freq影响最终词汇量的大小。
估计此语料库中一元字母、二元字母和三元字母的 Zipfian 分布指数。
查找一些其他数据源(下载标准机器学习数据集、选择另一本公共领域书籍、抓取网站等)。对于每个,在单词和字符级别对数据进行标记化。词汇量大小与Time Machine语料库的等效值相比如何min_freq。估计与这些语料库的一元和二元分布相对应的 Zipfian 分布的指数。他们如何与您观察到的时间机器语料库的值进行比较?
-
pytorch
+关注
关注
2文章
808浏览量
13395
发布评论请先 登录
相关推荐
如何将算得的数据(10进制)转换为16进制通过串口发送出?
如何将原始数据从LIS2DS12转换为G为2/4/8/16g范围?
怎么将原始拜耳转换为RGB输出
是否有办法用vee pro将文本文件转换为excel文件?
如何在Python中将语音转换为文本
ABPDLNN100MG2A3压力传感器如何将原始数据转换为毫巴?
将Pytorch模型转换为DeepViewRT模型时出错怎么解决?
将ONNX模型转换为中间表示(IR)后,精度下降了怎么解决?
如何将ADC采集的原始数据的序列转换成VisualAnalog中Pattern Loader可以接受的I Only文件,文件格式是怎样的?

序列数据和文本的深度学习






 工商网监
工商网监
评论