 Allen AI推出集成主流大语言模型的LLM-BLENDER框架
Allen AI推出集成主流大语言模型的LLM-BLENDER框架
wkk
随着大语言模型(LLM)的迅速发展,众多开源的LLM性能参差不齐。今天分享的是由Allen AI实验室联合南加大和浙江大学的最新研究论文,发表在ACL上。本文提出了一个集成框架(LLM-BLENDER),旨在通过利用多个开源大型语言模型的不同优势使框架始终保持卓越的性能。
下面请大家跟随我的视角一起来分析LLM-BLENDER框架是如何工作的吧!

论文:LLM-BLENDER: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
链接:https://arxiv.org/pdf/2306.02561
简介
考虑到众多LLM有不同的优势和劣势,本文开发了一种利用其互补潜力的集成方法,从而提高鲁棒性、泛化和准确性。通过结合单个LLM的贡献,可以减轻单个LLM中的偏见、错误和不确定性信息,从而产生更符合人类偏好的输出。
LLM-BLENDER
LLM-BLENDER包括两个模块:PAIRRANKER和GENFUSER。首先,PAIRRANKER比较N个LLM的输出,然后通过GENFUSER将它们融合,从排名前K的输出中生成最终输出。现有的方法如instructGPT中的reward model能够对输入x的输出Y进行排名,但是当在多个LLM进行组合时其效果并没有那么明显。原因在于,它们都是由复杂的模型产生的,其中一个可能只比另一个好一点。即使对人类来说,在没有直接比较的情况下衡量候选质量也可能是一项挑战。
因此,本文提出了一种专门用于成对比较的方法PAIRRANKER,以有效地识别候选输出之间的细微差异并提高性能。具体地,首先为每个输入收集N个模型的输出,然后创建其输出的N(N−1)/2对。以fφ(x,yi,yj)的形式将输入 x 和两个候选输出yi和yj联合编码为交叉注意力编码器的输入,以学习并确定哪个候选更好。
在推理阶段,计算一个矩阵,该矩阵包含表示成对比较结果的logits。给定该矩阵,可以推断给定输入x的N个输出的排序。随后,可以使用来自PAIRRANKER的每个输入的排名最高的候选者作为最终结果。
尽管如此,这种方法可能会限制产生比现有候选更好产出的潜力。为了研究这种可能性,从而引入了GENFUSER模块来融合N个排名的候选输出中的前K个,并为最终用户生成改进的输出。
任务定义
给定输入x和N个不同的语言模型{M1,., MN },可以通过使用每个模型处理x来生成N个候选输出Y={y1,.,yN}。
研究目标是开发一种集成学习方法,该方法为输入x产生输出y,然后计算x与y的最大化相似度Q。与使用固定模型或随机选择x的模型相比,这种方法将产生更好的总体性能。
MixInstruct:一个新的基准
本文引入了一个新的数据集MixInstruct,用于在指令跟随任务中对LLM的集成模型进行基准测试。主要从四个来源收集了一组大规模的指令示例,如下表所示。对数据集中的100k个样本进行训练,5k个用于验证,5k个用于测试。然后,在这110k个示例上运行N=11个流行的开源LLM,包括 Vicuna、OpenAssistant、Alpaca、MPT等如下图所示。
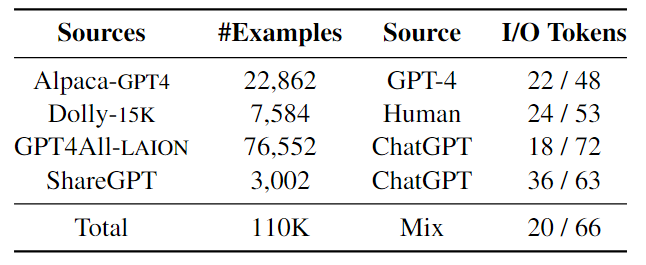
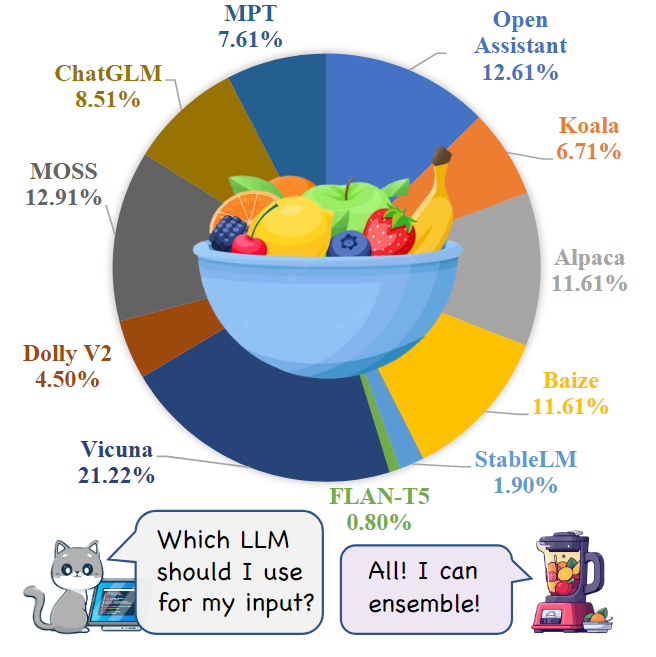
为了获得候选输出的性能排名,为ChatGPT设计了comparative prompts来评估所有候选对。具体来说,对于每个示例,准备了55对候选者(11×10/2)。对于每一对,要求ChatGPT基于输入x和真值输出y来判断哪一个更好(或声明平局)。
LLM-BLENDER: 一个新的框架
提出的一个用于集成LLM的框架LLM-BLENDER,如下图所示。该框架由两个主要组件组成:成对排序模块PAIRRANKER和融合模块GENFUSER。PAIRRANKER模块学习比较每个输入的所有候选对,然后对候选输出进行排名。选择前K=3个排名的候选输出,将它们与输入x连接起来,并为GENFUSER模块构建输入序列。GENFUSER模块是一个seq2seq LM,由它生成为用户服务的最终输出。
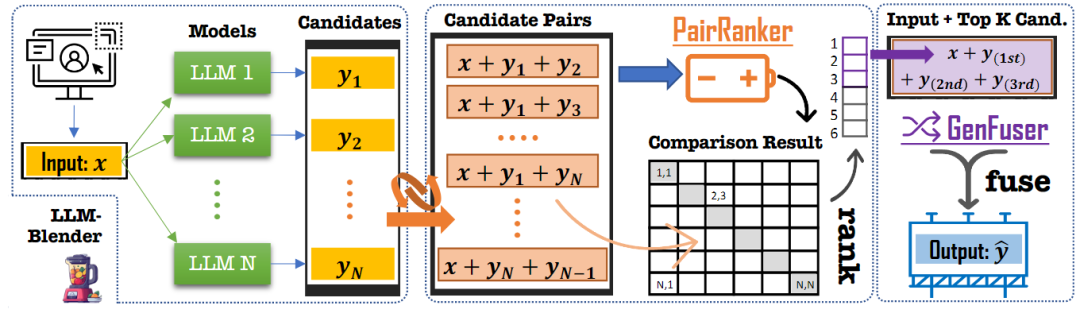
PAIRRANKER 架构
Encoding:使用Transformer层对一个输入和一对候选对象进行编码,通过注意力机制在输入的上下文中捕获候选输出之间的差异。按顺序连接这三个片段,并使用特殊标记作为分隔符形成单个输入序列:< source >、< candidate1 >和< candidate2 >。生成的transformer输入序列的形式为“< s >< source > x < /s > < candidate1 > yi< /s > < candidate2 > yj < /s >”,其中x是源输入的文本,yi和yj是两个候选输出的文本。特殊标记< source >、< candidate1 >和< candidate2 >的嵌入分别用作x、yi和yj的表示。
Traning:为了确定两个候选输出的分数,将X的嵌入分别与yi和yj连接起来,并使它们传递给多层感知器,最终层的维度等于要优化的Q函数的数量。该维度内的每个值表示特定Q函数的score。通过对这些Q个分数取平均值来导出候选输出的最终分数。并在训练阶段应用了有效的子采样策略来确保学习效率。训练期间,从候选输出中随机选择一些组合,而不是所有N(N−1)/2对。实践发现,每个输入使用 5 对足以获得不错的结果。
考虑到语言模型的位置嵌入,一对(x,yi,yj)中候选输出的顺序很重要,因为(x,yi,yj)和(x,yj,yi)的比较结果可能不一致。因此,在训练过程中将每个训练对中候选输出的顺序打乱,以便模型学习与其自身一致
Inference:在推理阶段,计算每一对候选输出的分数。在N(N−1)次迭代后,得到矩阵M如下图所示,为了根据 M 确定最佳候选者,通过引入了聚合函数来确定候选输出的最终排名。
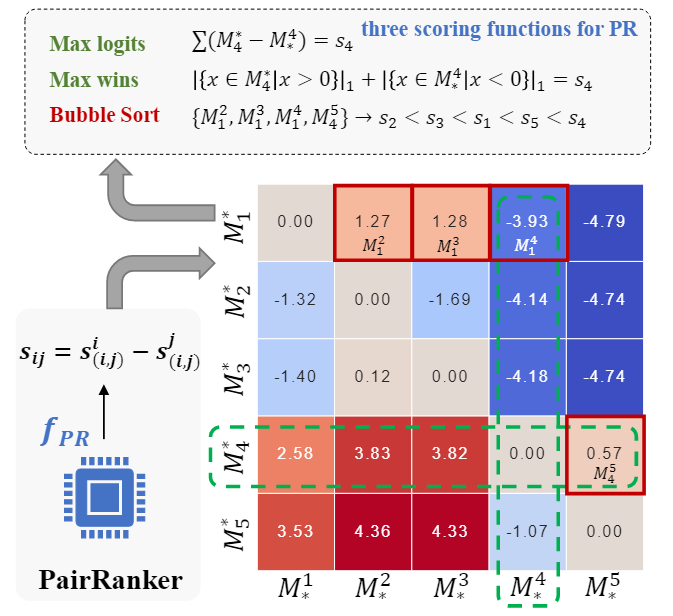
GENFUSER: 生成融合
PAIRRANKER的有效性受到从候选输出中选择的质量的限制。假设,通过合并多个排名靠前的候选输出,能够克服这种限制。由于这些得分较高的候选输出往往表现出互补的优势和劣势,因此在减轻其缺点的同时结合它们的优势来生成更好的响应是合理的。研究目标是设计一个生成模型,该模型采用输入x和K个排名靠前的候选输出,并产生改进的输出作为最终响应。为了实现这一点,提出了GENFUSER,这是一种seq2seq方法,用于融合一组以输入指令为条件的候选输出,以生成增强的输出。具体地,使用分隔符标记顺序连接输入和K个候选,并微调类似T5的模型以学习生成y。
评估
使用MixInstruct数据集进行评估,使用DeBERTa作为PAIRRANKER的主干,GENFUSER则是基于Flan-T5-XL ,实验结果如下表所示。
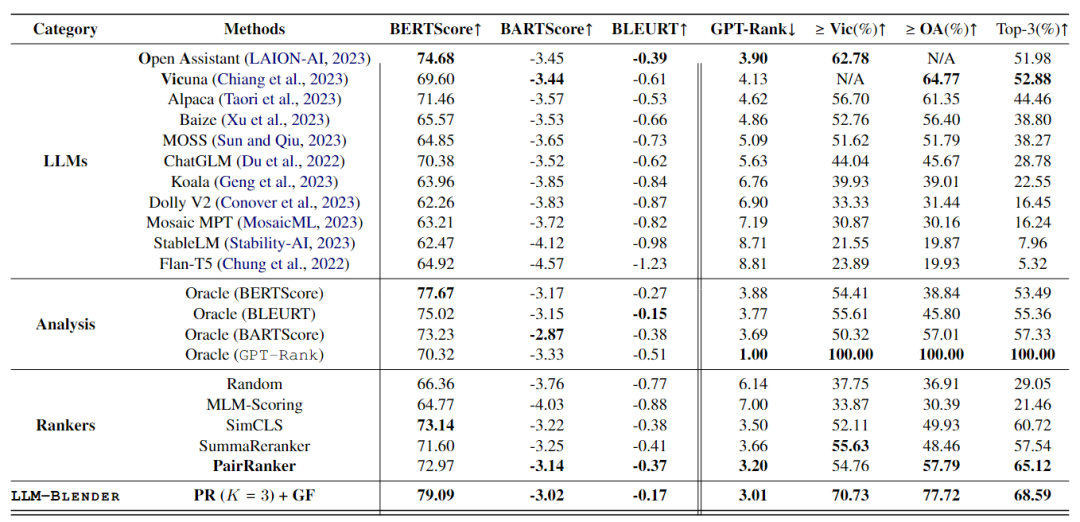
主要结果
LLM具有不同的优势和劣势
根据ChatGPT确定LLM的平均等级,按排序顺序显示LLM。在这些模型中,Open Assistant、Vicuna和Alpaca是表现最好的三项,继它们之后为Baize、Moss和ChatGLM,也在MixInstruction上表现出色。相反,Mosaic MPT、StableLM和Flan-T5在评估中排名倒数第三。尽管如此,top/bottom模型的平均GPT排名与first/last位置保持着明显的距差距,这突出了组合LLM的重要性。
顶级LLM并不总是最好的
尽管OA和Vic表现得非常好,但仍有很大一部分示例显示其他LLM优于它们。例如,Koala的平均GPT-Rank为6.76,但大约40%的示例表明Koala产生了更好或同样优于OA和Vic的结果。这进一步强调了使用LLM-BLENDER框架进行排名和融合的重要性。
NLG Metrics
根据每个Metrics本身对oracle选择的性能进行了全面分析。研究结果表明,这些选择在其他指标上也表现出良好的性能。这一观察结果证实了使用BARTScore为PAIRRANKER提供监督的合理性。
PAIRRANKE的表现优于其他排名工具
MLM-Scoring无法胜出random selection,突出了其无监督范式的局限性。相反,与BARTScore和GPT-Rank的最佳模型(OA)相比,SimCLS、SummaReranker和PAIRRANKER表现出更好的性能。值得注意的是,PAIRRANKER选择的响应的平均GPT排名显着优于最佳模型,以及所有其他排名。
LLM-BLENDER 是最好的
使用从PAIRRANKER中选出的前三名,并将其作为GENFUSER的候选。在此的基础上,LLM-BLENDER展示了预期的卓越性能。
排名相关性
除了只关注每个排名的top-1之外,还对所有具有GPT排名的候选之间的总体排名相关性进行了全面分析。事实证明,BARTScore与GPT排名的相关性最高,这表明使用BARTScore提供监督为训练。对于排序器来说,MLM得分仍然无法超过random permutations。
更多分析
将PAIRRANKER应用于三个典型的自然语言生成(NLG)任务:摘要、机器翻译和约束文本生成。发现PAIRRANKER在使用单个相同的基础模型解码N个候选者(使用不同的算法)的上下文中仍然大大优于其他方法。
总结
本文引入了LLM-BLENDER,这是一个创新的集成框架,通过利用多个开源LLM的不同优势来获得持续卓越的性能。LLM-BLENDER通过排名的方式来减少单个LLM的弱点,并通过融合生成来整合优势,以提高LLM的能力。
总之,这是一篇非常有趣的文章,想了解更深入的话,还是看下原论文吧~
-
框架
+关注
关注
0文章
403浏览量
17472 -
模型
+关注
关注
1文章
3220浏览量
48803 -
语言模型
+关注
关注
0文章
520浏览量
10268 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:博采众长!我全都要!Allen AI推出集成主流大语言模型的LLM-BLENDER框架
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVIDIA 推出大型语言模型云服务以推进 AI 和数字生物学的发展
LLM之外的性价比之选,小语言模型
NVIDIA AI平台为大型语言模型带来巨大收益
基于Transformer的大型语言模型(LLM)的内部机制

现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

Snowflake推出面向企业AI的大语言模型
大语言模型(LLM)快速理解

LLM模型的应用领域
llm模型和chatGPT的区别
AI大模型与AI框架的关系
LLM大模型推理加速的关键技术
新品|LLM Module,离线大语言模型模块






 工商网监
工商网监
评论