 李飞飞团队新作SiamMAE:孪生掩码自编码器,刷榜视觉自监督方法!
李飞飞团队新作SiamMAE:孪生掩码自编码器,刷榜视觉自监督方法!
【导读】只需一个简单操作扩展MAE,即可实现自监督学习新sota!
在计算机视觉领域,想要建立图像和场景(scene)之间之间的对应关系是一项比较困难的任务,尤其是在存在遮挡、视角改变或是物体外观发生变化的情况下。
最近,斯坦福大学李飞飞团队对MAE进行扩展,提出了孪生掩码自编码器SiamMAE(Siamese Masked Autoencoders)以学习视频中的视觉对应关系。

论文链接:https://siam-mae-video.github.io/resources/paper.pdf
先随机采样两个视频帧,并进行非对称掩码操作;然后SiamMAE编码器网络对两个帧进行独立处理,最后使用交叉注意层组成的解码器来预测未来帧(future frame)中丢失的图像块。
通过对未来帧中的大部分(95%)图像块进行掩码,同时保持过去帧(past frame)图像不变,SiamMAE促使网络专注于物体运动,并学习以物体为中心的表征。

尽管整个网络的设计概念比较简单,但通过SiamMAE学习到的特征在视频物体分割、姿势关键点传播和语义部分传播任务上都优于最先进的自监督方法。
SiamMAE在不依赖于数据增强、基于手工跟踪的前置任务或其他技术来防止表征崩溃的情况下,实现了非常有竞争力的性能。
孪生掩码自编码器
研究人员的目标是开发一种自监督的方法来学习对应关系,主要是将掩码自编码器(MAE)模型扩展到视频数据中。
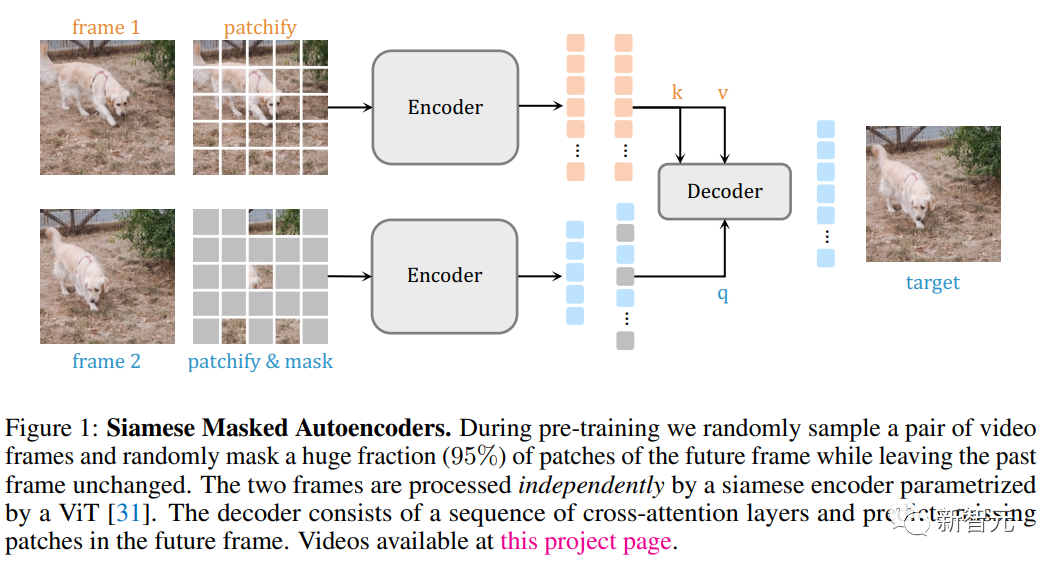
Patchify
给定具有L帧的视频剪辑,首先随机采样两个视频帧,两帧之间的距离通过从预定的potential frame gaps范围中选择一个随机值来确定。
与原始ViT模型类似,通过将每个帧转换为一系列不重叠的N×N个patch来拼接视频帧。
最后,把位置嵌入加到线性投影上,并附加一个[CLS]标记,需要注意的是没有使用时序位置嵌入。
Masking
像图像和视频这样的自然信号是高度冗余的,分别表现为空间和时空上的冗余。
为了创造一个具有挑战性的预测性自监督学习任务,MAEs随机掩码了75%的图像patch,视频数据的掩码率提升到90%,并且对每帧都使用相同的掩码率。
这种设计可以使网络无法利用和学习到时间上的对应关系,避免在对应关系学习基准上达到次优性能。
研究人员认为,不对称的掩码可以创造一个更有挑战性的自监督学习任务,并且可以鼓励网络学习时间上的相关性。
所以对于采样的两个视频帧,对第一帧选择不掩码,对第二帧选择掩码95%,这样就可以将整个过去帧(entire past frame)作为输入,网络只需要将其扩散到未来中的适当位置即可,可以促进网络对物体运动进行建模并关注物体的边界。

为了进一步增加任务的难度,两个视频帧之间具有更大的时间间隔,尽管可能会导致对未来的预测变得模糊,并可能产生多种合理的结果,但为第二帧提供少量的patch作为输入,可以让网络的自监督学习变得更困难。
编码器
研究人员探索了两种不同的编码器配置来处理输入帧。
联合编码器(joint encoder)是图像MAEs在一对视频帧上的扩展,把两帧未掩码的图像patch串联起来,然后输入到标准的ViT编码器中进行处理。
孪生编码器(siamese encoder)是用于比较实体的权重共享神经网络,是对比表征学习方法的一个重要组件,用于对应学习(corresponding learning)时通常需要一些信息瓶颈来防止网络学习的解决方案,如使用颜色通道dropout来迫使网络避免依赖颜色来匹配对应关系。
在这篇论文中,研究人员使用孪生编码器来独立处理两幅图像,使用非对称掩码作为信息瓶颈。
解码器
编码器的输出通过线性层进行投影,并加入带有位置嵌入的[MASK] token,以生成对应于输入帧的所有token
研究人员探索了三种不同的解码器配置:
联合解码器(joint decoder)在两帧的token串联上使用原版Transformer模块,其主要缺点是对GPU内存的需求大幅增加,特别是在使用较小的patch尺寸时。
交叉自解码器(cross-self decoder)与原版Transformer模型的编码-解码器设计类似,每个解码器块由一个交叉注意力层和一个自注意力层组成,来自第二帧的token通过交叉注意力层与第一帧的token进行注意力操作,然后通过自注意力层进行相互融合。
可以注意到,交叉注意力层在功能上类似于自监督对应学习方法中经常使用的affinity矩阵。
交叉解码器(cross decoder)由交叉注意力层的解码器块组成,其中来自第二帧的token与来自第一帧的token进行注意力操作。
最后,解码器的输出序列被用来预测掩码图像块中的归一化像素值,在解码器的预测和真实值之间使用L2损失。
实验结果

视频物体分割
在多物体分割基准数据集DAVIS 2017上,使用480p分辨率的图像对模型进行评估。
实验结果可以发现SiamMAE明显优于VideoMAE(从39.3%提升到62.0%),研究人员将其归因于VideoMAE中使用了tube掩码方案,使得模型无法学习时间上的对应关系。
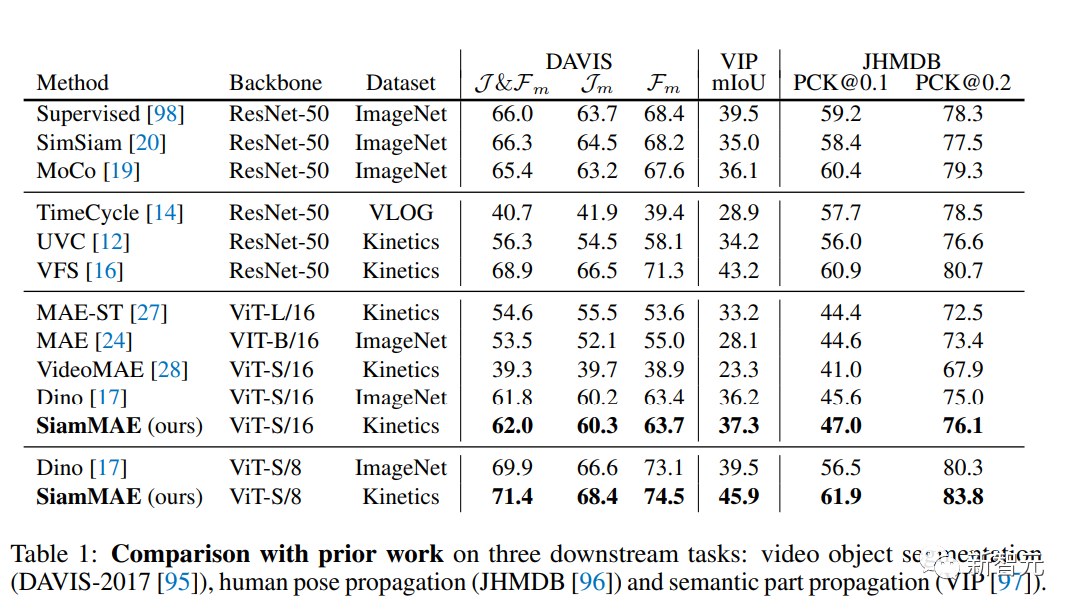
与DINO类似,研究人员也发现降低patch的尺寸会带来明显的性能提升。
并且文中使用的ViT-S/8(+9.4%)模型优于之前所有的对比学习和自监督的对应学习方法。

还可以注意到尽管较大的MAE-ST模型(ViT-L/16,304M参数)在随机掩码的情况下比VideoMAE表现更好,但其性能仍然落后于SiamMAE相当多。
而且在视频上训练的MAE与图像MAE的表现相似,视频与图像的不同之处在于,图像是(近似)各向同性的,时间维度是特殊的,并不是所有的时空方向都是同等可能的。
因此,对称地处理空间和时间信息可能是次优的。
视频部分分割(Video Part Segmentation)
在视频实例解析(Video Instance Parsing, VIP)基准上对SiamMAE进行评估,该基准包括为20个不同的人体部位传播语义掩码。
与评估的其他数据集相比,VIP特别具有挑战性,因为包括更长的视频(最长120秒)。
与先前工作类似,使用560×560的图像和单一背景帧进行评估后,可以发现ViT-S/8模型性能大大超越了DINO (从39.5提升到45.9)。

SiamMAE从更小的patch尺寸中,比DINO受益更多,实现了+8.6的mIoU评分,比DINO的+3.3 mIoU有所提高。
SiamMAE也优于之前所有的对比学习和自监督的对应关系学习方法。
姿势追踪(pose tracking)
在关键点传播的任务上对SiamMAE进行了评估,需要传播15个关键点,并且要求空间上的精确对应关系,使用320×320的图像和一个单一的背景帧,SiamMAE的性能优于所有其他模型,并且比DINO更受益于较小的patch尺寸(+14.9到+10.9 PCK@0.1)

参考资料: https://siam-mae-video.github.io/resources/paper.pdf
-
解码器
+关注
关注
9文章
1153浏览量
40998 -
编码器
+关注
关注
45文章
3680浏览量
135423 -
图像
+关注
关注
2文章
1089浏览量
40605
原文标题:李飞飞团队新作SiamMAE:孪生掩码自编码器,刷榜视觉自监督方法!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于变分自编码器的异常小区检测
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

自编码器是什么?有什么用
自编码器介绍
稀疏自编码器及TensorFlow实现详解
自编码器基础理论与实现方法、应用综述
一种多通道自编码器深度学习的入侵检测方法

一种基于变分自编码器的人脸图像修复方法

基于变分自编码器的网络表示学习方法
基于自编码特征的语音声学综合特征提取
自编码器神经网络应用及实验综述
堆叠降噪自动编码器(SDAE)
自编码器 AE(AutoEncoder)程序






 工商网监
工商网监
评论