 ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
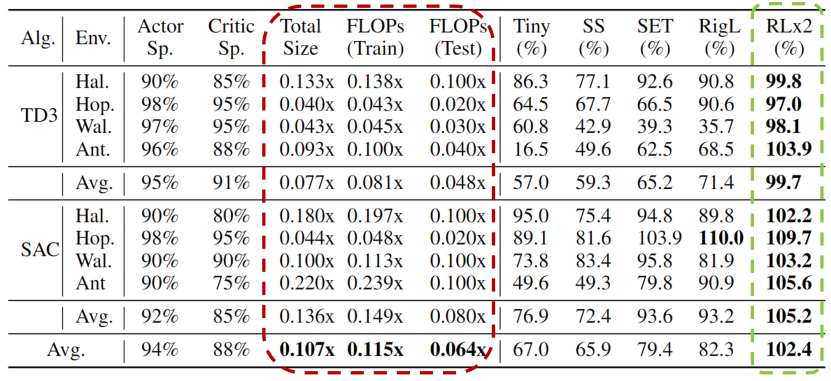
深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨大潜力。然而现有的生成小型模型的方法主要基于知识蒸馏,即通过迭代训练稠密网络,训练过程仍需要大量的计算资源。另外,由于强化学习自举训练的复杂性,训练过程中全程进行稀疏训练在深度强化学习领域尚未得到充分的研究。 清华大学黄隆波团队提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),可适用于多种离策略强化学习算法。它采用基于梯度的拓扑演化原则,能够完全基于稀疏网络训练稀疏深度强化学习模型。RLx2 引入了一种延迟多步差分目标机制,配合动态容量的回放缓冲区,实现了在稀疏模型中的稳健值学习和高效拓扑探索。在多个 MuJoCo 基准任务中,RLx2 达到了最先进的稀疏训练性能,显示出 7.5 倍至 20 倍的模型压缩,而仅有不到 3% 的性能降低,并且在训练和推理中分别减少了高达 20 倍和 50 倍的浮点运算数。大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销。

- 论文主页:https://arxiv.org/abs/2205.15043
- 论文代码:https://github.com/tyq1024/RLx2
图:基于强化学习的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家 高昂的资源消耗限制了深度强化学习在资源受限设备上的训练和部署。为了解决这一问题,作者引入了稀疏神经网络。稀疏神经网络最初在深度监督学习中提出,展示出了对深度强化学习模型压缩和训练加速的巨大潜力。在深度监督学习中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于网络结构演化的动态稀疏训练(Dynamic sparse training - DST)框架可以从头开始训练一个 90% 稀疏的神经网络,而不会出现性能下降。
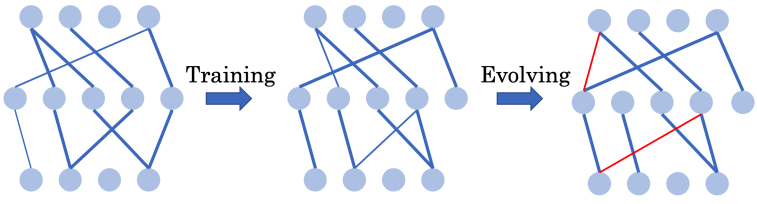
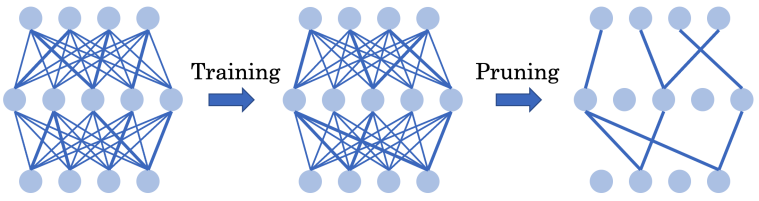
能否通过全程使用超稀疏网络从头训练出高效的深度强化学习智能体?
方法 清华大学黄隆波团队对这一问题给出了肯定的答案,并提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于离策略强化学习(Off-policy RL)。这是第一个在深度强化学习领域以 90% 以上稀疏度进行全程稀疏训练,并且仅有微小性能损失的算法框架。RLx2 受到了在监督学习中基于梯度的拓扑演化的动态稀疏训练方法 RigL [Evci et al. 2020] 的启发。然而,直接应用 RigL 无法实现高稀疏度,因为稀疏的深度强化学习模型由于假设空间有限而导致价值估计不可靠,进而干扰了网络结构的拓扑演化。 因此,RLx2 引入了延迟多步差分目标(Delayed multi-step TD target)机制和动态容量回放缓冲区(Dynamic capacity buffer),以实现稳健的价值学习(Value learning)。这两个新组件解决了稀疏拓扑下的价值估计问题,并与基于 RigL 的拓扑演化准则一起实现了出色的稀疏训练性能。为了阐明设计 RLx2 的动机,作者以一个简单的 MuJoCo 控制任务 InvertedPendulum-v2 为例,对四种使用不同价值学习和网络拓扑更新方案的稀疏训练方法进行了比较。
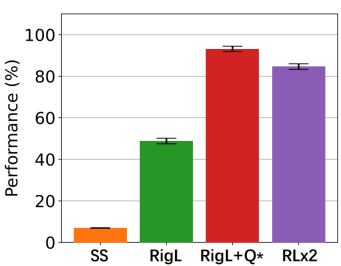
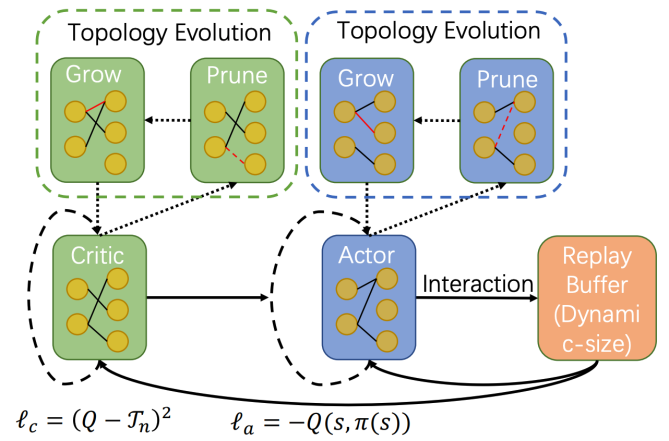
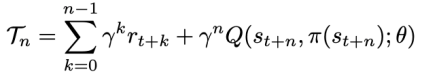

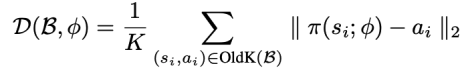
原文标题:ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2916文章
45232浏览量
380152
原文标题:ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
清华光芯片取得新突破,迈向AI光训练
电子发烧友网报道(文/吴子鹏)近日,清华大学发布官方消息称,清华大学电子工程系方璐教授课题组、自动化系戴琼海院士课题组另辟蹊径,首创了全前向智能光计算训练架构,研制了“太极-II”光训练
详解RAD端到端强化学习后训练范式
受限于算力和数据,大语言模型预训练的 scalinglaw 已经趋近于极限。DeepSeekR1/OpenAl01通过强化学习后训练涌现了强大的推理能力,掀起新一轮技术革新。

大模型训练框架(五)之Accelerate
Hugging Face 的 Accelerate1是一个用于简化和加速深度学习模型训练的库,它支持在多种硬件配置上进行分布式训练,包括 CPU、GPU、TPU 等。Accelerate 允许用户
PyTorch GPU 加速训练模型方法
在深度学习领域,GPU加速训练模型已经成为提高训练效率和缩短训练时间的重要手段。PyTorch作为一个流行的深度学习
如何使用 PyTorch 进行强化学习
强化学习(Reinforcement Learning, RL)是一种机器学习方法,它通过与环境的交互来学习如何做出决策,以最大化累积奖励。PyTorch 是一个流行的开源机器学习库,
什么是协议分析仪和训练器
协议分析仪和训练器是两种不同但相关的设备或工具,它们在网络通信、电子设计和测试等领域发挥着重要作用。以下是对这两种设备的详细解释:一、协议分析仪
定义:协议分析仪(Protocol Analyzer
发表于 10-29 14:33
冠军说|第二届OpenHarmony竞赛训练营冠军团队专访
在刚刚结束的第三届OpenHarmony技术大会上
今年的OpenHarmony竞赛训练营获奖团队
举行了星光熠熠的颁奖仪式
10月11日,经过激烈的现场决赛角逐共有10个赛队脱颖而出
其中来自
发表于 10-28 17:11

预训练和迁移学习的区别和联系
预训练和迁移学习是深度学习和机器学习领域中的两个重要概念,它们在提高模型性能、减少训练时间和降低对数据量的需求方面发挥着关键作用。本文将从定
如何理解机器学习中的训练集、验证集和测试集
理解机器学习中的训练集、验证集和测试集,是掌握机器学习核心概念和流程的重要一步。这三者不仅构成了模型学习与评估的基础框架,还直接关系到模型性
PyTorch如何训练自己的数据集
PyTorch是一个广泛使用的深度学习框架,它以其灵活性、易用性和强大的动态图特性而闻名。在训练深度学习模型时,数据集是不可或缺的组成部分。然而,很多时候,我们可能需要使用自己的数据集
深度学习模型训练过程详解
深度学习模型训练是一个复杂且关键的过程,它涉及大量的数据、计算资源和精心设计的算法。训练一个深度学习模型,本质上是通过优化算法调整模型参数,使模型能够更好地拟合数据,提高预测或分类的准
基于毫米波的人体跟踪和识别算法
。雷达已被提议作为粗粒度活动识别的替代模式,使用微多普勒频谱图捕捉环境信息的最小子集。然而,由于低成本毫米波雷达系统产生稀疏和不均匀的点云,训练细粒度、准确的活动分类器是一个挑战。在本文中,我们
发表于 05-14 18:40
【大语言模型:原理与工程实践】大语言模型的预训练
大语言模型的核心特点在于其庞大的参数量,这赋予了模型强大的学习容量,使其无需依赖微调即可适应各种下游任务,而更倾向于培养通用的处理能力。然而,随着学习容量的增加,对预训练数据的需求也相应
发表于 05-07 17:10
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
和强化学习展开,详细介绍各阶段使用的算法、数据、难点及实践经验。
预训练阶段需要利用包含数千亿甚至数万亿单词的训练数据,并借助由数千块高性能GPU 和高速网络组成的超级计算机,花费数十天完成深度神经网络
发表于 03-11 15:16





 工商网监
工商网监
评论