 基于深度强化学习的视觉反馈机械臂抓取系统
基于深度强化学习的视觉反馈机械臂抓取系统
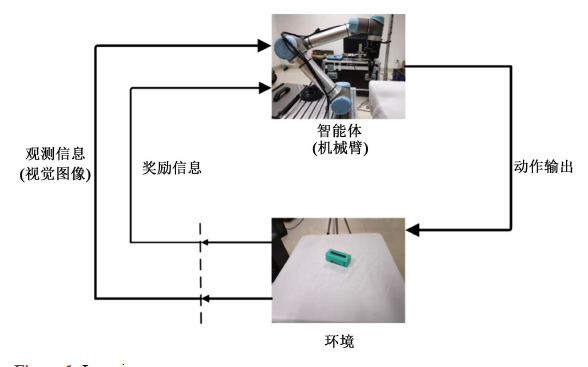
机械臂抓取摆放及堆叠物体是智能工厂流水线上常见的工序,可以有效的提升生产效率,本文针对机械臂的抓取摆放、抓取堆叠等常见任务,结合深度强化学习及视觉反馈,采用AprilTag视觉标签、后视经验回放机制
实现了稀疏奖励下的机械臂的抓取任务,并针对本文的抓取场景提出了结合深度确定性策略梯度及后视经验回放的分段学习的算法,相比于传统控制算法,强化学习提高了抓取的准确度及稳定性,在仿真与实际系统中验证了效果。
一.仿真与物理环境搭建
本文采用大象机器人的6自由度的串联型机械手臂myCobot Pro-600,根据myCobot Pro-600的机械结构,采用标准D-H参数法建立机械臂连杆坐标系,如图所示:
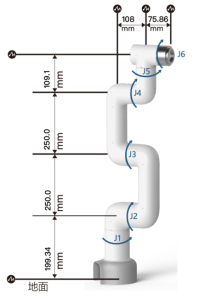
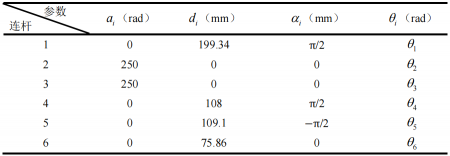
根据上图建立的机械臂连杆坐标系,得到D-H参数表:
根据模型参数,使用Pybullet搭建抓取摆放任务仿真环境如下:

在抓取摆放任务中,机械臂要实现的就是抓取紫色的物块,并稳定的放置在绿色的目标点处
仿真环境的状态、目标、奖赏和动作的设置如下:
(1) 状态(States):包括机械臂的末端位置、姿态;待抓取物块位置、姿态(紫色长方体);目标点位置。
注:仿真环境中为了减轻算力,没有使用AprilTag进行姿态解算,实物中使用AprilTag来定位待抓取物块位置。
(2) 目标(Goals)(绿色圆锥区域):目标描述了目标的期望位置,具有一定固定的容差,也就是在这个公式中,表示物体在状态s时的位置。
(3) 奖赏(Rewards):奖赏是二进制值,即稀疏奖赏,通过其中是机械臂在状态s下执行动作a后的状态。
(4) 动作(Actions):X(前后),Y(左右),(夹爪旋转)方向的运动速度。Z(高度)由时间步控制。
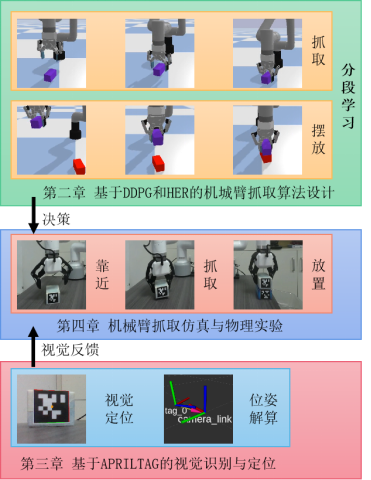
二.基于DDPG与HER的机械臂搬运任务分段学习算法
DeepMind在2016年提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法,是结合了深度学习和确定性策略梯度方法的一种算法
DDPG在具有连续动作空间的决策任务中已经成功应用,但是对于一些复杂的技能学习任务,不能设计合适的奖励函数,所以不能得到较好的学习效果。
然而,将DDPG和HER结合,可以解决稀疏奖励的不可学习问题。
HER只通过改变经验池中数据的状态和奖励,增大正向奖励的密度,利用DDPG的主策略网络采集完轨迹数据,再将轨迹数据重组为经验形式的数据,利用目标选择策略修改其中的状态和奖励,最后将经验存放在经验池中。
在实际应用中,为了减少内存需求,则HER的实施方式也不同,经验池中一般存放的是轨迹,只有再采集小批量数据更新网络或者归一化器时才使用目标选择策略。
在抓取任务中,开始时DDPG算法在动作空间随机采样运动,由于奖励的稀疏,在多次探索后可能仍然无法获得奖励,而HER加入后,在已经探索的轨迹中加入虚拟奖励,刺激价值函数的增长,以加速强化学习的学习速率。
针对抓取任务,本文采用分段学习的技巧,第一阶段为接近物块阶段,第二阶段为物块搬运阶段,有效的消除了传统HER算法对不需要奖励的步数的替换,从而加速了学习过程。
结合HER的DDPG算法的伪代码如图所示:

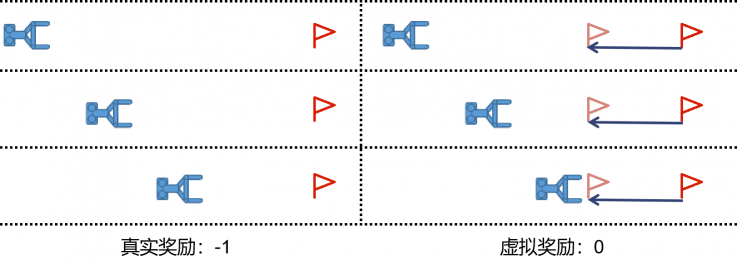
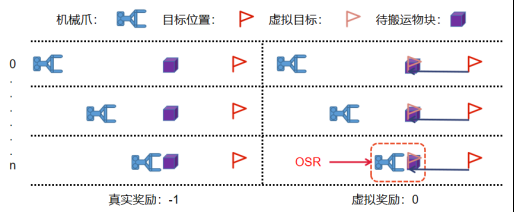
由于抓取摆放任务的奖励稀疏性与任务的层次性,使用传统的DDPG+HER算法会引起重叠虚假奖励(OSR)问题
如下图所示,具体来说当HER算法将目标位置虚拟到与物块位置相同给与虚拟奖励时,会引起强化学习抓取而不搬运的错误学习,这会严重影响学习过程的稳定性,导致价值网络不稳定甚至无法收敛。
为了解决此问题,本文提出了针对抓取摆放等分层任务的分段学习算法。
分段学习是指通过将问题分解成多个子问题,并针对每个子问题独立地解决,从而提高了算法的效率和鲁棒性。分段学习是将原问题分解成若干个子问题,每个子问题对应一个状态空间和一个动作空间。
然后,针对每个子问题,使用强化学习算法进行学习和探索,以得到最优的策略。
最后,将所有子问题的策略组合起来,得到解决原问题的最优策略。分段学习算法的优点在于,它可以针对复杂的大规模问题进行分解,从而使得每个子问题的状态空间和动作空间更小,更易于学习和探索。
此外,由于子问题之间是独立的,因此分段学习算法具有很好的可扩展性和可并行性。
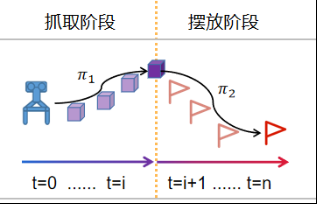
针对抓取摆放任务,利用分段学习将任务分为抓取阶段与摆放阶段,下图为抓取摆放任务分段学习过程示意图,抓取阶段与摆放阶段各自采用DDPG+HER进行训练,抓取阶段以抓取到物块作为奖励
摆放阶段以正确摆放作为奖励,最终得到抓取决策1与摆放决策2,使用机械爪是否抓取到物块作为策略的切换标志,最终完成了机械臂靠近物块(决策1),机械爪夹取物块,机械臂摆放物块(决策2)的任务。
三.基于AprilTag的视觉识别与定位
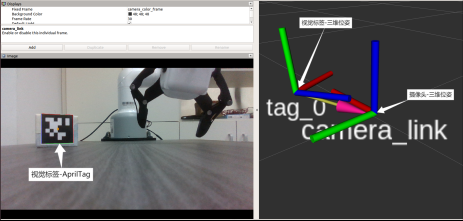
AprilTag是一个基准视觉库,通过在物体上粘贴Apriltag标签,利用识别算法,确定标签坐标系和摄像头坐标系的关系,即可得到物体的位姿,在增强实现、机器人和相机校准等领域广泛使用。
AprilTag视觉标签与二维码有相似之处,但是降低了视觉标签的复杂度,抗光和抗遮挡性能比较好,能够快速的检测视觉标签信息,并计算相机与标识码之间的相对位置。
AprilTag的特点是高速、高精度、高稳定性。它的高速性表现在在实时应用中,AprilTag可以快速地识别目标,并输出其位姿信息,响应速度可以达到几十毫秒。
常用的AprilTag视觉标签有以下几个族:Tag16h5、Tag25h9和Tag36h11,如下所示。
从图中,我们可以看到Tag16h5族的数量相对比较少,当处于光照较强的环境中或者被遮挡时容易被误识别,但在远距离定位中有较高的精度。
Tag36h11与Tag16h5对比,其族数量较多,应用在复杂环境时鲁棒性较强,但是在远距离定位中精度较低。

这里通过AprilTagROS库来进行定位与目标姿态解算
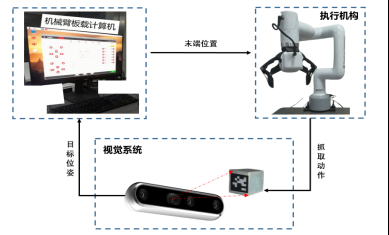
通过深度相机经过目标物块Tag的检测与世界坐标系下的映射,可以得出待抓取物块的位置坐标和姿态信息,此时将该目标位姿作为所提决策算法的输入
经过机械臂板载计算机的计算输出各关节动作,该动作经过机械臂逆运动学的解算映射成机械臂末端位置到达目标物块位置实现一次的抓取动作
在运行该决策流程时,目标位置可随时变化,深度相机再次解算目标物块变化之后的位姿并输入给决策算法,如此循环,直到终止程序。视觉反馈系统工作流程图如下所示。
四.机械臂抓取仿真与物理实验
仿真实验
在仿真中采用结合HER的DDPG算法,其网络设计如下。DDPG有策略网络和值网络两种。
策略网络是以输入作为状态,输出作为动作;而值网络的输入是状态-动作对,输出的是一维的Q值,在引入HER后,状态则变为了状态-目标对。
在此次实验中,所用到的状态信息主要是机械臂和目标物等的状态信息,所以网络结构只包含全连接层,策略网络的输出层的激活函数选择双曲正切函数
则动作值的映射区间为-1到1,其余的各层激活函数用修正线性单元(Recitified Linear Unit,ReLU)。策略网络和值网络的结构如表所示。
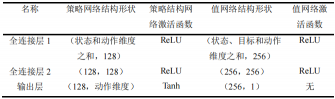
在学习和策略更新中使用的学习率为0.001。使用Adam优化器训练网络,学习率为2.5e-4,训练批次大小是256。后视经验的回放策略为未来策略(future)。
使用百度飞桨(PaddlePaddle)深度学习框架进行训练,在16GB内存,8核心i7-7700处理器,Tesla V100显卡的Linux的系统下进行训练,训练轮数为2000,单个算法的运行时间10小时,仿真训练效果如图所示,截取训练次数在第200、440、680和840次的效果。
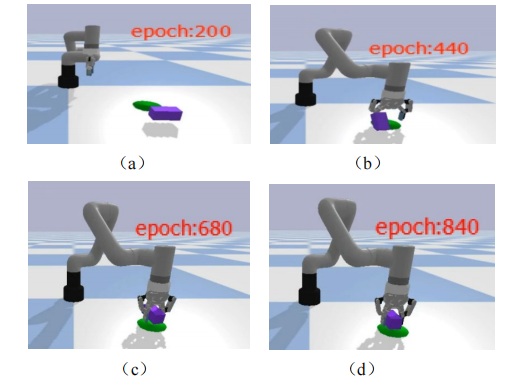
从图的仿真结果可以看到,在训练200、440次的时候,机械臂能够成功抓取b并放置在目标点的成功率并不高,随着训练次数的增加,对于随机的物块放置位置,机械臂成功抓取并放置的概率越来越大。
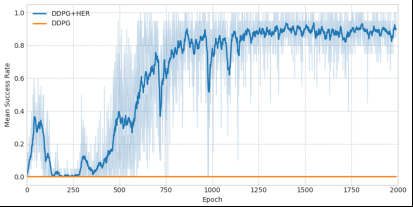
(1) 深度确定性策略梯度算法在抓取摆放任务环境中并不收敛,成功率一直为0。说明在没有后视经验回放(HER)的机制下算法很难探索到目标区域,经验池中有限的目标点不足以支持算法的计算收敛。
(2) 在两个算法中DDPG+HER相比于DDPG收敛速度更快,成功率更高,说明本文提出针对机械臂抓取任务分段学习的后视回放机制算法相比于传统的强化学习算法性能有了较大提升。
物理实验
为了将仿真训练的网络能够用于实际机械臂系统,本文搭建了和仿真中较为一致的抓取实验平台。采用的是大象机器人的myCobot Pro600协作机械臂,其采用树莓派微处理器,内嵌robotFlow可视化编程软件,操作简单。
上位机采用的是ThinkPad T490笔记本电脑。在硬件方面,采用D435i的RGBD相机作为手眼相机,D435i结合了宽视场和全局快门传感器,在机器人导航和物体识别等领域广泛应用。
在软件方面,在Windows10系统中使用Python3.6、paddlepaddle2.3.0版本搭建神经网络,与训练时配置一致,则可以直接载入训练好的模型参数运行控制程序。

在机械臂的抓取放置实验中,抓取物为一个长方体的物块,在该物块上粘贴AprilTag码,实验目标是将该物块放置到目标位置的盒子中:

机械臂抓取堆叠的任务是将两个相同的物块堆叠放置,即将白色的物块安全的放置在蓝色物块上,在白色和蓝色物块上贴有不同的AprilTag码,实现过程如图所示:

通过物理实验验证了强化学习算法的有效性,在实物上实现了与仿真相同的效果,能够实现将物块稳定的堆叠放置在另一个物块上,具体实验效果视频请查看。

审核编辑:汤梓红
-
机器人
+关注
关注
211文章
28362浏览量
206886 -
机械臂
+关注
关注
12文章
513浏览量
24543 -
智能工厂
+关注
关注
3文章
997浏览量
42403 -
深度强化学习
+关注
关注
0文章
14浏览量
2300
原文标题:基于深度强化学习的视觉反馈机械臂抓取系统
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

什么是深度强化学习?深度强化学习算法应用分析

【瑞芯微RK1808计算棒试用申请】基于机器学习的视觉机械臂研究与设计
深度强化学习实战
将深度学习和强化学习相结合的深度强化学习DRL
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向
深度强化学习将如何控制机械臂的灵活动作
基于深度强化学习仿真集成的压边力控制模型
《自动化学报》—多Agent深度强化学习综述


模拟矩阵在深度强化学习智能控制系统中的应用






 工商网监
工商网监
评论