 基于通过非常稀疏的视角输入合成场景的方法
基于通过非常稀疏的视角输入合成场景的方法

作者引入了一种方法,可以仅使用单个宽基线立体图像对生成新视角。在这种具有挑战性的情况下,3D场景点只被正常观察一次,需要基于先验进行场景几何和外观的重建。作者发现从稀疏观测中生成新视角的现有方法因恢复不正确的3D几何和可导渲染的高成本而失败,这阻碍了其在大规模训练中的扩展。作者通过构建一个多视图转换编码器、提出一种高效的图像空间极线采样方案来组装目标射线的图像特征,以及一个轻量级的基于交叉注意力的渲染器来解决这些问题。作者的贡献使作者的方法能够在一个大规模的室内和室外场景的真实世界数据集上进行训练。作者展示了本方法学习到了强大的多视图几何先验,并降低了渲染时间。作者在两个真实世界数据集上进行了广泛的对比实验,在保留测试场景的情况下,明显优于先前从稀疏图像观测中生成新视图的方法并实现了多视图一致的新视图合成。
1 前言
本文介绍了在极端稀疏输入条件下进行新视图合成的问题,提出了一个从单个广角立体图像对中生成高质量新视图的方法。为了更好地推理三维场景,提出了一个多视图视觉变换器来计算每个输入图像的像素对准特征,并引入多视图特征匹配以进一步炼化三维几何。通过采用以图像为中心的采样策略,提出了一种高效的可微分渲染器,解决了样本稀疏问题,从而大大减少了样本量需求。实验证明了该方法在几个数据集上均获得了最先进的结果,比现有方法表现出更好的性能。
2 相关背景
IBR方法通过融合一组输入图像的信息生成新的相机视角下的图像。单场景体绘制方法则利用可微渲染进行的3D场景表示来进行新视角合成。不同于IBR方法需要多个输入图像,单场景体绘制方法需要数百个密集采样的3D场景的输入图像。与这两种方法不同,一些方式使用可微渲染来监督基于先验的推理方法,即先验知识可以帮助优化3D重建和视图合成。现有的方法普遍依赖于多个图像观测,而作者的方法通过仅使用一组宽基线立体图像对场景进行重建来解决这一问题。
3 方法
本文提出一种用于生成3D场景新视角图像的方法。该方法使用已知相机内参和外参以及宽基线立体图像计算像素对齐的特征,并使用基于交叉注意力的渲染器将特征转换为新视角的图像渲染结果。该方法为解决新视角图像生成问题提供了一种有效的解决方案。
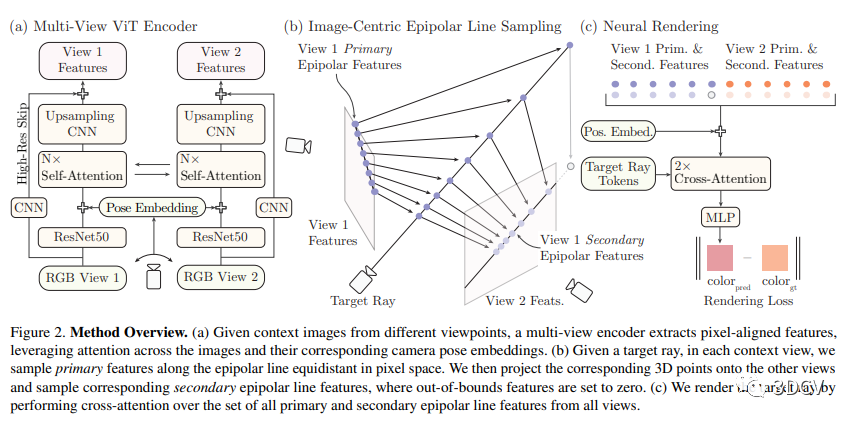
3.1 Multiview Feature Encoding - 多视图特征编码
本文中提出了一种多视角编码器来获取特征。该方法包括两个阶段:首先通过ResNet50提取基础卷积特征。然后,通过学习的每像素位置嵌入和相机位置嵌入将这两个图像转换为平面特征向量。接下来,这些向量经过视觉Transformer编码器处理,使每个向量的表示包含了整个场景的上下文。最后,用一个低分辨率的基础CNN获取高频的图像信息,这些信息与之前的图像特征映射级联在一起。
3.2 Epipolar Line Sampling and Feature Matching - 线极线采样和特征匹配
本文提出了一种基于像素对齐特征的通用的新视角合成方法。通过对极线采样来找到样本点,然后使用特征匹配模块计算来自另一个视图的次要特征,以进一步处理表面细节。采用基础矩阵来定义不同视图生产的极线,并在其上采样像素来获得样本。深度值可通过封闭形式的三角测量获得。在这种方法中,样本点的数量已达到有效最大值。
3.3 Differentiable Rendering via Cross-Attention - 交叉注意力实现可微分渲染
本文介绍了使用交叉注意力实现可微分渲染的方法。为了将样本集映射到颜色值,作者将每个视差线上的点嵌入为一个射线查询标记。然后,作者的渲染程序通过两轮交叉注意力,得到特征嵌入,然后通过简单的 MLP 解码为颜色。作者的方法不需要显式计算精确的场景深度,而是可以使用目标相机射线信息和少数视差样本计算像素颜色。
3.4 Training and Losses - 训练和损失函数
在视图合成中,训练图像合成模型的损失函数是关键。模型应该能够生成与真实图像尽可能接近的合成图像。本文提出了由图像损失和正则化损失组成的损失函数,其中图像损失通过LPIPS感知损失测量。此外,正则化损失有助于提高多视角一致性。作者还使用几何一致的数据增强来提高模型的泛化能力。
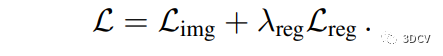
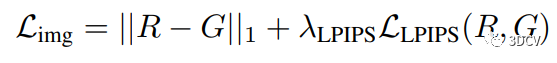
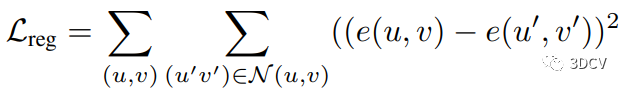
4 实验
在本文中,作者展示的方法可以从宽基线立体图像中有效地渲染新视角。作者在不同类型的场景中进行了评估和分析,并且成功应用了该方法在野外捕获的场景中。
4.1 实验细节
作者在RealEstate10k和ACID这两个大型室内外场景的数据集上进行训练和评估。作者使用67477个场景进行RealEstate10k的训练和7289个场景进行测试,11075个场景进行ACID的训练和1972个场景进行测试,按照默认的划分方法。作者使用256×256分辨率的图像对作者的方法进行训练,并在测试场景中评估方法的重建中间视角的能力(详细信息在附录中)。
作者将作者的方法与几种现有的从稀疏图像观测中合成新视角的方法进行比较。作者将比较使用像素对齐特征的pixelNeRF和IBRNet,这些特征被解码成使用体积渲染渲染的3D体积。作者还将与使用视觉变换器骨干计算极线特征和基于光场渲染器计算像素颜色的通用补丁渲染(GPNR)进行比较。这些基线涵盖了现有方法中使用的各种设计选择,例如使用CNN和transformer计算的像素对齐特征图,使用MLP和transformer进行的特征解码体积渲染以及基于光场的渲染。
作者为所有基线使用公开可用的代码库,并使用作者用于公正评估的相同数据集对其进行训练。有关更多基线的比较,请参见补充材料。评估指标。作者使用LPIPS ,PSNR,SSIM和MSE指标来比较渲染图像与地面真实图像的图像质量。
4.2 室内场景的神经渲染
在各种评估指标下,本文的方法在室内场景中渲染新视角时均优于比较的基线。此外,与其他方法相比,该方法能更好地重建场景的3D结构,并捕获更多的高频细节,这为视觉应用提供了更好的合成质量。


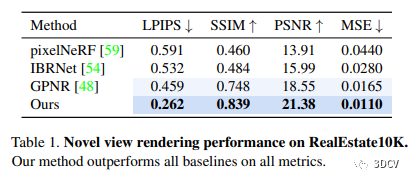
4.3 室外场景的神经渲染
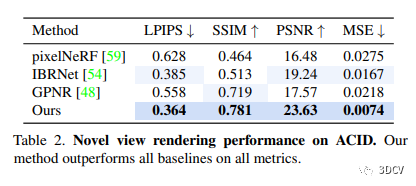
本文研究对具有潜在无界深度的户外场景进行了神经渲染的评估,展示了定性和定量结果,指出了该方法在重建几何结构、多视角一致的渲染以及各项指标方面的表现均优于基线方法。

4.4 消融实验
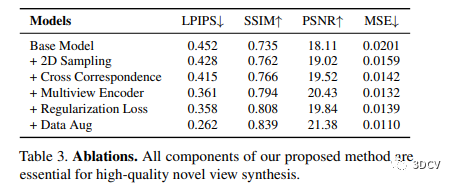
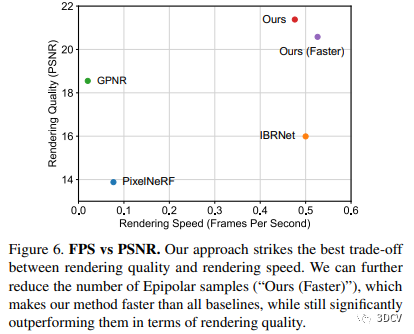
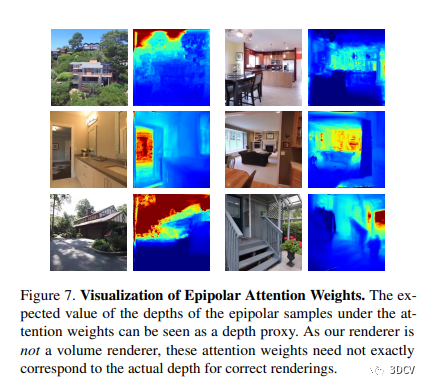
本文研究进行了组件分析和消融实验。消融实验表明了我们方法的各个组件对性能的贡献,其中包括2D极线采样、多视编码器、跨图像的对应关系匹配、多视一致性的正则化损失以及数据增强。此外,本研究对不同渲染方法的质量和速度进行了比较,结果显示我们的轻量级方法在质量和速度方面实现了最佳的平衡,并提升了高质量视频的渲染速度。最后,我们可视化了我们方法中的基础极线注意权重,用来分析渲染器的学习计算。
4.5 从不规定姿态图像中合成新视角
本文提出了一种方法,可以使用宽基线立体图像合成新视角,即使在未知相对位姿的情况下。在这种情况下,使用SuperGlue计算像素对应关系,使用平均内参估计本质矩阵,从而推导出姿态信息。这一方法可以处理不规定姿态的图像,能较好地推断场景的几何形状。
5 讨论
本文提出了一种通过非常稀疏的视角输入合成场景的方法。然而,该方法的渲染结果质量不如其他基于更多图像的优化方法。同时,由于该方法依赖于学习先验知识,其适用范围受到限制。虽然该方法能够扩展到处理多于两个输入视角,但是目前只尝试了处理两个视角。
6 总结
本文提出了一种仅使用自监督训练实现从单个宽基线立体图像对中进行隐式3D重建和新视角合成的方法。该方法利用多视角编码器、图像空间对极线特征采样方案和基于交叉注意力的渲染器,在具有挑战性场景数据集上超越了以往方法的质量,同时在渲染速度和质量之间取得了很好的平衡。同时,利用对极线几何在结构化和通用化学习范例之间进行平衡,该方法可在RealEstate10k等现实数据集上进行训练。
责任编辑:彭菁
-
3D
+关注
关注
9文章
3023浏览量
115577 -
数据集
+关注
关注
4文章
1240浏览量
26261 -
渲染器
+关注
关注
0文章
18浏览量
3378
原文标题:CVPR2023 I 一种全新的单个宽基线立体图像对中学习渲染新视角的方法
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
敏捷合成器的技术原理和应用场景
基于稀疏编码的迁移学习及其在行人检测中的应用
【ELT.ZIP】OpenHarmony啃论文俱乐部——浅析稀疏表示医学图像
基于分层稀疏编码的行人检测算法
结合弹性网络的稀疏分解方法的人脸识别
基于坐标下降的并行稀疏子空间聚类方法
基于块稀疏表示的行人重识别方法
如何使用自适应嵌入的半监督多视角特征实现降维的方法概述
稀疏微波成像的研究案例
从多视角图像做三维场景重建 (CVPR'22 Oral)
近场合成孔径雷达稀疏测量微波成像简析

读者理解:LEAP泛化到新的物体类别和场景




评论