 AMD带领GPU进入Chiplet时代 RDNA3架构深入解读
AMD带领GPU进入Chiplet时代 RDNA3架构深入解读
11月3日,AMD 透露了其 RDNA 3 GPU 架构和 Radeon RX 7900 系列显卡的关键细节。这是一个公开宣布,全世界都被邀请观看。宣布后不久,AMD 邀请媒体和分析师进行了闭门采访,以更深入地研究是什么让 RDNA 3 起作用——或者它是否起作用?
对架构的深入研究主要集中在 RX 7900 XTX/XT (Navi 31) GPU 上,但在接下来的几个月中,我们了解了更多细节。这些 GPU 旨在与Nvidia Ada Lovelace 和 RTX 40 系列 GPU竞争,以打造最佳显卡. 我们从 AMD 提供的其他简报中获得了额外的 RDNA 3 详细信息,我们将立即对其进行分类。自从我们最初发布此 RDNA 3 架构深入研究以来,我们已经审查了Radeon RX 7900 XTX 和 7900 XT,以及Radeon RX 7600。
由于使用了Chiplet设计,AMD 的 RDNA 3 架构从根本上改变了 GPU 的几个关键设计元素。这是一个很好的起点。
AMD 已经正式推出了 RX 7900 XTX/XT 和 RX 7600。介于 RX 7800 系列和 RX 7700 系列之间的部分仍然是 MIA,但有传言称它们可能会在 2023 年 7 月到达。所有规格和细节都在7800/7700 是目前最好的猜测。
在顶部,AMD 为 Navi 31 提供了多达 96 个计算单元 (CU),但这并不能说明全部情况。相对于之前的 RDNA 2 架构,每个 GPU“核心”的吞吐量都翻了一番。因此,RX 7900 XTX 上的 6144 个内核提供理论上 61.4 teraflops 的 FP32 性能,是 FP16 的两倍。相比之下,RX 6950 XT 有 5120 个内核,但计算能力仅为 23.7 teraflops。
L0/L1/L2 缓存的缓存大小更大,但 Infinity Cache(即 L3)在 7900 XTX 上已减少到最大 96MB。其他 GPU 包括每个 64 位接口 16MB 的缓存。
与 RDNA 2 代相比,时钟速度有所提高,具体取决于您正在查看的 GPU。Navi 21 部件的官方加速时钟高达 2.31 GHz,而 Navi 31 将其增加到 2.5 GHz。然而,其他 Navi 2x GPU 的时钟频率往往已经在 2.5 GHz 范围内。
到目前为止,定价至少在理论上与上一代产品相当或更好。实际上,一旦以太坊挖矿结束,之前的部分价格暴跌,目前 RX 6950 XT 的售价为 600 ~ 700 美元。同样,RX 7600 的厂商建议零售价为 269 美元,而之前的 RX 6650 XT 的厂商建议零售价为 399 美元,但至少从 10 月开始,6650 XT 的售价一直在 250 美元至 275 美元之间。
让我们继续讨论 RDNA 3 架构的其他细节。
AMD RDNA 3 和 GPU 小芯片
Navi 31 由两个核心部分组成,即图形计算芯片 (GCD) 和内存缓存芯片 (MCD)。这与 AMD 对其 Zen 2/3/4 CPU 所做的事情有相似之处,但一切都经过调整以适应图形世界的需求。
对于 Zen 2 及更高版本的 CPU,AMD 使用连接到系统内存的输入/输出芯片 (IOD),并为 PCIe Express 接口、USB 端口以及最近的 (Zen 4) 图形和视频等提供所有必要的功能功能。IOD 然后通过 AMD 的 Infinity Fabric 连接到一个或多个核心计算芯片(CCD — 或者“核心复杂芯片”),CCD 包含 CPU 核心、缓存和其他元素。
设计中的一个关键点是典型的通用计算算法——在 CPU 内核上运行的东西——将主要适合各种 L1/L2/L3 缓存。直到 Zen 4 的现代 CPU 只有两个用于系统 RAM 的 64 位内存通道(尽管EPYC Genoa 服务器处理器最多可以有十二个 DDR5 通道)。
CCD 很小,IOD 范围从大约 125mm²(Ryzen 3000)到 416mm²(EPYC xxx2 代)。最近,Zen 4 Ryzen 7000 系列 CPU 的 IOD 使用 TSMC N6 制造,尺寸仅为 122mm²,带有一个或两个在 TSMC N5 上制造的 70mm² CCD,而 EPYC xxx4 代使用相同的 CCD,但具有相对巨大的 IOD 尺寸为 396mm²(仍由 TSMC N6 制造)。
GPU 有非常不同的要求。大型缓存可以提供帮助,但 GPU 也非常喜欢拥有大量内存带宽来满足所有 GPU 核心的需求。例如,即使是配备 12 通道 DDR5 配置的 EPYC 9654 也“仅”提供高达 460.8 GB/s 的带宽。RTX 4090 等最快的显卡可以轻松将其翻倍。
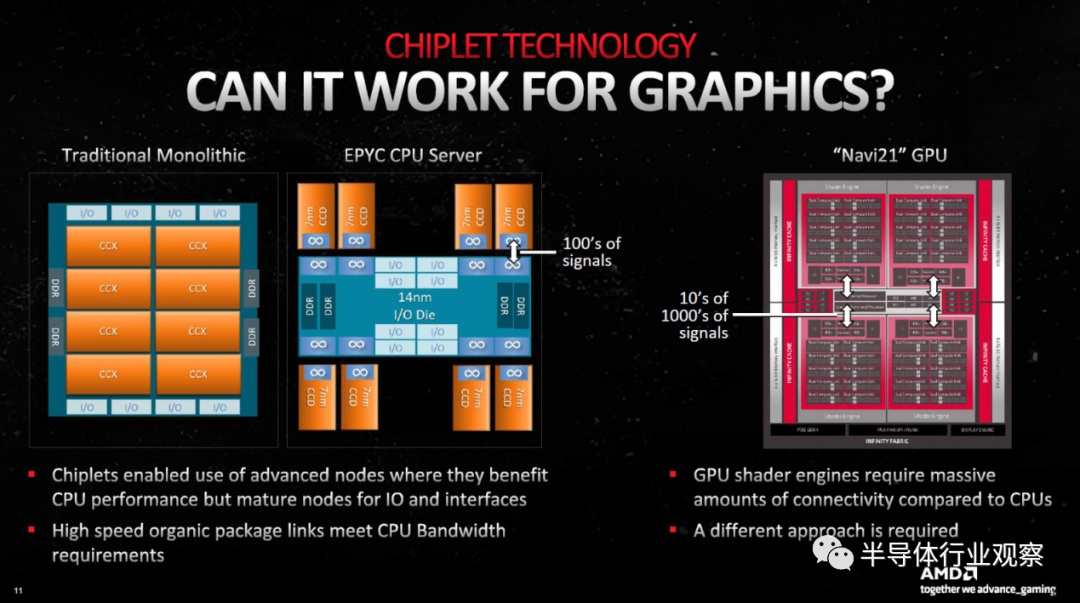
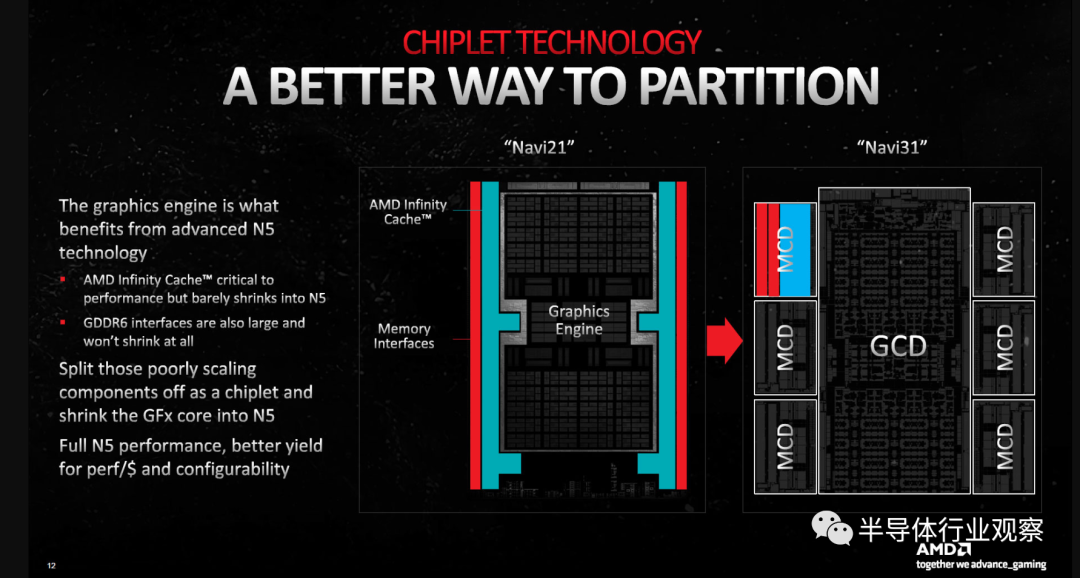
换句话说,AMD 需要做一些不同的事情来让 GPU 小芯片有效地工作。该解决方案最终几乎与 CPU 小芯片相反,内存控制器和缓存被放置在多个较小的芯片上,而主要计算功能位于中央 GCD 小芯片中。
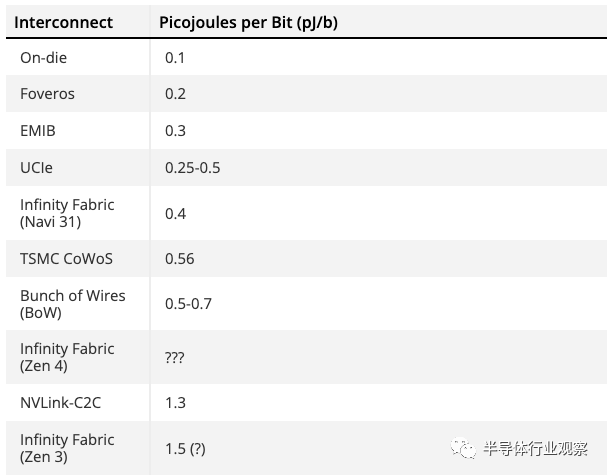
GCD 包含所有计算单元 (CU) 以及其他核心功能,如视频编解码器硬件、显示接口和 PCIe 连接。Navi 31 GCD 有多达 96 个 CU,这是典型的图形处理发生的地方。但它的顶部和底部边缘也有一个 Infinity Fabric(通过某种总线连接到芯片的其余部分),然后连接到 MCD。
MCD,顾名思义(Memory Cache Dies)主要包含大型 L3 缓存块(Infinity Cache),以及物理 GDDR6 内存接口。它们还需要包含 Infinity Fabric 链接以连接到 GCD,您可以在沿着 MCD 面向中心的边缘拍摄的芯片中看到这一点。
GCD 使用台积电的 N5 节点,将 457 亿个晶体管封装到一个 300mm² 的芯片中。与此同时,MCD 建立在台积电的 N6 节点上,每个芯片在尺寸仅为 37mm² 的芯片上封装了 20.5 亿个晶体管。高速缓存和外部接口是现代处理器中扩展性最差的一些元素,我们可以看到总体上 GCD 平均每 mm² 有 1.523 亿个晶体管,而 MCD 平均只有 5540 万个晶体管/mm²。
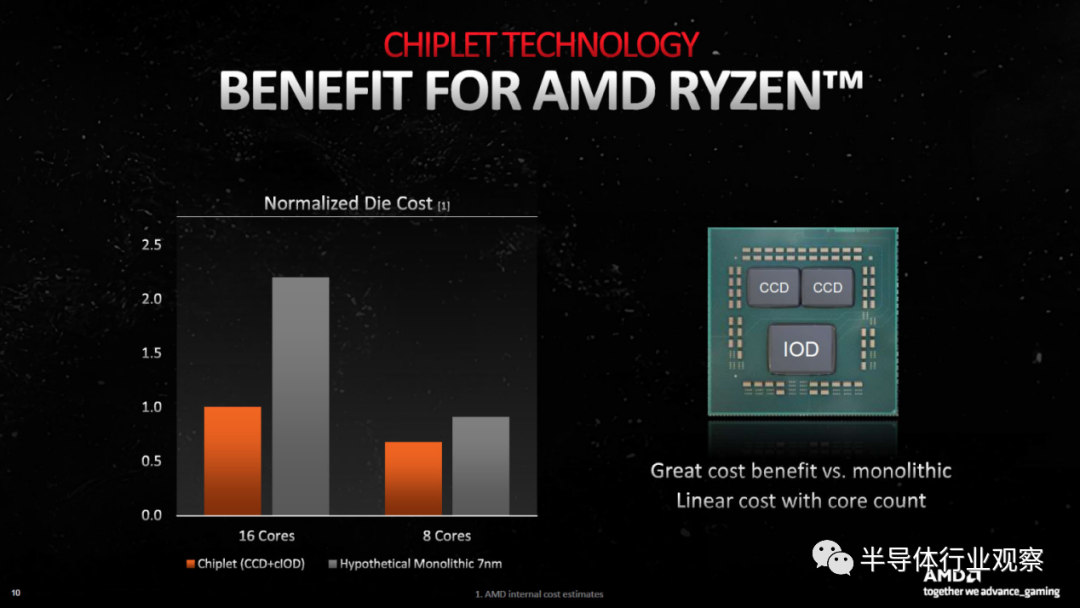
这里值得一提的是,虽然 Navi 31(可能还有 Navi 32)使用 GPU 小芯片,但最小的 Navi 33 裸片(用于Radeon RX 7600和其他移动 GPU)由构建在台积电 N6 节点上的单片裸片组成。成本节约措施显然是各种 RDNA 3 设计的主要因素。
AMD 的高性能扇出互连
GPU 上的小芯片方法的一个潜在问题是所有 Infinity Fabric 链路需要多少功率——外部芯片几乎总是使用更多功率。例如,Zen CPU 有一个制造成本相对较低的有机基板中介层,但它消耗 1.5 pJ/b(每比特皮焦耳)。将其扩展到 384 位接口会消耗相当大的功率,因此 AMD 努力改进与 Navi 31 的接口。
结果就是 AMD 所谓的高性能扇出互连。上图并没有把事情说清楚,但左边较大的接口是 Zen CPU 上使用的有机基板互连。右边是 Navi 31 上使用的高性能扇出桥,“大致按比例”。

您可以清楚地看到用于 CPU 的 25 根电线,而用于 GPU 的 50 根电线被挤在一个小得多的区域中,因此您甚至看不到单独的电线。对于相同的目的,它大约是高度和宽度的 1/8,这意味着大约是总面积的 1/64。这反过来又大大降低了功耗要求,AMD 表示,所有 Infinity Fanout 链接组合起来可提供 3.5 TB/s 的有效带宽,而仅占 GPU 总功耗的不到 5%。



这里有一个有趣的地方:GCD 和 MCD 上的所有 Infinity Fabric 逻辑都占用了相当大的裸片空间。从裸片照片来看,GCD 上的六个 Infinity Fabric 接口使用了大约 9% 的裸片面积,而这些接口大约占 MCD 上总裸片尺寸的 15%。
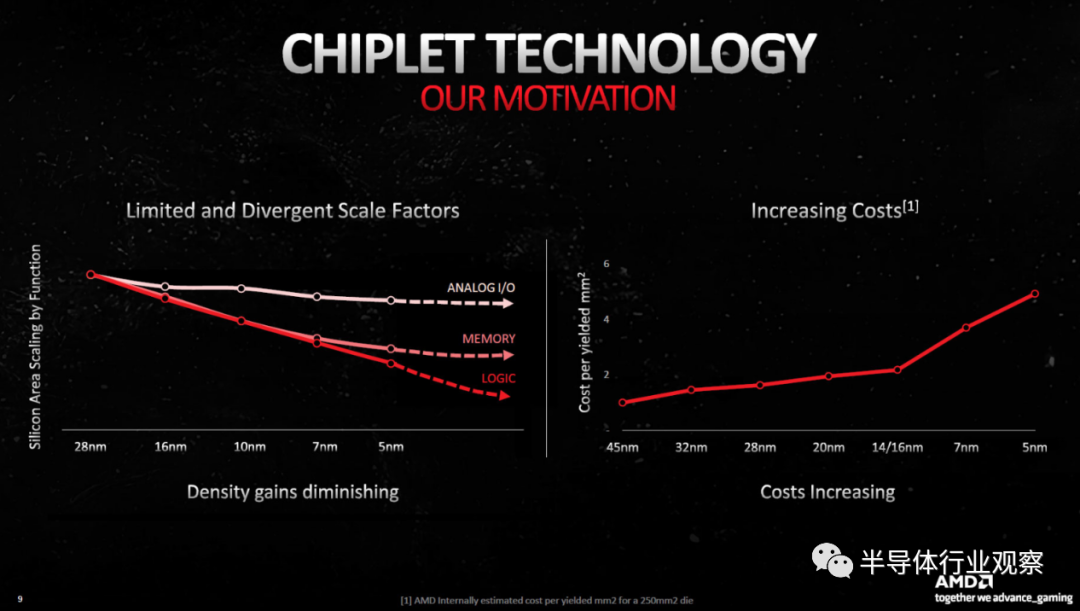
去掉 Infinity Fabric 接口并将整个芯片构建为台积电 N5 节点上的单片部件,它的尺寸可能只有 ~400mm²。显然,台积电 N5 的成本远高于 N6,因此值得采用小芯片路线,这说明了较小制造节点的成本不断增加。要么是这样,要么是 AMD 正在为未来设计架构,现在接受打击并希望以后获得更大的收益。

与此相关,我们知道芯片设计的某些方面可以随着工艺的缩小而更好地扩展。外部接口——比如 GDDR6 物理接口——几乎停止了扩展。缓存的扩展性也很差。有趣的是,AMD 的下一代 GPU(Navi 4x / RDNA 4)是否会利用与 RDNA 3 相同的 MCD,同时将 GCD 转移到 N3 等未来的台积电节点。
AMD RDNA 3 架构升级
这涉及到设计的小芯片方面,所以现在让我们来看看 GPU 各个部分的架构变化。这些可以大致分为四个方面:芯片设计的一般变化、GPU 着色器(流处理器)的增强、改进光线追踪性能的更新以及矩阵运算硬件的改进。

查看原始规格,AMD 似乎并没有将时钟速度提高那么多,但之前我们只有游戏时钟数据。现在我们可以说加速时钟更高了,在一般情况下,AMD 的 RDNA 3 GPU 甚至会超过官方的加速时钟——换句话说,它们是保守的加速。
AMD 表示 RDNA 3 的设计可以达到 3 GHz 的速度。参考 7900 XTX / XT 上的官方升压时钟远低于该标记,但我们也认为 AMD 的参考设计更侧重于最大限度地提高效率。第三方 AIB 卡可以大大提高功率限制、电压和时钟速度。我们会看到 3 GHz 出厂超频吗?7900 系列没有发生这种情况,但也许其他 GPU 中的一个会走那么远。
根据 AMD 的说法,RDNA 3 GPU 可以在使用一半功率的情况下达到与 RDNA 2 GPU 相同的频率,或者在使用相同功率的情况下达到 1.3 倍的频率。最终,AMD 希望平衡频率和功率以提供最佳的整体体验。实际上,顶级 GPU 上的时钟比上一代高几百 MHz。
AMD 提出的另一点是,它已将硅利用率提高了约 20%。换句话说,RDNA 2 GPU 上有一些功能单元,其中部分芯片经常处于闲置状态,即使在卡处于满载状态下也是如此。不幸的是,我们没有直接衡量这一点的好方法,所以我们会接受 AMD 的话,但最终这应该会带来更高的性能。
AMD RDNA 3 计算单元增强功能
在小芯片之外,许多最大的变化发生在计算单元 (CU) 和工作组处理器 (WGP) 中。其中包括对 L0/L1/L2 缓存大小的更新、用于 FP32 和矩阵工作负载的更多 SIMD32 寄存器,以及某些元素之间更广泛和更快的接口。
AMD 的 Mike Mantor 展示了上面和下面的幻灯片,它们很密集!他基本上在一个小时的大部分时间里不停地讲话,试图涵盖 RDNA 3 架构所做的一切,但时间远远不够。上面的幻灯片涵盖了全局概览,但让我们逐步了解一些细节。
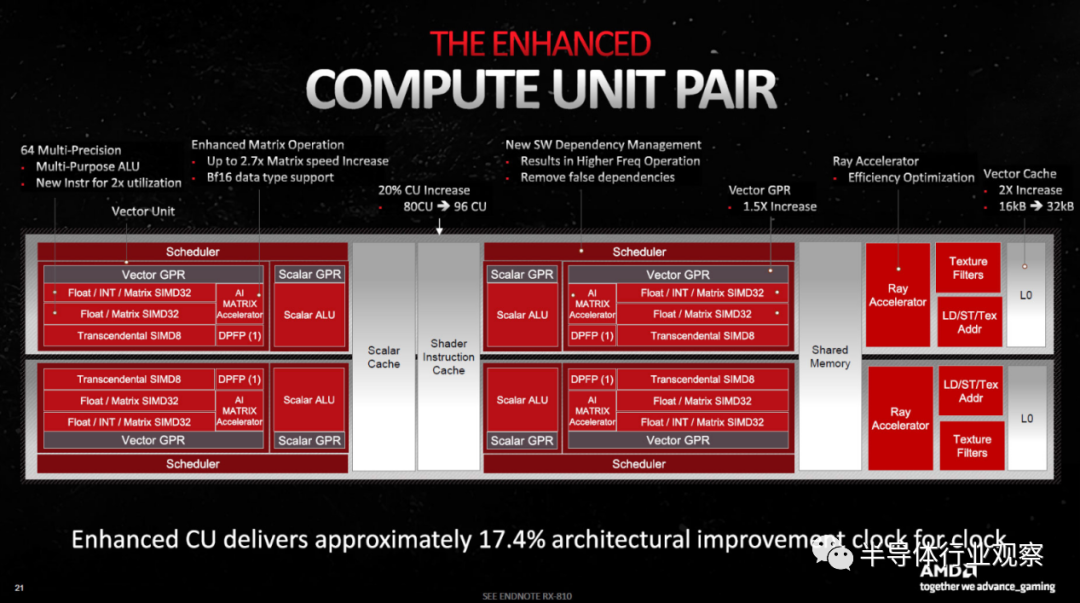
RDNA 3 带有增强的计算单元对——成为 RDNA 芯片主要构建块的双 CU。这与 RDNA 2 不同,但请注意调度程序和矢量 GPR(通用寄存器)的第一个块表示“Float / INT / Matrix SIMD32”,然后是第二个块表示“Float / Matrix SIMD32”。第二个块是 RDNA 3 的新块,它基本上意味着浮点吞吐量翻倍。
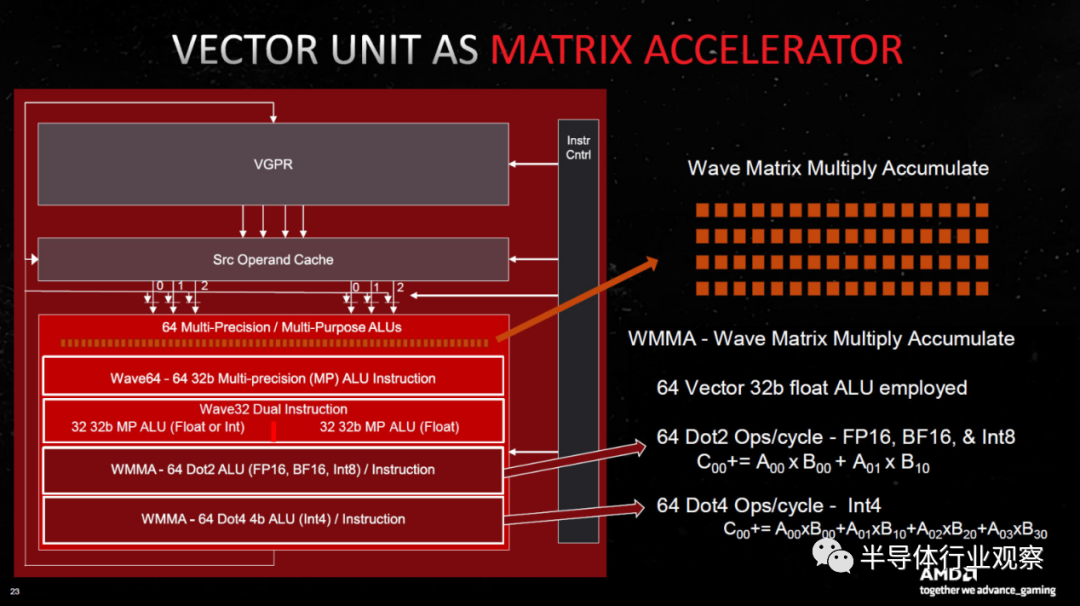
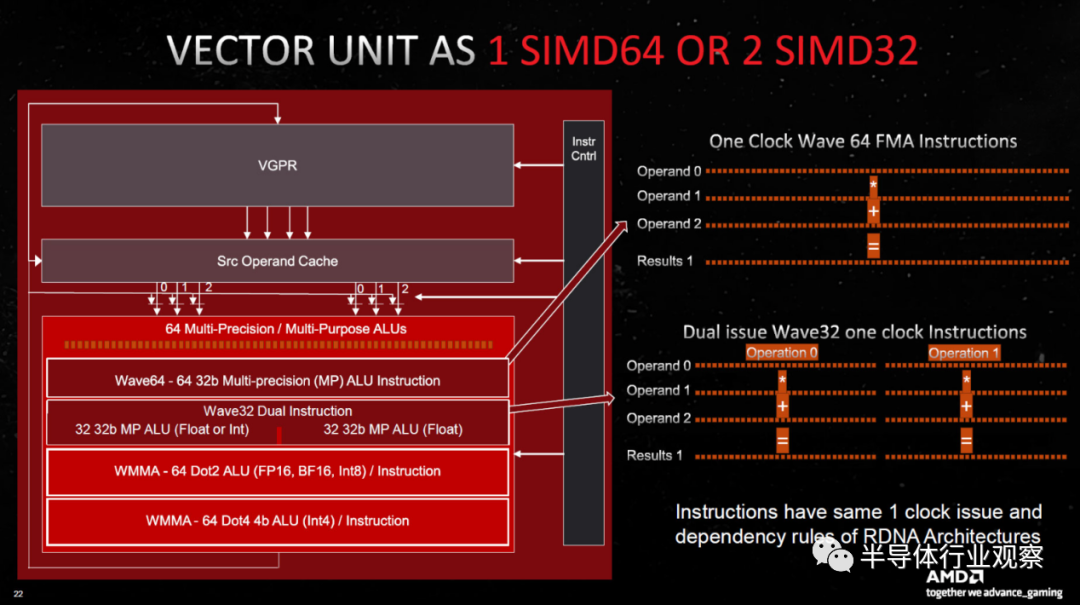
您可以选择以两种方式之一查看事物:每个 CU 现在有 128 个流处理器(SP 或 GPU 着色器),并且您总共获得 12,288 个着色器 ALU(算术逻辑单元),或者您可以将其视为 64”与上一代 RDNA 2 CU 相比,FP32 吞吐量恰好翻了一番。
这有点好笑,因为有些地方说 Navi 31 有 6,144 个着色器,而其他地方说有 12,288 个着色器,所以我特地问了 AMD 的首席 GPU 架构师和 RDNA 3 设计背后的主要负责人 Mike Mantor,它是否是 6,144或 12,288。他拿出计算器,敲了几个数字,说:“嗯,应该是12288。” 然而,在某些方面,事实并非如此。
AMD 自己的规格说 7900 XTX 有 6,144 个 SP 和 96 个 CU,而 7900 XT 有 84 个 CU 和 5,376 个 SP,因此 AMD 正在采取使用较低数量的方法。但是,原始 FP32 计算(和矩阵计算)增加了一倍。就我个人而言,将其称为每个 CU 128 个 SP 比 64 个更有意义,整体设计看起来类似于 Nvidia 的 Ampere 和 Ada Lovelace 架构。现在每个流式多处理器 (SM) 有 128 个 FP32 CUDA 内核,还有 64 个 INT32 单元。但无论如何,AMD 并没有使用更大的数字。
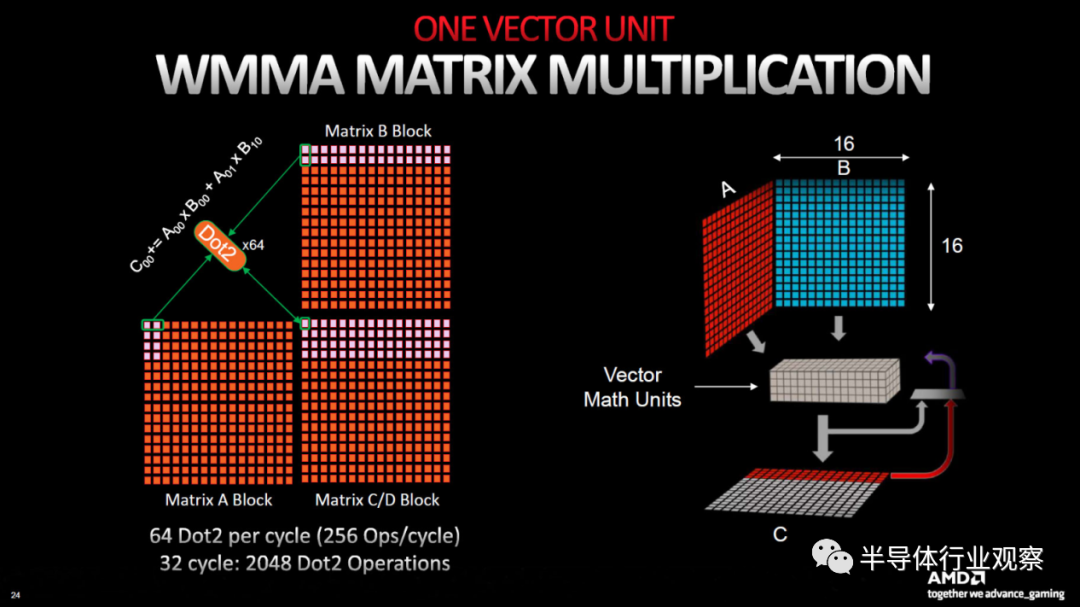
除了额外的 32 位浮点计算,AMD 还将矩阵 (AI) 吞吐量提高了一倍,并且 AI 矩阵加速器共享许多着色器执行资源。AI 单元的新功能是 BF16(大脑浮动 16 位)支持,以及 INT4 WMMA Dot4 指令(波形矩阵乘积),并且与 FP32 吞吐量一样,矩阵运算速度整体提高了 2.7 倍。
这 2.7 倍似乎来自时钟对时钟性能的总体增长 17.4%,加上 CU 增加 20% 以及每个 CU 的 SIM32 单元增加一倍。
AMD RDNA 3:更大更快的缓存和互连
缓存以及缓存与系统其余部分之间的接口都已升级。例如,L0 缓存现在是 32KB(双倍 于RDNA 2),L1 缓存是 256KB(又是双倍于 RDNA 2),而 L2 缓存增加到 6MB(比 RDNA 2 大 1.5 倍)。
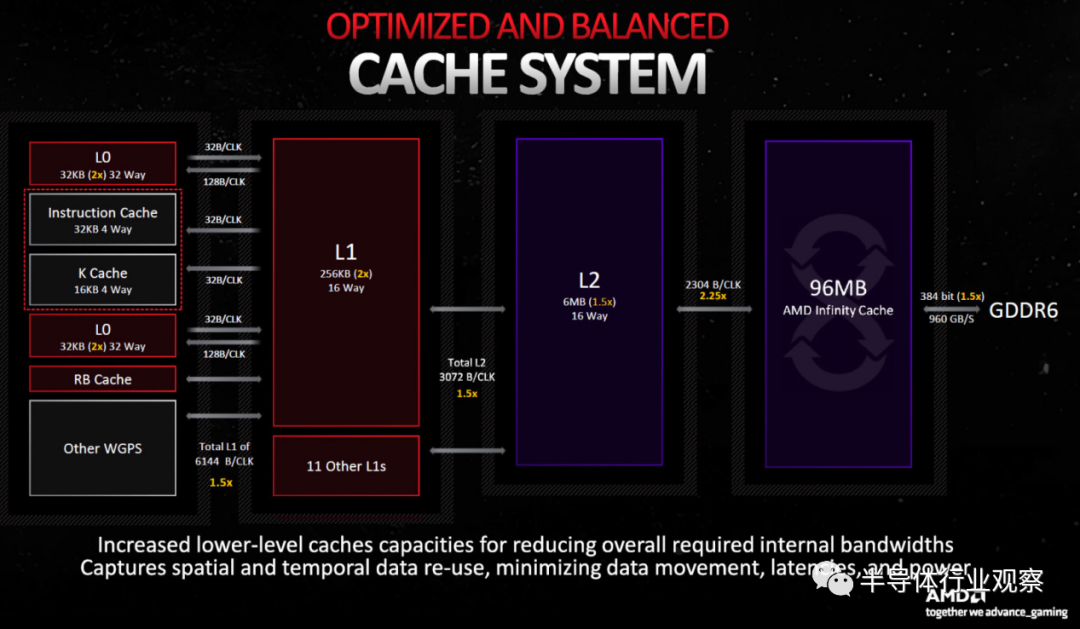
主处理单元和 L1 缓存之间的链接现在宽 1.5 倍,每个时钟吞吐量为 6144 字节。同样,L1 和 L2 缓存之间的链接也宽 1.5 倍(每个时钟 3072 字节)。
L3 缓存,也称为 Infinity Cache,相对于 Navi 21 确实缩小了。现在是 96MB 对 128MB。然而,L3 到 L2 链路现在宽了 2.25 倍(每个时钟 2304 字节),因此总吞吐量要大得多更高。事实上,AMD 给出了 5.3 TB/s 的数字——在 2.3 GHz 的速度下为 2304 B/clk。RX 6950 XT 只有 1024 B/clk 链接到其 Infinity Cache(最大值),RDNA 3 提供高达 2.7 倍的峰值接口带宽。
请注意,这些数字仅适用于 7900 XTX 中完全配置的 Navi 31 解决方案。7900 XT 有五个 MCD,下降到 320 位 GDDR6 接口和 1920 B/clk 链接到组合的 80MB Infinity Cache。我们将自然而然地看到较低层级的 RDNA 3 部件,它们会进一步缩减接口宽度和性能。
最后,现在有多达六个 64 位 GDDR6 接口,用于连接到 GDDR6 内存的组合 384 位链接。VRAM 的时钟频率也为 20 Gbps(后来的 6x50 卡为 18 Gbps,原始 RDNA 2 芯片为 16 Gbps),总带宽为 960 GB/s。
有趣的是,这一代 GDDR6 和 GDDR6X 之间的差距缩小了多少,至少在出货配置方面是这样。AMD 在 RX 7900 XTX 上的 960 GB/s 仅比现在 RTX 4090 的 1008 GB/s 低 5%,而 RX 6900 XT 和 RTX 3090 仅比 Nvidia 的 936 GB/s 高 512 GB/s。回到 2020 年。Nvidia 当然也采用了更大的缓存大小及其Ada Lovelace 架构。
AMD RDNA 3:第二代光线追踪
RDNA 2 架构上的光线追踪总是感觉像是事后才想到的——为了满足 DirectX 12 Ultimate 所需的功能清单而附加的东西。AMD 的 RDNA 2 GPU 缺乏专用的 BVH 遍历硬件,选择通过其他共享单元来完成这项工作,这至少部分归咎于它们较弱的 RT 性能。

RDNA 2 射线加速器每个时钟最多可以进行四次射线/盒子相交,或一次射线/三角形相交。相比之下,英特尔的 Arc Alchemist 每个时钟每个 RTU 最多可以进行 12 次射线/盒子交叉,而 Nvidia 没有提供具体数字,但在 Ampere 上每个 RT 内核最多可以进行 2 次射线/三角形交叉,最多可以进行 4 次射线/Ada Lovelace 上每个时钟的三角形交叉点。

目前尚不清楚 RDNA 3 是否真的直接改进了这些数字,或者 AMD 是否专注于其他增强功能以减少执行的光线/盒子相交的数量。也许两者都有。我们所知道的是,RDNA 3 将改进 BVH(边界体积层次)遍历,这将提高光线追踪性能。

RDNA 3 还具有大 1.5 倍的 VGPR(矢量通用寄存器),这意味着飞行中的射线数量增加了 1.5 倍。还有其他堆栈优化可以减少 BVH 遍历所需的指令数量,并且可以使用专门的框排序算法(最接近优先、最大优先、最接近中点)来提取提高的效率。
总的来说,由于新功能、更高的频率和更多的射线加速器数量,AMD 表示与 RDNA 2 相比,RDNA 3 的射线追踪性能应该提高 1.8 倍。这应该会缩小 AMD 和 Nvidia Ampere 之间的差距。尽管如此,Nvidia 似乎还在 Ada Lovelace 的光线追踪硬件上加倍投入,因此我们不会指望 AMD 能够提供与 RTX 40 系列 GPU 相当的性能。
AMD RDNA 3:其他架构改进
最后,RDNA 3 调整了与命令处理器、几何形状和像素管道相关的架构的其他元素。还有一个新的双媒体引擎,支持 AV1 编码/解码、AI 增强视频解码和新的 Radiance 显示引擎。

命令处理器 (CP) 更新应提高某些工作负载的性能,同时减少驱动程序和 API 端的 CPU 瓶颈。基于硬件的剔除性能在事物的几何方面也快了 50%,并且每个时钟的峰值光栅化像素增加了 50%。
最后一个似乎是将 Navi 21 上的 ROP(渲染输出)数量从 128 个增加到 Navi 31 上的 192 个的结果。这是有道理的,因为内存通道也增加了 50%,AMD 希望扩展其他元素与此同步。
双媒体引擎应该使 AMD 在视频方面与 Nvidia 和 Intel 持平,尽管我们最近的视频编解码器质量和性能测试表明它仍然落后于 Intel 和 Nvidia。另请注意,AV1 更多的是关于摆脱 HEVC 的版税,而不是提高质量,尽管性能可能有点不确定。
AMD 还因为包含对 DisplayPort 2.1 的支持而获得了至少几点。英特尔的 Arc GPU 也支持 DP2,但最高可达 40 Gbps (UHBR 10),而 AMD 可以达到 54 Gbps (UHBR 13.5)。AMD 的显示输出可以在 229 Hz 下驱动高达 4K,无需压缩 8 位色深,或 187 Hz 10 位色。Display Stream Compression 可以将其提高一倍以上,允许 4K 和 480 Hz 或 8K 和 165 Hz——并不是说我们离拥有实际支持这种速度的显示器还差得很远。
实际上,我们不得不怀疑 DP2.1 UHBR 13.5 对 RDNA 3 显卡的重要性。首先,您需要一台支持 DP2.1 的新显示器,其次,问题是 4K 180 Hz 之类的东西在使用和不使用 DSC 时看起来有多好——因为 DP1.4a 仍然可以使用 DSC 处理该分辨率,而 UHBR 13.5 可以在没有 DSC 的情况下完成。我们一直在使用三星 Odyssey Neo G8 32 英寸显示器,通过 DSC 支持 4K 240 Hz,并且没有发现任何质量下降。
AMD RDNA 3:结语
总的来说,这听起来像是一项令人印象深刻的工程壮举。
AMD 可以很好地与 Nvidia 的 RTX 4080 卡竞争,至少在非光线追踪和非 AI 工作负载方面是这样。另一方面,如果您想要最快的 GPU,AMD 甚至不会尝试与更大的RTX 4090正面交锋。
简单的数学提供了大量的思考。FP32 6,144 个着色器以 2.5 GHz 运行,ALU 吞吐量翻倍,而 Nvidia 的 16,384 个着色器以 2.52 GHz 运行,Nvidia 显然具有原始计算优势——61 teraflops 对比 83 teraflops。如前所述,添加更多 FP32 单元使 AMD 的 RDNA 3 看起来更像 Ampere 和 Ada Lovelace。
除了原始计算,我们还有晶体管数量和芯片尺寸。Nvidia 坚持为 Ada Lovelace 使用单片芯片,包括 AD102、AD103、AD104、AD106 和 AD107 芯片。最大的一个在 608mm²芯片中有 763 亿个晶体管。即使 AMD 正在开发具有 580 亿个晶体管的单片 522mm²芯片,我们也希望 Nvidia 具有一些优势。然而,GPU 小芯片方法意味着一些区域和晶体管被用于与性能不直接相关的事情。
与此同时,Nvidia 的倒数第二个 Ada 芯片,即RTX 4080 中使用的 AD103 ,落在了栅栏的另一边。凭借 256 位接口、459 亿个晶体管和 368.6mm²裸片尺寸,Navi 31 应该具有一些明显的优势——无论是 RX 7900 XTX 还是稍低一些的 7900 XT。然后是具有 358 亿个晶体管和 294.5mm²裸片的 AD104,即“未发布”的 RTX 4080 12GB,最终演变为 RTX 4070 Ti。
但性能比纸面规格更重要。Nvidia 将晶体管投入到 DLSS(张量核心)、DLSS 3(光流加速器)和光线追踪硬件等功能中。AMD 似乎更愿意放弃一些光线追踪性能,同时提升更常见的用例。实际上,在我们的GPU 基准测试层次结构中,RX 7900 XTX 在光栅化性能方面几乎领先于 RTX 4080 ,而在光线追踪性能方面,它更接近于上一代RTX 3090。
对于那些对价格在 900 美元或以上的显卡不感兴趣的人,还有RTX 4070 Ti、RTX 4070、RTX 4060 Ti和RX 7600等显卡. 我们仍在等待 AMD 的 RX 7800 和 7700 产品,这可能会在 AMD 等待清理剩余的 Navi 2x 库存时推迟。据传,Navi 32 使用相同的 MCD,但具有更小的 GCD,而 Navi 33 已经作为仍然构建在 N6 节点上的单片芯片推出。
审核编辑:刘清
-
CCD
+关注
关注
32文章
880浏览量
142228 -
gpu
+关注
关注
28文章
4729浏览量
128901 -
GCDM
+关注
关注
0文章
4浏览量
2144 -
RDNA
+关注
关注
0文章
20浏览量
1904
原文标题:AMD带领GPU进入Chiplet时代,RDNA 3架构深入解读
文章出处:【微信号:Hack电子,微信公众号:Hack电子】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMD确认2025年推出RDNA 4显卡,光追与AI性能大幅提升
X86架构处理器有哪些优点和缺点
X86架构和ARM架构有什么区别
ElfBoard技术贴|如何将libwebsockets库编译为x86架构

移动端芯片性能提升,Armv9架构新升级引发关注
AMD RDNA4显卡全部搭载18Gbps显存,带宽略逊于部分RDNA3产品
AMD Radeon RX 7000M系列显卡特性分析

AMD推出锐龙8000嵌入式处理器,AI算力高达39 T
AMD Zen6架构继续飞跃!核显跨越下下代RDNA5

arm架构和x86架构区别 linux是x86还是arm
AMD全新的锐龙8000G系列台式机处理器介绍

基于Zen 4的锐龙8000G系列桌面处理器

深入解读AMD最新GPU架构
值得入手的AMD Radeon 显卡推荐—— AMD Radeon RX 7900 XT






 工商网监
工商网监
评论