 CVPR 2023:视觉重定位,同等精度下速度提升300倍
CVPR 2023:视觉重定位,同等精度下速度提升300倍
本次分享的论文来自CVPR 2023(Highlight),作者来自鼎鼎大名的Niantic Labs,是一个很有名的VR游戏开发公司,做了增强现实游戏Ingress和位置发现应用Field Trip和pokemon go手游。
论文题目:Accelerated Coordinate Encoding:Learning to Relocalize in Minutes using RGB and Poses
论文链接:https://arxiv.org/pdf/2305.14059.pdf
代码主页:https://github.com/nianticlabs/ace
01介绍
本文是一篇基于学习的视觉定位算法,更具体的是通过网络学习回归图像密集像素三维坐标,建立2D-3D对应后放在鲁棒姿态估计器(RANSAC PNP + 迭代优化)中估计相机六自由度姿态。
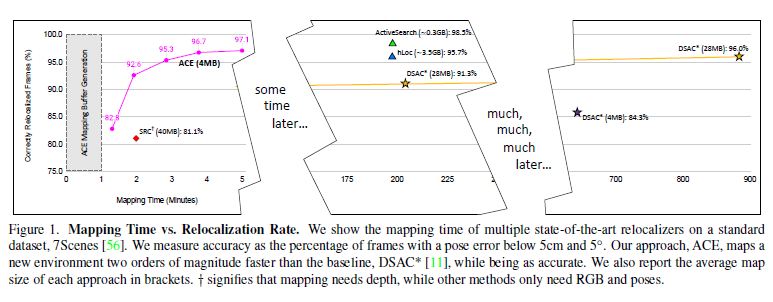
与以往基于学习的视觉定位算法的区别在于:以前的方法往往需要数小时或数天的训练,而且每个新场景都需要再次进行训练,使得该方法在大多数应用程序中不太现实,所以在本文中作者团队提出的方法改善了这一确定,使得可以在不到5分钟的时间内实现同样的精度。
具体的,作者讲定位网络分为场景无关的特征backbone和场景特定的预测头。而且预测头不使用传统的卷积网络,而是使用MLP,这可以在每次训练迭代中同时对数千个视点进行优化,导致稳定和极快的收敛。
此外使用一个鲁棒姿态求解器的curriculum training替代有效但缓慢的端到端训练。
其方法在制图方面比最先进的场景坐标回归快了300倍!
curriculum training:Curriculum training是一种训练方法,训练时向模型提供训练样本的难度逐渐变大。在对新数据进行训练时,此方法需要对任务进行标注,将任务分为简单、中等或困难,然后对数据进行采样。
把原来的卷积网络预测头换成MLP预测头的动机是什么?作者认为场景坐标回归可以看作从高维特征向量到场景空间三维点的映射,与卷积网络相比,多层感知器(MLP)可以很好地表示这种映射,而且训练一个特定场景的MLP允许在每次训练迭代中一次优化多个(通常是所有可用的)视图,这会导致非常稳定的梯度,使其能够在非常积极的、高学习率的机制下操作。把这个和curriculum training结合在一起,让网络在后期训练阶段burn in可靠的场景结构,使其模拟了端到端训练方案,以此会极大提升训练速度和效率。
02主要贡献
(1)加速坐标编码(ACE),一个场景坐标回归算法,可以在5分钟内映射一个新场景,以前最先进的场景坐标回归系统需要数小时才能达到相当的重定位精度。
(2)ACE将场景编码成4MB的网络权重,以前的场景坐标回归系统需要7倍的存储空间。
(3)只需要RGB图像和对应的pose进行训练,以前的依赖于像深度图或场景网格这样的先验知识来进行。
03方法
算法的目标是估计给定的RGB图像I的相机姿态h。定义的相机姿态为一个刚体变换,其将相机空间下的坐标ei映射到场景空间的坐标yi,即yi = h*ei。
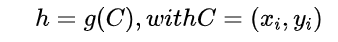
其中C表示2D像素位置和3D场景坐标之间的对应,g表示一个鲁棒的姿态估计器。
设计的网络学习预测给定2D图像点对应的3D场景点,即:
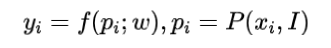
其中f表示学习到的权重参数化的网络,表示从图像I的像素位置附近提取的图像patch,所以f是一个patchs到场景坐标的映射。
网络在训练时在所有建图图像用他们的ground truth 作为监督进行训练:
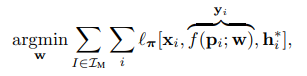
3.1 通过解关联梯度进行高效训练
作者认为以往的方法在每次训练迭代中优化了成千上万个patch的预测,但它们都来自同一幅图像,因此它们的损失和梯度将是高度相关的。所以这篇文章的关键思想是在整个训练集上随机化patches,并从许多不同的视图中构造batch,这种方法可以解关联batch中的梯度,从而得到稳定的训练,而且对高学习率具有鲁棒性,并最终实现快速收敛。
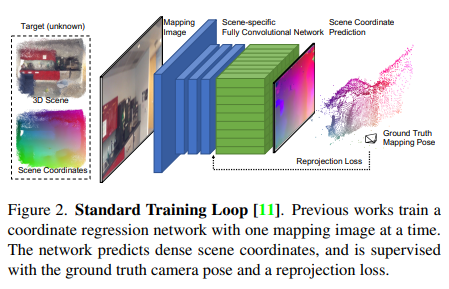
以往的方法的网络如下图所示,一次一副图像,切图像特征编码器和预测头解码器都是CNN
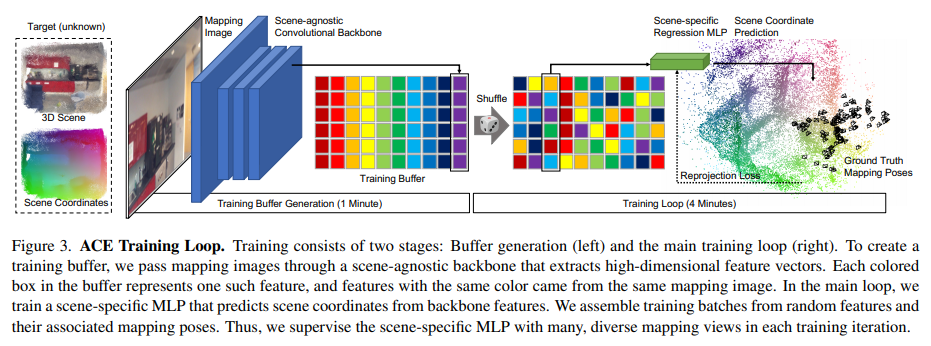
作者将网络拆分为卷积主干和多层感知器(MLP)头,如下图所示:
所以网络拆分成两部分:
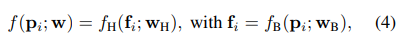
其中是用来预测表示图像特征的高维向量,是用来预测场景坐标的回归头
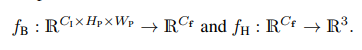
作者认为可以用场景无关的卷积网络实现一个通用的特征提取器,可以使用一个MLP而不是另一个卷积网络来实现。这样做因为在预测patch对应的场景坐标时是不需要空间上下文的,也就是说,与backbone不同,不需要访问邻近的像素来进行计算,因此可以用所有图像中的随机样本构建的训练batch,具体就是通过在所有图像上运行预训练的backbone来构建一个固定大小的训练缓冲区,这个缓冲区包含数以百万计的特征及其相关像素位置、相机内参和ground truth ,在训练的第一分钟就产生了这个缓冲。然后开始在缓冲区上迭代主训练循环,即在每个epoch的开始,shuffle缓冲区以混合所有图像数据的特征,在每个训练步骤中,构建数千个特征batch,这可能同时计算数千个视图的参数更新,这样不仅梯度计算对于MLP回归头非常高效,而且梯度也是不相关的,这允许使用高学习速度来快速收敛。
3.2 课程(Curriculum)训练
课程(Curriculum)训练:比如像我们上课一样,开始会讲一些简单的东西,然后再慢慢深入学习复杂的东西,类比网络,就是开始给宽松的阈值,让网络学习简单的知识,后续随着训练时间的进行,增大阈值,让网络学习复杂且鲁棒的知识。
具体的,在整个训练过程中使用一个移动的内阈值,开始时是宽松的,随着训练的进行,限制会越来越多,使得网络可以专注于已经很好的预测,而忽略在姿态估计过程中RANSAC会过滤掉的不太精确的预测。
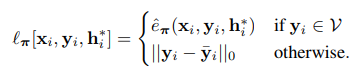
这种损失优化了所有有效坐标预测的鲁棒重投影误差π,有效的预测指在图像平面前方10cm到1000m之间,且重投影误差低于1000px。
再使用tanh夹持重投影误差:
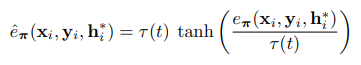
根据在训练过程中变化的阈值τ动态地重新缩放tanh:
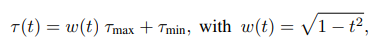
其中t∈(0,1)表示相对训练进度。这个课程训练实现了一个循环的τ阈值时间表,τ阈值在训练开始时保持在附近,在训练结束时趋于。
3.3 Backbone训练
backbone可以使用任何密集的特征描述网络。作者提出了一种简单的方法来训练一个适合场景坐标回归的特征描述网络。为了训练backbone,采用DSAC*的图像级训练,并将其与课程训练相结合。用N个回归头并行地训练N个场景,而不是用一个回归头训练一个场景的backbone。这种瓶颈架构使得backbone预测适用于广泛场景的特性。在ScanNet的100个场景上训练1周,得到11MB的权重,可用于在任何新场景上提取密集的描述符。
04实验
主要在两个室内数据集7Scenes和12Scenes和一个室外数据集Cambridge上进行训练测试:
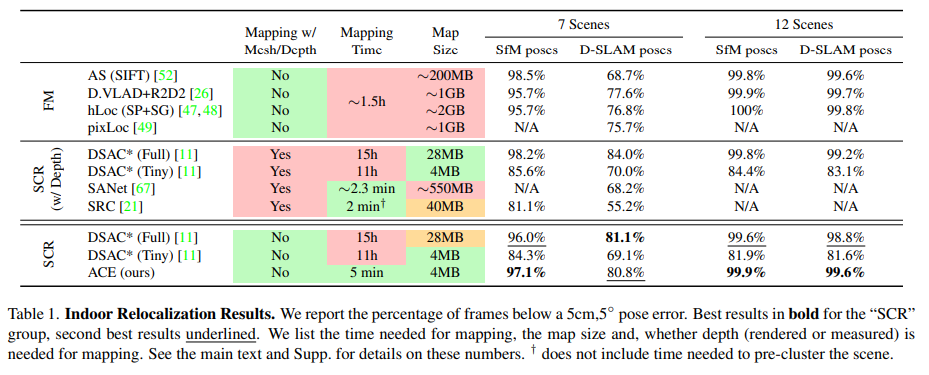
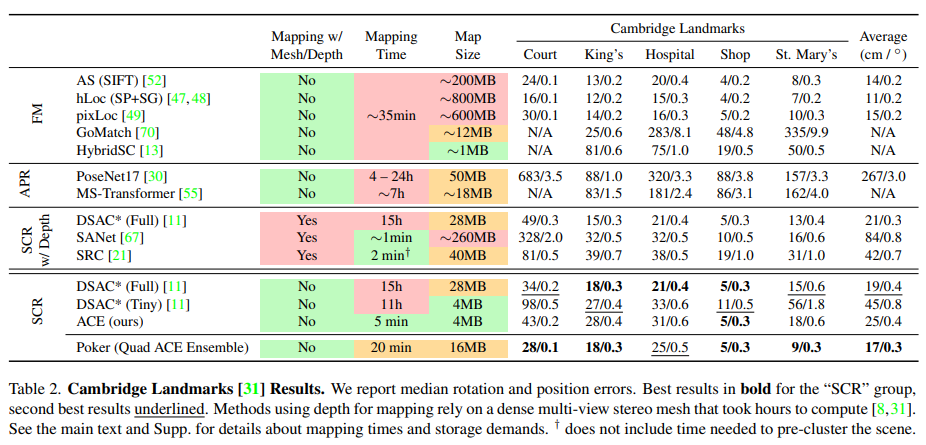
和DSAC*比较了在建图训练上的时间损耗:
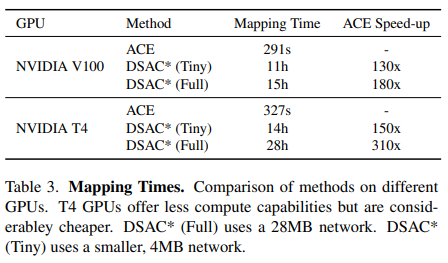
以及在无地图定位数据集(自己构建的 WaySpots)上的定位结果:


05总结
这是一个能够在5分钟内训练新环境的重定位算法。
与之前的场景坐标回归方法相比,将建图的成本和存储消耗降低了两个数量级,使得算法具有实用性。
-
算法
+关注
关注
23文章
4607浏览量
92841 -
视觉
+关注
关注
1文章
147浏览量
23936 -
卷积网络
+关注
关注
0文章
42浏览量
2163
原文标题:前沿丨CVPR 2023:视觉重定位,同等精度下速度提升300倍
文章出处:【微信号:gh_c87a2bc99401,微信公众号:INDEMIND】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
直线电机定位精度和重复定位精度
视觉定位方案求助,谢
深圳CCD视觉检测定位系统有什么特点?
CCD视觉定位系统在紫外激光打标机上的应用
高精度定位技术需求日益凸显,和SKYLAB了解一下高精度定位方案
iOS 12正式版即将推出,高负载下app启动速度最高提升至2倍
自动驾驶检测器可同时实现3D检测精读和速度的提升
教你们视觉SLAM如何去提高定位精度
CVPR 2021华为诺亚方舟实验室发表30篇论文 |CVPR 2021

华为DATS路面感知响应速度提升100倍

HighLight:视觉重定位,同等精度下速度提升300倍

CVPR 2023 | 完全无监督的视频物体分割 RCF

激光焊接视觉定位引导方法






 工商网监
工商网监
评论