 击败LLaMA?史上最强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
击败LLaMA?史上最强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
【导读】前几天公布的LLM排行榜引发业内人士广泛讨论,新模型Falcon在性能上真的能打过LLaMA吗?符尧实测来了!
前段时间,初出茅庐的猎鹰(Falcon)在LLM排行榜碾压LLaMA,在整个社区激起千层浪。
但是,猎鹰真的比LLaMA好吗?
简短回答:可能不是。
符尧团队对模型做了更深入的测评:
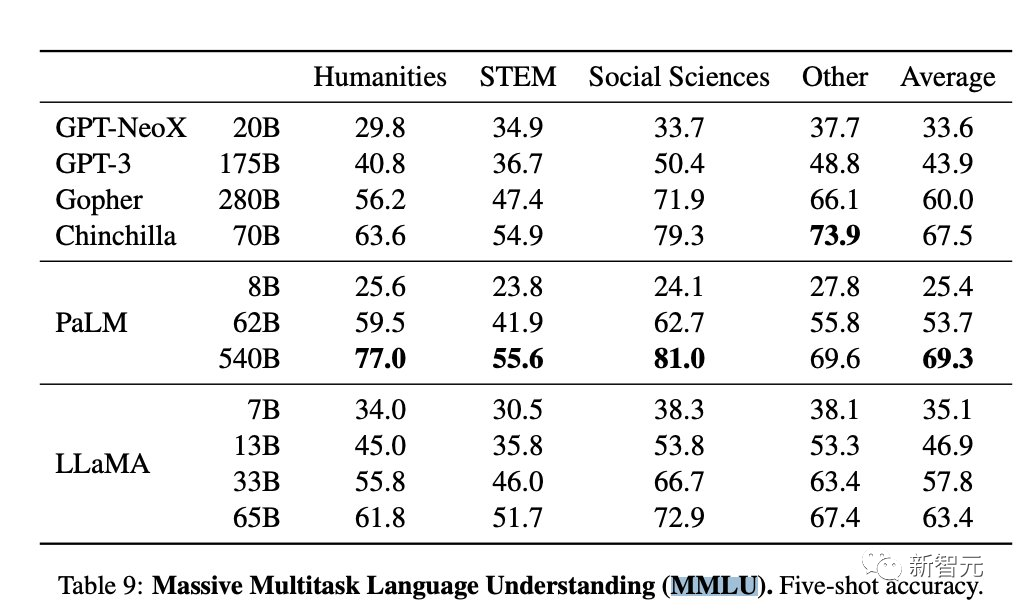
「我们在MMLU上复现了LLaMA 65B的评估,得到了61.4的分数,接近官方分数(63.4),远高于其在Open LLM Leaderboard上的分数(48.8),而且明显高于猎鹰(52.7)。」
没有花哨的提示工程,没有花哨的解码,一切都是默认设置。
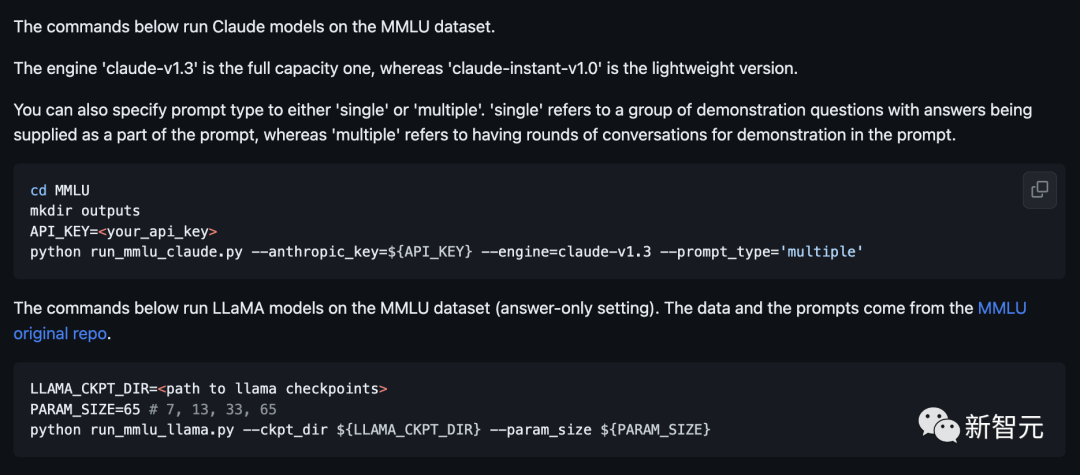
目前,Github上已经公开了代码和测试方法。
对于猎鹰超越LLaMA存疑,LeCun表态,测试脚本的问题...
LLaMA真·实力
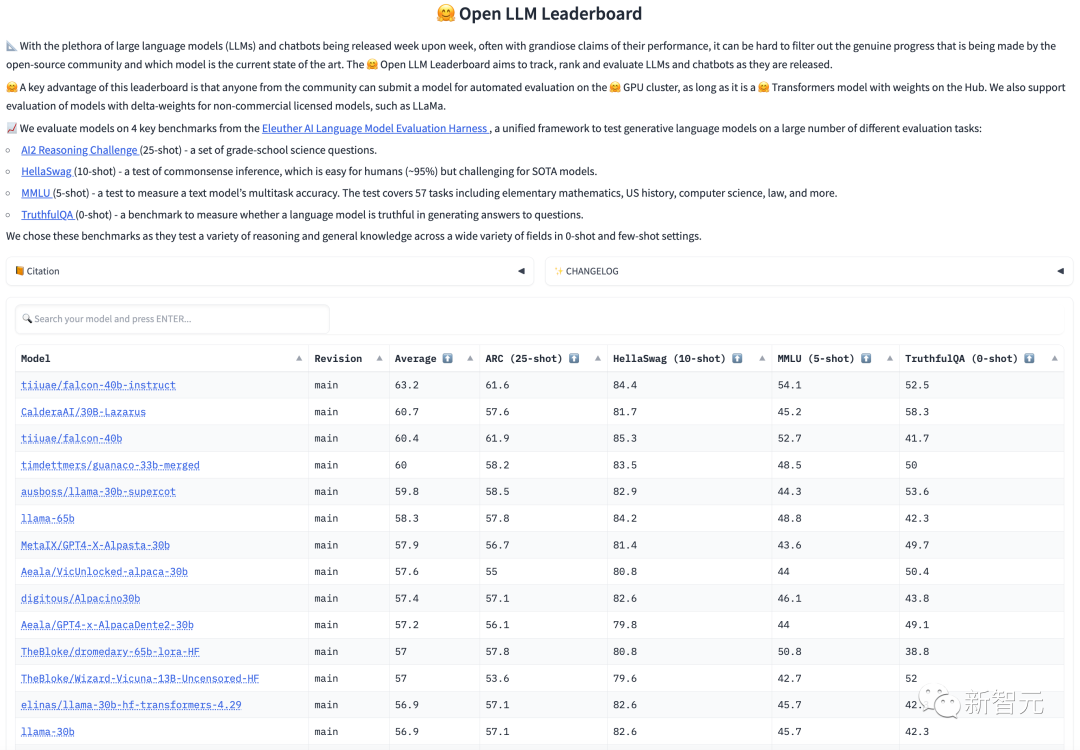
目前在OpenLLM排行榜上,Falcon位列第一,超过了LLaMA,得到了包括Thomas Wolf在内的研究人员的力荐。

然而,有些人对此表示疑虑。
先是一位网友质疑,LLaMA这些数字从哪来,看起来与论文数字不一致...
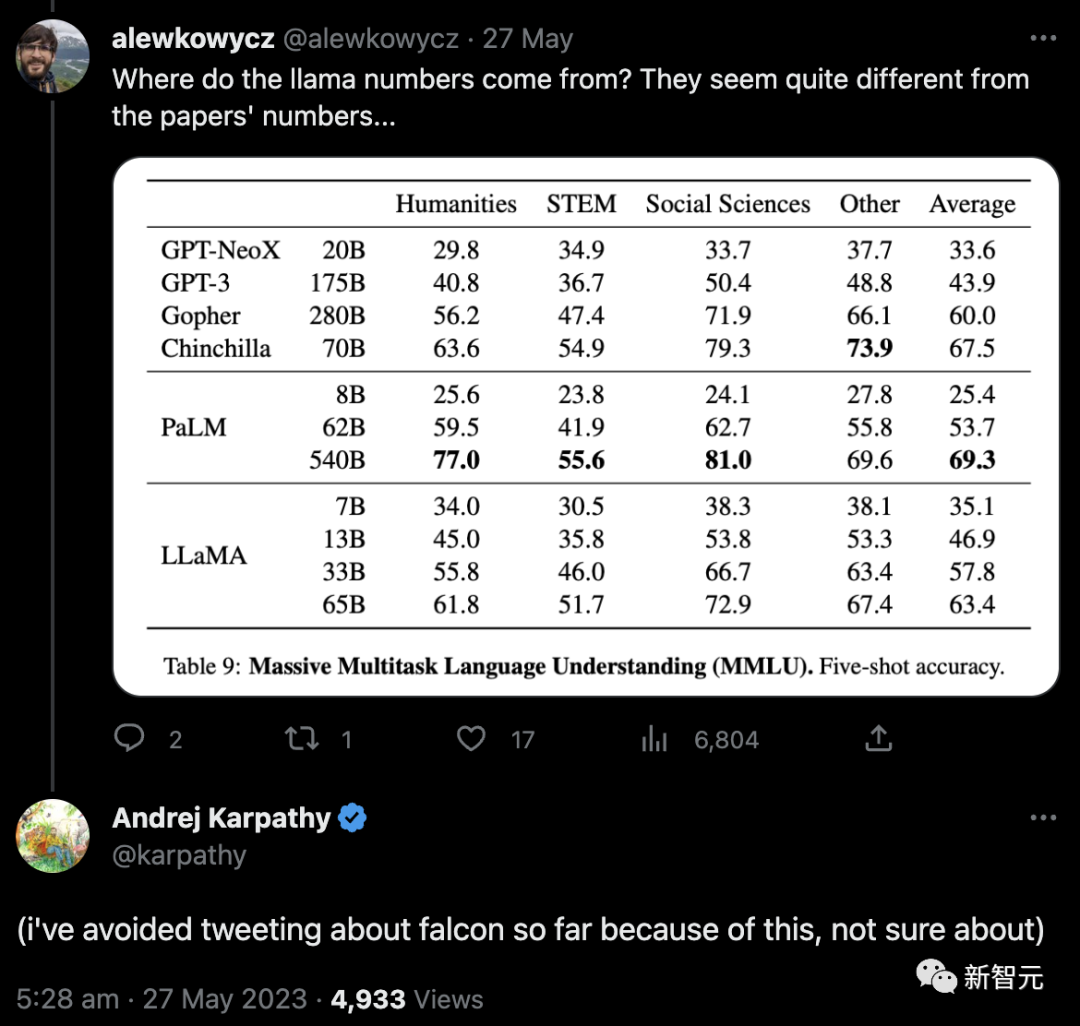
随后,OpenAI科学家Andrej Karpathy也对LLaMA 65B为什么在Open LLM排行榜上的分数明显低于官方(48.8 v.s. 63.4)表示关注。
并发文,到目前为止,我一直避免在推特上发表关于猎鹰的文章,因为这一点,不确定。
为了弄清楚这个问题,符尧和团队成员决定对LLaMA 65B进行一次公开的测试,结果得到61.4分。
在测试中,研究者没有使用任何特殊机制,LLaMA 65B就能拿到这个分数。
这一结果恰恰证明了,如果想要模型实现接近GPT-3.5的水平,最好是在LLaMA 65B上使用RLHF。
根据就是,近来符尧团队发表的一篇Chain-of-Thought Hub论文的发现。

当然,符尧表示,他们这一测评并非想要引起LLaMA和Falcon之间的争端,毕竟这些都是伟大的开源模型,都为这个领域做出了重大的贡献!
另外,Falcon还有更加方便的使用许可,这也让它有很大的发展潜力。
对于这一最新测评,网友BlancheMinerva指出,公平的比较应该在默认设置下运行猎鹰(Falcon)在MMLU上。
对此,符尧称这是正确的,并正进行这项工作,预计在一天后可以得到结果。

不管最终的结果怎样,要知道GPT-4这座山峰才是开源社区真正想要追求的目标。
OpenLLM排行榜问题
来自Meta的研究人员称赞,符尧很好地再现了LLaMa的结果,并指出了OpenLLM排行榜的问题。
与此同时,他还分享了关于OpenLLM排行榜的一些问题。
首先,MMLU的结果:LLaMa 65B MMLU结果在排行榜上是15分,但对7B模型来说是一样的。13B、30B模型也存在较小的性能差距。
OpenLLM真的需要在公布哪个模型是最好的之前看看这个。
基准:这些基准是如何选择的?
ARC 25 shot和Hellaswag 10 shot似乎与LLM并不特别相关。如果能在其中加入一些生成式基准就更好了。虽然生成式基准有其局限性,但它们仍然是有用的。

单一平均分:将结果减少到单一分数总是很吸引人的,平均分是最容易的。
但在这种情况下,4个基准的平均值真的有用吗?在MMLU上获得1分和在HellaSwag上获得1分是一样的吗?
在LLM快速迭代的世界里,开发这样一个排行榜肯定有一定的价值。

还有来自谷歌研究人员Lucas Beyer也发表了自己的观点,
疯狂的是,NLP研究人员对同一个基准有不同的理解,因此导致了完全不同的结果。同时,每当我的同事实现一个指标时,我都会立即问他们是否真的检查将官方代码的完美重现,如果没有,就放弃他们的结果。

另外,他还表示,据我所知,无论模型如何,它实际上都不会重现原始基准测试的结果。

网友附和道,这就是LLM基准的现实...

Falcon——开源、可商用、性能强
说到Falcon,其实值得我们再好好回顾一下。
按LeCun的说法,大模型时代,开源最重要。
而在Meta的LLaMA代码遭泄之后,各路开发者都开始跃跃欲试。
Falcon正是由阿联酋阿布扎比的技术创新研究所(TII)开发的一支奇兵。
刚发布时从性能上看,Falcon比LLaMA的表现更好。
目前,「Falcon」有三个版本——1B、7B和40B。
TII表示,Falcon迄今为止最强大的开源语言模型。其最大的版本,Falcon 40B,拥有400亿参数,相对于拥有650亿参数的LLaMA来说,规模上还是小了一点。
不过,此前TII曾表示,别看咱Falcon规模虽小,性能却很能打。
先进技术研究委员会(ATRC)秘书长Faisal Al Bannai认为,「Falcon」的发布将打破LLM的获取方式,并让研究人员和创业者能够以此提出最具创新性的使用案例。

FalconLM的两个版本,Falcon 40B Instruct和Falcon 40B在Hugging Face OpenLLM排行榜上位列前两名,而Meta的LLaMA则位于第三。
而前文所讲的有关排行榜的问题也正是这个。
尽管「Falcon」的论文目前还没公开发布,但Falcon 40B已经在经过精心筛选的1万亿token网络数据集的上进行了大量训练。
研究人员曾透露,「Falcon」在训练过程非常重视在大规模数据上实现高性能的重要性。
我们都知道的是,LLM对训练数据的质量非常敏感,这就是为什么研究人员会花大量的精力构建一个能够在数万个CPU核心上进行高效处理的数据管道。
目的就是,在过滤和去重的基础上从网络中提取高质量的内容。
目前,TII已经发布了精炼的网络数据集,这是一个经过精心过滤和去重的数据集。实践证明,非常有效。
仅用这个数据集训练的模型可以和其它LLM打个平手,甚至在性能上超过他们。这展示出了「Falcon」卓越的质量和影响力。

此外,Falcon模型也具有多语言的能力。
它理解英语、德语、西班牙语和法语,并且在荷兰语、意大利语、罗马尼亚语、葡萄牙语、捷克语、波兰语和瑞典语等一些欧洲小语种上也懂得不少。
Falcon 40B还是继H2O.ai模型发布后,第二个真正开源的模型。
另外,还有一点非常重要——Falcon是目前唯一的可以免费商用的开源模型。
在早期,TII要求,商业用途使用Falcon,如果产生了超过100万美元以上的可归因收入,将会收取10%的「使用税」。
可是财大气粗的中东土豪们没过多长时间就取消了这个限制。
至少到目前为止,所有对Falcon的商业化使用和微调都不会收取任何费用。
土豪们表示,现在暂时不需要通过这个模型挣钱。
而且,TII还在全球征集商用化方案。
对于有潜力的科研和商业化方案,他们还会提供更多的「训练算力支持」,或者提供进一步的商业化机会。

这简直就是在说:只要项目好,模型免费用!算力管够!钱不够我们还能给你凑!
对于初创企业来说,这简直就是来自中东土豪的「AI大模型创业一站式解决方案」。
根据开发团队称,FalconLM 竞争优势的一个重要方面是训练数据的选择。
研究团队开发了一个从公共爬网数据集中提取高质量数据并删除重复数据的流程。
在彻底清理多余重复内容后,保留了 5 万亿的token——足以训练强大的语言模型。
40B的Falcon LM使用1万亿个token进行训练, 7B版本的模型训练token达到 1.5 万亿。
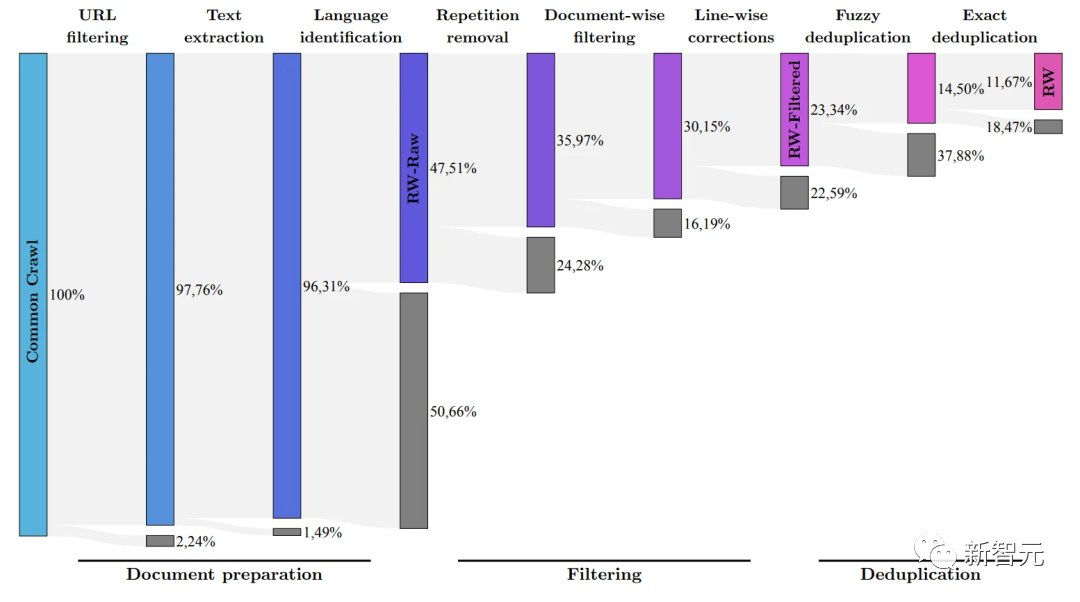
(研究团队的目标是使用RefinedWeb数据集从Common Crawl中仅过滤出质量最高的原始数据)
此外,Falcon的训练成本相对来说更加可控。
TII称,与GPT-3相比,Falcon在只使用75%的训练计算预算的情况下,就实现了显著的性能提升。
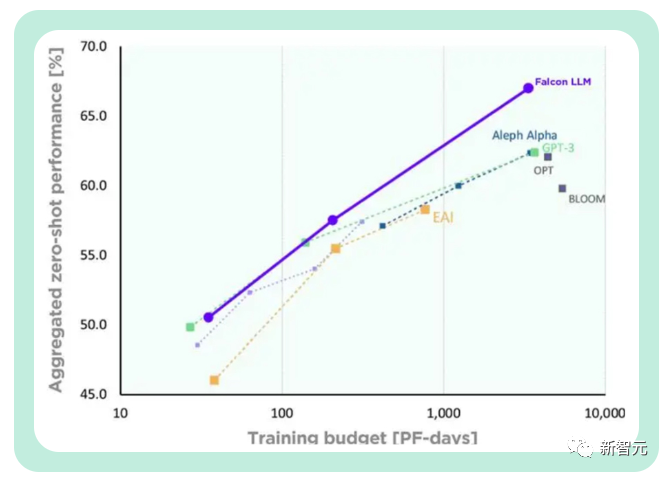
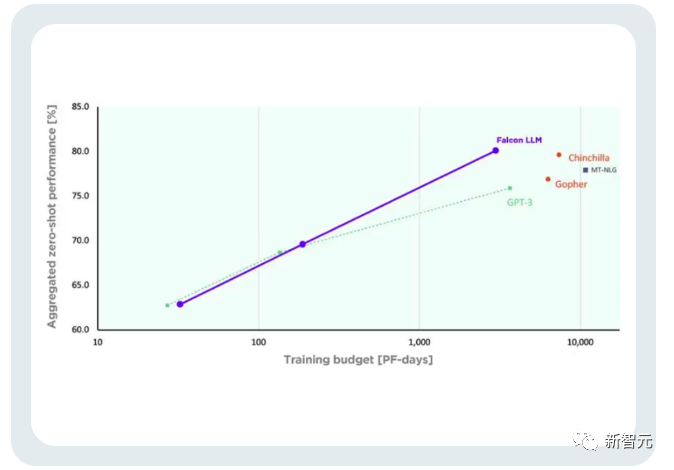
而且在推断(Inference)时只需要只需要20%的计算时间,成功实现了计算资源的高效利用。
-
模型
+关注
关注
1文章
3238浏览量
48824 -
代码
+关注
关注
30文章
4786浏览量
68558 -
GitHub
+关注
关注
3文章
470浏览量
16435
原文标题:击败LLaMA?史上最强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
文章出处:【微信号:AI智胜未来,微信公众号:AI智胜未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用NVIDIA TensorRT提升Llama 3.2性能
Llama 3 的未来发展趋势
如何使用 Llama 3 进行文本生成
Llama 3 语言模型应用
调用云数据库更新排行榜单
Meta Llama 3.1系列模型可在Google Cloud上使用
如何将Llama3.1模型部署在英特尔酷睿Ultra处理器

PerfXCloud平台成功接入Meta Llama3.1
Llama 3 王者归来,Airbox 率先支持部署

百度智能云国内首家支持Llama3全系列训练推理!
Meta推出最强开源模型Llama 3 要挑战GPT
中颖电子入选Fabless 100排行榜TOP10微控制器公司榜单






 工商网监
工商网监
评论