 CVPR 2023:把人放在他们的位置,把人自然地插到图像里
CVPR 2023:把人放在他们的位置,把人自然地插到图像里
CVPR 2023:把人放在他们的位置,把人自然地插到图像里
1. 论文信息
题目:Putting People in Their Place: Affordance-Aware Human Insertion into Scenes
作者:Sumith Kulal, Tim Brooks, Alex Aiken, Jiajun Wu, Jimei Yang, Jingwan Lu, Alexei A. Efros, Krishna Kumar Singh
链接:https://arxiv.org/abs/2304.14406
代码:https://sumith1896.github.io/affordance-insertion/
2. 引言

一百年前,雅各布·冯·厄克尔指出了感知环境(umwelt)在生物生活中的关键、甚至决定性作用。他认为,生物只能感知到它可以影响或被影响的环境部分。从某种意义上说,我们对世界的感知取决于我们能够执行的相互作用类型。相关的功能性视觉理解思想(给定场景对代理人提供了哪些动作?)在1930年代由格式塔心理学家讨论过,后来由J.J.吉布森描述为“可供性”。虽然这个方向激发了视觉和心理学研究的许多努力,但是对可供性感知的全面计算模型仍然难以捉摸。这样的计算模型的价值对未来的视觉和机器人研究是不可否认的。
可供性:Affordance,指一个物理对象与人之间的关系。无论是动物还是人类,甚至是机器和机器人,他们之间发生的任何交互作用。可供性的体现,由物品的品质,和与之交互的主体的能力共同决定。
过去十年,对基于数据驱动的可供性感知的计算模型重新产生了兴趣。早期的研究采用了中介方法,通过推断或使用中间语义或3D信息来辅助可供性感知。一些难以预测的可供性例子包括涉及物体之间复杂交互或需要更高层次推理和对场景上下文的理解。例如,预测一把椅子是否可以用来站立可能相对简单,但是预测一把椅子是否可以用来到达高架子、避开障碍物或单腿平衡可能更加困难。同样地,预测一扇门是否可以被打开可能相对容易,但是预测一扇门是否可以在特定情境下用作盾牌或路障可能更加具有挑战性。通常,预测涉及物体的新颖或创造性使用或需要深入理解场景上下文的可供性可能特别具有挑战性。而近期的方法则更加关注直接感知可供性,更符合吉布森的框架。然而,这些方法受到数据集特定要求的严格限制,降低了它们的普适性。
为了促进更普遍的设置,我们从最近大规模生成模型的进展中汲取灵感,例如文本到图像系统。这些模型的样本展示了令人印象深刻的物体-场景组合性。然而,这些组合是隐式的,可供性仅限于通常在静态图像中捕捉并由说明文字描述的内容。我们通过将人“放入画面”并在人类活动的视频上进行训练,将可供性预测任务明确化。
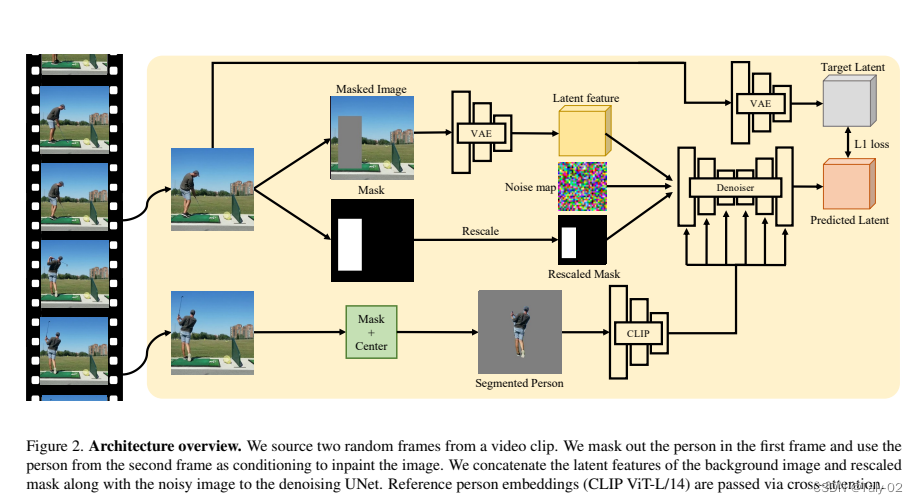
我们将问题表述为条件修补任务。给定一个遮罩的场景图像和一个参考人物,我们学习在遮罩区域内正确地填充人物和可供性。在训练时,我们从视频剪辑中借用两个随机帧,遮罩一个帧,并尝试使用第二帧中的人作为条件进行修补。这迫使模型学习给定上下文下可能的场景可供性以及实现连贯图像所需的重新姿态和协调。在推理时,可以使用不同的场景和人物图像组合提示模型。我们在一个包含240万个人类在各种场景中移动的视频剪辑数据集上训练了一个大规模模型。
除了条件任务外,我们的模型可以在推理时以不同的方式进行提示。如图中的最后一行所示,当没有人物时,我们的模型可以产生逼真的虚构人物。同样地,当没有场景时,它也可以产生逼真的虚构场景。还可以执行部分人物完成任务,如更改姿势或交换衣服。我们展示了训练视频对于预测可供性的重要性。
3. 方法
3.1. Diffusion Models介绍
Diffusion Models是一种生成模型,使用扩散过程来建模数据的概率分布,从而可以生成逼真的图像样本。Diffusion Models使用反向Diffusion Process来建模数据的概率分布,其中反向Diffusion Process是一个从数据点的随机状态开始,向初始状态扩散的过程。在训练过程中,Diffusion Models使用Score Matching方法来估计反向Diffusion Process的条件概率密度函数。在生成过程中,Diffusion Models通过随机初始化一个数据点的状态,然后使用反向Diffusion Process逆推回初始状态,从而生成一张新的图像样本。Diffusion Models可以通过调整Diffusion Process中的扩散系数来控制生成图像的多样性和清晰度。其中,Diffusion Process的随机微分方程和反向Diffusion Process的随机微分方程如下:
3.2. 任务设定

我们模型的输入包含一个遮罩的场景图像和一个参考人物,输出图像包含在场景上重新调整姿势的参考人物。
受到Humans in Context (HiC)的启发,我们生成了一个大规模的人在场景中移动的视频数据集,并使用视频帧作为完全自监督的训练数据。我们将问题表述为条件生成问题。在训练时,我们从视频中提取两个包含同一人的随机帧。我们将第一个帧中的人物遮罩并用作输入场景,然后从第二个帧中裁剪并居中人物作为参考人物条件。我们训练一个条件潜在扩散模型,同时以遮罩的场景图像和参考人物图像为条件。这鼓励模型在自监督的方式下推断正确的姿势,hallucinate的人物-场景交互,并将重新姿势的人物无缝地融入场景中。在测试时,模型可以支持多个应用程序,插入不同的参考人物、无参考hallucinate的人物和hallucinate的场景。我们通过在训练过程中随机删除条件信号来实现这一点。我们在实验部分评估了人物条件生成、人物hallucinate和场景hallucinate的质量。
hallucinate:幻觉是指人们的感官(视觉、听觉、嗅觉、触觉和味觉)出现虚假的感知,看起来是真实的,但实际上并不存在。
3.3. 模型训练
本文介绍了一个基于自监督训练的人物-场景交互生成模型。为了训练模型,作者生成了一个包含240万个人在场景中移动的视频剪辑的数据集,使用了HiC的预处理流程,并使用Keypoint R-CNN和OpenPose进行人物检测和关键点检测。作者使用Mask R-CNN检测人物掩码,以在输入场景图像中遮蔽人物并裁剪出参考人物。作者还设计了一种遮蔽和数据增强策略,以支持不同粒度级别的人物插入,并通过Dropout和DDIM样本来提高生成质量。作者的实验结果表明,所提出的方法可以成功地生成高质量的人物-场景交互图像。
4. 实验
本表格展示了进行了几项消融实验,以分析不同因素对所提出方法性能的影响。
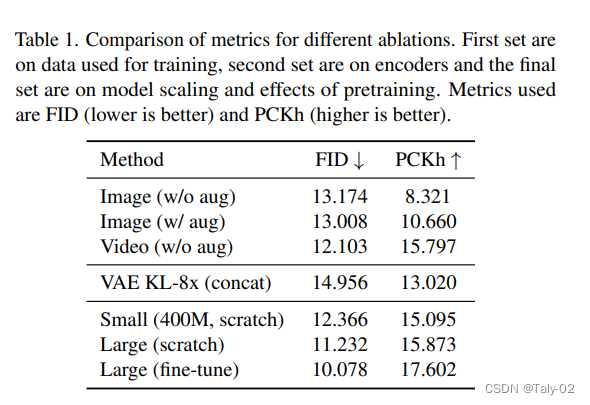
第一组实验比较了使用不同类型的输入数据和数据增强策略的方法性能。结果显示,使用视频作为输入数据且不进行数据增强会在FID(越小越好)和PCKh(越大越好)指标方面获得最佳性能。这表明使用视频作为输入数据可以提供更多的时间信息和上下文,使模型可以从中学习,而数据增强可以进一步提高性能。第二组实验研究了不同图像编码器对所提出方法性能的影响。结果显示,使用带有8倍KL散度损失的VAE的性能不如使用不带KL散度损失的图像编码器。这表明对于所提出的方法,使用更简单的图像编码器更为有效。最后一组实验分析了模型规模和预训练对所提出方法性能的影响。结果显示,增加模型规模并从预训练的检查点进行微调会在FID和PCKh指标方面获得更好的性能。这表明增加模型容量并使用预训练可以帮助提高所提出方法的性能。

本节主要介绍了针对人物幻觉和场景幻觉任务的实验评估。在人物幻觉任务中,作者将条件人物去除后进行评估,并与Stable Diffusion和DALL-E 2进行比较。作者通过传递空条件人物对其模型进行评估,并使用Stable Diffusion进行定量评估。在定性评估中,作者生成了具有相同提示的Stable Diffusion和DALL-E 2结果。实验结果表明,作者的方法可以成功地幻觉出与输入场景相一致的多样化人物,并且其性能优于基线方法。在场景幻觉任务中,作者评估了受限和非受限两种场景幻觉情况,并与Stable Diffusion和DALL-E 2进行比较。实验结果表明,作者的方法比基线方法更能够维持输入参考人物的位置和姿态,并且在综合大量图像的场景幻觉任务中表现更好。作者还分析了条件因素对模型性能的影响,并对其进行了消融实验。总的来说,实验结果表明,作者的方法在人物幻觉和场景幻觉任务中表现出色,并且相比基线方法具有更好的性能和生成效果。同时,作者还分析了模型性能的不同影响因素,并提出了可用于改进性能的策略。
5. 讨论
本文提出的方法具有以下优点和广阔的应用前景:
数据集限制:为了训练模型,作者使用了一个包含240万个人在场景中移动的视频剪辑的数据集,这些视频剪辑来自于互联网,可能存在版权和隐私问题。此外,数据集中的场景和人物的多样性也有限,这可能影响了模型在生成真实世界的多样化人物和场景时的表现。
参考人物的选择:为了生成人物-场景交互图像,模型需要一个参考人物来指导生成。在本文中,作者使用了一些启发式规则来选择参考人物,如选择中央人物或群体中的人物。但这种启发式规则可能不能很好地适应不同的场景和应用场景,可能需要更精细的选择方法来提高模型的生成效果。
训练和推理时间:由于所提出的方法使用了大规模的神经网络模型,并需要在大量的数据上进行训练,因此训练时间和计算资源需求较高。在推理时,生成一张高质量的图像也需要一定的时间和计算资源。这可能限制了该方法在实际应用中的可扩展性和实用性。
生成结果的控制性较差:本文中所提出的方法是无条件生成人物-场景交互图像,即无法直接控制生成图像中的人物和场景属性。尽管在一定程度上可以通过选择参考人物来指导生成,但仍然存在控制性较差的问题。在某些应用场景,需要更精细的生成控制来满足特定的需求,这可能需要其他方法的支持。
但是本文提出的方法在人物-场景交互图像生成任务中表现出了良好的性能和效果,但也存在一些缺点:
数据集:为了训练模型,作者使用了一个包含240万个人在场景中移动的视频剪辑的数据集,这些视频剪辑来自于互联网,可能存在版权和隐私问题。此外,数据集中的场景和人物的多样性也有限,这可能影响了模型在生成真实世界的多样化人物和场景时的表现。
参考人物的选择:为了生成人物-场景交互图像,模型需要一个参考人物来指导生成。在本文中,作者使用了一些启发式规则来选择参考人物,如选择中央人物或群体中的人物。但这种启发式规则可能不能很好地适应不同的场景和应用场景,可能需要更精细的选择方法来提高模型的生成效果。
训练和推理时间:由于所提出的方法使用了大规模的神经网络模型,并需要在大量的数据上进行训练,因此训练时间和计算资源需求较高。在推理时,生成一张高质量的图像也需要一定的时间和计算资源。这可能限制了该方法在实际应用中的可扩展性和实用性。
生成结果的控制性较差:本文中所提出的方法是无条件生成人物-场景交互图像,即无法直接控制生成图像中的人物和场景属性。尽管在一定程度上可以通过选择参考人物来指导生成,但仍然存在控制性较差的问题。在某些应用场景,需要更精细的生成控制来满足特定的需求,这可能需要其他方法的支持。
同时作者指出 EfficientViT 的一个局限性是,尽管它具有很高的推理速度,但由于引入了额外的 FFN,在模型大小方面与最先进的高效 CNN相比略微更大。此外,模型是基于构建高效视觉 Transformer 的指导方针手动设计的。在未来的工作中,可以有兴趣减小模型大小,并结合自动搜索技术进一步提高模型的容量和效率。
6. 结论
在这项工作中,我们提出了一项新的任务,即感知可供性的人类插入场景,我们通过使用视频数据以自我监督的方式学习条件扩散模型来解决它。我们展示了各种定性结果来证明我们方法的有效性。我们还进行了详细的消融研究,以分析各种设计选择的影响。我们希望这项工作能激励其他研究人员追求这个新的研究方向
-
模型
+关注
关注
1文章
3268浏览量
48937 -
数据集
+关注
关注
4文章
1208浏览量
24743
原文标题:CVPR 2023:把人放在他们的位置,把人自然地插到图像里
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论