 PyTorch教程-11.9. 使用 Transformer 进行大规模预训练
PyTorch教程-11.9. 使用 Transformer 进行大规模预训练
到目前为止,在我们的图像分类和机器翻译实验中,模型是在具有输入输出示例的数据集上从头开始训练的,以执行特定任务。例如,Transformer 使用英法对(第 11.7 节)进行训练,因此该模型可以将输入的英文文本翻译成法文。因此,每个模型都成为一个特定的专家,即使是数据分布的微小变化也很敏感(第 4.7 节)。对于更好的泛化模型,或者更胜任的通才,可以在有或没有适应的情况下执行多项任务,大数据的预训练模型越来越普遍。
给定更大的预训练数据,Transformer 架构在模型大小和训练计算增加的情况下表现更好,展示了卓越的缩放行为。具体而言,基于 Transformer 的语言模型的性能与模型参数、训练标记和训练计算的数量成幂律关系 (Kaplan等人,2020 年)。Transformers 的可扩展性还可以通过在更大数据上训练的更大视觉 Transformers 的显着提升性能得到证明(在第 11.8 节中讨论 )。最近的成功案例包括 Gato,这是一个可以玩 Atari、字幕图像、聊天并充当机器人的多面手模型(Reed等。, 2022 )。Gato 是一个单一的 Transformer,在对不同模式(包括文本、图像、关节力矩和按钮按下)进行预训练时可以很好地扩展。值得注意的是,所有此类多模态数据都被序列化为一个扁平的标记序列, Transformers可以将其处理为类似于文本标记(第11.7 节)或图像补丁(第 11.8 节)。
在为多模态数据预训练 Transformers 取得令人瞩目的成功之前,Transformers 使用大量文本进行了广泛的预训练。最初提出用于机器翻译,图 11.7.1中的 Transformer 架构由一个用于表示输入序列的编码器和一个用于生成目标序列的解码器组成。基本上,Transformer 可以用于三种不同的模式: encoder-only、encoder-decoder和decoder-only。作为本章的总结,我们将回顾这三种模式并解释预训练 Transformers 的可扩展性。
11.9.1。仅编码器
当仅使用 Transformer 编码器时,一系列输入标记被转换为相同数量的表示,这些表示可以进一步投影到输出(例如,分类)。Transformer 编码器由自注意力层组成,其中所有输入标记相互关注。例如,图 11.8.1中描述的视觉 Transformers 仅是编码器,将一系列输入图像块转换为特殊“”标记的表示。由于这种表示依赖于所有输入标记,因此它被进一步投射到分类标签中。这种设计的灵感来自早期在文本上预训练的仅编码器 Transformer:BERT(Bidirectional Encoder Representations from Transformers)(Devlin等人,2018 年)。
11.9.1.1。预训练 BERT

图 11.9.1左:使用掩码语言建模预训练 BERT。对被屏蔽的“love”token 的预测取决于“love”前后的所有输入 token。右图:Transformer 编码器中的注意力模式。垂直轴上的每个标记都涉及水平轴上的所有输入标记。
BERT 使用掩码语言建模在文本序列上进行预训练:带有随机掩码标记的输入文本被送入 Transformer 编码器以预测掩码标记。如图11.9.1所示 ,原始文本序列“I”、“love”、“this”、“red”、“car”前面加上“”标记,“” token随机替换“love”;那么在预训练期间,掩码标记“love”与其预测之间的交叉熵损失将被最小化。请注意,Transformer 编码器的注意力模式没有约束( 图 11.9.1右侧)) 所以所有的代币都可以互相关注。因此,“爱”的预测取决于序列中它前后的输入标记。这就是 BERT 是“双向编码器”的原因。无需人工标注,可以使用书籍和维基百科中的大规模文本数据来预训练 BERT。
11.9.1.2。微调 BERT
预训练的 BERT 可以针对涉及单个文本或文本对的下游编码任务进行微调。在微调期间,可以使用随机参数向 BERT 添加额外的层:这些参数和那些预训练的 BERT 参数将被更新以适应下游任务的训练数据。

图 11.9.2微调 BERT 以进行情绪分析。
图 11.9.2说明了用于情绪分析的 BERT 微调。Transformer 编码器是一个预训练的 BERT,它将文本序列作为输入并将“”表示(输入的全局表示)馈送到额外的全连接层以预测情绪。在微调期间,通过基于梯度的算法最小化预测和情感分析数据标签之间的交叉熵损失,其中从头开始训练附加层,同时更新 BERT 的预训练参数。BERT 做的不仅仅是情绪分析。3.5 亿参数 BERT 从 2500 亿个训练标记中学习到的通用语言表征提升了自然语言任务的最新水平,例如单一文本分类、文本对分类或回归、文本标记和问答。
您可能会注意到这些下游任务包括文本对理解。BERT 预训练还有另一个损失,用于预测一个句子是否紧跟另一个句子。然而,后来发现在对 20000 亿个令牌预训练相同大小的 BERT 变体 RoBERTa 时,这种损失没有用(Liu等人,2019 年)。BERT 的其他衍生产品改进了模型架构或预训练目标,例如 ALBERT(强制参数共享)(Lan等人,2019 年)、SpanBERT(表示和预测文本跨度)(Joshi等人,2020 年)、DistilBERT(轻量级通过知识蒸馏) (桑等人。, 2019 )和 ELECTRA(替代令牌检测) (Clark等人,2020)。此外,BERT 启发了计算机视觉中的 Transformer 预训练,例如视觉 Transformers ( Dosovitskiy et al. , 2021 )、Swin Transformers ( Liu et al. , 2021 )和 MAE (masked autoencoders) ( He et al. , 2022 )。
11.9.2。编码器-解码器
由于 Transformer 编码器将一系列输入标记转换为相同数量的输出表示,因此仅编码器模式无法像机器翻译那样生成任意长度的序列。正如最初为机器翻译提出的那样,Transformer 架构可以配备一个解码器,该解码器可以自动回归预测任意长度的目标序列,逐个标记,以编码器输出和解码器输出为条件:(i)对于编码器输出的条件,编码器-解码器交叉注意力(图 11.7.1中解码器的多头注意力)允许目标标记关注所有输入标记;(ii) 对解码器输出的调节是通过所谓的因果关系实现的注意(这个名称在文献中很常见,但具有误导性,因为它与正确的因果关系研究几乎没有联系)模式(图 11.7.1中解码器的屏蔽多头注意),其中任何目标标记只能关注过去并在目标序列中呈现标记。
为了在人工标记的机器翻译数据之外预训练编码器-解码器 Transformer,BART (Lewis等人,2019 年)和 T5 (Raffel等人,2020 年)是两个同时提出的在大规模文本语料库上预训练的编码器-解码器 Transformer。两者都试图在其预训练目标中重建原始文本,而前者强调噪声输入(例如,掩蔽、删除、排列和旋转),后者则强调通过综合消融研究实现多任务统一。
11.9.2.1。预训练T5
作为预训练的 Transformer 编码器-解码器的示例,T5(文本到文本传输转换器)将许多任务统一为相同的文本到文本问题:对于任何任务,编码器的输入都是任务描述(例如, “总结”、“:”)之后是任务输入(例如,文章中的一系列标记),解码器预测任务输出(例如,一系列标记对输入文章的总结)。为了执行文本到文本,T5 被训练为根据输入文本生成一些目标文本。

图 11.9.3左:通过预测连续跨度来预训练 T5。原句为“I”、“love”、“this”、“red”、“car”,其中“love”被特殊的“”token 代替,连续的“red”、“car”为替换为特殊的“”标记。目标序列以特殊的“”标记结尾。右图:Transformer 编码器-解码器中的注意力模式。在编码器自注意力(下方块)中,所有输入标记都相互关注;在编码器-解码器交叉注意力(上部矩形)中,每个目标标记关注所有输入标记;在解码器自我关注(上三角)中,每个目标标记仅关注当前和过去的目标标记(因果关系)。
为了从任何原始文本中获取输入和输出,T5 被预训练以预测连续的跨度。具体来说,来自文本的标记被随机替换为特殊标记,其中每个连续的跨度被相同的特殊标记替换。考虑图 11.9.3中的示例 ,其中原始文本是“I”、“love”、“this”、“red”、“car”。标记“love”、“red”、“car”随机替换为特殊标记。由于“red”和“car”是连续的跨度,因此它们被相同的特殊标记替换。结果,输入序列为“I”、“”、“this”、“”,目标序列为“”、“love”、“”、“ red”,“car”,“”,其中“”是另一个标记结束的特殊标记。如图 11.9.3,解码器有一个因果注意模式,以防止自己在序列预测期间关注未来的标记。
在 T5 中,预测连续跨度也称为重建损坏的文本。为了实现这一目标,T5 使用来自 C4(Colossal Clean Crawled Corpus)数据的 10000 亿个标记进行了预训练,该数据由来自 Web 的干净英文文本组成(Raffel等人,2020 年)。
11.9.2.2。微调T5
与 BERT 类似,T5 需要在任务特定的训练数据上进行微调(更新 T5 参数)以执行此任务。与 BERT 微调的主要区别包括:(i)T5 输入包括任务描述;(ii) T5 可以通过其 Transformer 解码器生成任意长度的序列;(iii) 不需要额外的层。

图 11.9.4为文本摘要微调 T5。任务描述和文章标记都被送入 Transformer 编码器以预测摘要。
图 11.9.4以文本摘要为例解释了微调 T5。在这个下游任务中,任务描述标记“Summarize”、“:”和文章标记被输入到编码器。
经过微调后,110 亿参数的 T5 (T5-11B) 在多个编码(例如分类)和生成(例如摘要)基准测试中取得了最先进的结果。自发布以来,T5在后期研究中得到了广泛的应用。例如,开关 Transformer 的设计基于 T5 以激活参数子集以提高计算效率(Fedus等人,2022 年)。在名为 Imagen 的文本到图像模型中,文本被输入到具有 46 亿个参数的冻结 T5 编码器 (T5-XXL) (Saharia等人,2022 年)。图 11.9.5中逼真的文本到图像示例建议即使没有微调,单独的 T5 编码器也可以有效地表示文本。
11.9.3。仅解码器
我们已经回顾了仅编码器和编码器-解码器 Transformers。或者,仅解码器的 Transformer 从图 11.7.1中描绘的原始编码器-解码器架构中移除了整个编码器和具有编码器-解码器交叉注意力的解码器子层 。如今,只有解码器的 Transformer 已经成为大规模语言建模(第 9.3 节)中的实际架构,它通过自监督学习利用世界上丰富的未标记文本语料库。
11.9.3.1。GPT 和 GPT-2
GPT(生成预训练)模型以语言建模为训练目标,选择 Transformer 解码器作为其主干 (Radford等人,2018 年)。

图 11.9.6左:使用语言建模预训练 GPT。目标序列是输入序列移位一个标记。“”和“”都是分别标记序列开始和结束的特殊标记。右图:Transformer 解码器中的注意力模式。垂直轴上的每个标记仅关注其过去沿水平轴的标记(因果关系)。
按照第 9.3.3 节中描述的自回归语言模型训练 ,图 11.9.6 说明了使用 Transformer 编码器进行 GPT 预训练,其中目标序列是输入序列移位一个标记。请注意,Transformer 解码器中的注意力模式强制每个标记只能关注其过去的标记(无法关注未来的标记,因为它们尚未被选择)。
GPT 有 1 亿个参数,需要针对个别下游任务进行微调。一年后推出了更大的 Transformer-decoder 语言模型 GPT-2 (Radford等人,2019 年)。与 GPT 中原始的 Transformer 解码器相比, GPT-2 采用了预归一化(在11.8.3 节中讨论)和改进的初始化和权重缩放。在 40 GB 的文本上进行预训练,15 亿参数的 GPT-2 在语言建模基准测试中获得了最先进的结果,并且在不更新参数或架构的情况下在多个其他任务上获得了有希望的结果。
11.9.3.2。GPT-3
GPT-2 展示了在不更新模型的情况下对多个任务使用相同语言模型的潜力。这比微调在计算上更有效,微调需要通过梯度计算更新模型。

图 11.9.7使用语言模型(Transformer 解码器)进行零样本、单样本、少样本上下文学习。不需要更新参数。
在解释在没有参数更新的情况下更高效地使用语言模型之前,请回顾第 9.5 节,可以训练语言模型以生成以某些前缀文本序列为条件的文本序列。因此,预训练语言模型可以将任务输出生成为没有参数更新的序列,以具有任务描述、特定于任务的输入输出示例和提示(任务输入)的输入序列为条件。这种学习范式称为情境学习 ( Brown et al. , 2020 ),可进一步分为 零样本、单样本和少样本,当分别没有、一个和几个特定于任务的输入输出示例时(图 11.9.7)。
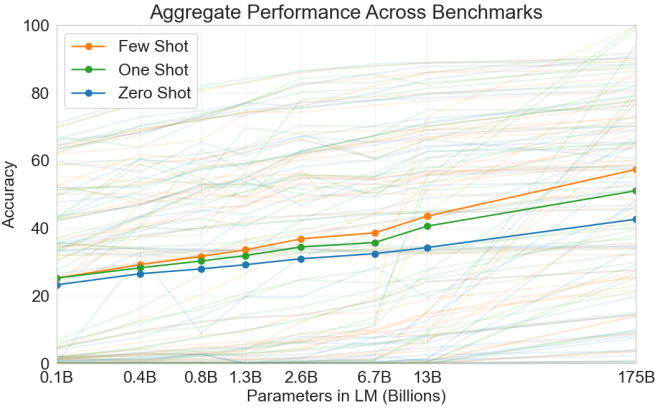
图 11.9.8 GPT-3 在所有 42 个以准确度命名的基准中的综合性能(改编的标题和来自 Brown等人(2020)的图)。
这三个设置在 GPT-3 中进行了测试(Brown等人,2020 年),其最大版本使用的数据和模型大小比 GPT-2 大两个数量级。GPT-3 在其直接前身 GPT-2 中使用相同的 Transformer 解码器架构,除了注意模式(图 11.9.6右侧)在交替层更稀疏。使用 3000 亿个标记进行预训练后,GPT-3 在更大的模型尺寸下表现更好,其中 few-shot 性能增加最快(图 11.9.8)。
大型语言模型提供了一个令人兴奋的前景,即制定文本输入以诱导模型通过上下文学习执行所需的任务,这也称为提示。例如,链式思维提示 ( Wei et al. , 2022 ),一种具有少量“问题、中间推理步骤、答案”演示的上下文学习方法,引出大型语言模型的复杂推理能力来解决数学、常识和符号推理任务。采样多个推理路径 (Wang et al. , 2023),多样化 few-shot demonstrations (Zhang et al. , 2023) , 以及将复杂问题分解为子问题( Zhou et al. , 2023 )都可以提高推理精度。事实上,在每个答案之前通过“让我们逐步思考”这样的简单提示,大型语言模型甚至可以相当准确地执行 零样本思维链推理 (Kojima等人,2022 年)。即使对于包含文本和图像的多模态输入,语言模型也可以执行多模态思维链推理,其准确性比仅使用文本输入进一步提高 (Zhang et al. , 2023)。
11.9.4。可扩展性
图 11.9.8凭经验证明了 Transformer 在 GPT-3 语言模型中的可扩展性。对于语言建模,关于 Transformer 可扩展性的更全面的实证研究使研究人员看到了用更多数据和计算来训练更大的 Transformer 的希望(Kaplan等人,2020 年)。
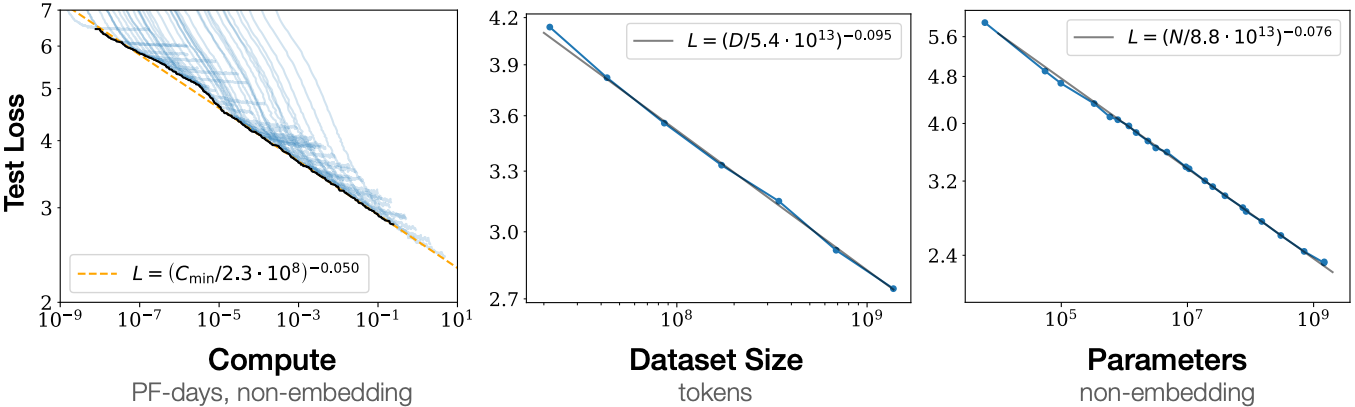
图 11.9.9 Transformer 语言模型性能随着我们增加模型大小、数据集大小和用于训练的计算量而平稳提高。为了获得最佳性能,必须同时放大所有三个因素。当没有受到其他两个因素的瓶颈时,经验表现与每个单独因素都具有幂律关系(改编自Kaplan等人(2020 年)的图)。
如图 11.9.9所示,在模型大小(参数数量,不包括嵌入层)、数据集大小(训练令牌数量)和训练计算量( PetaFLOP/s-days,不包括嵌入层)。一般来说,同时增加所有这三个因素会带来更好的性能。然而,如何同时增加它们仍然是一个有争议的问题 ( Hoffmann et al. , 2022 )。
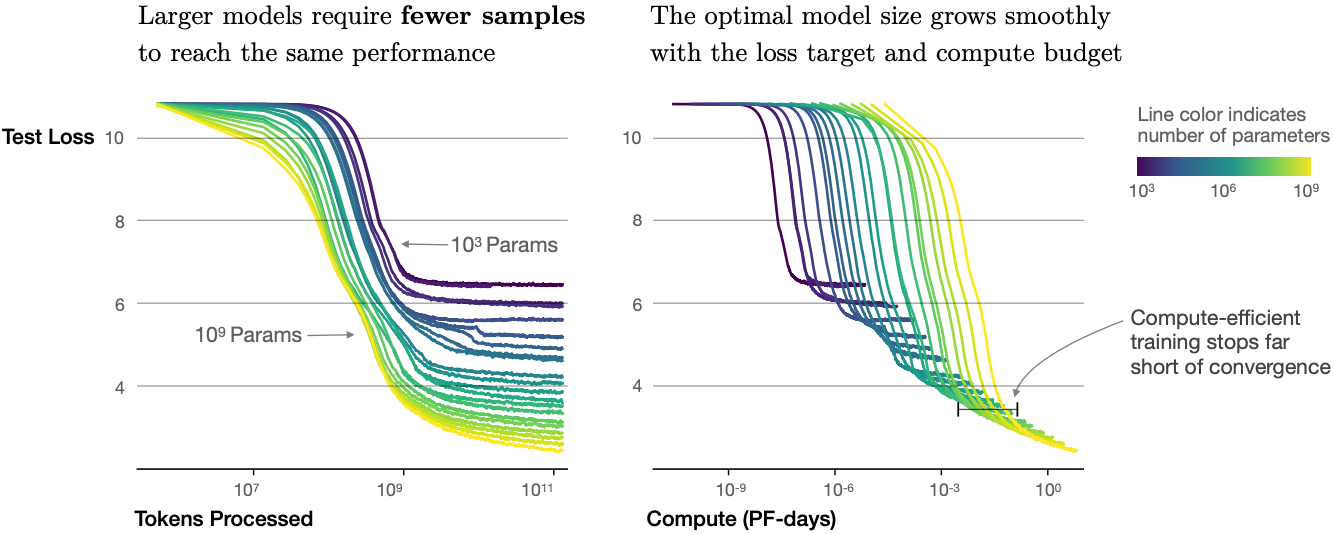
图 11.9.10 Transformer 语言模型训练运行(图取自 Kaplan等人(2020))。
除了提高性能外,大型模型还具有比小型模型更好的采样效率。图 11.9.10显示,大型模型需要更少的训练样本(处理的令牌)才能达到小型模型达到的相同水平,并且性能随计算平滑扩展。
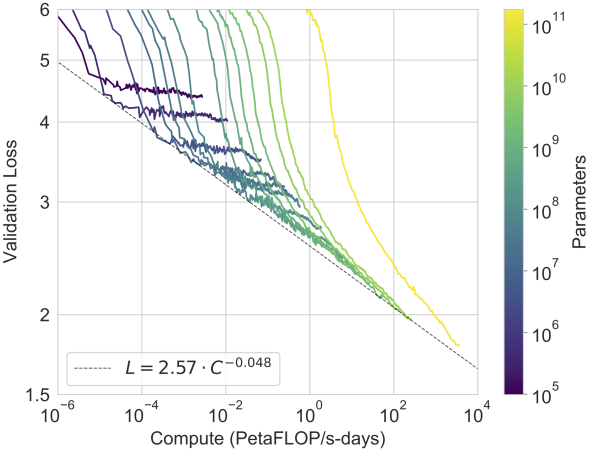
图 11.9.11 GPT-3 性能(交叉熵验证损失)随着用于训练的计算量遵循幂律趋势。在Kaplan等人中观察到的幂律行为。( 2020 )继续增加两个数量级,与预测曲线的偏差很小。嵌入参数被排除在计算和参数计数之外(标题改编自 Brown等人( 2020 ))。
Kaplan等人的经验缩放行为。( 2020 )已经在后续的大型 Transformer 模型中进行了测试。例如,GPT-3 在 图 11.9.11中以两个数量级支持了这一假设。
GPT 系列中 Transformers 的可扩展性启发了后续的 Transformer 语言模型。虽然 GPT-3 中的 Transformer 解码器在 OPT(Open Pretrained Transformers) (Zhang等人,2022 年)中得到广泛应用,但碳足迹仅为前者的 1/7,而 GPT-2 Transformer 解码器用于训练 530 -十亿参数威震天-图灵 NLG (Smith等人,2022 年),具有 2700 亿个训练令牌。继 GPT-2 设计之后,2800 亿参数的 Gopher ( Rae et al. , 2021 )经过 3000 亿个标记的预训练,在大约 150 个不同的任务中,大多数人都取得了最先进的表现。Chinchilla (Hoffmann等人,2022 年)继承了与 Gopher 相同的架构并使用相同的计算预算, 是一个小得多(700 亿个参数)的模型,训练时间长得多(1.4 万亿训练令牌),在许多任务上优于 Gopher。为了继续扩大语言建模的规模,PaLM(路径语言模型) (Chowdhery等人,2022 年)是一种 5400 亿参数的 Transformer 解码器,其设计经过修改,在 7800 亿个标记上进行了预训练,在 BIG-Bench 上的表现优于人类平均水平基准 (斯利瓦斯塔瓦等。, 2022 )。在 Minerva (Lewkowycz等人,2022 年)中对包含科学和数学内容的 385 亿个标记进一步训练 PaLM ,这是一个大型语言模型,可以回答近三分之一需要定量推理的本科水平问题,例如物理、化学、生物学和经济学。
魏等。( 2022 )讨论了大型语言模型的涌现能力,这些能力只存在于较大的模型中,但不存在于较小的模型中。然而,简单地增加模型大小并不能从本质上使模型更好地遵循人类指令。遵循通过微调使语言模型与人类意图保持一致的 InstructGPT (Ouyang等人,2022), ChatGPT能够从与人类的对话中遵循指令,例如代码调试和笔记起草。
11.9.5。总结与讨论
Transformer 已被预训练为仅编码器(例如 BERT)、编码器-解码器(例如 T5)和仅解码器(例如 GPT 系列)。预训练模型可以适用于执行不同的任务,包括模型更新(例如,微调)或不更新(例如,少量镜头)。Transformer 的可扩展性表明更好的性能受益于更大的模型、更多的训练数据和更多的训练计算。由于 Transformer 最初是为文本数据设计和预训练的,因此本节稍微倾向于自然语言处理。尽管如此,上面讨论的那些模型经常可以在跨多种模式的更新模型中找到。例如,(i) Chinchilla ( Hoffmann et al. , 2022 )被进一步扩展到 Flamingo ( Alayrac等。, 2022 ), 一种用于小样本学习的视觉语言模型;(ii) GPT-2( Radford et al. , 2019 )和 vision Transformer 在 CLIP (Contrastive Language-Image Pre-training)( Radford et al. , 2021 ),其图像和文本嵌入后来被采用在 DALL-E 2 文本到图像系统中 ( Ramesh等人,2022 年)。虽然目前还没有关于多模态预训练中 Transformer 可扩展性的系统研究,但最近的一个全 Transformer 文本到图像模型 Parti ( Yu et al. , 2022 ),显示了跨模态的可扩展性潜力:更大的 Parti 更有能力生成高保真图像和理解内容丰富的文本(图 11.9.12)。
11.9.6。练习
是否可以使用由不同任务组成的小批量来微调 T5?为什么或者为什么不?GPT-2 怎么样?
给定一个强大的语言模型,你能想到什么应用?
假设您被要求微调语言模型以通过添加额外的层来执行文本分类。你会在哪里添加它们?为什么?
考虑序列到序列问题(例如,机器翻译),其中输入序列在整个目标序列预测中始终可用。使用仅解码器的 Transformer 进行建模的局限性是什么?为什么?
Discussions
-
Transformer
+关注
关注
0文章
143浏览量
5995 -
pytorch
+关注
关注
2文章
808浏览量
13201
发布评论请先 登录
相关推荐
基于Transformer做大模型预训练基本的并行范式
Pytorch模型训练实用PDF教程【中文】
怎样使用PyTorch Hub去加载YOLOv5模型
国内科学家团队发布超大规模AI预训练模型

使用NVIDIA DGX SuperPOD训练SOTA大规模视觉模型
文本预训练的模型架构及相关数据集
第一个大规模点云的自监督预训练MAE算法Voxel-MAE
基于Transformer架构的文档图像自监督预训练技术
PyTorch教程11.9之使用Transformer进行大规模预训练






 工商网监
工商网监
评论